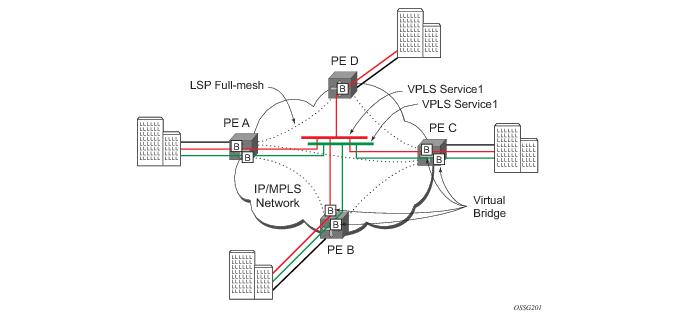
Virtual Private LAN Service (VPLS) as described in RFC 4905, Encapsulation methods for transport of layer 2 frames over MPLS, is a class of virtual private network service that allows the connection of multiple sites in a single bridged domain over a provider-managed IP/MPLS network. The customer sites in a VPLS instance appear to be on the same LAN, regardless of their location. VPLS uses an Ethernet interface on the customer-facing (access) side which simplifies the LAN/WAN boundary and allows for rapid and flexible service provisioning.
VPLS offers a balance between point-to-point Frame Relay service and outsourced routed services (VPRN). VPLS enables each customer to maintain control of their own routing strategies. All customer routers in the VPLS service are part of the same subnet (LAN) which simplifies the IP addressing plan, especially when compared to a mesh constructed from many separate point-to-point connections. The VPLS service management is simplified since the service is not aware of nor participates in the IP addressing and routing.
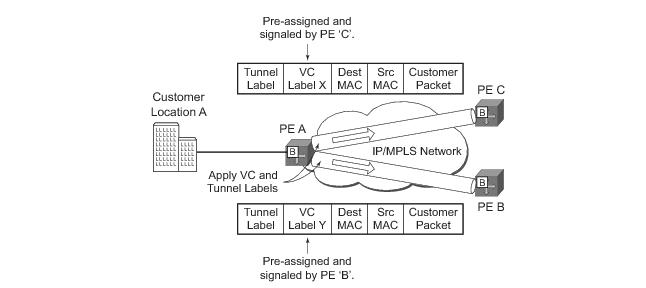
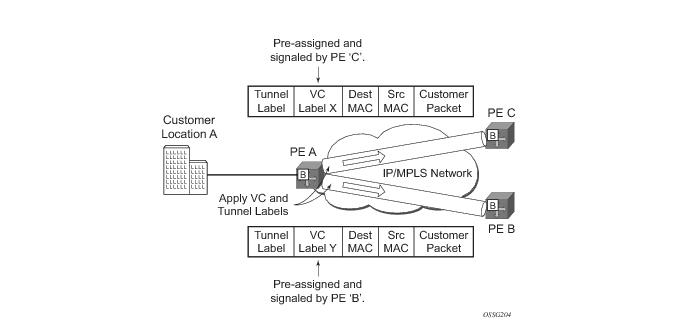
The VPLS architecture proposed in RFC 4762, Virtual Private LAN Services Using LDP Signalling specifies the use of provider equipment (PE) that is capable of learning, bridging, and replication on a per-VPLS basis. The PE routers that participate in the service are connected using MPLS Label Switched Path (LSP) tunnels in a full-mesh composed of mesh SDPs or based on an LSP hierarchy (Hierarchical VPLS (H-VPLS)) composed of mesh SDPs and spoke SDPs.
Multiple VPLS services can be offered over the same set of LSP tunnels. Signaling specified in RFC 4905, Encapsulation methods for transport of layer 2 frames over MPLS is used to negotiate a set of ingress and egress VC labels on a per-service basis. The VC labels are used by the PE routers for de-multiplexing traffic arriving from different VPLS services over the same set of LSP tunnels.
The 7750 SR edge devices perform the packet replication required for broadcast and multicast traffic across the bridged domain. MAC address learning is performed by the 7750 SRto reduce the amount of unknown destination MAC address flooding.
7750 SR routers learn the source MAC addresses of the traffic arriving on their access and network ports.
Each 7750 SR maintains a Forwarding Information Base (FIB) for each VPLS service instance and learned MAC addresses are populated in the FIB table of the service. All traffic is switched based on MAC addresses and forwarded between all participating nodes using the LSP tunnels. Unknown destination packets (for example, the destination MAC address has not been learned) are forwarded on all LSPs to all participating nodes for that service until the target station responds and the MAC address is learned by the routers associated with that service.
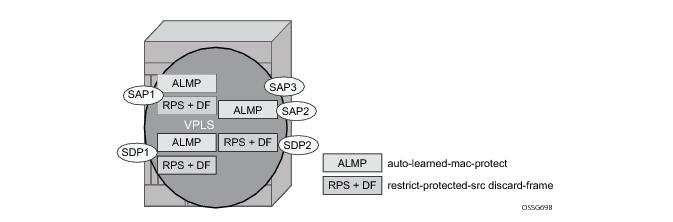
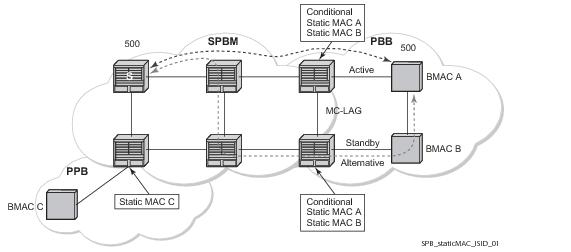
In a Layer 2 environment, subscribers connected to SAPs A, B, C can create a denial of service attack by sending packets sourcing the gateway MAC address. This will move the learned gateway MAC from the uplink SDP/SAP to the subscriber’s SAP causing all communication to the gateway to be disrupted. If local content is attached to the same VPLS (D), a similar attack can be launched against it. Communication between subscribers is also disallowed but split-horizon will not be sufficient in the topology depicted in
Figure 5.
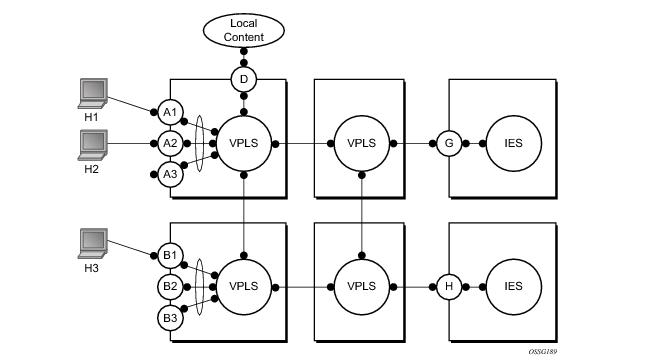
7750 SRs enable MAC learning protection capability for SAPs and SDPs. With this mechanism, forwarding and learning rules apply to the non-protected SAPs. Assume hosts H1, H2 and H3 (
Figure 5) are non-protected while IES interfaces G and H are protected. When a frame arrives at a protected SAP/SDP the MAC is learned as usual. When a frame arrives from a non-protected SAP or SDP the frame must be dropped if the source MAC address is protected and the MAC address is not relearned. The system allows only packets with a protected MAC destination address.
In order to eliminate the ability of a subscriber to cause a DOS attack, the node restricts the learning of protected MAC addresses based on a statically defined list. In addition the destination MAC address is checked against the protected MAC list to verify that a packet entering a restricted SAP has a protected MAC as a destination.
When DE bit is set to 0 (DE=FALSE), the related packet is not discard eligible. This is the case for the packets that are within the CIR limits and must be given priority in case of congestion. If the DEI is not used or backwards compliance is required the DE bit should be set to zero on transmission and ignored on reception.
This is a complementary solution to features such as mac-move and
mac-pinning, but has the advantage that MAC moves are not seen and it has a low operational complexity. It should be noted that if a MAC is initially learned on the wrong SAP/SDP, the operator can clear the MAC from the MAC FDB in order for it to be re-learned on the correct SAP/SDP.
The auto-learn-mac-protect and
restrict-protected-src commands allow the following functions:
Figure 7 shows a specific configuration using
auto-learn-mac-protect and
restrict-protected-src discard-frame in order to describe their operation.
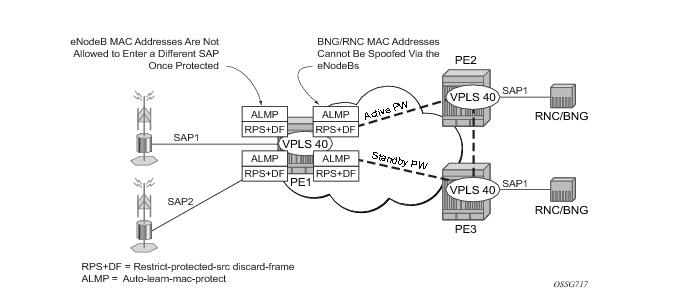
Figure 8 shows a possible configuration using
auto-learn-mac-protect and
restrict-protected-src discard-frame in a mobile backhaul network, with the focus on PE1.
In order to protect the MAC addresses of the BNG/RNCs on PE1, auto-learn-mac-protect is enabled on the pseudo-wires connecting it to PE2 and PE3. Enabling
restrict-protected-src discard-frame on the SAPs towards the eNodeBs will prevent frames with the source MAC addresses of the BNG/RNCs from entering PE1 from the eNodeBs.
The MAC addresses of the eNodeBs are protected in two ways. In addition to the above commands, enabling auto-learn-mac-protect on the SAPs towards the eNodeBs will prevent the MAC addresses of the eNodeBs being learned on the wrong eNodeB SAP. Enabling restrict-
protected-src discard-frame on the pseudowires connecting PE1 to PE2 and PE3 will protect the eNodeB MAC addresses from being learned on the pseudowires. This may happen if their MAC addresses are incorrectly injected into VPLS 40 on PE2/PE3 from another eNodeB aggregation PE.
|
•
|
rstp — Rapid Spanning Tree Protocol (RSTP) compliant with IEEE 802.1D-2004 - default mode
|
|
•
|
dot1w — Compliant with IEEE 802.1w
|
|
•
|
comp-dot1w — Operation as in RSTP but backwards compatible with IEEE 802.1w (this mode allows interoperability with some MTU types)
|
|
•
|
mstp — Compliant with the Multiple Spanning Tree Protocol specified in IEEE 802.1Q-REV/D5.0-09/2005. This mode of operation is only supported in an mVPLS.
|
While the 7750 SR initially uses the mode configured for the VPLS, it will dynamically fall back (on a per-SAP basis) to STP (IEEE 802.1D-1998) based on the detection of a BPDU of a different format. A trap or log entry is generated for every change in spanning tree variant.
The 7750 SR supports two BDPU encapsulation formats, and can dynamically switch between the following supported formats (on a per-SAP basis):
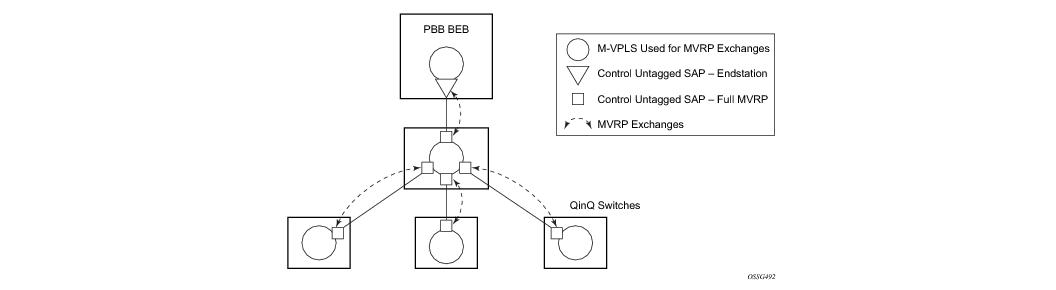
Different access scenarios are displayed in Figure 9 as example network diagrams dually connected to the PBB PEs:
|
•
|
Access Type C — Two or more ES devices connected by QinQ/802.1ad SAPs
|
|
•
|
STP/RSTP can be used for all access types.
|
|
•
|
M-VPLS with MSTP can be used as is just for access Type A. MSTP is required for access type B and C.
|
The SR-Series platform uses a concept of mVPLS to group different SAPs under a single STP instance. The VLAN range covering SAPs to be managed by a given mVPLS is declared under a specific mVPLS SAP definition. MSTP mode-of-operation is only supported in an mVPLS.
To interconnect 7750 SR routers (PE devices) across the backbone, service tunnels (SDPs) are used. These service tunnels are shared among multiple VPLS instances. Alcatel-Lucent’s implementation of the Spanning Tree Protocol (STP) incorporates some enhancements to make the operational characteristics of VPLS more effective. The implementation of STP on the router is modified in order to guarantee that service tunnels will not be blocked in any circumstance without imposing artificial restrictions on the placement of the root bridge within the network. The modifications introduced are fully compliant with the 802.1D-2004 STP specification.
In order to achieve this, all mesh SDPs are dynamically configured as either root ports or designated ports. The PE devices participating in each VPLS mesh determine (using the root path cost learned as part of the normal protocol exchange) which of the 7750 SR devices is closest to the root of the network. This PE device is internally designated as the primary bridge for the VPLS mesh. As a result of this, all network ports on the primary bridges are assigned the designated port role and therefore remain in the forwarding state.
7750 SR routers allow transparent tunneling of PDUs across the VPLS core. However, in some network designs, the VPLS PE is connected to CPEs through a legacy Layer 2 network, rather than having direct connections. In such environments termination of tunnels through such infrastructure is required.
7750 SR routers support L2PT termination for STP BPDUs. More specifically:
To address these network designs, BPDU format translation is supported on 7750 SR devices. If enabled on a given SAP or spoke SDP, the system will intercept all BPDUs destined to that interface and perform required format translation such as STP-to-PVST or vice versa.
In the case where subscriber SLA management is enabled on the SAP and the SAP queues are not available, the queues created by the non-sub-addr-traffic SLA-profile instance are used.
The egress IOM (Input Output Module) automatically creates the SAP chains on each egress forwarding plane (typically all ports on an MDA are part of a single forwarding plane except in the case of the 10 Gigabit IOM which has two MDAs on a single forwarding plane). The size of each chain is based on the dest-chain-limit command defined on the egress multicast group to which the SAPs in the chain belong.
A set of chains is created by the IOM for each egress flooding list managed by the IOM. While SAPs from multiple VPLS contexts are allowed into a single egress multicast group, an egress flooding list is typically based on a subset of these SAPs. For instance, the broadcast/multicast/unknown flooding list for a VPLS context is limited to the SAPs in that VPLS context. With IGMP snooping on a single VPLS context, the flooding list is per Layer 2 IGMP (s,g) record and is basically limited to the destinations where IGMP joins for the multicast stream have been intercepted. When MVR (Multicast VPLS Registration) is enabled, the (s,g) flooding list may include SAPs from various VPLS contexts based on MVR configuration.
The system maintains a unique flooding list for each forwarding plane VPLS context (see section VPLS Broadcast/Multicast/Unknown Flooding List). This list will contain all SAPs (except for residential SAPs), spoke SDP and mesh SDP bindings on the forwarding plane that belong to that VPLS context. Each list may contain a maximum of 127 SAPs. In the case where the IOM is able to create an egress multicast chain, the SAPs within the chain are represented in the flooding list by a single SAP entry (the first SAP in the chain).
The system also maintains a unique flooding list for each Layer 2 IP multicast (s,g) record created through IGMP snooping (see sections VPLS IGMP Snooping (s,g) Flooding List and
MVR IGMP Snooping (s,g) Flooding List). A flooding list created by IGMP snooping is limited to 127 SAPs, although it may contain other entries representing spoke and mesh SDP bindings. Unlike a VPLS flooding list, a residential SAP may be included in a Layer 2 IP multicast flooding list.
The IOM includes all VPLS destinations in the egress VPLS Broadcast/Multicast/Unknown (BMU) flooding list that exist on a single VPLS context. Whenever a broadcast, multicast or unknown destination MAC is received in the VPLS, the BMU flooding list is used to flood the packet to all destinations. For normal flooding, care is taken at egress to ensure that the packet is not sent back to the source of the packet. Also, if the packet is associated with a split horizon group (mesh or spoke/SAP) the egress forwarding plane will prevent the packet from reaching destinations in the same split horizon context as the source SAP or SDP-binding.
The VPLS BMU flooding list may contain both egress multicast group SAPs and other SAPs or SDP bindings as destinations. The egress IOM will separate the egress multicast group SAPs from the other destinations to create one or more chains. Egress multicast group SAPs are placed into a chain completely at the discretion of the IOM and the order of SAPs in the list will be nondeterministic. When more SAPs exist on the VPLS context within the egress multicast group then are allowed in a single chain, multiple SAP chains will be created. The IOM VPLS egress BMU flooding list will then contain the first SAP in each chain plus all other VPLS destinations.
When chaining the egress multicast group SAPs in an MVR (s,g) list, the IOM will keep the native chained SAPs in separate chains from the alien SAPs to prevent issues with split horizon squelching.
As previously stated, the IOM automatically creates the chain lists from the available egress multicast group SAPs. The IOM will create chains from the available SAPs based on the following rules:
Given the following conditions for an IOM creating a multicast forwarding list (List 1) for a Layer 2 IP multicast (s,g) native to VPLS instance 100:
Note: While an operationally down SAP is placed into replication chains, the system ignores that SAP while in the process of replication.
Based on the egress multicast group and the native or alien nature of the SAP in the list, a set of chains are selected for the SAP. The IOM will search the chains for the first empty position in an existing chain and place the SAP in that position. If an empty position is not found, the IOM will create a new chain with that SAP in the first position and add the SAP to the flooding list to represent the new chain.
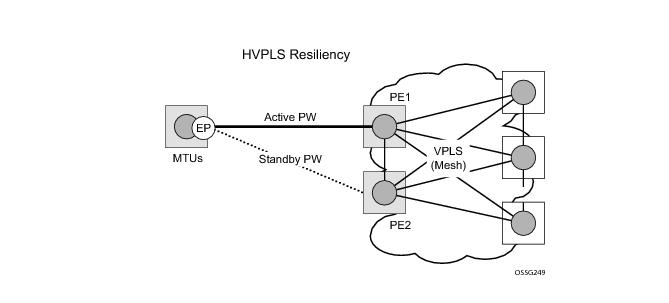
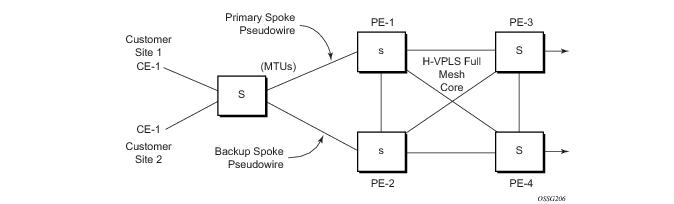
The VPLS standard (RFC 4762, Virtual Private LAN Services Using LDP Signalling) includes provisions for hierarchical VPLS, using point-to-point spoke SDPs. Two applications have been identified for spoke SDPs:
When two or more meshed VPLS instances are interconnected by redundant spoke SDPs (as shown in Figure 10), a loop in the topology results. In order to remove such a loop from the topology, Spanning Tree Protocol (STP) can be run over the SDPs (links) which form the loop such that one of the SDPs is blocked. As running STP in each and every VPLS in this topology is not efficient, the node includes functionality which can associate a number of VPLSes to a single STP instance running over the redundant SDPs. Node redundancy is thus achieved by running STP in one VPLS, and applying the conclusions of this STP to the other VPLS services. The VPLS instance running STP is referred to as the “management VPLS” or mVPLS.
In the configuration example displayed in Figure 10, the MTUs have spoke SDPs to two PEs devices. One is designated as the primary and one as the secondary spoke SDP. This is based on a precedence value associated with each spoke.
Similar as other protocols, MC-EP will register with BFD if the bfd-enable command is active under the
config>redundancy>multi-chassis>peer>mc-ep context. As soon as the MC-EP application is activated using no shutdown, it tries to open a new BFD session or register automatically with an existing one. The source-ip configuration under redundancy multi-chassis peer-ip is used to determine the local interface while the peer-ip is used as the destination IP for the BFD session. After MC-EP registers with an active BFD session, it will use it for fast detection of MC-EP peer failure. If BFD registration or BFD initialization fails, the MC-EP will keep using its own keep-alive mechanism and it will send a trap to the NMS signaling the failure to register with/open BFD session.
|
→
|
The no bfd-enable command in the config>redundancy>multi-chassis>peer>mc-ep context – this is the recommended procedure.
|
|
→
|
The shutdown command in the config>redundancy>multi-chassis>peer>mc-ep or from under config>redundancy>multi-chassis>peer contexts.
|
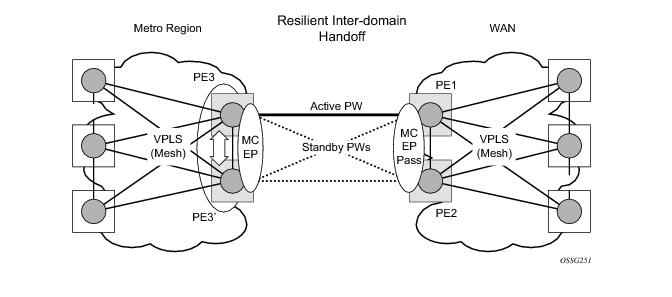
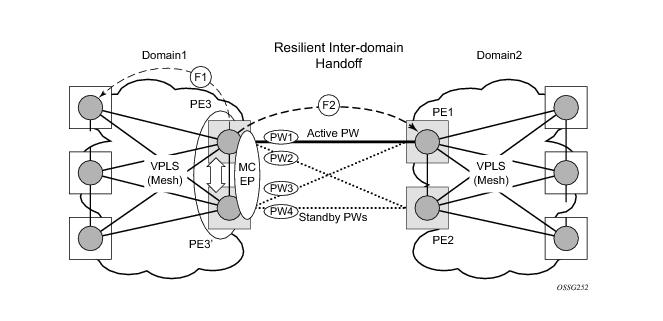
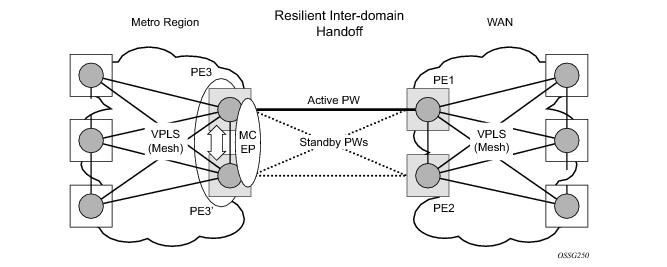
Figure 14 depicts a pair of PE gateways (PE3 and PE3) running MC-EP towards PE1 and PE2 where F1 and F2 are used to indicate the possible direction of the MAC flush signaled using T-LDP MAC withdraw message. PE1 and PE2 can only use regular VPLS pseudowires and do not have to use a MC-EP or a regular pseudowire endpoint.
|
→
|
PE3 sends a T-LDP flush-all-but-mine message towards PE2 in the F2 direction which is propagated by PE2 in the local VPLS mesh. Note that when MC-EP is in passive mode and the first spoke becomes active, a no mac flush-all-but-mine message will be generated.
|
|
→
|
The default is no block-on-mesh-failure to allow for easy migration from previous releases.
|
Prior to Release 7.0, the block-on-mesh-failure command could not be enabled under
config>service>vpls>endpoint context. In order for a spoke SDP to be added to an (single-chassis) endpoint, its
block-on-mesh-failure had to be disabled (
config>service> vpls>spoke-sdp>no block-on-mesh-failure). Then, the configuration of
block-on-mesh-failure under a spoke SDP is blocked.
|
•
|
If block-on-mesh-failure is enabled on PE1 and PE2, these PEs will signal pseudowire standby status toward the MC-EP PE pair. PE3 and PE3 should consider the pseudowire status signaling from remote PE1 and PE2 when making the selection of the active pseudowire.
|
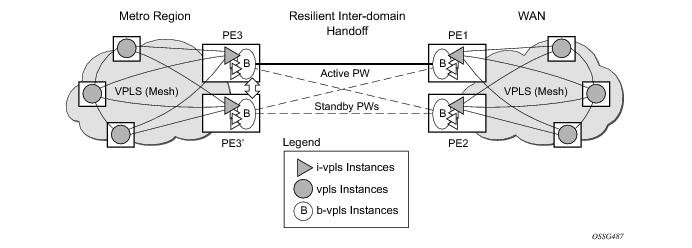
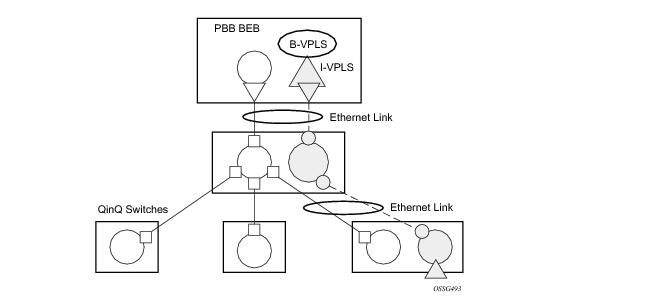
Note that for the PBB topology described in Figure 15, block-on-mesh-failure in the I-VPLS domain will not have any effect on the B-VPLS MC-EP side. That is because mesh failure in one I-VPLS should not affect other I-VPLS sharing the same B-VPLS.
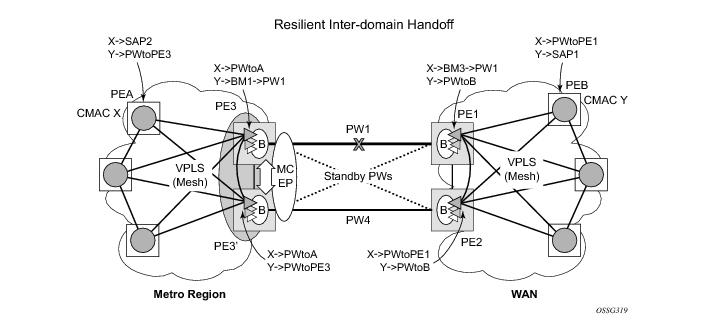
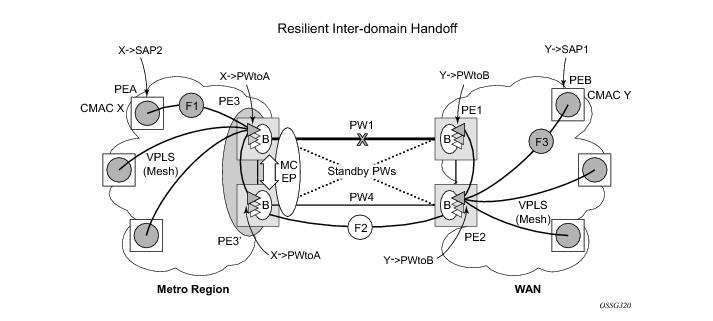
The scenario depicted in Figure 16 is used to define the blackholing problem in PBB-VPLS using MC-EP.
In topology displayed in Figure 16, PE A and PE B are regular VPLS PEs participating in the VPLS mesh deployed in the metro and respectively WAN region. As the traffic flows between CEs with CMAC X and CMAC Y, the FIB entries in blue are installed. A failure of the active PW1 will result in the activation of PW4 between PE3 and PE2 in this example. An LDP flush-all-but-mine will be sent from PE3 to PE2 to clear the BVPLS FIBs. The traffic between CMAC X and CMAC Y will be blackholed as long as the entries from the VPLS and I-VPLS FIBs along the path are not removed. This may take as long as 300 seconds, the usual aging timer used for MAC entries in a VPLS FIB.
In configuration shown in Figure 18, STP is activated on the MTU and two PEs in order to resolve a potential loop.Note that STP only needs to run in a single VPLS instance, and the results of the STP calculations are applied to all VPLSes on the link.
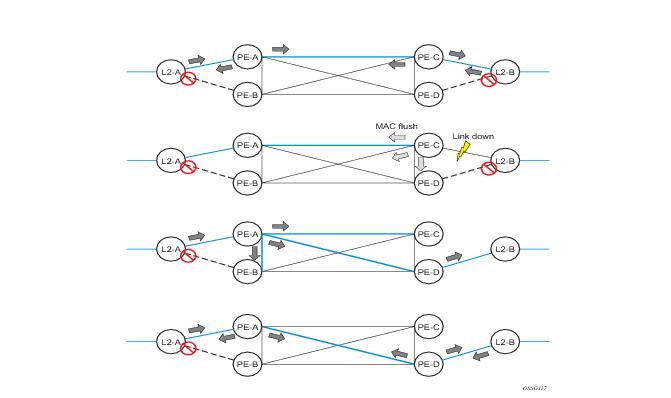
Figure 10 illustrates a dual-homed connection to VPLS service (PE-A, PE-B, PE-C, PE-D) and operation in case of link failure (between PE-C and L2-B). Upon detection of a link failure PE-C will send MAC-Address-Withdraw messages, which will indicate to all LDP peers that they should flush all MAC addresses learned from PE-C. This will lead that to a broadcasting of packets addressing affected hosts and re-learning process in case an alternative route exists.
Note that the message described here is different than the message described in previous section and in RFC 4762, Virtual Private LAN Services Using LDP Signaling. The difference is in the interpretation and action performed in the receiving PE. According to the standard definition, upon receipt of a MAC withdraw message, all MAC addresses, except the ones learned from the source PE, are flushed,
|
•
|
The oper-group bgp-vpls-mesh is created
|
service>oper-group bgp-vpls-mesh-1 create
service>vpls>bgp>pw-template-binding> oper-group bgp-vpls-mesh-1
service>vpls>site> monitor-group bgp-vpls-mesh-1
As described on respective sections, the 7750 SR supports two types of MAC flush message, flush-all-but-mine and flush-mine. The main difference between these messages is the type of action they signal. Flush-all-but-mine requests clearing of all FDB entries which were learned from all other LDP peers except the originating PE. This type is also defined by RFC 4762 as an LDP MAC address withdrawal with an empty MAC address list.
Figure 19 illustrates a dual-homed connection to VPLS service (PE-A, PE-B, PE-C, PE-D) and operation in case of link failure (between PE-C and L2-B). Upon detection of a link failure PE-C will send MAC-Address-Withdraw messages, which will indicate to all LDP peers that they should flush all MAC addresses learned from PE-C. This will lead that to a broadcasting of packets addressing affected hosts and re-learning process in case an alternative route exists.
Note that the message described here is different than the message described in draft-ietf-l2vpn-vpls-ldp-xx.txt, Virtual Private LAN Services over MPLS. The difference is in the interpretation and action performed in the receiving PE. According the draft definition, upon receipt of a MAC-withdraw message, all MAC addresses, except the ones learned from the source PE, are flushed, This section specifies that all MAC addresses learned from the source are flushed. This message has been implemented as an LDP address message with vendor-specific type, length, value (TLV), and is called the flush-all-from-ME message.
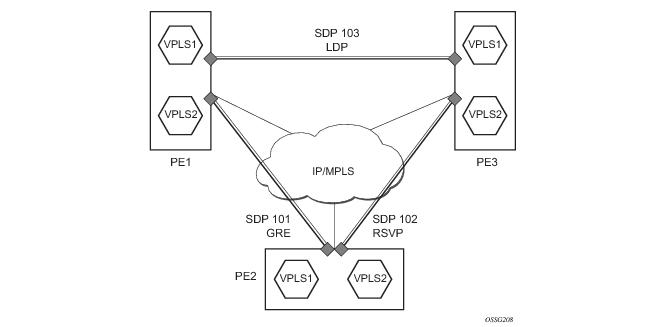
The simple three-node network described in Figure 21 shows two MPLS SDPs and one GRE SDP defined between the nodes. These SDPs connect VPLS1 and VPLS2 instances that are defined in the three nodes. With this feature the operator will have local CLI based as well as SNMP based statistics collection for each VC used in the SDPs. This will allow for traffic management of tunnel usage by the different services and with aggregation the total tunnel usage.
When a VPLS service is created and the radius-discovery command is enabled, manual configuration of SDPs is not required. The far-end SDP is discovered by RADIUS and an auto-SDP will be created for each far-end PE. An auto-SDP binding will be created for the service (the SDP binding is on a per service basis). The auto-SDP can be used for other VPLS service instances between the pair of PEs. If a manual SDP binding is created for the service, it will be preferred to the auto-SDP binding to allow override.
If a manual SDP was provisioned after the RADIUS discovery process, the admin>radius-discovery>force-discover command should be executed in order to use the new manual SDPs.
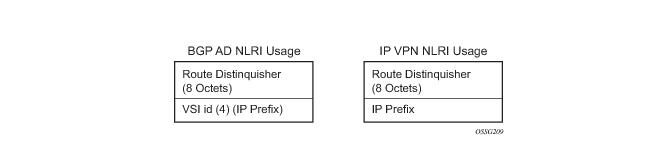
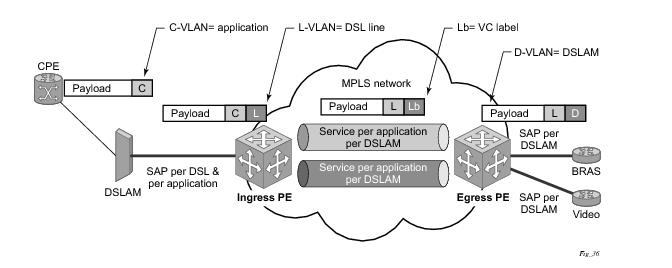
The format of the BGP AD NLRI is very similar with the one used for IP VPN as depicted in Figure 22. The system IP may be used for the last 4 bytes of the VSI ID further simplifying the addressing and the provisioning process.
Two LDP FEC elements are defined in RFC 4447, PW Setup & Maintenance Using LDP. The original pseudowire-ID FEC element 128 (0x80) employs a 32-bit field to identify the virtual circuit ID and it was used extensively in the initial VPWS and VPLS deployments. The simple format is easy to understand but it does not provide the required information model for BGP auto-discovery function. In order to support BGP AD and other new applications a new Layer 2 FEC element, the generalized FEC (0x81) is required.
The Alcatel-Lucent BGP VPLS solution, compliant with RFC 4761, Virtual Private LAN Service (VPLS) Using BGP for Auto-Discovery and Signaling, is described in this section.
Figure 25 depicts the service representation for BGP VPLS mesh. The major BGP VPLS components and the deltas from LDP VPLS with BGP AD are explained below:
In addition to the pseudowire label information, the Layer2 Info Extended Community attribute must be included in the BGP Update for BGP VPLS to signal the attributes of all the pseudowires that converge towards the originator VPLS PE.
+------------------------------------+
| Extended community type (2 octets) |
+------------------------------------+
| Encaps Type (1 octet) |
+------------------------------------+
| Control Flags (1 octet) |
+------------------------------------+
| Layer-2 MTU (2 octet) |
+------------------------------------+
| Reserved (2 octets) |
+------------------------------------+
tools perform service [
id service-id]
eval-pw-template policy-id [a
llow-service-impact]
tools perform service id 100 eval-pw-template 1 allow-service-impact
Figure 26 depicts the VPLS using BGP Multi-homing for the case of multi-homed CEs. Although the picture depicts the case of a pseudowire infrastructure signaled with LDP for a LDP VPLS using BGP-AD for discovery, the procedures are identical for BGP VPLS or for a mix of BGP and LDP signaled pseudowires.
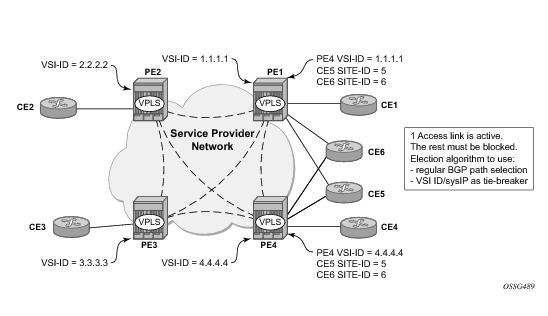
After the pseudowire infrastructure between VSIs is built using either RFC 4762, Virtual Private LAN Service (VPLS) Using Label Distribution Protocol (LDP) Signaling, or RFC 4761 procedures or a mix of pseudowire Signaling procedure, on activation of a multi- homed site, an election algorithm must be run on the local and remote PEs to determine which site will be the designated forwarder (DF). The end result is that all the related MH sites in a VPLS will be placed in standby except for the site selected as DF. Alcatel-Lucent BGP-based multi-homing solution uses the DF election procedure described in the IETF working group document
draft-ietf-l2vpn-vpls-multihoming. The initial implementation allows the use of BGP Local Preference but does not support VPLS preference.
Alternatively, one may choose to associate the MH site to multiple access pseudowires using an access SHG. The config>service>vpls>site>failed-threshold command can be used to indicates the number of pseudowire failures that are required for the MH site to be declared down.
IPv6 multicast forwarding entries — IPv6 multicast snooping forwarding entries are based on MAC addresses, while native IPv6 multicast forwarding entries are based on IPv6 addresses (supported on 7750 SR with IOM2). Thus, when both MLD snooping and native IPv6 multicast are enabled on the same device, both formats are supported on the same IOM2, although they are used for different services.
The root-and-leaf command is required; otherwise, this node will behave as a leaf only node by default. When the node is leaf only for the I-PMSI of type P2MP RSVP LSP, no PMSI Tunnel Attribute is included in BGP-AD route update messages and thus no RSVP P2MP LSP is signaled but the node can join RSVP P2MP LSP rooted at other PE nodes participating in this VPLS/B-VPLS service. Note that the user must still configure a LSP template even if the node is a leaf only. For the I-PMSI of type mLDP, the leaf-only node will join I-PMSI rooted at other nodes it discovered but will not include a PMSI Tunnel Attribute in BGP-AD route update messages. This way, a leaf only node will forward packets to other nodes in the VPLS/B-VPLS using the point-to-point spoke-sdps.
A standard IP interface within an existing IES or VPRN service context may be bound to a service name. Subscriber and group IP interfaces are not allowed to bind to a VPLS or I-VPLS service context or I-VPLS. For the remainder of this section Routed VPLS and Routed I-VPLS will both be described as a VPLS service and differences will be pointed out where applicable. A VPLS service only supports binding for a single IP interface.
Special consideration is given to a service name that is assigned to a VPLS service that has the configure>service>vpls>allow-ip-int-binding command is enabled. If a name is applied to the VPLS service while the flag is set, the system will scan the existing IES and VPRN services for an IP interface that is bound to the specified service name. If an IP interface is found, the IP interface will be attached to the VPLS service associated with the name. Only one interface can be bound to the specified name.
If the allow-ip-int-binding command is not enabled on the VPLS service, the system will not attempt to resolve the VPLS service name to an IP interface. As soon as the
allow-ip-int-binding flag is configured on the VPLS, the corresponding IP interface will be bound and become operational up. There is no need to toggle the
shutdown/no shutdown command.
The allow-ip-int-binding flag within an IP interface attached VPLS service cannot be reset. The IP interface must first be unbound from the VPLS service name to reset the flag.
The allow-ip-int-binding flag on a VPLS service context is used to inform the system that the VPLS service is enabled for routing support. The system uses the setting of the flag as a key to determine what type of ports and which type of forwarding planes the VPLS service may span.
The allow-ip-int-binding flag is set (routing support enabled) on a VPLS/I-VPLS service. SAPs within the service can be created on standard Ethernet, HSMDA., and CCAG ports. ATM and POS are not supported.
When at least one VPLS context is configured with the allow-ip-int-binding flag set, all ports within the system defined as mode network must be on an FP2 or greater forwarding plane. If one or more network ports are on an FP1 based forwarding plane, the
allow-ip-int-binding flag cannot be set in a VPLS service context. Once the
allow-ip-int-binding flag is set on a VPLS service context, a port on an FP1 based forwarding plane cannot be placed in mode network.
When the allow-ip-int-binding flag is set on a VPLS service, the following features cannot be enabled (The flag also cannot be enabled while any of these features are applied to the VPLS service.):
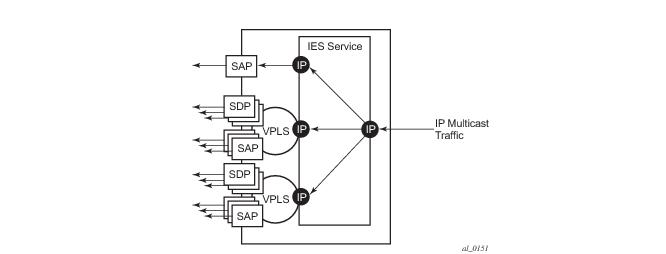
An example scenario is shown in Figure 29. The IP multicast traffic entering the system is replicated to IP interfaces, two of which are part of an IES routed VPLS service. The IP multicast traffic is sent only to those SAPs/SDPs from which a corresponding IGMP join has been received as igmp-snooping is enabled in the VPLS services.
This section describes various 7750 SR service features and any special capabilities or considerations as they relate to VPLS services.
A hold-time parameter (config>service>vpls>mrp>mvrp>hold-time) is provided in the M-VPLS configuration to control when the end-station or last UNI SAP is considered active from an MVRP perspective. The hold-time controls the amount of MVRP advertisements generated on fast transitions of the end-station or UNI SAPs.
If the no hold-time setting is used:
In the port down case MVRP will also be operationally down on the port so no VLAN declaration will take place.





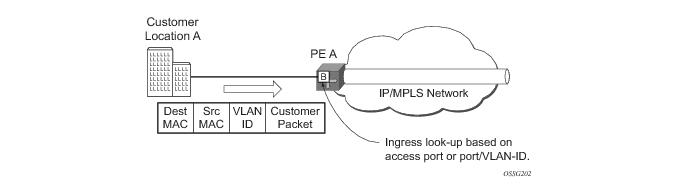
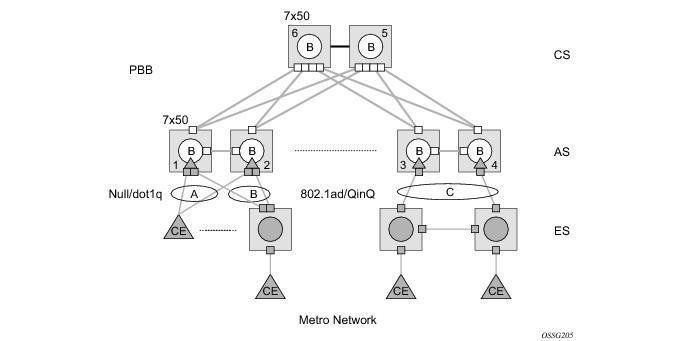 Figure 9: Access Resiliency
Figure 9: Access Resiliency