In non-LNS ESM environment, the existing agg-rate-limit command is applied to the subscriber within the subscriber profile (sub-profile). However, the agg-rate-limit cannot be the highest level in subscriber’s HQoS hierarchy. The agg-rate-limit will be only effective if it is applied to a subscriber that is tied to a port-scheduler . In other words, the port-scheduler in subscriber’s HQoS hierarchy is a prerequisite for successful operation of agg-rate-limit. On regular MDAs, the port-scheduler is directly applied to a physical port. The port between the carrier IOM and the ISA is an internal port that is not exposed in the CLI. This is shown in
Figure 70.
For example, the encap-offset command will cause the queue rates, the billing stats and the agg-rate-limit to be based on the wire encapsulation in the last mile. For ATM in the last mile, the wire overhead will be calculated per each packet (including ATM cellification overhead and padding). For Ethernet in the first mile, a fixed last mile encapsulation (defined with the
encap-offset command or the RFC 5515,
Layer 2 Tunneling Protocol (L2TP) Access Line Information Attribute Value Pair (AVP) Extensions) wire overhead will be considered in rate calculation. In essence the length of the PPPoE Ethernet QinQ header that is used on the link between the carrier IOM and the ISA will be artificially modified so that it matches the length of the header used in the last mile. The net effect is rate shaping on LNS based on the virtual packet length that is present in the last mile.
In the absence of the encap-offset command, the queue rates, the billing stats and the agg-rate-limit rates will be based on the Ethernet QinQ encapsulation between the carrier IOM and the ISA. Depending on the queue-frame-based-accounting configuration option, those rates can be wire based or data based (Layer 2 encapsulation only).
There are two major tasks associated with LFI
1 on the LNS:
High priority traffic within the bundle is classified into the high priority queue. This type of traffic is not MLPPPoX encapsulated unless its packet size exceeds the link MTU as described in MLPPPoX Fragmentation, MRRU and MRU Considerations . Low priority traffic is classified into a low priority queue and is always MLPPPoX encapsulated. In case that the high priority traffic becomes MLPPPoX encapsulated/fragmented, the MLPPPoX processing module (BB-ISA) will consider it as low-priority. The assumption is that the high priority traffic is small in size and consequently MLPPPoX encapsulation/fragmentation an degradation in priority can be avoided. The aggregate rate of the MLPPPoX bundle is on-the-wire rate of the last mile as shown in Figure 3.
As shown in Figure 70 (point 2) the first fragment F1 is sent out immediately (transmission delay at 10G is in the 1us range). The transmission of the next fragment F2 is delayed by 50ms. While the transmission of the second fragment F2 is being delayed, the two high priority packets (P1 and P2 in red) are received by the BB-ISA and are immediately transmitted ahead of fragments F2 and F3. This approach relies on the imperfection of the IOM shaper which is releasing traffic in bursts (P2 and P3 right after P1). The burst size is dependent on the depth of the rate token bucket associated with the IOM shaper.
Note on the AN-RG link in Figure 70 that packets P2 and P3 are ahead of fragments F2 and F3. Therefore the delay incurred on this link by the low priority packets is never greater than the transmission delay of the first fragment (50ms). The remaining two fragments, F2 and F3, can be queued and further delayed by the transmission time of packets P2 and P3 (which is normally small, in our example 3ms for each).
We will not support multiclass MLPPP (RFC 2686, The Multi-Class Extension to Multi-Link PPP). Multiclass MLPPP would require another level of intelligent queuing in the BB-ISA which we do not have.
PPP/PPPoE sessions are by default load balanced across multiple BB-ISAs (max 6) in the same group. The load balancing algorithm considers the number of active session on each BB-ISA in the same group
2.
In a per fragment/packet load sharing algorithm, there is always the possibility that there is uneven load utilization between the member links. A single link overload will most likely go unnoticed in the network all the way to the Access Node. The access node is the only node in the network that actually has multiple physical links connected to it. All other session-aware nodes
3 (LAC and LNS) only see MLPPPoX as a bundle with multiple sessions without any mechanism to shape traffic per physical link.
The priority of the forwarding class in regular QoS (on IOM) is determined by the properties
4 of the queue to which the forwarding class is mapped. In contracts, traffic prioritization in LFI domain (in BB-ISA) is determined by the outer dot1p bits that are set by the carrier IOM while transmitting packets towards the BB-ISA. The outer dot1p bits are marked based on the forwarding class information determined by classification/re-classification on ingress/carrier IOM. This marking of outer dot1p bits in the Ethernet header between the carrier IOM and the BB-ISA is fixed and defined in the default sap-egress LNS ESM policy 65537. The marking definition is as follows:
In LFI (on BB-ISA), dot1p bits [0,1,2 and 3] are considered low priority while dot1p bits (4,5,6 and 7) are considered high priority. Consequently, forwarding classes BE, L2, AF and L1 are considered low priority while forwarding classes H2, EF, H1 and NC are considered high priority. High priority traffic
5 will be interleaved with low priority traffic.
ip-only type mirrors are supported on MLPPPoX bundles.




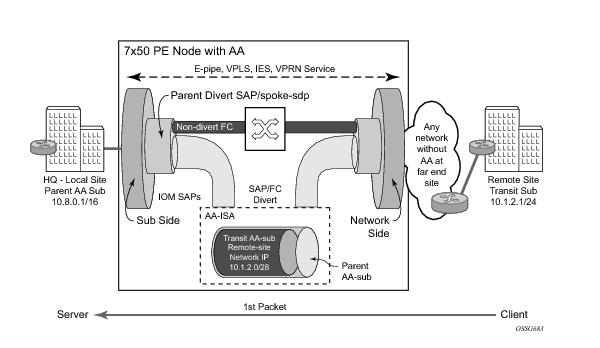 Figure 70: QoS Hierarchy on LNSCLI Syntax: configureCLI Syntax: configureFor example, the encap-offset command will cause the queue rates, the billing stats and the agg-rate-limit to be based on the wire encapsulation in the last mile. For ATM in the last mile, the wire overhead will be calculated per each packet (including ATM cellification overhead and padding). For Ethernet in the first mile, a fixed last mile encapsulation (defined with the encap-offset command or the RFC 5515, Layer 2 Tunneling Protocol (L2TP) Access Line Information Attribute Value Pair (AVP) Extensions) wire overhead will be considered in rate calculation. In essence the length of the PPPoE Ethernet QinQ header that is used on the link between the carrier IOM and the ISA will be artificially modified so that it matches the length of the header used in the last mile. The net effect is rate shaping on LNS based on the virtual packet length that is present in the last mile.The last mile encapsulation information that is used in Last Mile Aware Shaping can be obtained either statically through the explicit value in the encap-offset command or dynamically by the RFC 5515 method (AVP 144 in ICRQ). The latter will be the case if the encap-offset command does not have any explicitly configured value.In the absence of the encap-offset command, the queue rates, the billing stats and the agg-rate-limit rates will be based on the Ethernet QinQ encapsulation between the carrier IOM and the ISA. Depending on the queue-frame-based-accounting configuration option, those rates can be wire based or data based (Layer 2 encapsulation only).CLI Syntax: configureCLI Syntax: configuredst-ip 10.10.10.10 - traffic classification criteria ; in this case LNS tunnel endpoint.CLI Syntax: configureinterface from-lacCLI Syntax: configureThere are two major tasks associated with LFI1 on the LNS:
Figure 70: QoS Hierarchy on LNSCLI Syntax: configureCLI Syntax: configureFor example, the encap-offset command will cause the queue rates, the billing stats and the agg-rate-limit to be based on the wire encapsulation in the last mile. For ATM in the last mile, the wire overhead will be calculated per each packet (including ATM cellification overhead and padding). For Ethernet in the first mile, a fixed last mile encapsulation (defined with the encap-offset command or the RFC 5515, Layer 2 Tunneling Protocol (L2TP) Access Line Information Attribute Value Pair (AVP) Extensions) wire overhead will be considered in rate calculation. In essence the length of the PPPoE Ethernet QinQ header that is used on the link between the carrier IOM and the ISA will be artificially modified so that it matches the length of the header used in the last mile. The net effect is rate shaping on LNS based on the virtual packet length that is present in the last mile.The last mile encapsulation information that is used in Last Mile Aware Shaping can be obtained either statically through the explicit value in the encap-offset command or dynamically by the RFC 5515 method (AVP 144 in ICRQ). The latter will be the case if the encap-offset command does not have any explicitly configured value.In the absence of the encap-offset command, the queue rates, the billing stats and the agg-rate-limit rates will be based on the Ethernet QinQ encapsulation between the carrier IOM and the ISA. Depending on the queue-frame-based-accounting configuration option, those rates can be wire based or data based (Layer 2 encapsulation only).CLI Syntax: configureCLI Syntax: configuredst-ip 10.10.10.10 - traffic classification criteria ; in this case LNS tunnel endpoint.CLI Syntax: configureinterface from-lacCLI Syntax: configureThere are two major tasks associated with LFI1 on the LNS: