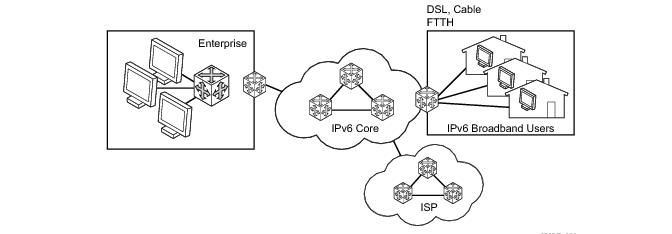
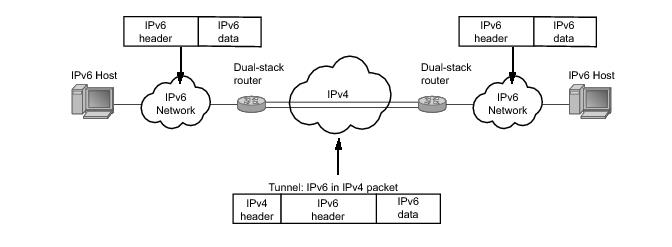
Refer to 7750 SROS Triple Play Guide for information about DHCP and support as well as configuration examples. on page 33
An IP address range can be reserved for exclusive use for services by defining the config>router>service-prefix command. When the service is configured, the IP address must be in the range specified as a service prefix. If no service prefix command is configured, then no limitation exists.
Addresses in the range of a service prefix can be allocated to a network port unless the exclusive parameter is used. Then, the address range is exclusively reserved for services.
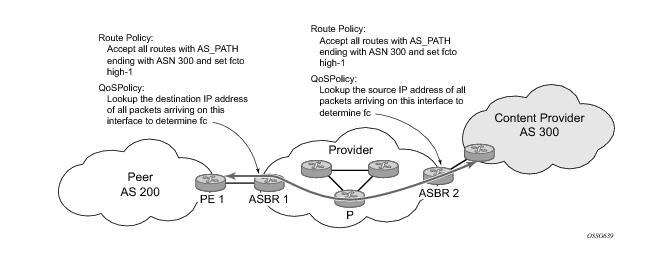
Figure 1 shows an example of an ISP that has an agreement with the content provider managing AS300 to provide traffic sourced and terminating within AS300 with differentiated service appropriate to the content being transported. In this example we presume that ASBR1 and ASBR2 mark the DSCP of packets terminating and sourced, respectively, in AS300 so that other nodes within the ISP’s network do not need to rely on QPPB to determine the correct forwarding-class to use for the traffic. Note however, that the DSCP or other COS markings could be left unchanged in the ISP’s network and QPPB used on every node.
fc fc-name [priority {low | high}]
config>router>policy-options
begin
community gold members 300:100
policy-statement qppb_policy
entry 10
from
protocol bgp
community gold
exit
action accept
fc h1 priority high
exit
exit
exit
commit
The fc command is supported with all existing from and to match conditions in a route policy entry and with any action other than reject, it is supported with next-entry, next-policy and accept actions. If a next-entry or next-policy action results in multiple matching entries then the last entry with a QPPB action determines the forwarding class and priority.
A route policy that includes the fc command in one or more entries can be used in any import or export policy but the
fc command has no effect except in the following types of policies:
|
•
|
static-route {ip-prefix/ prefix-length| ip-prefix netmask} [fc fc-name [priority {low | high}]] next-hop ip-int-name| ip-address
|
|
•
|
static-route {ip-prefix/ prefix-length| ip-prefix netmask} [fc fc-name [priority {low | high}]] indirect ip-address
|
This feature uses a qos keyword to the
show>router>route-table command. When this option is specified the output includes an additional line per route entry that displays the forwarding class and priority of the route. If a route has no fc and priority information then the third line is blank. The following CLI shows an example:
show router route-table [family
] [ip-prefix[/prefix-length]] [longer
| exact
] [protocol
protocol-name] qos
A:Dut-A# show router route-table 10.1.5.0/24 qos
===============================================================================
Route Table (Router: Base)
===============================================================================
Dest Prefix Type Proto Age Pref
Next Hop[Interface Name] Metric
QoS
-------------------------------------------------------------------------------
10.1.5.0/24 Remote BGP 15h32m52s 0
PE1_to_PE2 0
h1, high
-------------------------------------------------------------------------------
No. of Routes: 1
===============================================================================
A:Dut-A#
To enable QoS classification of ingress IP packets on an interface based on the QoS information associated with the routes that best match the packets the qos-route-lookup command is necessary in the configuration of the IP interface. The
qos-route-lookup command has parameters to indicate whether the QoS result is based on lookup of the source or destination IP address in every packet. There are separate qos-route-lookup commands for the IPv4 and IPv6 packets on an interface, which allows QPPB to enabled for IPv4 only, IPv6 only, or both IPv4 and IPv6. Note however, current QPPB based on a source IP address is not supported for IPv6 packets nor is it supported for ingress subscriber management traffic on a group interface.
Note: QPPB based on a source IP address is not supported for ingress subscriber management traffic on a group interface.
When QPPB is enabled on a SAP IP interface the forwarding class of a packet may change from fc1, the original
fc determined by the SAP ingress QoS policy to fc2, the new fc determined by QPPB. In the ingress datapath SAP ingress QoS policies are applied in the first P chip and route lookup/QPPB occurs in the second P chip. This has the implications listed below:
|
•
|
The profile state of a SAP ingress packet that matches a QPPB route depends on the configuration of fc2 only. If the de-1-out-profile flag is enabled in fc2 and fc2 is not mapped to a priority mode queue then the packet will be marked out of profile if its DE bit = 1. If the profile state of fc2 is explicitly configured (in or out) and fc2 is not mapped to a priority mode queue then the packet is assigned this profile state. In both cases there is no consideration of whether or not fc1 was mapped to a priority mode queue.
|
|
•
|
The priority of a SAP ingress packet that matches a QPPB route depends on several factors. If the de-1-out-profile flag is enabled in fc2 and the DE bit is set in the packet then priority will be low regardless of the QPPB priority or fc2 mapping to profile mode queue, priority mode queue or policer. If fc2 is associated with a profile mode queue then the packet priority will be based on the explicitly configured profile state of fc2 (in profile = high, out profile = low, undefined = high), regardless of the QPPB priority or fc1 configuration. If fc2 is associated with a priority mode queue or policer then the packet priority will be based on QPPB (unless DE=1), but if no priority information is associated with the route then the packet priority will be based on the configuration of fc1 (if fc1 mapped to a priority mode queue then it is based on DSCP/IP prec/802.1p and if fc1 mapped to a profile mode queue then it is based on the profile state of fc1).
|
Table 3 summarizes these interactions.
The router ID, a 32-bit number, uniquely identifies the router within an autonomous system (AS) (see Autonomous Systems (AS) ). In protocols such as OSPF, routing information is exchanged between areas, groups of networks that share routing information. It can be set to be the same as the loopback address. The router ID is used by both OSPF and BGP routing protocols in the routing table manager instance.
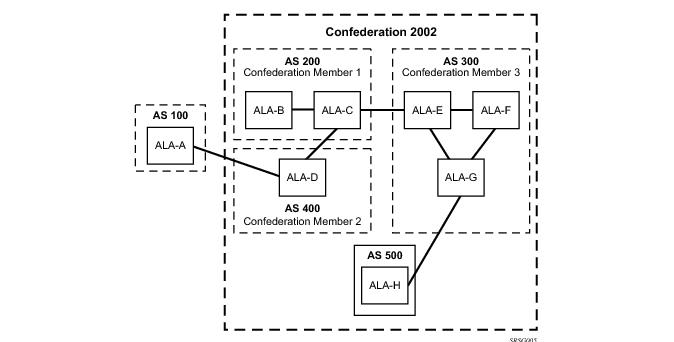
Configuring confederations is optional and should only be implemented to reduce the IBGP mesh inside an AS. An AS can be logically divided into smaller groupings called sub-confederations and then assigned a confederation ID (similar to an autonomous system number). Each sub-confederation has fully meshed IBGP and connections to other ASs outside of the confederation.
|
•
|
Routing within each sub-confederation is accomplished via IBGP.
|
The export-inactive-bgp command under config>service>vprn introduces an IP VPN configuration option that allows the best BGP route learned by a VPRN to be exported as a VPN-IP route even when that BGP route is inactive due to the presence of a more preferred BGP-VPN route from another PE. This “best-external” type of route advertisement is useful in active/standby multi-homing scenarios because it can ensure that all PEs have knowledge of the backup path provided by the standby PE.
Refer to 7750 SROS Triple Play Guide for information about DHCP and support provided by the 7750 SR as well as configuration examples.
The TiMOS implements IP routing functionality, providing support for IP version 4 (IPv4) and IP version 6 (IPv6). IP version 6 (RFC 1883, Internet Protocol, Version 6 (IPv6)) is a newer version of the Internet Protocol designed as a successor to IP version 4 (IPv4) (RFC-791,
Internet Protocol). The changes from IPv4 to IPv6 effect the following categories:
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|Version| Prio. | Flow Label |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Payload Length | Next Header | Hop Limit |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
+ +
| |
+ Source Address +
| |
+ +
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
+ +
| |
+ Destination Address +
| |
+ +
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Note: In SR OS 12.0.R4 any function that displays an IPv6 address or prefix changes to reflect rules described in RFC 5952,
A Recommendation for IPv6 Address Text Representation. Specifically, hexadecimal letters in IPv6 addresses are now represented in lowercase, and the correct compression of all leading zeros is displayed. This changes visible display output compared to previous SR OS releases. Previous SR OS behavior can cause issues with operator scripts that use standard IPv6 address expressions and with libraries that have standard IPv6 parsing as per RFC 5952 rules.
To generate an RSA key pair, use the admin certificate gen-keypair command:
admin certificate gen-keypair cf1:\myDir\myRsaKeyPair type rsa size 1024
To import a generated RSA key pair, use the admin certificate secure-nd-import command:
admin certificate secure-nd-import cf1:\myDir\myRsaKeyPair format der
|
•
|
key-rollover keyword: see the RSA key pair rollover mechanism section that follows.
|
To trigger a key rollover, use the admin certificate secure-nd-import command described in the previous section “
Import an online/offline generated RSA key pair”.
admin certificate secure-nd-import cf1:\myDir\myOtherRsaKeyPair format der key-rollover
|
•
|
If a secure-nd-import with key-rollover is requested while a previous key rollover is still being handled, the new command is refused.
|
|
•
|
If the secure-nd-import command is accepted, the imported RSA key pair is written to the file cfx:\system-pki\secureNdKey and loaded to SeND. Existing CGAs if any will be regenerated.
|
The admin certificate secure-nd-import command without the
key-rollover keyword will be refused if CGAs exist that made use of the auto-generated RSA key pair. Specifying the
key-rollover keyword will result in regeneration of the CGAs.
See the section “Making non-persistent CGAs persistent” for more information on the procedure to make non-persistent CGAs persistent,
|
•
|
manual: admin redundancy synchronize cert
|
Example1: Configure a SeND interface without modifiers (as it is done in release 12.0).
configure router interface itf1
address 10.10.10.1
port 1/1/1
ipv6
secure-nd
no shutdown
exit
address 2000:1::/64
Example 2: Configure a SeND interface with modifiers.
configure router interface itf2
address 10.10.10.2
port 1/1/2
ipv6
secure-nd
link-local-modifier 0xABCD
no shutdown
exit
address 3000:1::/64
address 3000:2::/64 modifier 0xABCD
address 3000:3::/64 modifier 0xABCD
You can import a new RSA key pair for SeND with the key-rollover keyword. This will result in the regeneration of all CGAs on all interfaces.
config>router>static-route-entry {ip-prefix/prefix-length} [mcast] indirect {ip-address}
tunnel-next-hop
resolution {any|disabled|filter}
resolution-filter
[no] ldp
[no] rsvp-te
[no] [lsp <name1>]
[no] [lsp <name2>]
.
.
[no] [lsp <namen>]
exit
[no] disallow-igp
exit
exit
The static-route-entry command is only supported with the
indirect next-hop option and the
tunnel-next-hop option configured together. The existing
static-route command is still supported with all other options, including the
indirect option which can be used to resolve the indirect next-hops in RTM.
/configure router static-route 5.5.5.5/32 indirect 1.0.0.2
/configure router static-route-entry 5.5.5.5/32 indirect 1.0.0.2
tunnel-next-hop
rsvp-te
lsp to-1.0.0.2-1
lsp to-1.0.0.2-2
exit
no shutdown
exit
If tunnel-next-hop context is configured and
resolution is set to
disabled, the binding to tunnel is removed and resolution resumes in RTM to IP next-hops.
If resolution is set to
any, any supported tunnel type in static route context will be selected following TTM preference.
|
•
|
The ldp value instructs the code to search for an LDP LSP with a FEC prefix corresponding to the address of the indirect next-hop.
|
|
•
|
The rsvp value instructs the code to search for the best metric RSVP LSP to the address of the indirect next-hop. This address can correspond to the system interface or to another loopback used on the remote node. The LSP metric is provided by MPLS in the tunnel table. In the case of multiple RSVP LSPs with the same lowest metric, the code selects the LSP with the lowest tunnel-id.
|
If one or more explicit tunnel types are specified using the resolution-filter option, then only these tunnel types will be selected again following the TTM preference. In the case of RSVP-TE tunnel type, the user can further restrict the selection by providing a list of LSP names.
The user must set resolution to
filter to activate the list of tunnel-types configured under resolution-filter.
If disallow-igp is enabled, the static-route will not be activated using IP next-hops in RTM if no tunnel next-hops are found in TTM.
When an IGP, BGP, or a static route prefix is resolved in RTM to a set of ECMP tunnel next-hops of type RSVP-TE and the router level weighted-ecmp option is enabled, the ingress hash table for the next-hop selection is populated with a number of tunnel next-hop entries for each LSP equal to the normalized LSP weight value. All prefixes resolving to the same set of ECMP tunnel next-hops use the same table.
The user can either provide a list of LSP names or let the automatic selection of the LSP tunnel next-hops from the TTM by configuring resolution to the
any value. These are mutually exclusive. A maximum of 128 LSP names can be entered within a static route prefix configuration.
Note that a P2P auto-lsp instantiated via an LSP template can be selected in TTM when resolution is set to
any. It is however not recommended to configure an auto-lsp name explicitly under the
rsvp-te node as the auto-generated name can change if the node reboots which will black-hole traffic of the static route.
The above command is covered in much more details in Static Route Resolution Using Tunnels which also provides the selection rules among multiple LSP types: RSVP and LDP. A given static route of a prefix can only be resolved to a set of tunnel next-hops of the same type though for each indirect next-hop.
The existing static-route command is still supported with all other options, including the
indirect one which can be used to resolve the indirect next-hops in RTM. The new command is an add-on to configure the resolution to tunnel next-hops in TTM. As such, the user must first configure the prefix with the existing command and the
indirect option and then enter the new command with the indirect option and with the new
static-route-entry command. Here is an example:
/configure router static-route 5.5.5.5/32 indirect 1.0.0.2
/configure router static-route-entry 5.5.5.5/32 indirect 1.0.0.2
tunnel-next-hop
rsvp-te
lsp to-1.0.0.2-1
lsp to-1.0.0.2-2
exit
no shutdown
exit
If the user enters for the same static route more LSP names with the same LSP metric than the value of the router level ecmp option, only the first configured LSPs which number equals the
ecmp value will be selected. The remaining tunnel next-hops for the route will not be activated. When automatic MPLS LSP selection is performed in TTM, the lower tunnel-id is used as a tie-breaker among the same lowest metric LSPs.
The behavior of this feature in terms of RTM and IOM is exactly the same as in the case of BGP, IGP, and static route prefixes resolving to IGP shortcuts. See Feature Behavior for the details. In this case, the static route module computes the normalized weight for each prefix tunnel next-hop of the static route indirect next-hop. The minimum value of the normalized weight is 1 and the maximum if 64. The static route module updates the route in RTM with the set of tunnel next-hops and normalized weights. RTM downloads the information to IOM for inclusion in the FIB.
ECMP is also supported when resolving in TTM the same static route with multiple user-entered indirect next-hops each binding to the same or different tunnel types. The system picks as many tunnel next-hops as available in RTM beginning from the first indirect next-hop and up to the value of the ecmp option in the system. In this case, the weighted load-balancing will be applied directly using the weights of the selected set of tunnel next-hops. If one or more LSP in the ECMP set of a prefix static route does not have a weight configured, or if one or more of the indirect next-hops binds to an LDP LSP, the regular ECMP spraying for the prefix will be performed.
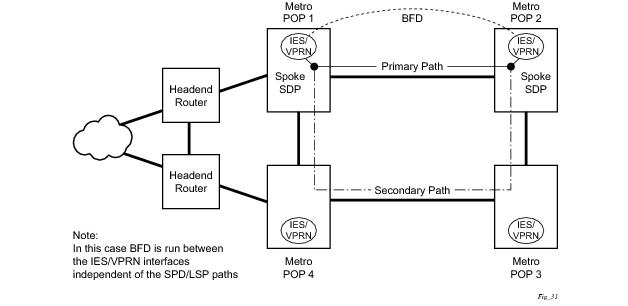
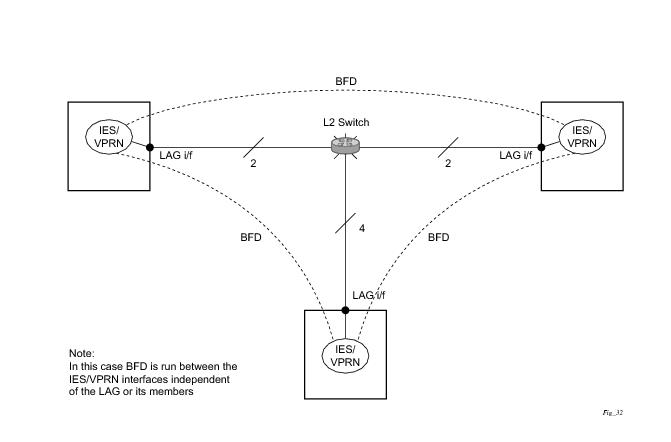
In addition to the typical asynchronous mode, there is also an echo function defined within RFC 5880,
Bi-directional Forwarding Detection, that allows either of the two systems to send a sequence of BFD echo packets to the other system, which loops them back within that system’s forwarding plane. If a number of these echo packets are lost then the BFD session is declared down.
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|Vers | Diag |Sta|P|F|C|A|D|R| Detect Mult | Length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| My Discriminator |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Your Discriminator |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Desired Min TX Interval |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Required Min RX Interval |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Required Min Echo RX Interval |
static-route {ip-prefix/prefix-length|
ip-prefix netmask } next-hop
ip-int-name|ip-address validate-next-hop
When an IPv4 packet is received on an ingress network interface, a subscriber IES interface, or a regular IES interface, the lookup of the packet by the ingress IOM will result in the packet being sent labeled with the label stack corresponding to the NHLFE of the LDP LSP when the preferred RTM entry corresponds to an LDP shortcut.
When ECMP is enabled and multiple equal-cost next-hops exit for the IGP route, the ingress IOM will spray the packets for this route based on hashing routine currently supported for IPv4 packets.
config>router>bgp>next-hop-resolution>shortcut-tunnel
family ipv4
resolution-filter ldp
You must use the fec-originate command to generate bindings for all non-local routes for which this node acts as an egress LER for the corresponding LDP FEC. Specifically, this feature must support the FEC origination of IGP learned routes and subscriber/host routes statically configured or dynamically learned over subscriber IES interfaces.
|
•
|
Confederation — (Optional) Creates confederation autonomous systems within an AS to reduce the number of IBGP sessions required within an AS.
|