To resolve a split-brain DR setup with autoFailover set to false
Overview
Note: All CLI commands should be run on either node1 or node2, i.e. a control-node.
This procedure assumes the following scenario:
-
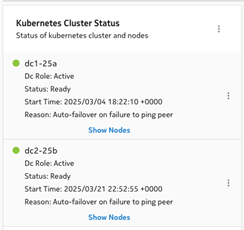
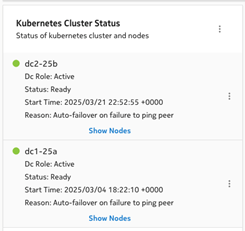
The DR setup has a split-brain situation where both clusters are acting as an active role. This can be checked by logging into both clusters using the clusters’ VIP. In the NSP System Administration System Health dashboard, under the Kubernetes Cluster Status, both clusters should have the “Dc Role” set to “Active”:
cluster dc1-25a
cluster dc2-25b
-
The autoFailiover property is set to disabled on both sites. This can be checked by running the following CLI command on both clusters:
kubectl exec -n $(kubectl get pods -A | awk '/spos-asm/ {print $1;exit}') -it $(kubectl get pods -A | awk '/nspos-asm/ {print $2;exit}') -c nspos-asm-app -- /opt/nsp/os/asm/bin/asmctl autoFailoverStatus
Sample output:
Current Auto-failover is: False
-
Communication between both clusters is fine, and there is no StandbyServerDown alarm shown on either clusters’ current alarms list.

