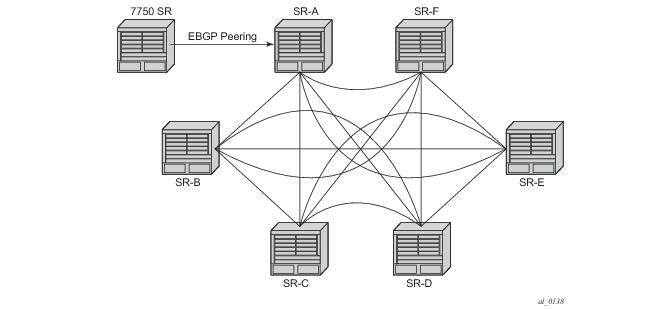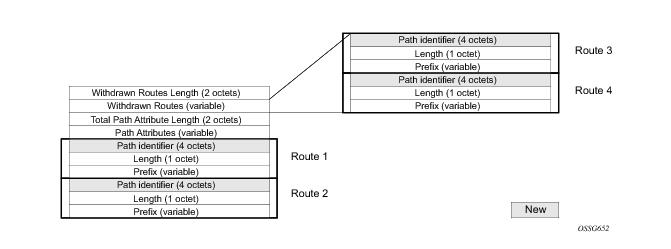
In SR-OS a BGP session is configured using the neighbor command. This command accepts either an IPv4 or IPv6 address, which allows the session transport to be IPv4 or IPv6. By default 7x50 is the
active side of TCP connections to remote neighbors, meaning that as soon as a session leaves the
Idle state 7x50 attempts to setup an outgoing TCP connection to the remote neighbor in addition to listening on TCP port 179 for an incoming connection from the peer. If required, a BGP session can be configured for
passive mode so that the 7x50 router only listens for an incoming connection and does not attempt to setup the outgoing connection. The source IP address used to setup the TCP connection to the peer can be configured explicitly using the
local-address command. If a
local-address is not configured then the source IP address is determined as follows:
|
•
|
Idle. This is the state of a BGP session when it is administratively disabled (with a shutdown command). In this state no incoming TCP connection is accepted from the peer. When the session is administratively enabled it transitions out of the Idle state immediately. When the session is restarted automatically it may not leave the Idle state immediately if damp-peer-oscillations is cnfigured. damp-peer-oscillations holds a session in the Idle state for exponentially increasing amounts of time if the session is unstable and resets frequently.
|
|
•
|
Connect. This is the state of a BGP session when the router, acting in active mode, is attempting to establish an outbound TCP connection with the remote peer.
|
|
•
|
Active. This is the state of a BGP session when the router is listening for an inbound TCP connection attempt from the remote peer.
|
|
•
|
OpenSent. This is the state of a BGP session when the router has sent an OPEN message to its peer in reaction to successful setup of the TCP connection and is waiting for an OPEN message from the peer.
|
|
•
|
OpenConfirm. This is the state of a BGP session after the router has received an acceptable OPEN message from the peer and sent a KEEPALIVE message in response and is waiting for a KEEPALIVE message from the peer. TCP connection collision procedures may be performed at this stage. Refer to RFC 4271 for more details.
|
|
•
|
Established. This is the state of a BGP session after the router has received a KEEPALIVE message from the peer. In this state BGP can advertise and withdraw routes by sending UPDATE messages to its peer.
|
When any one or these mechanisms is triggered the session immediately returns to the Idle state and a new session is attempted. Peer tracking, BFD and fast external failover are described in more detail in the following sections.
When peer tracking is enabled on a session the neighbor IP address is tracked in the routing table; if a failure occurs and there is no longer any IP route matching the neighbor address or else if the longest prefix match (LPM) route is rejected by the configurable peer-tracking-policy then after a 1 second delay the session is taken down. By default peer-tracking is disabled on all sessions. The default peer-tracking policy allows any type of route to match the neighbor IP address except aggregate routes and LDP shortcut routes.
On 7x50 routers BGP graceful restart is enabled on one or more BGP sessions by configuring the graceful-restart command in the global, group or neighbor context. The command causes the GR capability to be advertised and enables helper mode support for IPv4 (AFI1, SAFI1), IPv6 (AFI 2, SAFI1), VPN-IPv4 and VPN-IPv6 routes. Note that the GR capability advertised by a 7x50 router does not list the supported AFI/SAFI unless
enable-notification is configured.
|
•
|
Sent NOTIFICATION message (only if enable-notification is configured under graceful-restart, and the peer set the ‘N’ bit in its GR capability, and the NOTIFICATION is not a Cease with subcode Hard Reset)
|
|
•
|
Received NOTIFICATION message (only if enable-notification is configured under graceful-restart, and the peer set the ‘N’ bit in its GR capability, and the NOTIFICATION is not a Cease with subcode Hard Reset)
|
As soon as the failure is detected the helping 7x50 router marks the received IPv4, IPv6, VPN-IPv4 and VPN-IPv6 routes from the peer as ‘stale’ and starts a restart timer. (As noted above the ‘stale’ state is not factored into the BGP decision process and not made visible to other routers in the network.) The restart timer derives its initial value from the Restart Time carried in the peer’s last GR capability. (The default Restart Time advertised by 7x50 routers is 300 seconds but this can be changed using the restart-time command.) When the restart timer expires helping stops if the session has not yet re-established. If the session is re-established before the restart timer expires and the new GR capability from the restarting router indicates that forwarding state was preserved then helping continues and the peers exchange routes per the normal procedure. When each router has advertised all its routes for a particular address family it sends an
End-of-RIB marker (EOR) for the address family. The EOR is a minimal UPDATE message with no reachable or unreachable NLRI for the AFI/SAFI. When the helping router receives an EOR it deletes all remaining stale routes of the AFI/SAFI that were not refreshed in the most recent set of UPDATE messages; there is an upper limit on the amount of time that routes can remain stale (before being deleted if they were not refreshed) and this is configurable using the
stale-routes-time.
On 7x50 routers TTL security is enabled using the ttl-security command. This command requires a minimum TTL value to be specified. When TTL security is enabled on a BGP session the IP TTL values in packets that are supposedly coming from the peer are compared (in hardware) to the configured minimum value and if there is a discrepancy the packet is discarded and a log is generated. TTL security is used most often on single-hop EBGP sessions but it can be used on multi-hop EBGP and IBGP sessions as well.
In SR-OS every neighbor (and hence BGP session) is configured under a group. A group is a CLI construct that saves configuration effort when multiple peers have a similar configuration; in this situation the common configuration commands can be configured once at the group level and need not be repeated for every neighbor. A single BGP instance can support many groups and each group can support many peers. Most SR-OS commands that are available at the
neighbor level are also available at the
group level.
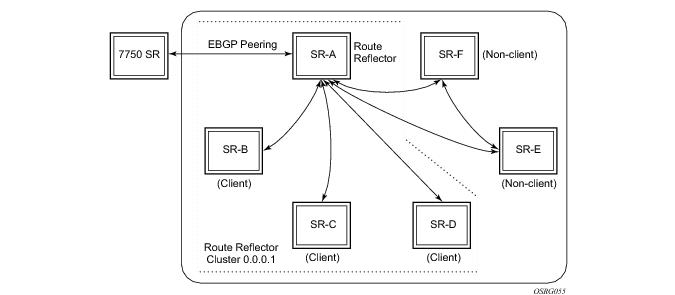
A route reflector provides route reflection service to IBGP peers called clients. Other IBGP peers of the RR are called
non-clients. An RR and its
client peers form a
cluster. A large AS can be sub-divided into multiple clusters, each identified by a unique 32-bit
cluster ID. Each cluster contains at least one route reflector which is responsible for redistributing routes to its clients. The
clients within a cluster do not need to maintain a full IBGP mesh between each other; they only require IBGP sessions to the route reflector(s) in their cluster. (If the clients within a cluster are fully meshed consider using the
disable-client-reflect functionality.) The
non-clients in an AS must be fully meshed with each other.
Figure 27 depicts the same network as
Figure 26 but with route reflectors deployed to eliminate the IBGP mesh between SR-B, SR-C, and SR-D. SR-A, configured as the route reflector, is responsible for reflection routes to its clients SR-B, SR-C, and SR-D. SR-E and SR-F are non-clients of the route reflector. As a result, a full mesh of IBGP sessions must be maintained between SR-A, SR-E and SR-F.
A 7x50 router becomes a route reflector whenever it has one or more client IBGP sessions. A client IBGP session is created with the cluster command, which also indicates the cluster ID of the client. Typical practice is to use the router ID as the cluster ID, but this is not necessary.
|
•
|
If the best and valid path for an NLRI is learned from a client and disable-client-reflect is NOT configured then advertise that route to all clients, non-clients and EBGP peers (as allowed by policy). If the client that advertised the best and valid path is a neighbor to which the split-horizon command (at the bgp, group or neighbor level) applies then the route is not advertised back to the sending client. In the route that is reflected to clients and non-clients:
|
|
•
|
If the best and valid path for an NLRI is learned from a client and disable-client-reflect is configured then advertise that route to all clients in other clusters, non-clients and EBGP peers (as allowed by policy). In the route that is reflected to clients in other clusters and non-clients:
|
The ORIGINATOR_ID and CLUSTER_LIST attributes allow BGP to detect the looping of a route within the AS. If any router receives a BGP route with an ORIGINATOR_ID attribute containing its own BGP identifier the route is considered invalid. In addition if a route reflector receives a BGP route with a CLUSTER_LIST attribute containing a locally configured cluster ID the route is considered
invalid. Invalid routes are not installed in the route table and not advertised to other BGP peers.
If the AS number is changed at the router level (config>
router) the new AS number is not used until the BGP instance is restarted either by administratively disabling and enabling the BGP instance or by rebooting the system with the new configuration.
In recognition of these points and the general trend towards more flexibility in BGP error handling SR-OS supports a BGP configuration option called update-fault-tolerance that allows the operator to decide whether the router should apply new or legacy error handling procedures to UPDATE message errors. If
update-fault-tolerance is configured then non-critical errors as described above are handled using the “treat-as-withdraw” or “attribute-discard” approaches to error handling; these approaches do not cause a session reset. If
update-fault-tolerance is not configured then legacy procedures continue to apply and all errors (critical and non-critical) trigger a session a reset.
|
•
|
Well-known mandatory. These attributes must be recognized by all BGP routers and must be present in every Update message that advertises reachable NLRI towards a certain type of neighbor (EBGP or IBGP).
|
|
•
|
Well-known discretionary. These attributes must be recognized by all BGP routers but are not required in every Update message.
|
|
•
|
Optional transitive. These attributes are allowed to be unrecognized by some BGP routers. If a BGP router does not recognize one of these attributes it accepts it, passes it on to other BGP peers, and sets the Partial bit to 1 in the attribute flags byte.
|
|
•
|
Optional non-transitive. These attributes are allowed to be unrecognized by some BGP routers. If a BGP router does not recognize one of these attributes it is quietly ignored and not passed on to other BGP peers.
|
When a BGP router receives a route containing one of its own Autonomous System numbers (local or global or confederation ID) in the AS_PATH the route is normally considered invalid for reason of an AS path loop. However SR-OS provides a
loop-detect command that allows this check to be bypassed. If it known that advertising certain routes to an EBGP peer will result in an AS path loop condition and yet there is no loop (assured by other mechanisms, such as the Site of Origin (SOO) extended community) then
as-override can be configured on the advertising router instead of disabling loop detection on the receiving router. The
as-override command replaces all occurrences of the peer AS in the AS_PATH with the advertising router’s local AS.
When as-override is configured on a PE-CE EBGP session the PE rewrites the customer ASN in the AS Path with the VPRN AS number as the route is advertised to the CE.
The description in the previous section does fully explain the reasons for using local-as. This BGP feature facilitates the process of changing the ASN of all the routers in a network from one number to another. This may be necessary if one network operator merges with or acquires another network operator and the two BGP networks must be consolidated into one Autonomous System.
|
3.
|
Configure local-as 64501 private no-prepend-global-as on every EBGP session of each RR client migrated in step 2.
|
When a 7x50 router receives a route with an AS4_PATH attribute it attempts to reconstruct the full AS path from the AS4_PATH and AS_PATH attributes, regardless of whether disable-4byte-asn is configured or not. The reconstructed path is the AS path displayed in BGP show commands. If the length of the received AS4_PATH is N and the length of the received AS_PATH is N+t then the reconstructed AS path contains the t leading elements of the AS_PATH followed by all the elements in the AS4_PATH.
|
→
|
If the next-hop-self command is applied to a confederation-EBGP peer this changes the next-hop to the local-address used with that peer.
|
|
→
|
If the next-hop-self command is applied to an IBGP peer this changes the next-hop to the local-address used with that peer, but only if the route came from a confed-EBGP or EBGP peer.
|
|
→
|
If the next-hop-unchanged label-ipv4 command is applied to the receiving IBGP or confederation-EBGP peer this overrides the automatic next-hop-self and causes no modification to the BGP next-hop
|
|
→
|
If the next-hop-self command is applied to the receiving IBGP peer this changes the next-hop to the local-address used with that peer.
|
|
→
|
If the next-hop-self command is applied to the session this changes the next-hop to the IPv4-mapped IPv6 address corresponding to the IPv4 local-address used with the peer.
|
The Multi-Exit Discriminator (MED) attribute is an optional attribute that can be added to routes advertised to an EBGP peer to influence the flow of inbound traffic to the AS. The MED attribute carries a 32-bit metric value. A lower metric is better than a higher metric when MED is compared by the BGP decision process. Unless the always-compare-med command is configured MED is compared only if the routes come from the same neighbor AS. By default if a route is received without a MED attribute it is evaluated by the BGP decision process as though it had a MED containing the value 0, but this can be changed so that a missing MED attribute is handled the same as a MED with the maximum value. SR-OS always removes the received MED attribute when advertising the route to an EBGP peer.
In SR-OS the default local preference is 100 but this can be changed with the local-preference command or using route policies. When a LOCAL_PREF attribute needs to be added to a route because it does not have one (e.g. because it was received from an EBGP peer) the value is the configured or default
local-preference unless overridden by policy.
When an aggregate route is activated by a 7x50 router it is not installed in the forwarding table by default. In general though it is advisable to specify the black-hole next-hop option for an aggregate route so that when it is activated it is installed in the forwarding table with a black-hole next-hop; this avoids the possibility of creating a routing loop. SR-OS also supports the option to program an aggregate route into the forwarding table with an
indirect next-hop; in this case packets matching the aggregate route but not a more-specific contributing route are forwarded towards the indirect next-hop rather than discarded.
|
→
|
If the as-set option is not specified the AS_PATH of the aggregate route starts as an empty AS path and has elements added per the description in the section titled AS Path .
|
|
→
|
If the as-set option is specified and all the contributing routes have the same AS_PATH then the AS_PATH of the aggregate route starts with that common AS_PATH and has elements added per the description in the section titled AS Path .
|
|
→
|
If the as-set option is specified and some of the contributing routes have different AS paths the AS_PATH of the aggregate route starts with an AS_SET and/or an AS_CONFED_SET and then adds elements per the description in the section titled AS Path .
|
The list of AFI/SAFI advertised in the MP-BGP capability of a 7x50 router is controlled primarily by the family command. The AFI/SAFI supported by SR-OS as of Release 12.0R1 and the method of configuring the AFI/SAFI support is summarized in
Table 11.
In the 7x50 implementation AIGP is supported only in the base router BGP instance and only for the following types of routes: IPv4, label-IPv4, IPv6 and 6PE. The AIGP attribute is only sent to peers configured with the aigp command. If the attribute is received from a peer that is not configured for
aigp or if the attribute is received in a non-supported route type the attribute is discarded and not propagated to other peers (but it is still displayed in BGP show commands).
The import command is used to apply one or more policies (up to 15) to a neighbor, group or to the entire BGP context. The
import command that is most-specific to a peer is the one that is applied. An
import policy command applied at the
neighbor level takes precedence over the same command applied at the
group or global level. An
import policy command applied at the
group level takes precedence over the same command specified on the global level. The
import policies applied at different levels are not cumulative. The policies listed in an
import command are evaluated in the order in which they are specified.
|
|
NOTE: The import command can reference a policy before it has been created (as a policy-statement). |
On 7x50 routers the BGP decision process orders valid LOC-RIB routes based on the following sequence of comparisons (if there multiple routes tied at step N then proceed to step N+1):
The always-compare-med command without the
strict-as keyword allows MED to be compared in paths from different neighbor autonomous systems; in this case, if neither
zero or
infinity is part of the command,
zero is inferred, meaning that a route without a MED attribute is handled as though it had a MED with value 0. When the
strict-as keyword is present MED is only compared between paths from the same neighbor AS and in this case
zero or
infinity is mandatory and tells BGP how to interpret paths without a MED attribute.
Table 12 shows how the MED comparison of two paths is influenced by different forms of the
always-compare-med command.
The ignore-nh-metric command allows the step comparing the distance to the BGP next-hop to be skipped. When this command is present in the
config>
service>
vprn context it applies to the comparison of two imported BGP-VPN routes. When this command is present in the
config>
router>
bgp context it applies to the comparison of any two BGP routes received by that instance. And when this command is present in the
config>
service>
vprn>
bgp context it applies to the comparison of two BGP routes learned from VPRN BGP peers (that is, CE peers). In all cases, this option is useful when there are multiple paths for a prefix that are equally preferred up to (but not including) the IGP cost comparison step of the BGP decision process and the network administrator wants all of them to be used for forwarding (
BGP-Multipath).
If the best BGP path for an IPv4 or IPv6 prefix is the most preferred route to the destination it is installed in the IP route table unless disable-route-table-install is configured. The best BGP path is the most preferred route if has the numerically lowest route preference among all routes, of all protocols, to the destination. The default preference value for BGP routes is 170 but this can be changed using the
preference command in the BGP or policy configuration.
|
|
NOTE: Consider configuring the disable-route-table-install command on control-plane route reflectors that are not involved in packet forwarding (i.e. that do not modify the BGP NEXT_HOP); this improves the performance and scalability of such route reflectors. |
If the best path can be installed in the route table and there are other BGP paths (LOC-RIB routes) for the same IPv4 or IPv6 prefix that are nearly as good as the best path the additional paths can also be installed in the route table. This is called BGP-Multipath and it must be explicitly enabled using the
multipath command. The
multipath command specifies the maximum number of BGP paths (up to 32), including the overall best path, that BGP can install in the route table for any particular IPv4 or IPv6 prefix; in this scenario each BGP path is effectively one ECMP next-hop of the IP route and traffic matching the IP route is load-shared across the ECMP next-hops based on a per-packet hash calculation.
By default the hashing is not sticky, meaning that when one or more of the equal-cost BGP next-hops fail all traffic flows matching the route are potentially moved to new BGP next-hops. If required, a BGP route can be marked (using the
sticky-ecmp action in route policies) for sticky ECMP behavior so that BGP next-hop failures are handled by moving only the affected traffic flows to the remaining next-hops as evenly as possible.
|
|
NOTE: In order for BGP to install a route with N ECMP next-hops in the route-table the associated routing instance must have the ecmp command in its configuration and the max number of ECMP next-hops specified as part of that command must have a value greater than or equal to N. |
|
|
NOTE: VPRN routing instances support a special mode of BGP multipath called EIBGP-Multipath. In EIBGP-Multipath BGP routes learned from CE devices that are typically EBGP peers are combined with imported VPN-IP routes that typically come from IBGP peers to form an IP ECMP route. When EIBGP-Multipath is enabled a route is a candidate for installation as an ECMP next-hop if it is the overall best route or else it is tied with the overall best route up to and including the MED step of the BGP decision process. |
SR-OS also supports a feature called IBGP-Multipath. In some topologies a BGP next-hop is resolved by an IP route (for example a static, OSPF or IS-IS route) that itself has multiple ECMP next-hops. When
ibgp-multipath is not configured only one of these ECMP next-hops is programmed as a next-hop of the BGP route in the IOM. But when
ibgp-multipath is configured the IOM attempts to use all of the ECMP next-hops of the resolving route in forwarding.
Although the name of the ibgp-multipath command implies that it is specific to IBGP-learned routes this is not the case; it applies to routes learned from any multi-hop BGP session including routes learned from multi-hop EBGP peers.
It is important to note that BGP-Multipath and
IBGP-Multipath are not mutually exclusive and work together.
BGP-Multipath enables ECMP load-sharing across different BGP next-hops (corresponding to different LOC-RIB routes) and
IBGP-Multipath enables ECMP load-sharing across different IP next-hops of IP routes that resolve the BGP next-hops.
The final point about IBGP-Multipath is that it does not control load-sharing of traffic towards a BGP next-hop that is resolved by a tunnel, such as the case when dealing with BGP shortcuts or labeled routes (VPN-IP, label-IPv4, 6PE). When a BGP next-hop is resolved by a tunnel that supports ECMP the load-sharing of traffic across the ECMP next-hops of the tunnel is automatic.
In SR OS, a Link Bandwidth Extended Community can be added to an IPv4, IPv6, VPN-IPv4 or VPN-IPv6 route using either route policies or the ebgp-link-bandwidth command. The
ebgp-link-bandwidth command is supported in BGP group and neighbor configuration contexts and automatically adds (on import) a Link Bandwidth Extended Community to received routes from single-hop (directly connected) EBGP peers. Note that when a route is advertised to an EBGP peer, the Link Bandwidth Extended Community, if present, is always removed. The Link Bandwidth Extended Community associated with a BGP route can be displayed using the
show router bgp routes commands; for the bandwidth value, the system automatically converts the binary value in the extended community to a decimal number in units of Mbps (1000000 bit/s).
If the best BGP path for a /32 IPv4 prefix is a label-IPv4 route (AFI 1, SAFI 4), and if it has the numerically lowest preference value among all routes (regardless of protocol) for the /32 IPv4 prefix, and if
disable-route-table-install is
not configured, the label-IPv4 route is automatically added, as a
BGP tunnel entry, to the tunnel table. In SR-OS the tunnel-table is used to resolve a BGP next-hop to a tunnel when required by the configuration or the type of route (see the section titled
Next-Hop Resolution for many of these details). BGP tunnels play a key role in the following solutions:
If multipath and
ecmp are configured appropriately a BGP tunnel can be installed in the tunnel table with multiple ECMP next-hops, each one corresponding to a path through a different BGP next-hop; the multipath selection process outlined in the previous section (
BGP Route Installation in the Route Table ) also applies to this case.
For BGP tunnels there is no support for the equivalent of IBGP-Multipath. That is, if a BGP next-hop of the label-IPv4 route in the tunnel table is resolved by an LDP tunnel with multiple ECMP next-hops load-sharing is not supported across the LDP ECMP next-hops; only the first next-hop carries traffic towards the BGP next-hop.
The backup-path command is used in the base router context to control fast reroute on a per-routing instance and per-family (IPv4 and IPv6) basis. The command supports options to enable fast reroute for IPv4 prefixes only, for IPv6 prefixes only, or for all IPv4 and IPv6 prefixes.
The install-backup-path command is used to designate a specific set of IPv4 or IPv6 prefixes that are eligible for BGP fast reroute protection. The command enables a BGP import policy to restrict the set of routes that are programmed with a backup path.
QPPB is enabled on an interface using the qos-route-lookup command. There are separate commands for IPv4 and IPv6 so that QPPB can be enabled in one mode (source or destination or none) for IPv4 packets arriving on the interface and a different mode (source or destination or none) for IPv6 packets arriving on the interface.
Policy accounting is a feature that allows different accounting classes to be associated with IPv4 and IPv6 BGP LOC-RIB routes based on BGP import policy processing. This is done so that per-accounting-class traffic statistics can be collected on policy accounting-enabled interfaces of the router. Policy accounting interfaces are only supported on IOM3 or better cards. The following types of interfaces are supported:
Policy accounting is enabled on an interface using the policy-accounting command. The name of a policy accounting template must be specified. Each policy accounting template contains a list of
source classes and
destination classes. 7x50 routers support up to 255 different source classes and up to 255 different destination classes. Each source class is identified by an index number (1-255) and each destination class is identified by an index number (1-255). The policy accounting template tells the IOM what accounting classes to collect stats for on a policy accounting interface. SR-OS supports up to 1024 different templates, depending on the chassis type.
In SR-OS route flap damping is configurable; by default it is disabled. It can be enabled on EBGP and confed-EBGP sessions by including the damping command in their group or neighbor configuration. The
damping command has no effect on IBGP sessions. When a route of any type (any AFI/SAFI) is received on a non-IBGP session that has
damping enabled:
The export command is used to apply one or more policies (up to 15) to a neighbor, group or to the entire BGP context. The
export command that is most-specific to a peer is the one that is applied. An
export policy command applied at the
neighbor level takes precedence over the same command applied at the
group or global level. An
export policy command applied at the
group level takes precedence over the same command specified on the global level. The
export policies applied at different levels are not cumulative. The policies listed in an
export command are evaluated in the order in which they are specified.
|
|
NOTE: The export command can reference a policy before it has been created (as a policy-statement). |
In SR-OS the send/receive capability for ORF type 3 is configurable (with the send-orf and
accept-orf commands) but the setting applies to all supported address families.
In SR-OS the type-3 ORF entries that are sent to a peer can be generated dynamically (if no Route Target Extended Communities are specified with the send-orf command) or else specified statically. Dynamically generated ORF entries are based on the route targets that are imported by all locally-configured VPRNs.
In SR-OS the capability to exchange RTC routes is advertised when the route-target keyword is added to the relevant
family command. RT-constrain is supported on EBGP and IBGP sessions of the base router instance. On any particular session either ORF or RT-constrain may be used but not both; if RT-constrain is configured the ORF capability is not announced to the peer.
SR-OS also supports a group/neighbor level default-route-target command that causes the 7x50 router to generate and send a 0:0:0/0 default RTC route to one or more peers. Sending the default RTC route to a peer conveys a request to receive all VPN routes from that peer. The
default-route-target command is typically configured on sessions that a route reflector has with its PE clients. Note that a received default RTC route is never propagated to other routers.
According to the BGP standard (RFC 4271) a BGP router should not send updated reachability information for an NLRI to a BGP peer until a certain period of time, called the Min Route Advertisement Interval, has elapsed since the last update. The RFC suggests the MRAI should be configurable per peer but does not propose a specific algorithm and therefore MRAI implementation details vary from one router operating system to another.
In SR-OS the MRAI is configurable, on a per-session basis, using the min-route-advertisment command. The
min-route-advertisement command can be configured with any value between 1 and 255 seconds and the setting applies to all address families. The default value is 30 seconds, regardless of the session type (EBGP or IBGP). When all RIB-OUT routes have been sent to a peer the MRAI timer associated with that session is started and when it expires the RIB-OUT changes that have accumulated while the timer was running trigger the sending of a new set of UPDATE messages to the peer.
It may be important to send UPDATE messages that advertise new NLRI reachability information more frequently for some address families than others. SR-OS offers a rapid-update command that overrides the peer-level
min-route-advertisement time and applies the minimum setting to routes belonging to specific address families; routes of other address families continue to be advertised according to the session-level MRAI setting. The address families that can be configured with
rapid-update support are:
Standard BGP rules do not allow a BGP route to be advertised to peers unless it is the best path and it is ‘used’ locally. An IPv4 or IPv6 BGP route is considered ‘used’ if it is the active route to the destination in the route table. If there a multiple routes from different protocols for the same IP destination the BGP route is ‘used’ only if it has the numerically lowest route preference among all these routes; for further details refer to the section titled
BGP Route Installation in the Route Table .
In some cases it may be useful to advertise the best BGP path to peers despite the fact that is inactive —i.e. because there are one or more lower-preference non-BGP routes to the same destination and one of these other routes is the
active route. One way SR-OS supports this flexibility is using the
advertise-inactive command; other methods include
Best-External and
Add-Paths.
As a global BGP configuration option the advertise-inactive command applies to all IPv4 and IPv6 routes and all sessions that advertise these routes. When the command is configured and the best BGP path is inactive it is automatically advertised to every peer unless rejected by a BGP export policy.
Best-External is a BGP enhancement that allows a BGP speaker to advertise to its IBGP peers its best “external” route for a prefix/NLRI when its best overall route for the prefix/NLRI is an “internal” route. This is not possible in a normal BGP configuration because the base BGP specification prevents a BGP speaker from advertising a non-best route for a destination.
In certain topologies Best-External can improve convergence times, reduce route oscillation and allow better loadsharing. This is achieved because routers internal to the AS have knowledge of more exit paths from the AS. Enabling
Add-Paths on border routers of the AS can achieve a similar result but
Add-Paths introduces NLRI format changes that must be supported by BGP peers of the border router and therefore has more interoperability constraints than
Best-External (which requires no messaging changes).
Best-External is supported in the base router BGP context. (A related feature is also supported in VPRNs; consult the Services Guide for more details.) It is configured using the
advertise-external command, which provides IPv4 and IPv6 as options.
Best-External for IPv4 applies to both regular IPv4 unicast routes as well as labeled-IPv4 (SAFI4) routes. Similarly,
Best-External for IPv6 applies to both regular IPv6 unicast routes as well as 6PE (SAFI4) routes.
The advertisement rules when advertise-external is enabled can be summarized as follows:
|
•
|
If a router has advertise-external enabled and its best overall route is a route from an IBGP peer then this best route is advertised to EBGP and confed-EBGP peers, and the “best external” route is advertised to IBGP peers. The “best external” route is the one found by running the BGP path selection algorithm on all LOC-RIB paths except for those learned from the IBGP peers.
|
|
|
NOTE: A 7x50 route reflector with advertise-external enabled does not include IBGP routes learned from other clusters in its definition of ‘external’. |
|
•
|
If a router has advertise-external enabled and its best overall route is a route from an EBGP peer then this best route is advertised to EBGP, confed-EBGP, and IBGP peers.
|
|
•
|
If a router has advertise-external enabled and its best overall route is a route from a confed-EBGP peer in member AS X then this best route is advertised to EBGP, IBGP peers and confed-EBGP peers in all member AS except X and the “best external” route is advertised to confed-EBGP peers in member AS X. In this case the “best external” route is the one found by running the BGP path selection algorithm on all RIB-IN paths except for those learned from member AS X.
|
Add-Paths is a BGP enhancement that allows a BGP router to advertise multiple distinct paths for the same prefix/NLRI. This provides a number of potential benefits, including reduced routing churn, faster convergence, and better loadsharing.
Add-Paths is only supported by the base router BGP instance and the EBGP and IBGP sessions it forms with other
Add-Paths capable peers. The ability to send and receive multiple paths per prefix is configurable per family, with the supported options being:
The LOC-RIB may have multiple paths for a prefix. The path selection mode refers to the algorithm used to decide which of these paths to advertise to an Add-Paths peer. SR-OS supports the Add-N path selection algorithm described in draft-ietf-idr-add-paths-guidelines. The Add-N algorithm selects, as candidates for advertisement, the N best paths with unique BGP next-hops. In the SROS implementation, the default value of N is configurable, per address-family, at the BGP instance, group and neighbor levels, however, this default value can be overridden, for specific prefixes, using route policies. The maximum number of paths to advertise for a prefix to an Add-Paths neighbor is the value N assigned by a BGP import policy to the best path for P, otherwise it defaults to the neighbor, group or instance level configuration of N for the address family to which P belongs.
To apply split-horizon behavior to routes learned from RR clients, confed-EBGP peers or (non-confed) EBGP peers the split-horizon command must be configured in the appropriate contexts; it is supported at the global BGP,
group and
neighbor levels. When
split-horizon is enabled on these types of sessions it only prevents the advertisement of a route back to its originating peer; for example SR-OS does not prevent the advertisement of a route learned from one EBGP peer back to different EBGP peer in the same neighbor AS.
The shortcut-tunnel and
family nodes are contexts to configure the binding of BGP unlabelled routes to tunnels.
The default resolution of a BGP unlabelled route is performed in RTM. The user must configure the resolution option to enable resolution to tunnels in TTM. If the
resolution option is explicitly set to
disabled, the binding to tunnel is removed and resolution resumes in RTM to IP next-hops.
If resolution is set to
any, any supported tunnel type in BGP shortcut context will be selected following TTM preference. If one or more explicit tunnel types are specified using the
resolution-filter option, then only these tunnel types will be selected again following the TTM preference.
|
•
|
The rsvp value instructs BGP to search for the best metric RSVP LSP to the address of the BGP next-hop. This address can correspond to the system interface or to another loopback used by the BGP instance on the remote node. The LSP metric is provided by MPLS in the tunnel table. In the case of multiple RSVP LSPs with the same lowest metric, BGP selects the LSP with the lowest tunnel-id.
|
|
•
|
The ldp value instructs BGP to search for an LDP LSP with a FEC prefix corresponding to the address of the BGP next-hop.
|
|
•
|
The bgp value instructs BGP to search for a BGP LSP with a RFC 107 label route prefix matching the address of the BGP next-hop.
|
|
•
|
When the sr-isis or sr-ospf value is enabled, an SR tunnel to the BGP next-hop is selected in the TTM from the lowest preference ISIS or OSPF instance and if many instances have the same lowest preference from the lowest numbered IS-IS or OSPF instance
|
The user must set resolution to
filter to activate the list of tunnel-types configured under
resolution-filter.
If disallow-igp is enabled, the BGP route will not be activated using IP next-hops in RTM if no tunnel next-hops are found in TTM.
Note that the label-route-transport-tunnel and
family CLI nodes are contexts used to configure the binding of IPv4 or IPv6 BGP labeled routes to tunnels.
The label-route-transport-tunnel command provides a separate control for the different families of RFC 3107 BGP label routes: core IPv4 routes and inter-AS option B vpn-ipv4 and vpn-ipv6 routes at ASBR.
If the resolution option is explicitly set to
disabled, the default binding to LDP tunnel resumes. If
resolution is set to
any, any supported tunnel type in BGP label route context will be selected following TTM preference.
|
•
|
The rsvp value instructs BGP to search for the best metric RSVP LSP to the address of the BGP next-hop. This address can correspond to the system interface or to another loopback used by the BGP instance on the remote node. The LSP metric is provided by MPLS in the tunnel table. In the case of multiple RSVP LSPs with the same lowest metric, BGP selects the LSP with the lowest tunnel-id.
|
|
•
|
The ldp value instructs BGP to search for an LDP LSP with a FEC prefix corresponding to the address of the BGP next-hop.
|
|
•
|
When the sr-isis or sr-ospf value is enabled, an SR tunnel to the BGP next-hop is selected in the TTM from the lowest preference ISIS or OSPF instance. If many instances have the same lowest preference from the lowest numbered IS-IS or OSPF instance
|
If one or more explicit tunnel types are specified using the resolution-filter option, then only these tunnel types will be selected again following the TTM preference.
The user must set resolution to
filter to activate the list of tunnel-types configured under
resolution-filter.
The auto-bind-tunnel node is simply a context to configure the binding of VPRN or BGP EVPN routes to tunnels. The user must configure the
resolution option to enable auto-bind resolution to tunnels in TTM. If the
resolution option is explicitly set to disabled, the auto-binding to tunnel is removed.
If resolution is set to
any, any supported tunnel type in VPRN or BGP EVPN context will be selected following TTM preference. If one or more explicit tunnel types are specified using the
resolution-filter option, then only these tunnel types will be selected again following the TTM preference.
|
•
|
The rsvp value instructs BGP to search for the best metric RSVP LSP to the address of the BGP next-hop. This address can correspond to the system interface or to another loopback used by the BGP instance on the remote node. The LSP metric is provided by MPLS in the tunnel table. In the case of multiple RSVP LSPs with the same lowest metric, BGP selects the LSP with the lowest tunnel-id.
|
|
•
|
The ldp value instructs BGP to search for an LDP LSP with a FEC prefix corresponding to the address of the BGP next-hop.
|
|
•
|
When the sr-isis or sr-ospf value is enabled, a SR tunnel to the BGP next-hop is selected in the TTM from the lowest preference ISIS or OSPF instance. If many instances have the same lowest preference from the lowest numbered IS-IS or OSPF instance.
|
|
•
|
The gre value instructs BGP to use a GRE encapsulated tunnel to the address of the BGP next-hop.
|
The user must set resolution to
filter to activate the list of tunnel-types configured under
resolution-filter.
When an explicit SDP to a BGP next-hop is configured in a VPRN or BGP EVPN service (configure>service>vprn>spoke-sdp), it overrides the
auto-bind-tunnel selection for that BGP next-hop only. There is no support for reverting automatically to the
auto-bind-tunnel selection if the explicit SDP goes down. The user must delete the explicit spoke-SDP in the VPRN or BGP EVPN service context to resume using the
auto-bind-tunnel selection for the BGP next-hop.
Flow-spec is supported for both IPv4 and IPv6. To exchange IPv4 Flow-spec routes with a BGP peer the flow-ipv4 keyword must be part of the
family command that applies to the session and to exchange IPv6 Flow-spec routes with a BGP peer
flow-ipv6 must be present in the
family configuration.
Table 16 summarizes the actions that may be associated with an IPv4 or IPv6 flow route and how each type of action is encoded.
|
2.
|
The flowspec-validate command is enabled, the flow route has a destination prefix subcomponent D, and the flow route was received from a peer that did not advertise the best route to D and all more-specific prefixes.
|
The none value reverts to the default mode which disables TTL propagation from the IP header to the labels in the transport label stack.
The none value reverts to the default mode which disables TTL propagation. Note this changes the existing default behavior which propagates the TTL to the transport label stack. When a customer upgrades, the new default becomes in effect. The above commands do not have a no version.
7x50 routers support BGP prefix origin validation for IPv4 and IPv6 routes received by the base router BGP instance from selected peers. When prefix origin validation is enabled on a session using the enable-origin-validation command every received IPv4 and/or IPv6 route received from the peer is checked to determine whether the origin AS is valid for the received prefix. The origin AS is generally the right most AS in the AS_PATH attribute and indicates the autonomous system that originated the route.
Static VRP entries are configured using the static-entry command available in the
config>router>origin-validation context of the base router. In SR-OS, a static entry can express that a specific prefix and origin AS combination is either valid or invalid.
|
•
|
A route is matched by a VRP entry if the prefix bits in the route match the prefix bits in the VRP entry (up to its min prefix length), AND the route prefix length is greater than or equal to the VRP entry min prefix length, AND the route prefix length is less than or equal to the VRP entry max prefix length, AND the origin AS of the route matches the origin AS of the VRP entry.
|
|
•
|
A route is covered by a VRP entry if the prefix bits in the route match the prefix bits in the VRP entry (up to its min prefix length), AND the route prefix length is greater than or equal to the VRP entry min prefix length, AND the VRP entry type is static-valid or dynamic.
|
The origin validation state of a route can affect its ranking in the BGP decision process. When origin-invalid-unusable is configured, all routes that have an origin validation state of ‘Invalid’ are considered unusable by the best path selection algorithm, that is, they cannot be used for forwarding and cannot be advertised to peers.
If origin-invalid-unusable is not configured then routes with an origin validation state of ‘Invalid’ are compared to other ‘usable’ routes for the same prefix according to the BGP decision process.
When compare-origin-validation-state is configured a new step is added to the BGP decision process after removal of invalid routes and before the comparison of Local Preference. The new step compares the origin validation state, so that a route with a ‘Valid’ state is preferred over a route with a ‘Not-Found’ state, and a route with a ‘Not-Found’ state is preferred over a route with an ‘Invalid’ state assuming that these routes are considered ‘usable’. The new step is skipped if the
compare-origin-validation-state command is not configured.
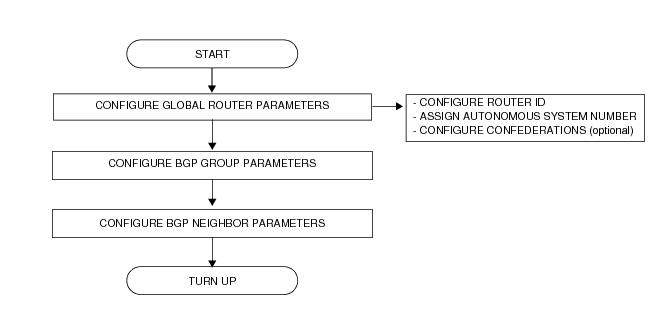
Figure 29 displays the process to provision basic BGP parameters.
|
•
|
If no import route policy statements are specified, then all BGP routes are accepted.
|
|
•
|
If no export route policy statements specified, then all best and used BGP routes are advertised and non-BGP routes are not advertised.
|
When the value set using SNMP is within the IETF allowed values and outside the SR OS values as specified in
Table 17 and
Table 18, a log message is generated.
The log messages that display are similar to the following log messages: