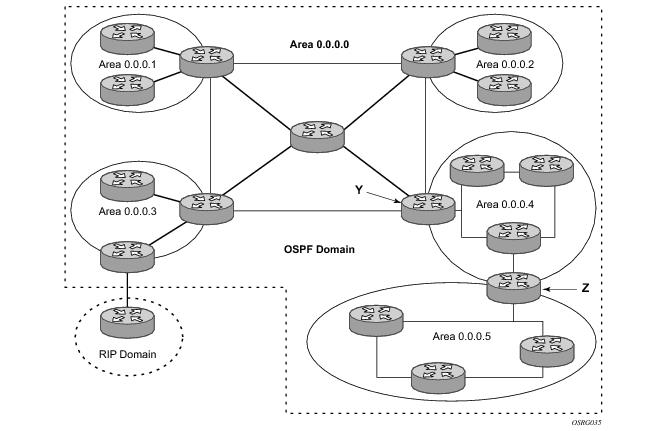
In Figure 6, areas 0.0.0.1, 0.0.0.2 and 0.0.0.5 could be configured as stub areas. A stub area cannot be designated as the transit area of a virtual link and a stub area cannot contain an AS boundary router. An AS boundary router exchanges routing information with routers in other ASs.
In Figure 6, area 0.0.0.3 could be configured as a NSSA area.
The 77x0 PE routers have implemented a version of the BGP/OSPF interaction procedures as defined in RFC 4577, OSPF as the Provider/Customer Edge Protocol for BGP/MPLS IP Virtual Private Networks (VPNs). Features included in this RFC includes:
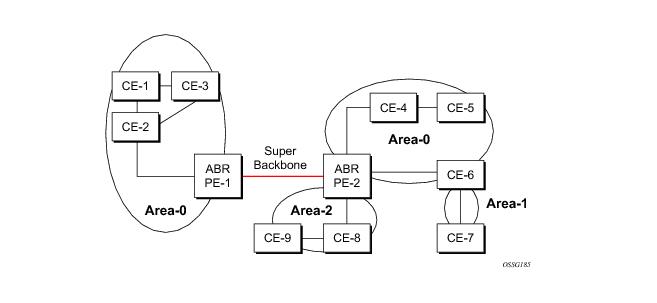
In Figure 7, the PEs are connected to the MPLS-VPN super backbone. In order to be able to distinguish if two OSPF instances are in fact the same and require Type 3 LSAs to be generated, or are two separate routing instances where type 5 external LSAs need to be generated, the concept of a domain-id is introduced.
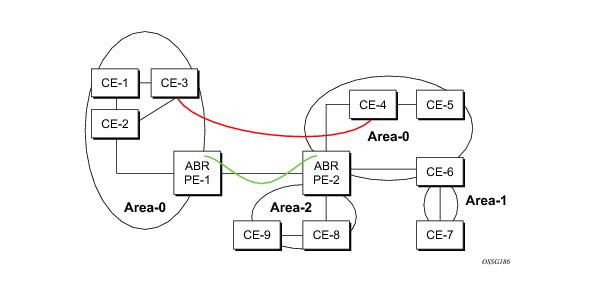
Figure 8 displays the red link between CE-3 and CE-4 could be a low speed OC-3/STM-1 link but because it establishes a intra-area route connection between the CE-3 and CE-4 the potentially high-speed PE-1 to PE-2 connection will not be utilized. Even with a super backbone configuration it is regarded as a inter-area connection.
As the shamlink forms an adjacency over the MPLS-VPRN backbone network, be aware that when protocol-protection is enabled in the config>sys>security>cpu-protection>protocol-protection context, the operator must explicit allow the OSPF packets to be received over the backbone network. This performed using the
allow-sham-links parameter of the
protocol-protection command.
A sham link is only required if a backdoor link (shown as the red link in Figure 8) is present, otherwise configuring an OSPF super backbone will probably suffice.
The re-keying procedure defined in RFC 4552, Authentication/Confidentiality for OSPFv3, supports the following:
Figure 9 displays the Graceful OSPF restart (GRACE) LSA format. See section 2.2 of RFC 5187,
OSPFv3 Graceful Restart.
Grace-LSA TLVs are formatted according to section 2.3.2 of RFC 3630, Traffic Engineering (TE) Extensions to OSPF Version 2. The Grace-LSA TLVs are used to carry the Grace period (type 1) and the reason the router initiated the graceful restart process (type 2).
Figure 6 depicts routers Y and Z as the start and end points of the virtual link while area 0.0.0.4 is the transit area. In order to configure virtual links, the router must be an ABR. Virtual links are identified by the router ID of the other endpoint, another ABR. These two endpoint routers must be attached to a common area, called the transit area. The area through which you configure the virtual link must have full routing information.
If an instance-id is specified, only routes installed by that instance are picked up for announcement. If no
instance-id is specified, then only routes installed by the base instance is will be announced. The
all keyword announces routes installed by all instances of OSPF.
When any of the following events occurs, IGP instructs in the fast path the IOM to enable the LFA backup next-hop:
Next the user enables IP FRR to cause RTM to download to IOM a LFA next-hop, when found by SPF, in addition to the primary next-hop for each prefix in the FIB.
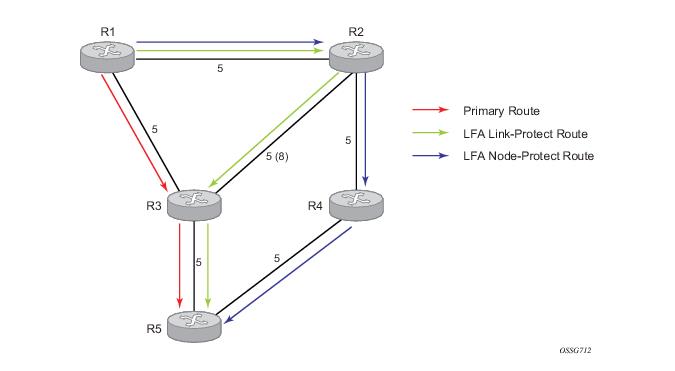
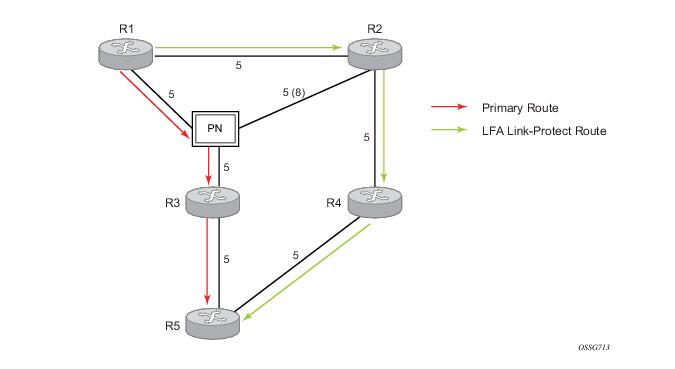
Figure 10 illustrates a simple network topology with point-to-point (P2P) interfaces and highlights three routes to reach router R5 from router R1.
The lfa-protect option allows an LSP to be included in both the main SPF and the LFA SPFs. For a given prefix, the LSP can be used either as a primary next-hop or as an LFA next-hop but not both. If the main SPF computation selected a tunneled primary next-hop for a prefix, the LFA SPF will not select an LFA next-hop for this prefix and the protection of this prefix will rely on the RSVP LSP FRR protection. If the main SPF computation selected a direct primary next-hop, then the LFA SPF will select an LFA next-hop for this prefix but will prefer a direct LFA next-hop over a tunneled LFA next-hop.
The lfa-only option allows an LSP to be included in the LFA SPFs only such that the introduction of IGP shortcuts does not impact the main SPF decision. For a given prefix, the main SPF always selects a direct primary next-hop. The LFA SPF will select a an LFA next-hop for this prefix but will prefer a direct LFA next-hop over a tunneled LFA next-hop.
The commands within the route next-hop policy use the begin-commit-abort model introduced with BFD templates. The following are the steps to create and modify the template:
Once the commit command is issued, IS-IS or OSPF will re-evaluate the templates and if there are any net changes, it will schedule a new LFA SPF to re-compute the LFA next-hop for the prefixes associated with these templates.
The no form of the
admin-group command under the interface deletes one or more of the admin-group memberships of the interface. It deletes all memberships if no group name is specified.
Each group is entered individually. The include-group statement instructs the LFA SPF selection algorithm to pick up a subset of LFA next-hops among the links which belong to one or more of the specified admin groups. A link which does not belong to at least one of the admin-groups is excluded. However, a link can still be selected if it belongs to one of the groups in a
include-group statement but also belongs to other groups which are not part of any
include-group statement in the route next-hop policy.
The pref option is used to provide a relative preference for the admin group to select. A lower preference value means that LFA SPF will first attempt to select a LFA backup next-hop which is a member of the corresponding admin group. If none is found, then the admin group with the next higher preference value is evaluated. If no preference is configured for a given admin group name, then it is supposed to be the least preferred, i.e., numerically the highest preference value.
When evaluating multiple include-group statements within the same preference, any link which belongs to one or more of the included admin groups can be selected as an LFA next-hop. There is no relative preference based on how many of those included admin groups the link is a member of.
The exclude-group statement simply prunes all links belonging to the specified admin group before making the LFA backup next-hop selection for a prefix.
If the same group name is part of both include and
exclude statements, the
exclude statement will win. It other words, the
exclude statement can be viewed as having an implicit preference value of 0.
The no form of the
srlg-group command under the interface deletes one or more of the SRLG memberships of the interface. It deletes all SRLG memberships if no group name is specified.
If the user excluded the interface from LFA using the command loopfree-alternate-exclude, the LFA policy if applied to the interface has no effect.
The default action of the above loopfree-alternate-exclude command when not explicitly specified by the user in the prefix policy is a “reject”. Thus, regardless if the user did or did not explicitly add the statement “default-action reject” to the prefix policy, a prefix which did not match any entry in the policy will be accepted into LFA SPF.
Note that this pruning applies only to IP next-hops. Tunnel next-hops can have the admin-group or SRLG constraint applied to them under MPLS. For instance, If a tunnel next-hop is using an outgoing interface which belongs to given SRLG ID, the user can enable the srlg-frr option under ‘config>router>mpls’ context to be sure the RSVP LSP FRR backup LSP will not use an outgoing interface with the same SRLG ID. A prefix which is resolved to a tunnel next-hop is protected by the RSVP FRR mechanism and not by the IP FRR mechanism. Similarly, the user can include or exclude admin-groups for the RSVP LSP and its FRR bypass backup LSP in MPLS context. Note however the admin-group constraints will be applied to the selection of the outgoing interface of both the LSP primary path and its FRR bypass backup path.
Configuring the rib-priority command either within the global OSPF or OSPFv3 routing context or under a specific OSPF/OSPFv3 interface context enables this feature. Under the global OSPF context, a prefix list can be specified that identifies which route prefixes should be considered high priority. If the
rib-priority high command is configured under an OSPF interface context then all routes learned through that interface is considered high priority.
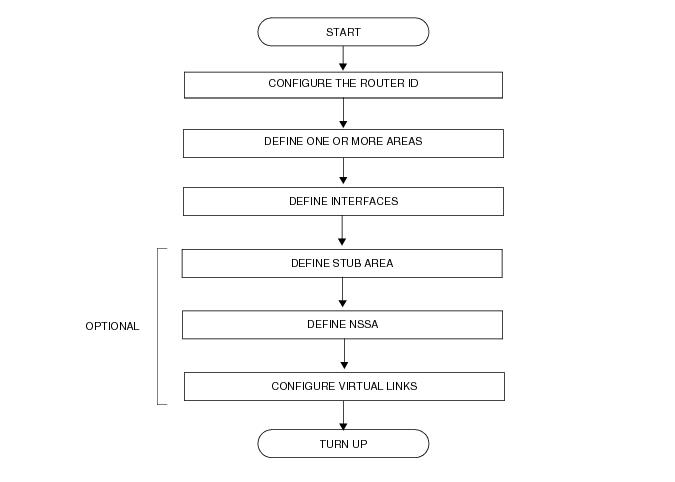
Figure 12 displays the process to provision basic OSPF parameters.