Diameter and diameter applications
Restrictions
Diameter-Based Restrictions:
Accounting (RFC 6733, Diameter Base Protocol) via Diameter is not supported in this release.
Accounting-Request (ACR), Accounting-Answer (ACA), Session-Termination-Requests (STR) and Session-Termination-Answer (STA) messages are not supported.
SCTP and IPsec as transport protocols are not supported. TCP is supported.
Gx-Based Restrictions:
Static hosts L2-Aware NAT hosts, MLPPP sessions, and LAC (L2TP) hosts are not supported in Gx.
Bridged homes and AA subscribers
Because there is no concept of a subscriber host in AA, the last AA policy submitted by Gx for any ESM subscriber host within the home is applied to the AA subscriber as a whole and overwrite any previously active AA policy.
The <SAP, MAC> combination must be unique for each host (single stack or dual-stack) if ipoe-session or ppp-sessions are not used or enabled.
When an SLA profile instance contains multiple subscriber hosts, it is mandatory that all hosts have the same PCC rules applied.
The Charging-Rule-Name within the Charging-Rule-Definition cannot contain a double colon (::) set of characters in the name string. The use of double colon in the name string itself is reserved for future use.
Reporting about successful rule activation on the node (3GPP 29.212, §4.5.2) is not supported. The rule report is sent only if the rule instantiation fails.
Time-based Usage-Monitoring is not supported.
Gx persistency is not supported. However, upon reboot with ESM persistency enabled, the node re-initiates Gx sessions (new CCR-I is generated for each Gx enabled host).
Gy and Usage-Monitoring cannot be enabled for the same host and the same category-map at the same time. Gy is pre-configured at the time of the host instantiation. If a Usage-Monitoring request is received while Gy is enabled, the node ignores the Usage-Monitoring request.
Each ESM host can have up to 16 Usage-Monitoring entities enabled simultaneously. Static configured categories and the internal category required for session level Usage-Monitoring are counted against this limit. The instantiation of the internal category for session level Usage-Monitoring is controlled with the gx-session-level-usage CLI command in the category map. If 16 categories are configured, then Usage-Monitoring cannot be enabled per session (host) because this would exceed the limit of 16 Usage-Monitoring entities per host.
Terminology
The term Gx interface (or simply Gx) refers to the implementation of the Gx reference point on the node. Gx reference points are defined in the 3GPP 29.212 document.
The ESM subscriber is a host or a collection of hosts instantiated on the Broadband Network Gateway. The ESM subscriber represents a household or a business entity for which various services with committed Service Level Agreements (SLA) can be delivered.
AA Subscriber is a representation of ESM subscriber in MS-ISA for the purpose of managing its traffic based on applications (Layer 7 awareness). An AA subscriber has no concepts of ESM hosts.
BNG refers to the network element on which a Gx interface is implemented and policy rules are enforced (PCEF).
Flow
A flow in Gx context represents traffic matching criteria (traffic classification or traffic identification) based on any combination of the following fields:
source IP address
destination IP address
source port or port ranges
destination port or port ranges
protocol field
DSCP bits
A Gx flow is defined in the Flow-Information AVP:
Flow-Information ::= < AVP Header: 1058 > 3GPP 29.212 §5.3.53
[ Flow-Description ] 3GPP 29.214 §5.3.8
[ ToS-Traffic-Class ] 3GPP 29.212 §5.3.15
[ Flow-Direction ] 3GPP 29.212 §5.3.65
*[ AVP ]
Gx flows are similar to dynamically created filter or ip-criteria (QoS) entries and are inserted within the entry range configured for the base filter/qos-policy.
IP criterion
These fields are used in IPv4/v6 packet header used as a match criterion. The supported fields are DSCP bits and 5 tuple. This is part of traffic classification (or traffic identification) within the PCC rule or within the static qos-policy/filter entry.
Gx policy rule
There are three types of Gx policy rules supported:
Gx based overrides
subscriber-related overrides (sub/sla/aa-profile, subscriber-id, QoS, filter, category-map, and so on).
NAS filter entry inserts via Gx
Basic permit/deny entries, similar to ACL filter entries
PCC rules or IP-criterion based rules which are fully constructed Policy and Charging Control (PCC) rules with multiple QoS/filter actions per rule and its own traffic classification
PCC rule represents a single or a set of IP based classifiers (DSCP bits or 5 tuple) associated with a single or multiple actions.
For example:
Each PCC rule can be removed via Gx from the node by referencing its name (Charging-Rule-Name AVP).
The PCC rule can contain a combination of QoS and IPv4/v6 filter actions as they pertain to the node.
PCC Rule Classifier
A flow-based (5 tuple) or a DSCP classifier defined in the Flow-Information AVP within the PCC Rule. There can be a single classifier or multiple classifiers (Flow-Information AVPs) within a single PCC rule. A PCC classifier (Flow-Information AVP) corresponds to an entry (match criteria) within the filter/ip-criteria definition.
CAM entry
A single entry in the CAM that counts toward the CAM scaling limit. For example a match condition within ip-criteria in a filter or qos-policy can evaluate into a single CAM entry or into multiple entries (where port-ranges are configured in the classifier, or where matching against UDP and TCP protocols are enabled simultaneously).
Subscriber Host Policy
A collection of PCC rules (classifiers and actions), Gx overrides, NAS filter inserts and statically configured rules (CLI defined QoS or filter) that are together applied to the subscriber host.
Diameter base
An updated Diameter base has been implemented to improve future enhancements. The advantages that the Diameter base implementation brings about are as follows:
Future proof extensibility and better compliance with RFC 6733, Diameter Base Protocol
CLI alignment with current AAA framework
SMP (multi-core) capabilities
Performance, the ability to process high volume of messages
Diameter routing
The legacy Diameter base continues to be supported along with the new implementation, although the two cannot be used simultaneously for an application (NASREQ/Gx/Gy) within a given Diameter node instance within the SR OS. Operators are advised to deploy the new Diameter base as there are no plans going forward to add new functionality in the legacy Diameter implementation. Furthermore, the legacy Diameter implementation is scheduled to be discontinued in a future SR OS release, in accordance with the NOKIA software discontinuation policy.
This section describes the operation of the updated Diameter base. The principal difference between the two implementations, from the operator’s point of view, is not only in the functional behavior but also in the CLI. For this reason, the CLI descriptions are provided for both implementations. Some of the CLI commands remain the same for both implementations, and some of the commands are specific to their respective implementation (new or legacy). Each command that is specific to an implementation contains an explicit statement about the implementation to which it pertains.
Diameter base protocol
The Diameter base protocol is used to provide reliable and secure communication for Diameter applications between and across the Diameter peers (diameter clients, agents, or servers). Its routing capabilities to transport traffic across Diameter nodes rely on Diameter identities that are composed of host and realm names. Diameter applications supported in SR OS are NASREQ, Gx, and Gy.
In the SR OS, Diameter base protocols run over TCP. It starts by establishing a TCP connection with peers, followed by capability exchanges. A data exchange occurs in the form of Attribute Value Pairs (AVPs). Some of these AVPs are used by the base protocol itself, while others are used by Diameter applications that are layered on top of it.
Diameter peers and the role of a diameter node in SR OS
Diameter peers exchange messages using a transport level connection (TCP in SR OS). Each peer is identified by a unique Fully Qualified Domain Name (FQDN). On the IP level, Diameter peers are always directly connected.
Applications (NASREQ, Gx, and Gy) relaying on Diameter base protocol use a concept of a session to communicate between the two end nodes that may be adjacent to each other or they may be multiple Diameter hops away.
This concept is shown in Diameter peers.
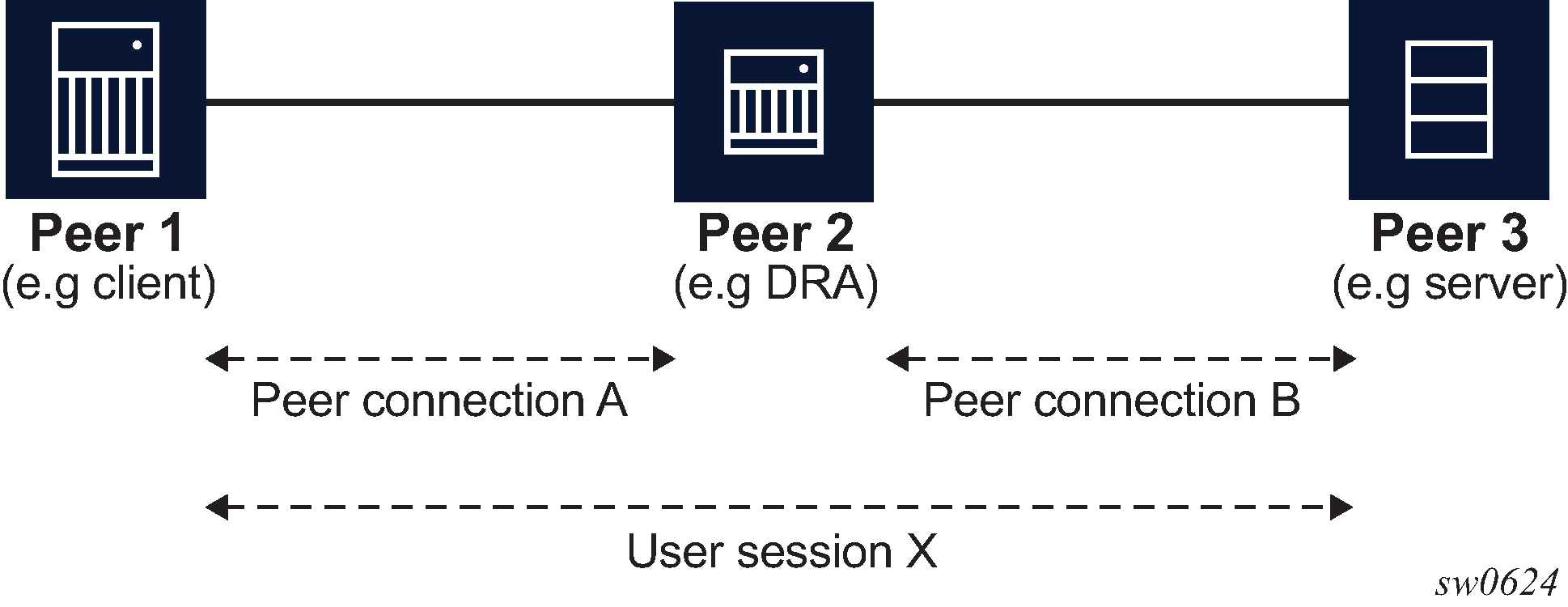
SR OS supports Diameter client functionality where it performs access control for a device running on the edge of the network. A Diameter client in an SR node can initiate and accept connection requests to and from its peers. A connection request is only accepted from another SR node in Diameter multi-chassis redundancy setup. This peering connection between the two redundant Diameter SR nodes is referred to as inter-peering connection and its use is described in Diameter multi-chassis redundancy.
A Diameter server hosting multiple applications must support all applications over a single peering connection. In other words, such a server must not open a separate peering connection per application because peers in the forwarding table are not application aware.
Capability Exchange
Upon TCP connectivity establishment, Diameter peers in an SR node exchange Capability Exchange messages. These messages contain information about the peer such as the peer’s identity, supported applications, protocol version, and security mechanisms. Capability Exchange messages do not traverse Diameter nodes but instead they are exchanged only between the peers (immediate Diameter next hops).
In this phase, an SR node performs peer authorization where the peer identity received from the peer through a Capability Exchange message (origin-host in CEA) is compared to the locally configured peer identity. This peer identity (the peer name) comparison in SR OS is case insensitive. If the compared peer names do not match, the TCP session is closed.
For example:
The configured peer name for SR OS is: peer-1.acme. This identifies the peer that the SR is allowed to establish a connection with.
The origin strings received from this peer in CEA are:
Origin-host: peer-1
Origin-realm: realm-x
In this scenario, SR rejects the connection from this peer because the configured peer name in the SR (peer-1.acme) does not match the origin-host received from the same peer in CEA (peer-1).
An SR node always advertises all three supported applications (NASREQ, Gx, and Gy) in Capability Exchange, regardless of whether these applications are configured in an SR node.
If no common applications are negotiated, the peer (the receiver of a Capability Exchange Request - CER) must return a Capability Exchange Answer (CEA) with the Result-Code AVP set to DIAMETER_NO_COMMON_APPLICATION and should disconnect the transport layer connection.
If the application ID of 0xffffffff (Diameter Relay Agent - DRA) is received by an SR node, then this is interpreted as having a common application with the peer.
Diameter names and realms learned from peers through Capability Exchange are used in SR nodes to populate local peer and realm routing tables that are then used for forwarding and routing of the Diameter messages.
Connection termination
The SR OS may initiate termination of the peering connection because of the following reasons:
peer shutdown
This refers to graceful termination by initiating a Disconnect Peer Request (DPR) message from either side of the connection.
watchdog timeouts
The peer is unresponsive and consequently the TCP connection is forcefully closed.
message authorization failure during the Capability Exchange phase with the peer
There is no support for common application or hostnames mismatch.
failure to verify the following AVPs in incoming Diameter Base messages
CEA: Origin-Host
DWR: Origin-Host, Origin-Realm, Origin-State-Id
DWA: Origin-Host, Origin-Realm, Origin-State-Id
DPR: Origin-Host, Origin-Realm
DPA: Origin-Host, Origin-Realm
These values of these AVPs are checked against:
Origin-Host: peer name configuration
Origin-Realm: learned from CEA
Origin-State-Id: learned the first time seen in either CEA, DWR, DWA
Diameter hosts and realms
Diameter realms are administrative domains that have a relationship with the user account. For example, a Diameter client can be common to multiple departments with different domain realm names, for example xyz.com and wvu.com. In some cases, realms can represent different geographical regions. Regardless, the realm names are maintained in Diameter nodes (as routes) and are used for routing of diameter messages. In general, realms can be thought of as a string in NAI (Network Access Identifier) that immediately follows the first ‟.” character in the string (for example, jdoe.example.com).
Host names identify a host within a realm. Together, the host and realm names form a Diameter Identity (DI). Every Diameter message must contain origin-host and origin realm AVP.
Forwarding and routing of application messages in Diameter
Forwarding and routing of the application level (NASREQ/Gx/Gy) messages in Diameter depends on the message type (requests or answers). Requests messages are forwarded or routed based on destination hosts and realms. Forwarding and routing of request messages is based on the Diameter hosts and realms and is dependent on the two tables maintained in each node between the source and destination:
A peer table contains a list of active peers (adjacent Diameter nodes). The peers in the peer table are populated though configuration and are not learned dynamically. The peer table contains only the peer name (no realms).
A realm-based routing table contains mapping of realms and applications to peers. A realm-based routing table is in the SR OS created per Diameter node. Realms in the routing table are learned dynamically from peers from the origin-realm AVP in Capability Exchange Answer (CEA) messages and cannot be statically configured.
The selection of a peer to which a request message is sent can be a two step process. First, if the request message contains the destination-host AVP, the peer table is checked to find out if there is a matching peer available. If so (the destination is directly connected), the request message is forwarded to it, without further checking the routing table for the next hop (this is called forwarding phase). If the matching host is not present in the peer table (the destination is not directly connected), or the destination-host AVP is not present in the request message (in other words, CCR-I), then the diameter routing table is checked for the matching realm. This is referred to as routing phase. Each routable request message must contain the destination realm AVP and the destination realm is a mandatory configuration parameter in an SR node for a Diameter application. However, on the application level, a Gx and Gy session can also learn the destination realm from received application messages. In this case, the learned value overwrites the configured value.
If the Diameter realm table does not contain an entry for the destination realm and the application, the request message is forwarded to the default peer, if one is configured. There can be only one default peer per Diameter node. Unlike a realm routing entry in the realm table, the default peer is application (NASREQ, Gx, Gy) unaware, and it is used as a route of last resort, regardless whether the selected path leads to a server supporting this application.
If the default peer is not configured, messages destined for a realm that is not known in the realm routing table, are dropped.
Application level answer messages do not rely on the routing or forwarding table. They are forwarded in reverse direction of the matching requests in the transactional cache of each traversed Diameter node and the Hop-by-Hop AVP. The Hop-by-Hop AVP is set to a locally unique value by each Diameter node that forwards request messages. This AVP is then used to match request and answer messages in the reverse direction. This allows a Diameter response to follow the same route as the corresponding Diameter request.
Static Diameter realm routes
Static Diameter realm routes are used to reach remote realms, which are not directly connected to the local realm configured on the SR OS.
They are configured under the Diameter peer:
configure
aaa
diameter
node <origin-host-string> [origin-realm <origin-realm-string>]
peer index <index> [<destination-host-string>]
route index <index> [realm <name>] [application <name>] [create]
preference <1-100>
There are two preference parameters that can be configured under this CLI hierarchy:
Peer preference is configured directly under the peer and applies only to routes learned using the capability exchange phase and not the static routes. This parameter determines the directly-connected preference of the learned routes relative to the static routes. Currently, there can be only one learned realm route per peer.
Static route preference is configured for each static route. The static route with the numerically lowest preference is used.
The order of the evaluation for realm routes is:
The route with the lowest preference is used. The preference of static routes is individually configured, whereas the preference of the learned routes is configured by a peer.
In case of a preference tie, the route configured by the peer with the lowest index is chosen.
A static route is installed in the realm table only if the peer in which it has been configured is in an open state.
Example with static realm routes
In this example, Gx and Gy traffic, destined for the remote realms Realm-3 and Realm-4, is balanced over two DRAs. Gx traffic destined for Realm-4 flows through Node-B, while Gy traffic destined for Realm-3 flows through Node-C, according to the preference of the static routes. If the connection to one of the peers fails, the surviving connection takes over as shown in Reaching remote realms.
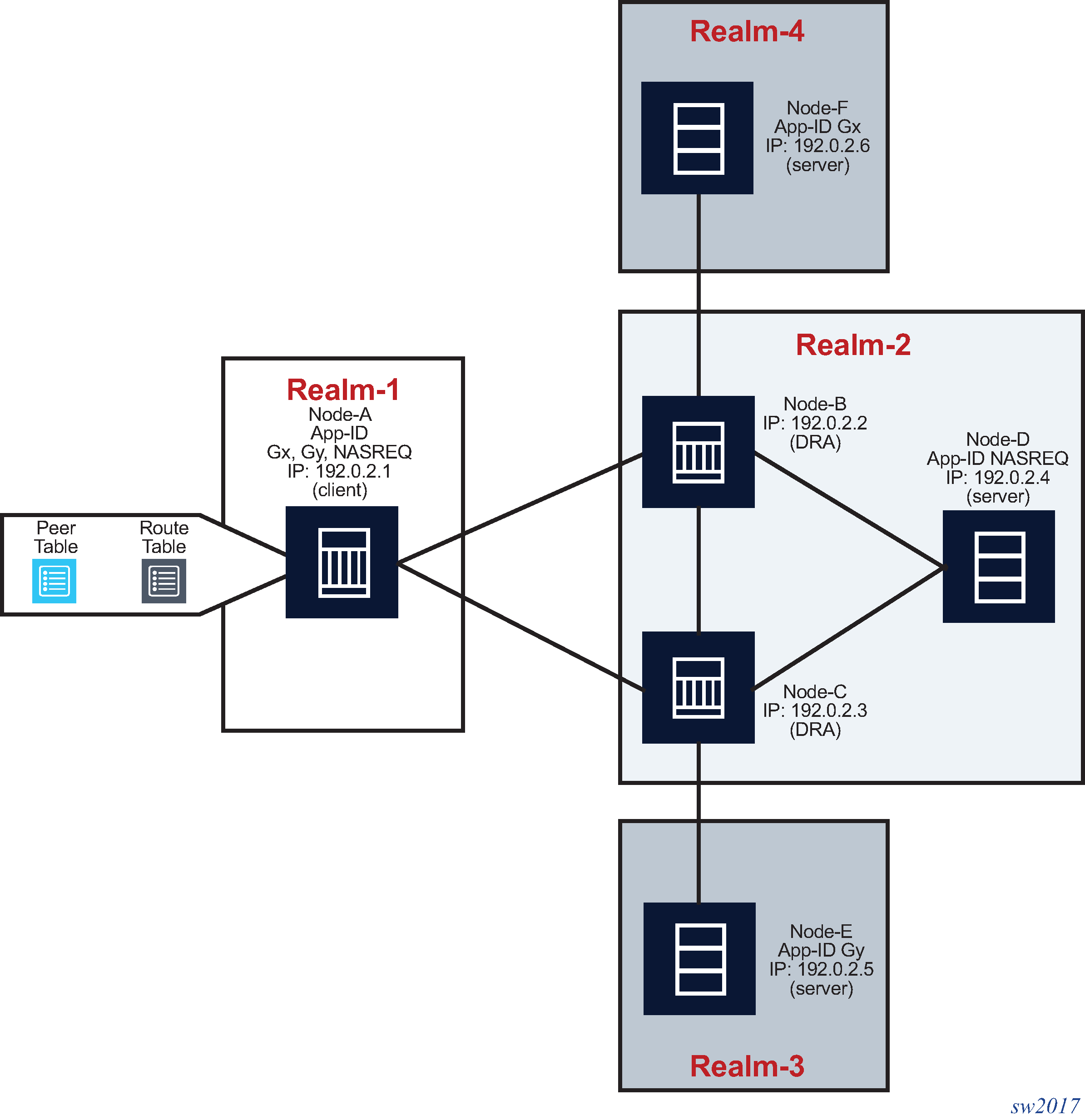
NASREQ traffic, which is destined for the directly-connected Realm-2 flows through Node-B because it has a lower peer index, while the peer preference is the same as on peer Node-C as described in Peer table and Realm routing table . Only when the communication to this peer fails does Node-C be selected as the new peer.
>config>aaa# info
----------------------------------------------
diameter
node "sr" origin-realm "realm-1" create
peer index 1 "node-b" create
address 192.0.2.2
preference 5
route index 1 realm realm-3 application gx
preference 10
route index 2 realm realm-4 application gy
preference 20
no shutdown
exit
peer index 2 "node-c" create
address 192.0.2.3
preference 5
route index 1 realm realm-3 application gx
preference 20
route index 2 realm realm-4 application gy
preference 10
no shutdown
exit
exit
exit
| Host identity | IP address |
|---|---|
Node-B |
192.0.2.2 |
Node-C |
192.0.2.3 |
| Realm name | App ID | Peer | Entry | Preference |
|---|---|---|---|---|
Realm-2 |
0xffffffff |
Node-B |
dynamic (learned) |
5 |
Realm-2 |
0xffffffff |
Node-C |
dynamic (learned) |
5 |
Realm-3 |
Gx |
Node-B |
static |
10 |
Realm-3 |
Gx |
Node-C |
static |
20 |
Realm-4 |
Gy |
Node-C |
static |
20 |
Realm-4 |
Gy |
Node-B |
static |
10 |
The NASREQ routing in this case can be configured in several ways:
with the same preference for both peers (as in the example above), where the peer with the lowest index prevails
with different peer preferences as shown in the example below
*A:right-b4>config>aaa# info ---------------------------------------------- diameter node "sr" origin-realm "realm-1" create peer index 1 "node-b" create address 192.0.2.2 preference 10 no shutdown exit peer index 2 "node-c" create address 192.0.2.3 preference 5 no shutdown exit exit exitIn this case, the preferred NASREQ path is through Node-C.
with static routing
*A:right-b4>config>aaa# info ---------------------------------------------- diameter node "sr" origin-realm "realm-1" create peer index 1 "node-b" create address 192.0.2.2 preference 10 no shutdown exit peer index 2 "node-c" create address 192.0.2.3 preference 10 route index <index> realm realm-2 application nasreq preference 5 no shutdown exit exit exitIn this case, the NASREQ path is through Node-C because the preference of the static route is the lowest.
Default peer
If the Diameter realm table does not contain an entry for the destination realm and the application, the request message is forwarded to the default peer, if one is configured. There can be only one default peer per Diameter node. Unlike a realm routing entry in the realm table, the default peer is application (NASREQ/Gx/Gy) unaware, and therefore it is used as a route of last resort, regardless of whether the selected path leads to a server supporting this application or not. If the default peer is not configured, messages destined for a realm that is not listed in the realm routing table are dropped.
Configuration of hostnames and realms in SR OS
Host names and realm names are essential in Diameter routing. They are conveyed in Diameter messages through the following AVPs:
Origin-Host
Origin-Realm
Destination-Host
Destination-Realm
Origin-host and origin-realm AVPs are used to identify nodes in Diameter networks. Every Diameter message must carry these two AVPs. In SR OS, the origin hostname must be statically configured through CLI. The configuration of the origin realm is optional. If the origin realm is not configured, the origin realm is extracted from the origin hostname. The first ‟.” in the configured origin hostname is used as a delimiter between the host portion and the realm portion. If there is no ‟.” in the configured origin hostname, then the origin hostname is used as both, the origin hostname and the origin realm name. Origin host and realm names do not support online changes (once they are configured, because they cannot be changed without first deleting the Diameter node hierarchy).
The origin-host and origin-realm names received from peers, as a result of successful Capability Exchange negotiation, are used to populate peer and realm tables in SR nodes.
While origin-host and origin realms are used for identification of Diameter nodes within realms, the destination-hosts and destination-realms are used in Diameter request messages for forwarding and routing purposes. They steer the message through the Diameter network toward the destination.
The destination hostname that is used by applications (NASREQ, Gx, Gy) cannot be configured in an SR node and is only learned from the incoming application level messages (the origin-host AVP in the incoming request or answer messages). within each Diameter session.
On the other hand, the destination realm that is used in application request messages is a mandatory configuration parameter in an SR node. However, its value can optionally be learned from the incoming application messages and any newly learned value overwrites the previous one. This learning is performed on a per-message basis. The destination realm value (configured or learned) is not used to populate the realm table but is only used on the application level to populate the destination-realm AVP in every application level request message.
Because the destination-host AVP is optional and the destination-realm is mandatory in application request messages, the destination-realm can be used without the destination-host in forwarding and routing decisions to guide the request message to its destination. The destination-realm used in initial request message (CCR-I) is a configured one, while the destination-host is not used in the same message because it has not been learned yet.
Destination-host or destination-realm AVPs are never present in:
Diameter messages that are not to be proxied or relayed (such as CER)
Diameter answer messages
New base configuration
Origins are creation time parameters in the Diameter node CLI configuration. Multiple unique diameter nodes can be instantiated within the same SR node.
config>aaa>diam#
node <origin-host-string> [origin-realm <origin-realm-string>]
Applications (NASREQ, Gx, and Gy) are associated with the Diameter node (and the origins) through the diameter-application-policy:
config>subscr-mgmt>diam-appl-plcy#
diameter-node <origin-host-string> destination-realm <destination-realm-string>
The destination-realm referenced in the Diameter node above is used to populate the destination-realm AVP in the application level request messages. This destination realm can be optionally learned from the incoming application level messages and any newly learned value overwrites the previous one. This learning is performed on a per-message basis.
Legacy configuration
The centerpiece of legacy in the Diameter base configuration in an SR node is a diameter-peer-policy where all the Diameter base parameters related to communication with other external Diameter peers are defined (peering connections, DiameterIdentity, timers, and so on). This diameter-peer-policy is then associated with Diameter applications (NASREQ, Gx, Gy) which rely on it to interact outside the network.
In legacy Diameter base, the origins are configured under the diameter-peer-policy:
config>aaa>diam-peer-plcy#
origin-host <origin-host-string>
origin-realm <origin-realm-string>
while the destinations are configured one level below, under the peers:
config>aaa>diam>diameter-peer-plcy>peer#
destination-host <destination-host-string>
destination-realm <destination-realm-string>
If these parameters are not configured, the diameter-peer-policy is operationally down.
Applications (NASREQ, Gx, and Gy) are associated with the diameter-peer-policy through the diameter-application:
config>subscr-mgmt>diam-appl-plcy#
diameter-peer-policy <name>
Dynamically learned parameters
The Diameter entities that are dynamically learned from a peer using Capability Exchange are:
the received origin realm name (via origin-realm AVP)
the App-ID
These entities are used to populate the realm table (<realm, app-id> to peer mapping) on which the routing decisions are based.
The origin-host AVP from CEA is used to cross check the peer name in the peer table. A mismatch between the configured and learned (origin-host AVP in CEA) peer names causes the TCP connection to close.
The destination hostname is initially learned on the application level (Gx and Gy) using CCA-I messages and the destination hostname can be re-learned through subsequent incoming application level messages. For example, the origin hostname in incoming application level messages become the destination hostname in outgoing application level messages.
The destination realm, although initially configured, can also be learned on the application level using incoming application level messages (Gx and Gy). Dynamic learning is enabled per message, and the learned value is used in subsequent request messages.
Diameter routing loop avoidance
Routing loop prevention in an SR node relies on the evaluation of a set of candidate next hop peers that are returned by each forwarding lookup (which is a realm routing lookup based on destination DI in the request message). The following peers are excluded from this set as next-hop candidates:
Peer from which the request is received
A peer from which a DIAMETER_UNABLE_TO_DELIVER (3002) or DIAMTER_TOO_BUSY (3004) answer was received for the request.
If an error message with the result-code AVP of DIAMETER_UNABLE_TO_DELIVER (3002) or DIAMTER_TOO_BUSY (3004) is received, the Diameter client should use an alternate route to deliver this message (§7, example relevant to Figure 7 in RFC 6733, Diameter Base Protocol).
Any peer identified in the Record-Route AVP of received request message (see the Diameter Multi-Chassis Redundancy section).
The remaining peers are evaluated and the one with the numerically lowest preference value is selected as the next-hop peer.
Retransmissions and message timers
Application level Diameter request messages originated from an SR node can be retransmitted in response to either an error messages received from the Diameter peer or server, or because of a lack of acknowledgment (Diameter Answer message or a TCP ACK) received from a Diameter peer or server.
Message retransmissions can occur on multiple levels:
TCP level where a TCP ACK is not received from a peer. Such retransmission cannot traverse Diameter nodes (for example between the originating node and the destination node that are separated by one or more intermediate Diameter nodes). They work only between Diameter peers.
The lack of TCP ACK can be caused by some anomaly in transmission lines or congestion in the network or the peering node where the TCP packets are dropped.
The Diameter Base level where they are triggered by the peer failover procedures that can be caused by the peer failure or the receipt of DIAMETER_UNABLE_TO_DELIVER (3002) and DIAMETER_TOO_BUSY (3004) error messages. The peer failover (and retransmission on the Diameter base level) is performed only for the messages that directly solicit 3002/3004 error response.
On the Diameter application level (NASREQ, Gx, Gy) retransmissions are sent only if the server failover functionality is enabled:
*A:node1>config>subscr-mgmt>diam-appl-plcy# on-failure failover {enabled|disabled} handling {continue|retry-and-terminate|terminate}On the Diameter application level, the request message is retransmitted only one time. Retransmissions on the Diameter application level are triggered by:
Answer messages that have the E-bit set (protocol error). The only two exceptions are DIAMETER_UNABLE_TO_DELIVER (3002) and DIAMETER_TOO_BUSY (3004) error messages that trigger retransmissions on the Diameter Base level until all viable Diameter paths are exhausted, or the Tx timer expires (whichever event occurs first). Only after all viable paths are exhausted, or the Tx timer expires, the handling is passed to the Diameter application which has the option to retransmit the message one last time, with the destination-host AVP cleared.
Notification by the Diameter base that the path to the destination-realm is unavailable. For example, because of Tx-timer timeout, the answer to an original request message is not received within the time window determined by this configurable timer.
Answer messages are never retransmitted on the Diameter application level. However, Answer messages can be retransmitted on a TCP level.
Retransmission of non-routable Diameter request messages is driven by an internal timer which is set to a fixed value of 10 seconds. Non-routable Diameter messages are messages required for maintenance of the peering connection. These messages never propagate beyond the peer. This internal timer is used in the following cases:
Failure to initiate TCP peering connection
Incomplete Capability Exchange
If the response to the CER message (CEA) is not received within 10 seconds, the peer connection is closed and the connection-timer is restarted. The expiry of the connection-timer triggers a new connection request.
Peer Disconnect Request
If the response to the DPR message is not received (DPA) within 10 seconds, the peer connection is closed.
Diameter Watchdog messages are an exception and they are not retransmitted. Watchdog messages are used to detect the liveliness of a peer. A Diameter Watchdog message is sent in absence of any traffic on the peer level and only when the peer level watchdog-timer expires.
Clearing the destination-host AVP in the retransmitted messages
The destination-host AVP is cleared in all Diameter request messages that are retransmitted by the Diameter application (NASREQ, Gx, Gy). Messages retransmitted by the Diameter Base (peer failover related retransmissions) do not have the destination-host AVP cleared.
The Diameter application retransmits the message with the assumption that the path to the destination-host, or the destination-host itself is unavailable. Clearing of the destination-host AVP provides a new chance to for the Diameter Base to deliver the message to an alternate destination in the same realm. This alternate destination must be in a geo-redundant setup where sessions are synchronized between the geo-redundant nodes.
Retransmission bit (T-Bit)
The T-bit can be set in a retransmitted Diameter request message as a direct indication that the message may be a duplicate. For example, if the original request message is received by the server, but the answer is lost on its way back to the sender. If the original request message is not received by the server, then the message is not a duplicate from the server point of view. Detection of the duplicates on the application server side is important, especially in credit control applications. Duplicate requests received by the server should not be interpreted as new requests for credit, or new reports for usage, otherwise, double accounting or billing may occur.
On the other hand, the indirect indication of a duplicate Diameter request message on the server side relies on the comparison of the origin-host and end-to-end identifier fields that must always be the same in original and retransmitted messages. This requires the server to keep a history of received messages (or some metadata after it has sent the answer). Normally, after the answer is sent, reference to end-to-end identifier is lost and the duplicate detection is not possible. While some servers may implement such logic to rely on implicit identification of duplicate messages, not all of them are expected to implement such logic. For this reason, setting the T-bit explicitly is a more reliable mechanism to detects duplicates on the server side.
The T-bit in an SR is set on retransmitted messages that are triggered by a timeout (via application) as well as on retransmitted messages triggered by an imminent peer failure.
The T-bit is not set on any message that is retransmitted in response to any explicit error message (3002, 3004, and so on). An explicit error message is an indication that the original request message has reached some Diameter node and solicited a specific response from that node, and therefore is not considered a duplicate.
Handling of Diameter_Unable_To_Deliver (3002) error message
Diameter_Unable_to_Deliver (3002) is a protocol error message with E-bit set that is handled on a hop-per-hop basis (the node receiving this message must handle it and not just transparently pass it to the next node). 3002 is a response to an application request message, and its purpose is to notify the sender (the first upstream Diameter node) that the intended destination for this particular application and within this realm is not available on that path. This should trigger the node that receives such a response to retransmit the request message over an alternate path, that is the next peer found in the realm routing table.
After all eligible next hop peers are exhausted, or the Tx timer expires, the Diameter application is notified that the message request has failed. A configurable Tx timer is started after the first peer failover is performed (reaction to the first 3002 or 3004 error message received). All this is in the context of a single application request message. At this point the Diameter application determines, based on the server failover configuration, whether to retransmit this message. The destination-host AVP is cleared in retransmitted message.
For example:
A 3002 message is received by the Diameter Base in the SR
The TX timer is started
The Diameter Base denylists the peer from which this message is received
The request message in the pending queue is immediately re-transmitted to the next eligible peer
This process continues until a viable peer is found (a request message is successfully delivered to the destination), the last eligible peer is tried, or the Tx timer expires, whichever event occurs first. The subsequent eligible peers can be only found in the realm routing table (and not the peering table).
If the message is not successfully delivered within the Tx time, the Diameter Base notifies the application layer (NASREQ, Gx, Gy).
The application executes the server failover procedure and potentially retransmit the request.
At this point the application clears the destination-host AVP and the message is delivered to any server in the same realm supporting this application. This assumption is that the application servers support geo-redundancy.
Response to Diameter_Too_Busy (3004) error message
The processing of the Diameter_Too_Busy error message is the same as the processing of Diameter_Unable_To-Deliver (3002) error message.
The SR attempts to retransmit the message to an alternate peer by a Diameter Base, and only when the delivery fails on all peers, the Diameter application (NASREQ, Gx, Gy) are notified for potentially one last retransmission attempt in which the destination-host AVP is cleared.
In both of these cases (Diameter_Unable_To_Deliver and Diameter_Too_Busy), an agent or server tells a downstream peer that it is either too busy to handle a request or unable to route a request to an upstream destination, perhaps because the destination itself is overloaded to the point of unavailability (RFC 7068, §4, Diameter Overload Control Requirements).
An SR as a transit Diameter node
In addition to Diameter client functionality where messages are originated and terminated, an SR node can also act as a transit node, routing messages between the peers. This functionality is primarily used in redundant Diameter multi-chassis configuration, where Diameter messages are sent between the two redundant SR nodes over inter-peer connection.
Transit Diameter request messages are never retransmitted. However, they are kept in a pending queue until a matching answer is received. If the answer to a request messages in the pending queue is not received within 10 seconds, the message is discarded. This 10 second timer is the same internal timer mentioned in section Retransmissions and message timers, which is also used for non-routable messages (such as CER/CEA, DPR/DPA).
Python support
Python processing of the Diameter messages is supported in Diameter base where the processing can be enabled per message type per direction.
3GPP-Based Diameter Credit Control Application (DCCA) - Online Charging
The 3GPP-based Diameter Credit Control Online Charging applications allow the control of subscriber access to services based on a pre-paid credit. The volume and time accounting on the node supports online charging using the Diameter Credit-Control Application (DCCA). The node supports Session Charging with Unit Reservation (SCUR), allowing the node to reserve volume and time quotas for rating-groups. Furthermore, the node supports centralized unit determination and centralized rating: it requests quotas and reports usage against the quota provided by the Online Charging Server (OCS). Credit control is always on a per-rating group basis. A rating group maps to a category inside a category map of the node volume-based and time-based accounting function.
The following are the basic configuration steps:
Configure a diameter policy.
In the config>aaa CLI context, configure a Diameter peer policy with one or multiple Diameter peers.
configure aaa diameter-peer-policy "diameter-peer-policy-1" create description "Diameter peer policy" applications gy connection-timer 5 origin-host "bng.domain.com" origin-realm "domain.com" source-address 10.0.0.1 peer "peer-1" create address 10.1.0.1 destination-host "server.domain.com" destination-realm "domain.com" no shutdown exit exit exitWhen the diameter peer is reachable from IPv6, then the peer address should be specified as an IPv6 address. Optionally, an IPv6 source address can be specified:
configure aaa diameter-peer-policy "diameter-peer-policy-1" create ---snip--- ipv6-source-address 2001:db8::1 peer "peer-1" create address 2001:db8:100::1 ---snip---Configure a diameter application policy.
In the config>subscr-mgmt CLI context, configure a diameter application policy:
-
Set the application to Gy (Diameter Credit Control Application)
-
Specify the Diameter peer policy to use and optionally specific additional Gy application specific parameters (for example AVP format).
configure subscriber-mgmt diameter-application-policy "diameter-gy-policy-1" create description "Diameter Gy policy" application gy diameter-peer-policy "diameter-peer-policy-1" gy avp-subscription-id subscriber-id type e164 include-avp radius-user-name exit exit exit exit-
Create a category-map and define:
the credit type (time or volume)
a category defining the queues to monitor for quota consumption and the rating-group this category maps to in DCCA
configure subscriber-mgmt category-map "cat-map-1" create description "Category Map" credit-type time category "cat-1" create rating-group 1 queue 1 ingress-egress exhausted-credit-service-level pir 256 exit exit exit exitCreate a credit control policy.
Define the credit control servers to use by specifying the diameter application policy. Optionally, specify the default-category-map and an out-of-credit-action.
configure subscriber-mgmt credit-control-policy "cc-policy-1" create description "Credit Control Policy" credit-control-server diameter "diameter-gy-policy-1" default-category-map "cat-map-1" out-of-credit-action change-service-level exit exitConfigure the diameter credit-control-policy in the sla-profile of the subscriber host for which credit control should be activated.
configure subscriber-mgmt sla-profile "sla-profile-3" create description "SLA profile" credit-control-policy "cc-policy-1" exit exit
The following are examples of Diameter online charging flows:
-
scenario 1
Scenario 1 depicts a redirect use-case:
When the quota is depleted, the subscriber is redirected to a web portal. When the credit is refilled, the OCS server notifies the BNG and provides a new quota. The configured out-of-credit-action when receiving a Final Unit Indication with action different from terminate is installed. See Online Charging scenario 1 - redirect (1/2) and Online Charging scenario 1 - redirect (2/2).
Figure 3. Online Charging scenario 1 - redirect (1/2) 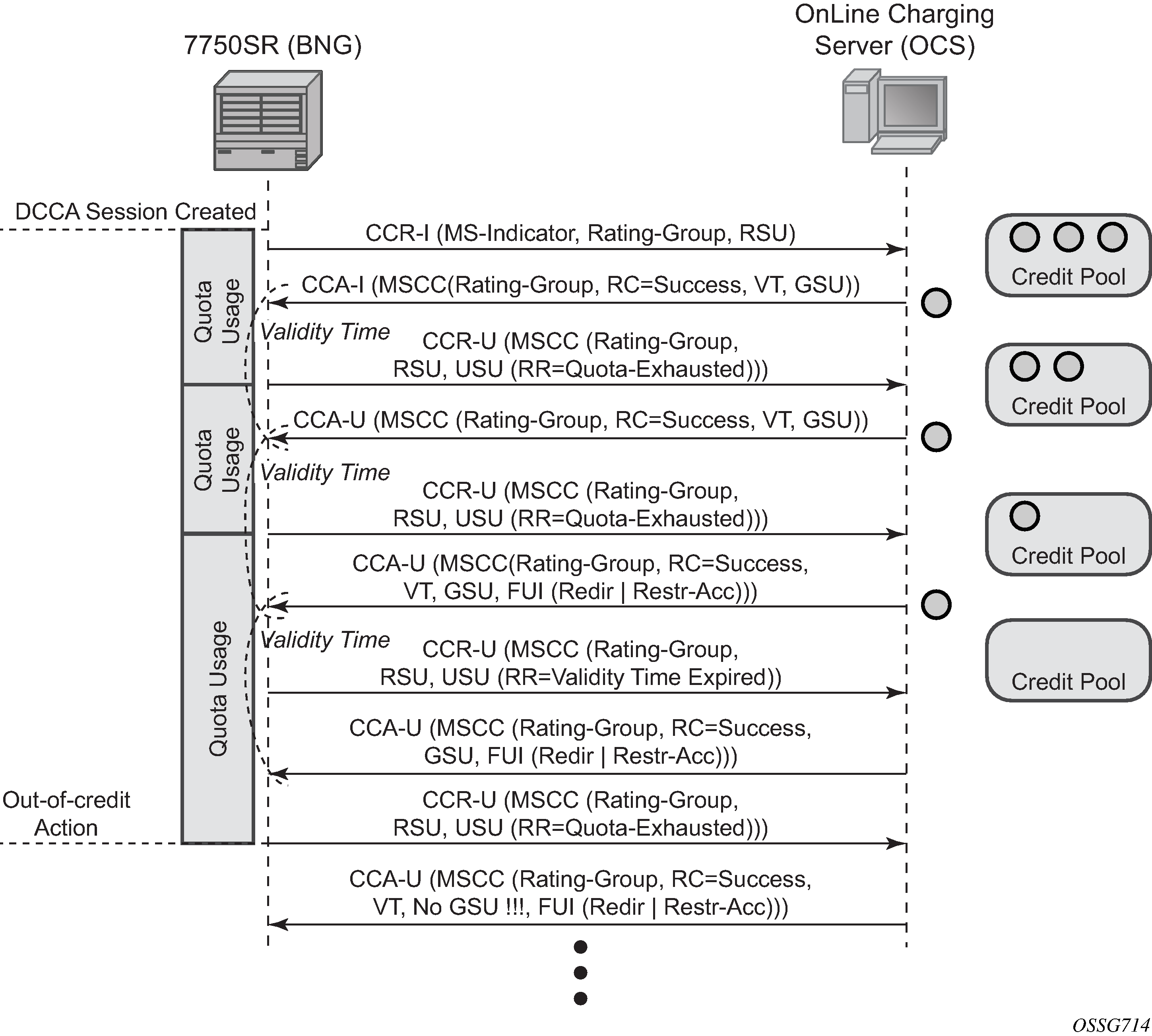
Figure 4. Online Charging scenario 1 - redirect (2/2) 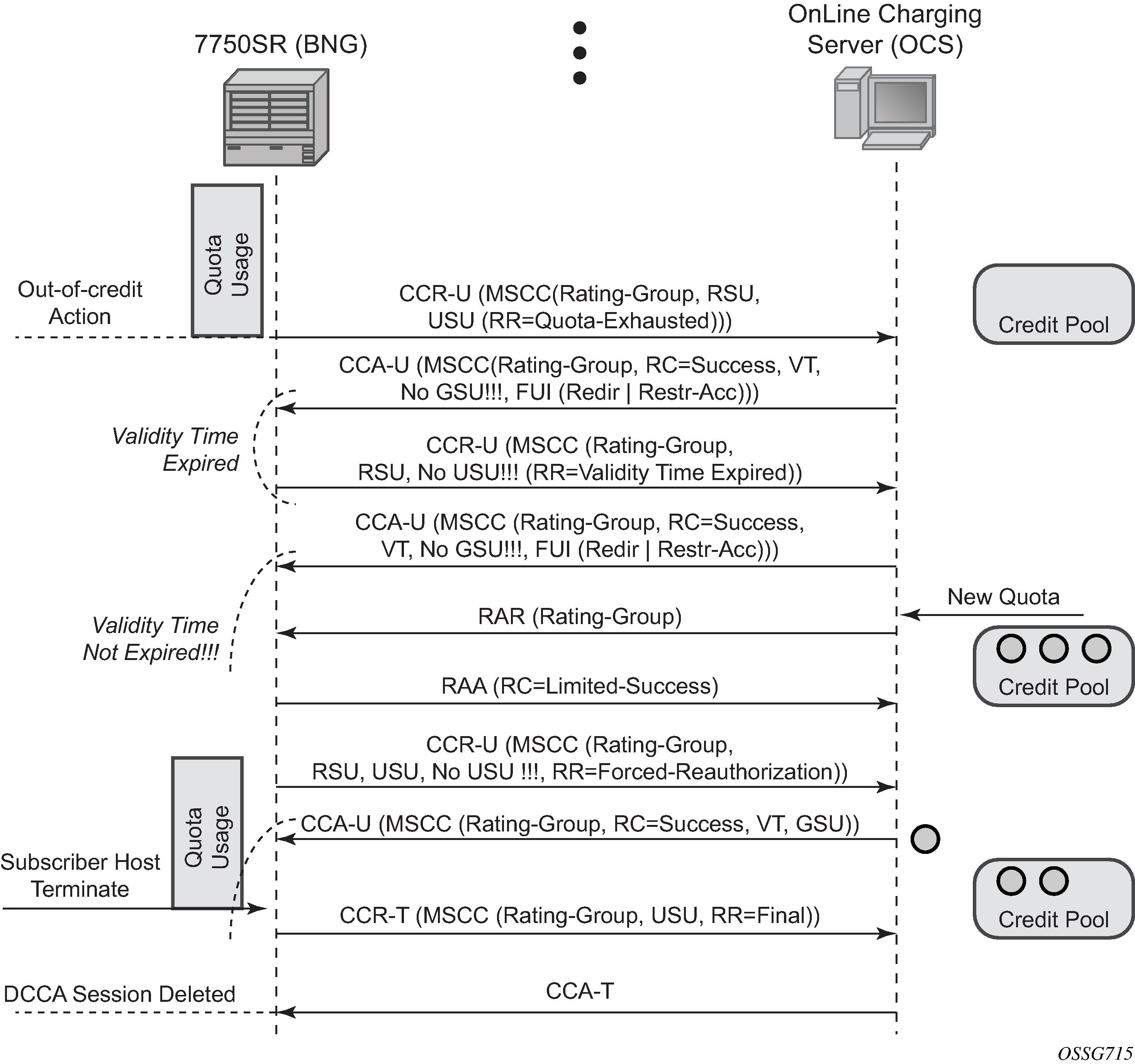
-
scenario 2
Scenario 2 depicts a terminate use case:
When the quota is depleted after reception of a Final Unit Indication with action set to Terminate, the subscriber host is disconnected. The configured out-of-credit-action is ignored in this case. See Online Charging scenario 2 – terminate.
Figure 5. Online Charging scenario 2 – terminate 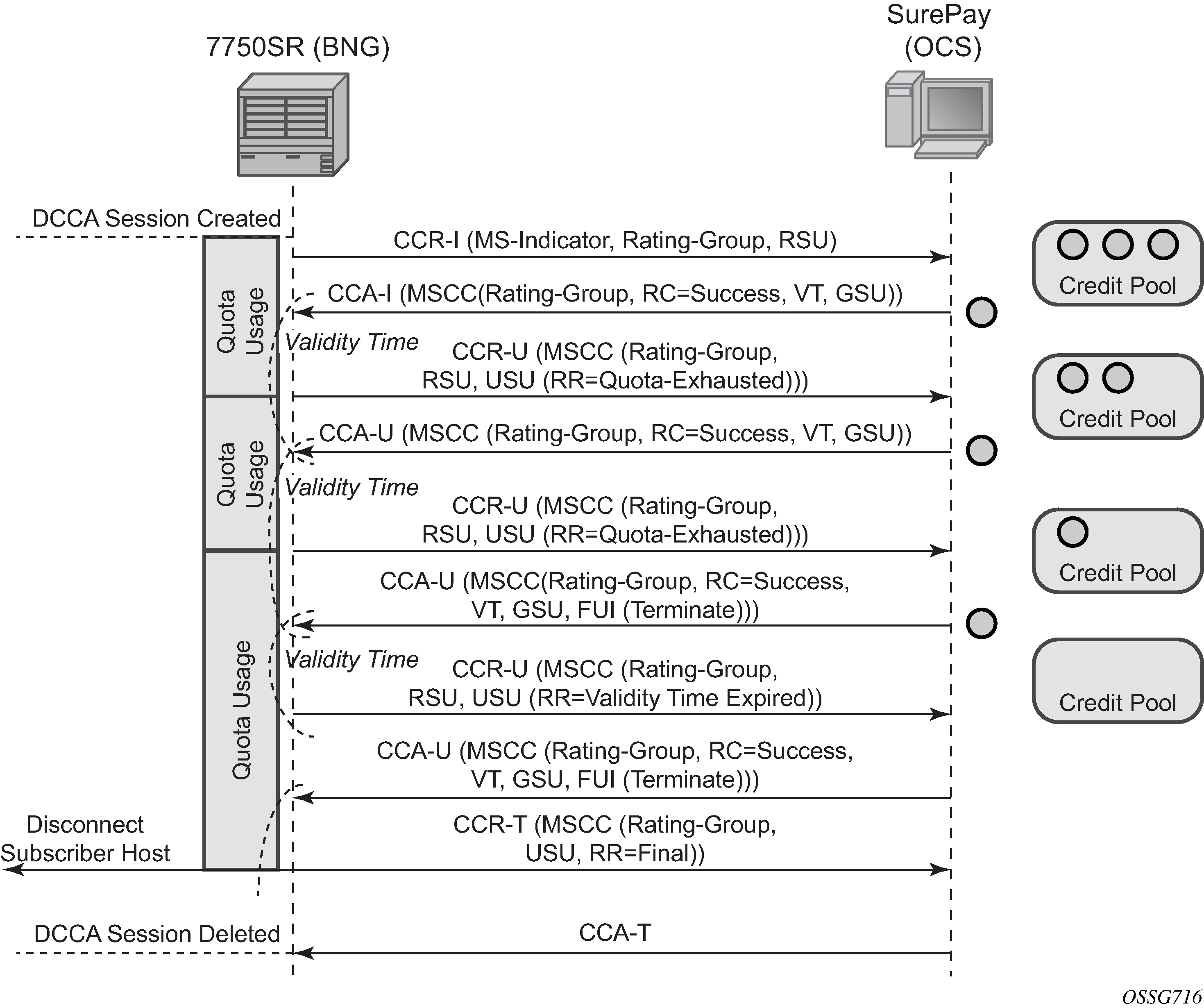
Abbreviations used in the previous drawings:
| Abbreviation | Expansion |
|---|---|
CCR |
Credit Control Request (-Initial, -Update, -Terminate) |
CCA |
Credit Control Answer (-Initial, -Update, -Terminate) |
RAR |
Re-Authentication Request |
RAA |
Re-Authentication Answer |
MSCC |
Multiple Services Credit Control |
GSU |
Granted Service Unit |
RSU |
Requested Service Unit |
USU |
Used Service Unit |
RC |
Result Code |
RR |
Reporting Reason |
VT |
Validity Time |
Diameter Gy out of credit actions
When all quota of a Diameter Gy credit control rating group is consumed and no additional quota is granted by the server, the out of credit action as configured in the credit-control-policy or category-map is executed.
The out of credit action is one of the following:
continue
Traffic corresponding to the rating group is no longer accounted for by credit control
.disconnect-host
The subscriber host or session is disconnected if any one of the categories within the category-map has expired credit
.block-category
Traffic corresponding to the rating group is blocked.
change-service-level
The service level is modified for the rating-group by applying one of the following:
a new PIR value to the corresponding queues or policers
an ingress or egress filter policy which could contain a filter to provide an HTTP redirect
Graceful service termination
RFC 4006, Diameter Credit Control Application, specifies a graceful service termination mechanism using the Final-Unit-Indication to indicate that an Answer message contains the final units for the service. When the final units are consumed, the action is specified with the Final-Unit-Action AVP.
Final-Unit-Indication ::= < AVP Header: 430 >
{ Final-Unit-Action }
*[ Restriction-Filter-Rule ]
*[ Filter-Id ]
[ Redirect-Server ]
In SR OS, with the Final-Unit-Action AVP = TERMINATE, the subscriber host or session is disconnected. With the Final-Unit-Action = REDIRECT or RESTRICT_ACCESS, the out-of-credit-action as specified in the credit-control-policy or category-map is executed. In the case of REDIRECT, the URL specified in the Redirect-Server AVP is used when IPv4 HTTP redirect is enabled as the out of credit action and the following conditions are met:
a Final-Unit-Indication AVP is present in the Multiple-Services-Credit-Control AVP of a CCA message
the Final-Unit-Action AVP is set to REDIRECT (1)
a Redirect-Server AVP is included with the following:
the Redirect-Address-Type AVP set to URL (2)
the Redirect-Server-Address AVP containing the URL to use for this rating group (category-map)
the out of credit action for the corresponding rating group is set to change-service-level using one of the following CLI commands:
configure subscriber-mgmt credit-control-policy policy-name out-of-credit-action change-service-level
configure subscriber-mgmt category-map category-map-name category category-name out-of-credit-action-override change-service-level
an IPv4 HTTP redirection action with allow-override is specified in the exhausted credit service level context for the corresponding rating group using the command configure subscriber-mgmt category-map category-map-name category category-name exhausted-credit-service-level ingress-ip-filter-entries entry entry-id action http-redirect url allow-override.
In all other cases, the URL specified in the Redirect-Server-Address AVP is ignored and the configured URL is used if HTTP redirect is enabled as the out of credit action.
The Restriction-Filter-Rule and Filter-Id AVPs included in the Final-Unit-Indication AVP are ignored.
Use the following show commands to find the active URL when an out-of-credit-action change-service-level is triggered that includes an IPv4 HTTP redirect action in the credit control ingress IP filter entries:
show service active-subscribers filter [subscriber sub-ident-string]
This command displays the active IPv4 ingress filter identifier.
show filter ip ip-filter-id
With the filter identifier found in the previous command, this command displays the credit control inserted entries (Origin = ‟Inserted on ingress by Credit Control”), including the IPv4 HTTP redirect action with the static configured URL. The optional allow-radius-override flag may be shown. This flag is common for RADIUS and Diameter-based overrides, where the flag indicates that the URL may have been overridden by the Diameter Credit Control server. Use the next command to determine if an override was specified.
show service active-subscribers credit-control
This command displays the URL received from the Diameter Credit Control server for a rating group or category with ‟Out of Credit Action = ChangeServiceLevel” active. The URL is displayed in the ‟HTTP Rdr URL Override” field.
Extended Failure Handling (EFH)
In a Diameter Gy application, that is, a Diameter Credit Control Application (DCCA), Credit Control Failure Handling (CCFH) determines the behavior of a credit control client in fault situations. When the CCFH value is set to CONTINUE and a failure occurs, the credit control client first attempts a failover procedure. If failover is not enabled or not supported by both client and server, or the failover is not successful, the client deletes the credit control session and continues the service to the end user without the Diameter Gy session until the user disconnects.
Extended Failure Handling (EFH) enables the credit control client to establish a new Diameter Gy session with the Online Charging Server (OCS) in failure situations where CCFH is triggered and the CCFH value is set to CONTINUE.
The following occurs when EFH is enabled and the CCFH value is set to CONTINUE.
Service to the end user continues during failures (such as lost connectivity to the OCS).
A new Diameter Gy session is established when the failure is restored.
Usage information is kept up-to-date for reporting purposes (optional).
Extended Failure Handling (EFH) shows an example of EFH.
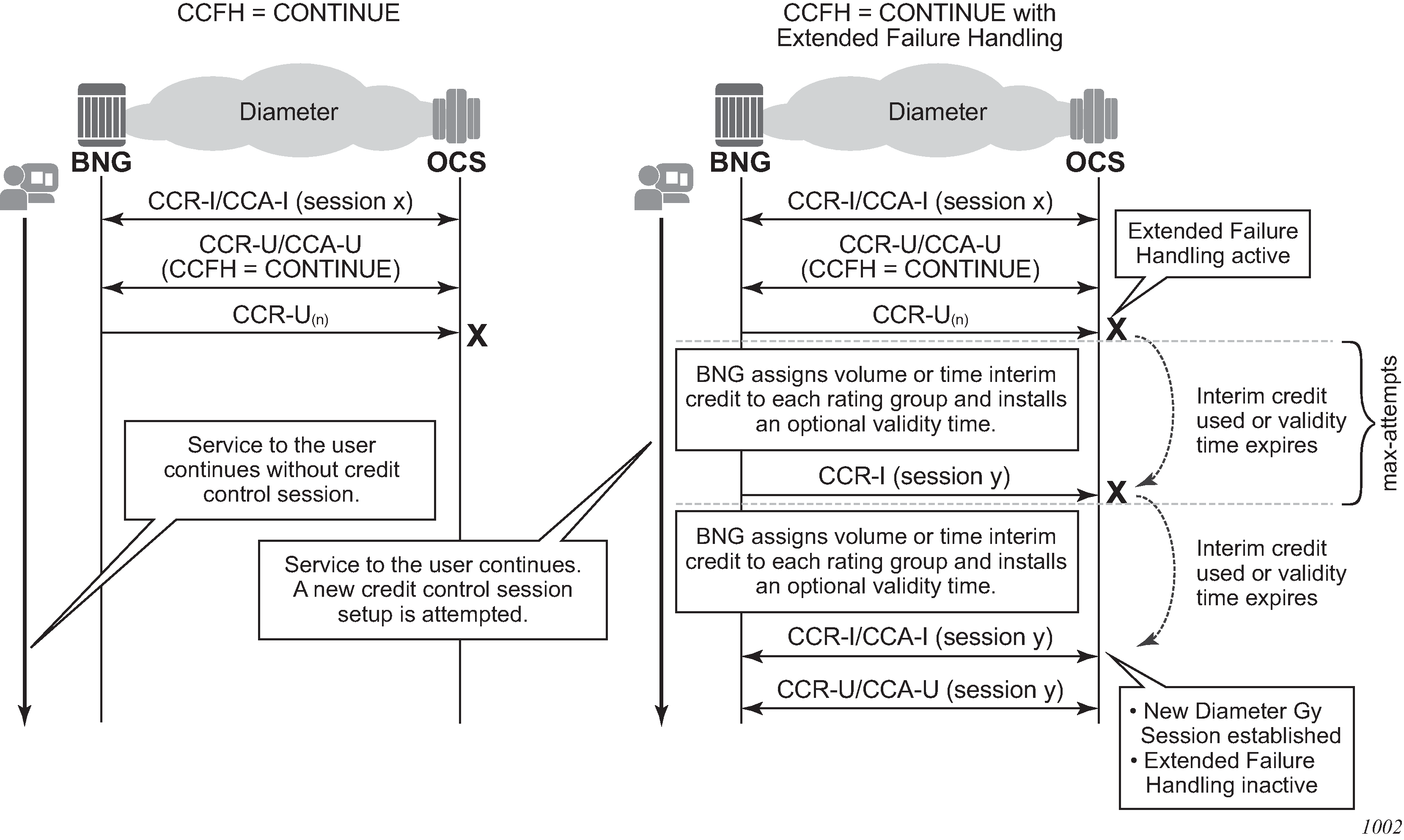
If a failure occurs when EFH is active, a preconfigured time interim credit or volume interim credit with an optional validity time is assigned to all rating groups. A new Diameter Gy session setup is attempted each time the interim credit is used or the validity time expires. The following occurs when an attempt to re-establish the Diameter Gy session is made.
The user session continues normally and EFH becomes inactive when the Diameter Gy session is successfully established with the OCS.
A new interim credit with optional validity time is assigned to all rating groups if the Diameter Gy session is not established with the OCS.
The user session is terminated if the Diameter Gy session is still not established with the OCS after a configurable maximum number of attempts.
EFH example call flow
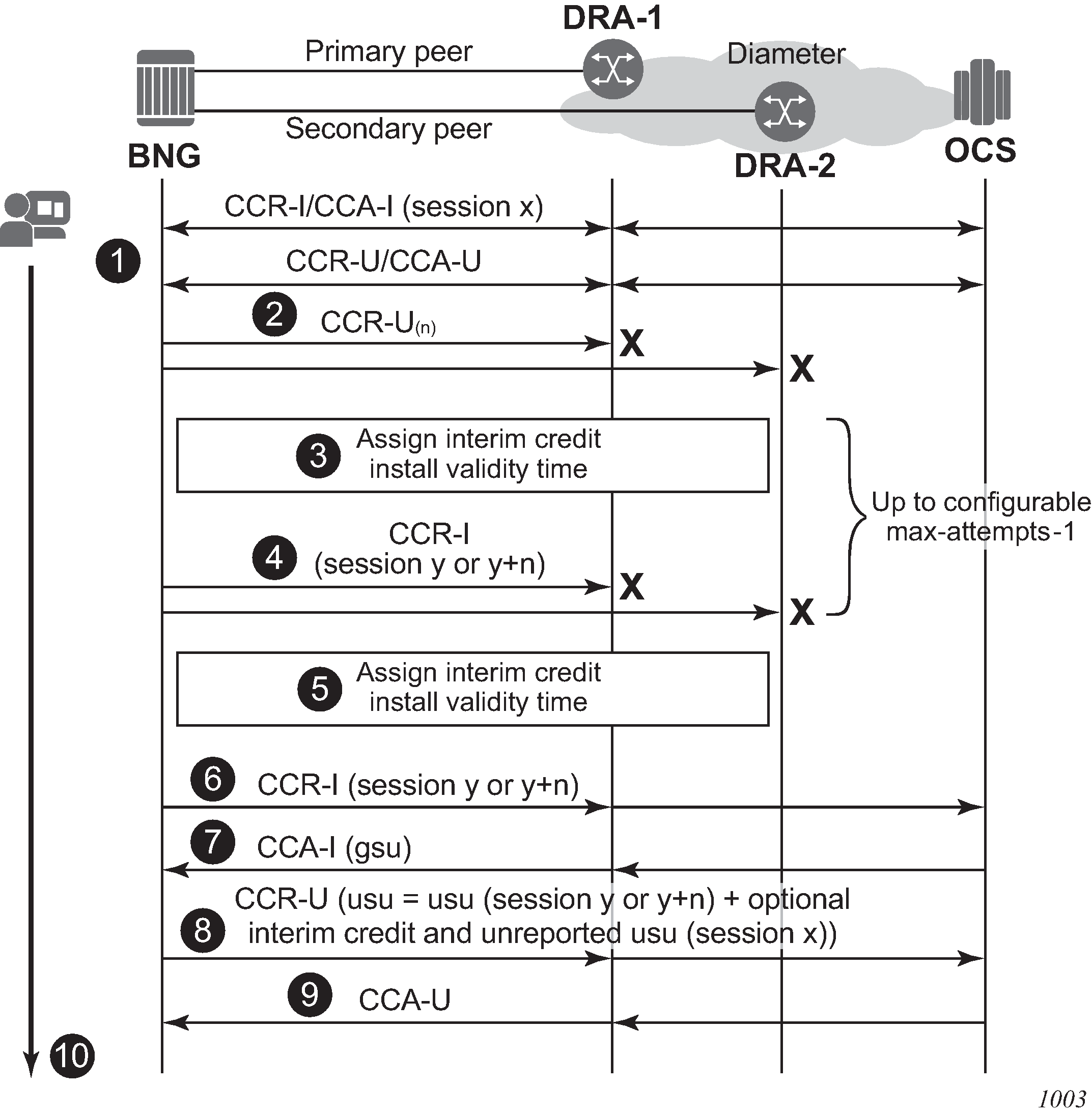
EFH - example call flow shows a sample call flow with EFH enabled. The following describes the call flow.
A Diameter Gy session is established between the Broadband Network Gateway (BNG), or credit control client, and the OCS, or credit control server.
A Credit Control Request Update (CCR-U) message is sent via the primary peer but no answer (CCA-U) is received. A timeout occurs which triggers a failover to the secondary peer. The same CCR-U is sent via the secondary peer. Again no answer is received. Because the CCFH value is set to CONTINUE for this session, EFH is activated.
The following EFH actions occur:
Service to the user continues uninterrupted.
If this is the first attempt to re-establish a Diameter Gy session:
The failed Diameter Gy session (session ID x) is terminated without sending a CCR-T (Terminate) message.
The unreported used credits for each rating group are stored in an EFH unreported credit counter.
A new Diameter Gy session (new session ID y) is created internally but is not yet established with the OCS; the CCR-I (Initial) message is sent later.
For all subsequent attempts to re-establish a Diameter Gy session:
The failed Diameter Gy session (session ID y or y+n) is terminated without sending a CCR-T (Terminate) message.
The unreported used interim credit for each rating group is added to the EFH unreported credit counter.
A new Diameter Gy session is created internally but not yet established with the OCS: the CCR-I (Initial) message is sent later. The internal Diameter session is created with the same session ID (y) or a new session ID (y+n) based on a configuration knob.
Pre-configured interim credit is assigned to all rating groups and an optional validity time is installed.
If either all interim credit is used or the validity time expires for one of the rating group, an attempt is made to establish the new Diameter Gy session (session ID y or y+n) with the OCS.
A CCR-I message is sent via the primary peer but no answer (CCA-I) is received. A timeout occurs which triggers a failover to the secondary peer. The same CCR-I is sent via the secondary peer. Again no answer is received.
EFH stays active for this user session.
Steps 3 and 4 can be repeated multiple times until the maximum number of interim credit allocations is reached and the user session is terminated (not shown in this example call flow).
The EFH actions are as follows:
Service to the user continues uninterrupted.
The failed Diameter Gy session (session ID y or y+n) is terminated without sending a CCR-T (Terminate) message.
The unreported used interim credit for each rating group is added to the EFH unreported credit counter.
A new Diameter Gy session is created internally but is not yet established with the OCS: the CCR-I (Initial) message is sent later. The Diameter session is created with the same session ID (y) or a new session ID (y+n) based on the configuration.
Pre-configured interim credits are assigned to all rating groups and an optional validity time is installed.
If either all interim credits are used or the validity time expires for one of the rating groups, an attempt is made to establish the new Diameter Gy session (session ID y or y+n) with the OCS.
A CCR-I message is sent via the primary peer.
An answer (CCA-I) is received with new granted service units (credit). Because communication with the OCS is restored, EFH becomes inactive.
The new Diameter Gy session resumes normal operation. Optionally, the EFH unreported credit usage is reported together with the usage from the newly granted credit in the next CCR-U credit negotiation for the rating group.
An answer (CCA-U) is received.
The service to the user continues and is uninterrupted during the OCS connectivity failure.
EFH triggers
For EFH to become active, the Credit Control Failure Handling (CCFH) value must be set to CONTINUE.
For a new session, the CCFH value is set in the configuration:
configure
subscriber-mgmt
diameter-application-policy <application-policy-name> [create]
on-failure [failover {enabled|disabled}] handling continue
For ongoing sessions, the CCFH value is determined from the configuration or can be overridden by the OCS by including the following AVP in an answer message (CCA-I or CCA-U):
[427] Credit-Control-Failure-Handling AVP = CONTINUE (1)
EFH is triggered when the CCFH value is set to CONTINUE and one of the following conditions occurs:
transmit failure
failure to send a CCR-I or CCR-U message
EFH trigger: transmit failure shows an example of a transmit failure.
Figure 8. EFH trigger: transmit failure 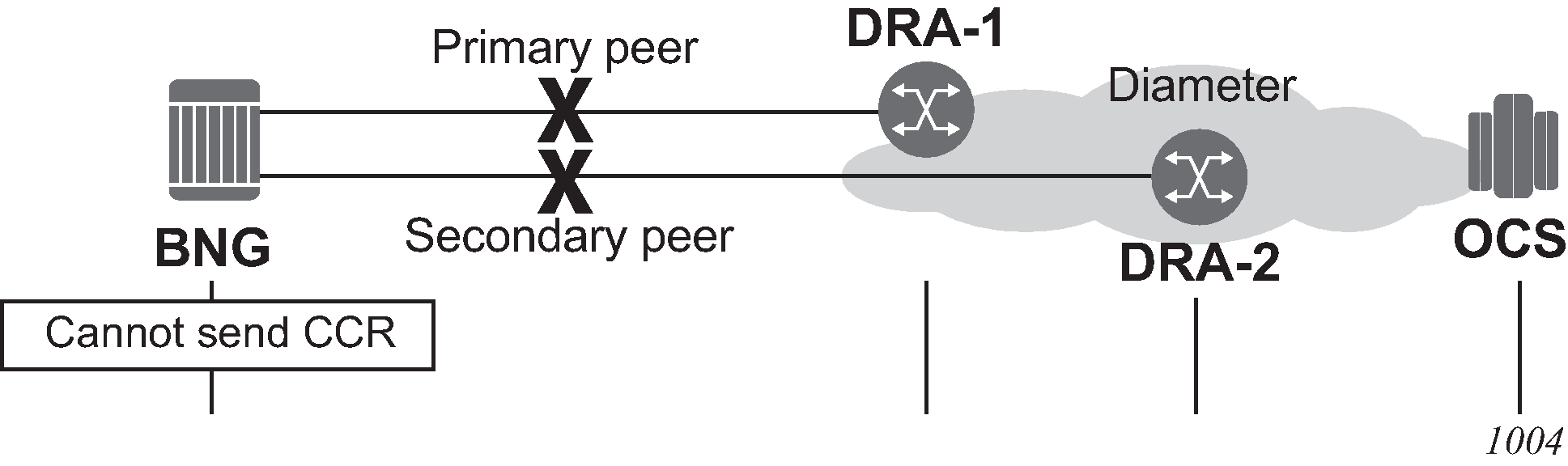
timeout
failure to receive an answer (CCA-I or CCA-U) within the configured timeout
EFH trigger: timeout shows an example of a timeout.
Figure 9. EFH trigger: timeout 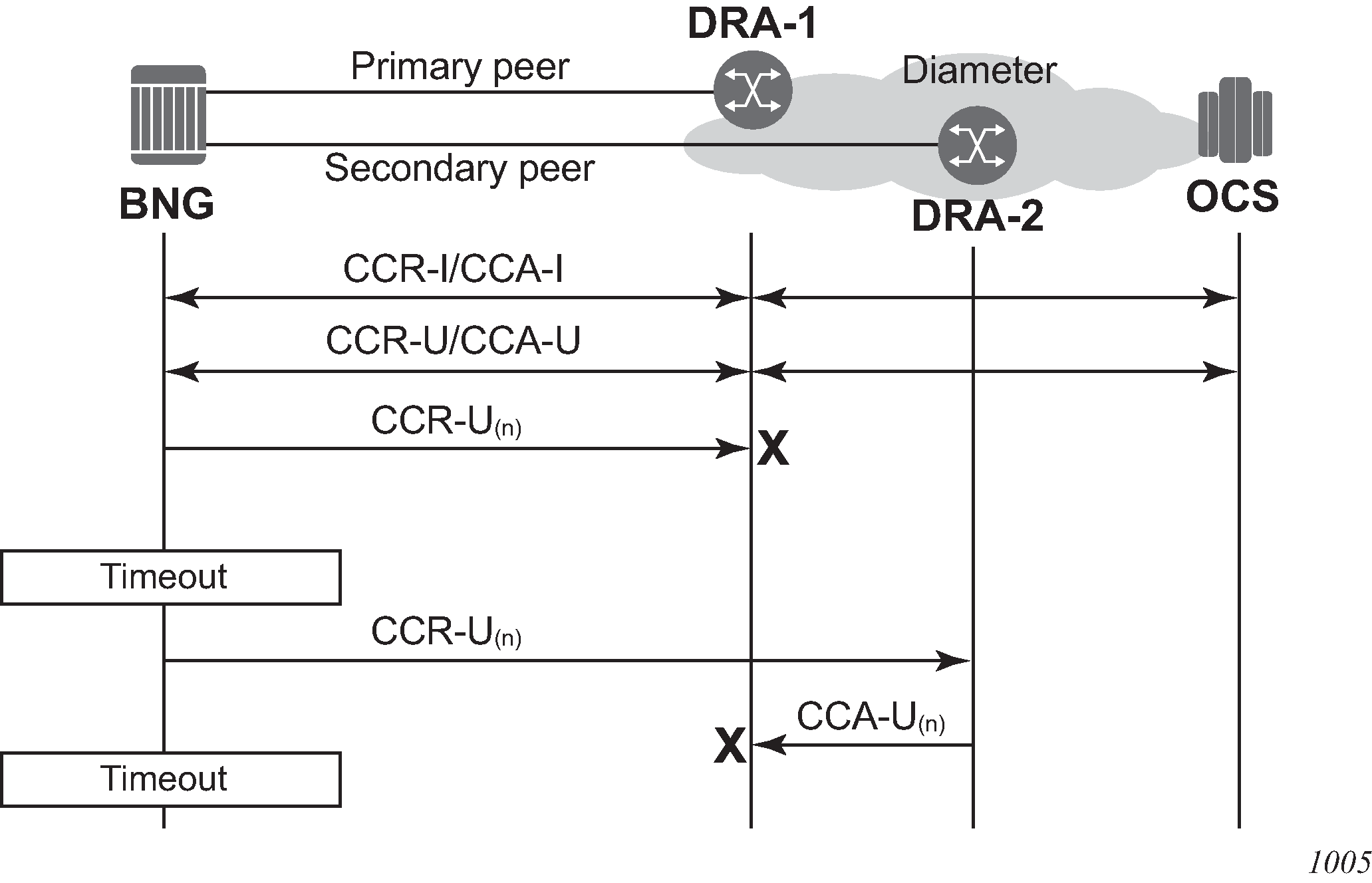
protocol error
failure because of a protocol error; seen as a Result-Code at command level in an answer message (CCA-I or CCA-U)
EFH trigger: protocol error shows an example of a protocol error.
Figure 10. EFH trigger: protocol error 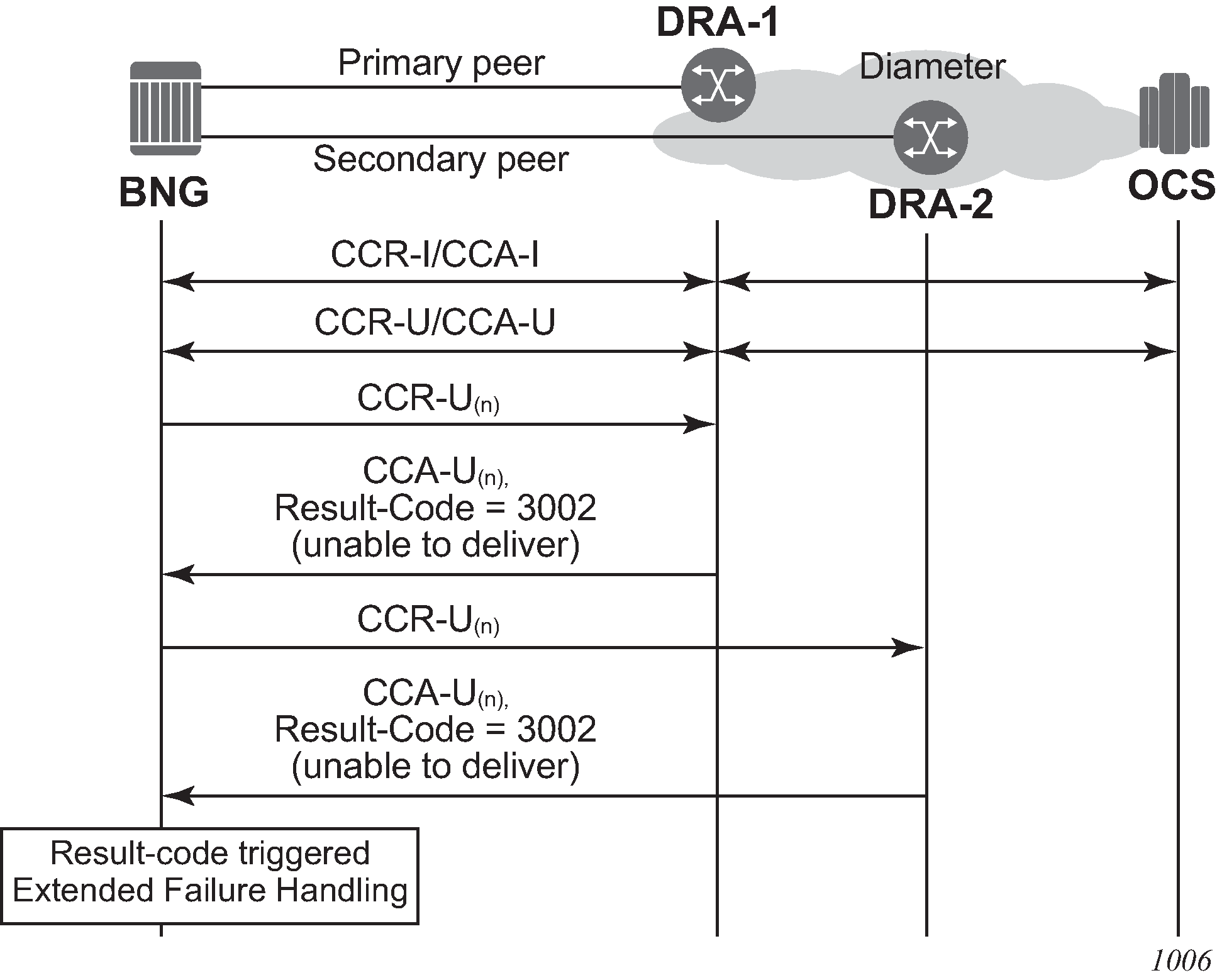
failure
reception of unknown Result-Code values in a Credit Control Answer message. Diameter Gy known transient and permanent failures result-code values lists the known Transient and Permanent Failures Result-Code values.
Table 4. Diameter Gy known transient and permanent failures result-code values Result code Command level MCSCC level CCA-I CCA-U 4001
DIAMETER_AUTHENTICATION_REJECTED
known
known
unknown
4010
DIAMETER_END_USER_SERVICE_DENIED
unknown
known
known
4011
DIAMETER_CREDIT_CONTROL_NOT_APPLICABLE
known
known
known
4012
DIAMETER_CREDIT_LIMIT_REACHED
unknown
known
known
5003
DIAMETER_AUTHORISATION_REJECTED
known
known
known
5030
DIAMETER_USER_UNKNOWN
known
known
unknown
5031
DIAMETER_RATING_FAILED
unknown
known
known
a Diameter Gy message decoding error, for example (this is not an exhaustive list):
a missing Result-Code AVP
an unknown command code received
an incorrect session ID, origin host or origin realm in CCA
quota received for unexpected rating group
quota received with Result-Code 4012 (Credit Limit Reached)
Assigning interim credit
EFH interim credit can be specified in two ways:
as a single volume interim credit value that is assigned to all rating groups of the Diameter Gy session with active EFH and that have no default credits configured
-
configure subscriber-mgmt diameter-application-policy <application-policy-name> create gy extended-failure-handling interim-credit volume <credits> {bytes|kilobytes|megabytes|gigabytes} -
as a single volume or time interim credit value per rating group (default credit)
The activity threshold configured in the category map also applies to all rating groups that have time-based interim credit assigned while EFH is active.
-
configure subscriber-mgmt category-map <category-map-name> create activity-threshold <kilobits-per-second> category <category-name> create default-credit time <seconds> default-credit volume <credits> <bytes|kilobytes|megabytes|gigabytes>
A single validity time value can be specified and applied to all rating groups that have interim credit assigned, regardless of whether the interim credit is configured for all rating groups in the Diameter application policy or per rating group in the category map.
configure subscriber-mgmt
diameter-application-policy <application-policy-name> create
gy
extended-failure-handling
interim-credit
validity-time <seconds>
The maximum number of times that interim credit is assigned to all rating groups of a Diameter Gy session when EFH is active can be limited in the configuration. The max-attempts value also corresponds with the maximum number of attempts to establish a new Diameter Gy session with the OCS (the default maximum attempts = 10).
configure subscriber-mgmt
diameter-application-policy <application-policy-name> create
gy
extended-failure-handling
interim-credit
max-attempts <count>
max-attempts infinite
An attempt to establish a new Diameter Gy session with the OCS is made when one of the following conditions occurs.
The assigned interim credit for one of the rating groups is used.
The validity time of the interim credit for one of the rating groups expires.
When the maximum number of attempts is reached and a new Diameter Gy session is not yet successfully established, then the user session is terminated; that is, the corresponding subscriber hosts are deleted from the system.
The reporting of used EFH interim credit can be enabled using the following CLI command:
configure subscriber-mgmt
diameter-application-policy <application-policy-name> create
gy
extended-failure-handling
interim-credit
[no] reporting
With reporting enabled, the following accumulated used credit is reported when a new Diameter Gy session is established with the OCS and usage reporting is triggered for a rating group:
unreported used credit granted via the initial Diameter Gy session that caused the EFH activation
used interim credit when EFH was active
used credit granted via the new Diameter Gy session
By default, reporting is disabled and all the used credit from the initial Gy session and all used interim credit are discarded.
Enabling EFH
EFH is enabled by specifying no shutdown in the extended-failure-handling CLI context in a Gy Diameter application policy.
configure subscriber-mgmt
diameter-application-policy <application-policy-name> create
gy
extended-failure-handling
no shutdown
EFH states lists the EFH states for a Diameter Gy session.
| EFH state | Description |
|---|---|
Disabled |
EFH is disabled (shutdown). EFH cannot be triggered for the Diameter Gy session. |
Enabled - active |
EFH is enabled (no shutdown) and active. A failure event occurred that triggered EFH. Interim credit is assigned to all rating groups and when either the validity time expires or the interim credit is used for a rating group, a new attempt is made to establish a Diameter Gy session with the OCS. |
Enabled - inactive |
EFH is enabled (no shutdown) and inactive. A Diameter Gy session with the OCS is established. EFH is activated for the Diameter Gy session if a trigger condition occurs. |
Configuration example 1 - single volume interim credit value
configure subscriber-mgmt
diameter-application-policy gy-1 create
--- snip ---
on-failure handling continue
gy
--- snip ---
extended-failure-handling
no new-session-id # default
interim-credit
no reporting # default
volume 100 megabytes
validity-time 900
max-attempts 96
exit
no shutdown
exit
exit
exit
In this example, EFH is enabled and when active, 100 Mbytes of volume interim credit is assigned to all rating groups of the Diameter Gy session with a validity time of 900 s. The maximum number of attempts to establish a Diameter Gy session with the OCS is 96.
Therefore, a maximum of 96 x 100 Mbytes or 9.6 Gbytes can be consumed before the user session is terminated (that is, the subscriber host is deleted from the system) when the OCS remains unreachable. Alternatively, when less than 100 Mbytes per rating group is consumed every 15 minutes (900 s), the user is disconnected after 900 s x 96 = 24 hours when the OCS remains unreachable.
Configuration example 2 - interim credit values per rating group
configure subscriber-mgmt
category-map "cat-map-1" create
activity-threshold 10
category "cat-1" create
description "Time interim credit per category"
default-credit time 900
rating-group 1
queue 1 ingress-egress
exit
category "cat-2" create
description "Volume interim credit per category"
default-credit volume 10 megabytes
rating-group 2
queue 2 ingress-egress
exit
category "cat-3" create
no default-credit
rating-group 3
queue 3 ingress-egress
exit
exit
diameter-application-policy gy-1 create
--- snip ---
on-failure handling continue
gy
--- snip ---
extended-failure-handling
new-session-id
interim-credit
reporting
volume 100 megabytes
validity-time 900
max-attempts 96
exit
no shutdown
exit
exit
exit
In this example, EFH is enabled and when active, the following interim credit is assigned:
900 s of time interim credit to rating group 1 (category cat-1) with a validity time of 900 s. The activity threshold applies. When the usage stays below 10 kbytes/s, no time credit is used.
10 Mbytes of volume interim credit to rating group 2 (category cat-2) with a validity time of 900 s
100 Mbytes of volume interim credit to rating group 3 (category cat-3) with a validity time of 900 s
For inactive users, the validity time ensures that new Diameter Gy session connection attempts with the OCS are made at regular intervals.
For each attempt to establish a Diameter Gy session with the OCS, a new session ID is used.
When a new Diameter Gy session is successfully established, the EFH unreported credit for each rating group is included in the used service units when reporting is triggered for that rating group on the new Diameter Gy session.
When no new Diameter Gy session is established after 96 attempts, the user session is terminated; that is, the subscriber hosts are deleted from the system.
Monitoring the EFH state
Subscribers with Diameter Gy sessions that have EFH enabled can be displayed with the following CLI command:
# show service active-subscribers credit-control extended-failure-handling [state] [summary]
where the EFH state can be set to:
active
shows subscribers with Diameter Gy sessions that have EFH enabled and EFH is active
inactive
shows subscribers with Diameter Gy sessions that have EFH enabled and EFH is inactive
all
shows subscribers with Diameter Gy sessions that have EFH enabled and EFH is active or inactive.
Example output:
A:BNG-1# show service active-subscribers credit-control extended-failure-handling
===============================================================================
Active Subscribers
===============================================================================
-------------------------------------------------------------------------------
Subscriber ipoe-msap-002 (sub-profile-1)
-------------------------------------------------------------------------------
-------------------------------------------------------------------------------
(1) SLA Profile Instance sap:[1/1/4:1201.2] - sla:sla-profile-3
-------------------------------------------------------------------------------
Credit Control Policy: cc-policy-1
Category Map : cat-map-1
Diameter Session Gy : bng.domain.com;1464610029;840
CC Failure Handling : continue
Extended Failure Handling (EFH)
State : active
Attempts : 1 Maximum Attempts : 10
Active time : 0d 00:00:10
Total Active time : 0d 00:00:10
Total Active Count : 1
Category Name : cat-1-time
Ingress Queues : 1
Egress Queues : 1
Ingress Policers :
Egress Policers :
Credit Volume Used : 0 Credit Time Used : 11
Credit Volume Avail. : 0 Credit Time Avail. : 589
Credit Volume Thres. : 0 Credit Time Thres. : 0
Credit Expired : False Credit Negotiating : False
Out Of Credit Action : None Quota Holding Time : 0
Validity Time Used : 0 Validity Time Avail. : 0
EFH Unreported Credit
Current Volume : 0 Current Time : 601
Total Volume : 0 Total Time : 601
Category Name : cat-2-volume
Ingress Queues : 4
Egress Queues : 4
Ingress Policers :
Egress Policers :
Credit Volume Used : 38400 Credit Time Used : 0
Credit Volume Avail. : 10447360 Credit Time Avail. : 0
Credit Volume Thres. : 0 Credit Time Thres. : 0
Credit Expired : False Credit Negotiating : False
Out Of Credit Action : None Quota Holding Time : 0
Validity Time Used : 13 Validity Time Avail. : 587
EFH Unreported Credit
Current Volume : 1527600 Current Time : 0
Total Volume : 1527600 Total Time : 0
-------------------------------------------------------------------------------
IP Address
MAC Address Session Origin Svc Fwd
-------------------------------------------------------------------------------
10.1.1.101
00:51:00:00:00:02 IPoE DHCP 1000 Y
-------------------------------------------------------------------------------
-------------------------------------------------------------------------------
Number of active subscribers : 1
===============================================================================
The following information is displayed In the Extended Failure Handling (EFH) section of the example:
Extended Failure Handling (EFH)
State : active
State indicates that EFH is enabled and active. Another possible state is ‟inactive”. When EFH is disabled, no EFH information is included.
Attempts : 1 Maximum Attempts : 10
Attempts indicates the number of times interim credit has been assigned to all categories followed by an attempt to establish a new Diameter Gy session with the OCS. When the attempt to establish a new Diameter Gy session with the OCS is still failing after the Maximum Attempts value is reached, then the user session is terminated (that is, the subscriber hosts are deleted from the system).
Active time : 0d 00:00:10
Active time indicates the time because the EFH state became active for this subscriber session.
Total Active time : 0d 00:00:10
Total Active Count : 1
Total Active time indicates the accumulative time of all occurrences that EFH was active during the lifetime of this subscriber session.
Total Active Count indicates the number of times that EFH was active during the lifetime of this subscriber session.
For each category (rating group), the EFH Unreported Credit is displayed:
EFH Unreported Credit
Current Volume : 0 Current Time : 601
Total Volume : 0 Total Time : 601
The Current Volume and Current Time counters contain, respectively, the unreported volume and time credit for the current occurrence of the EFH in an active state. These counters include the unreported used credit for the initial Diameter Gy session that caused the EFH state to become active and the unreported interim credit from previous attempts. Used interim credit for the current attempt per category (rating group) is shown in the following counters:
Credit Volume Used : 0 Credit Time Used : 11
Credit Volume Avail. : 0 Credit Time Avail. : 589
The Total Volume and Total Time counters contain respectively the accumulated total unreported volume and time credit for the previous occurrences of EFH active state. The total counters are updated when the EFH state toggles from active to inactive. When interim credit reporting is enabled, the counters are reset to zero when the actual usage reporting happens for that rating group. When interim credit reporting is disabled, the counters are accumulating the total unreported credit during the lifetime of the subscriber session.
Current and Total Volume EFH Unreported Credit counters are the sum of used ingress and egress octets.
For each category (rating group), the validity time is displayed:
Validity Time Used : 13 Validity Time Avail. : 587
The following fields are only displayed when the EFH state is active:
Extended Failure Handling (EFH): ‟Attempts”, ‟Max Attempts” and ‟Active time”
EFH Unreported Credit: ‟Current Volume” and ‟Current Time”
When EFH is disabled (shutdown), then the EFH information is not included in the credit control output.
Additional call flow examples
User disconnects while EFH is active
The call flow in EFH call flow - user disconnects during EFH shows a scenario where EFH is activated before the session is established with the OCS. The scenario is similar when EFH is activated by a CCR-U message.
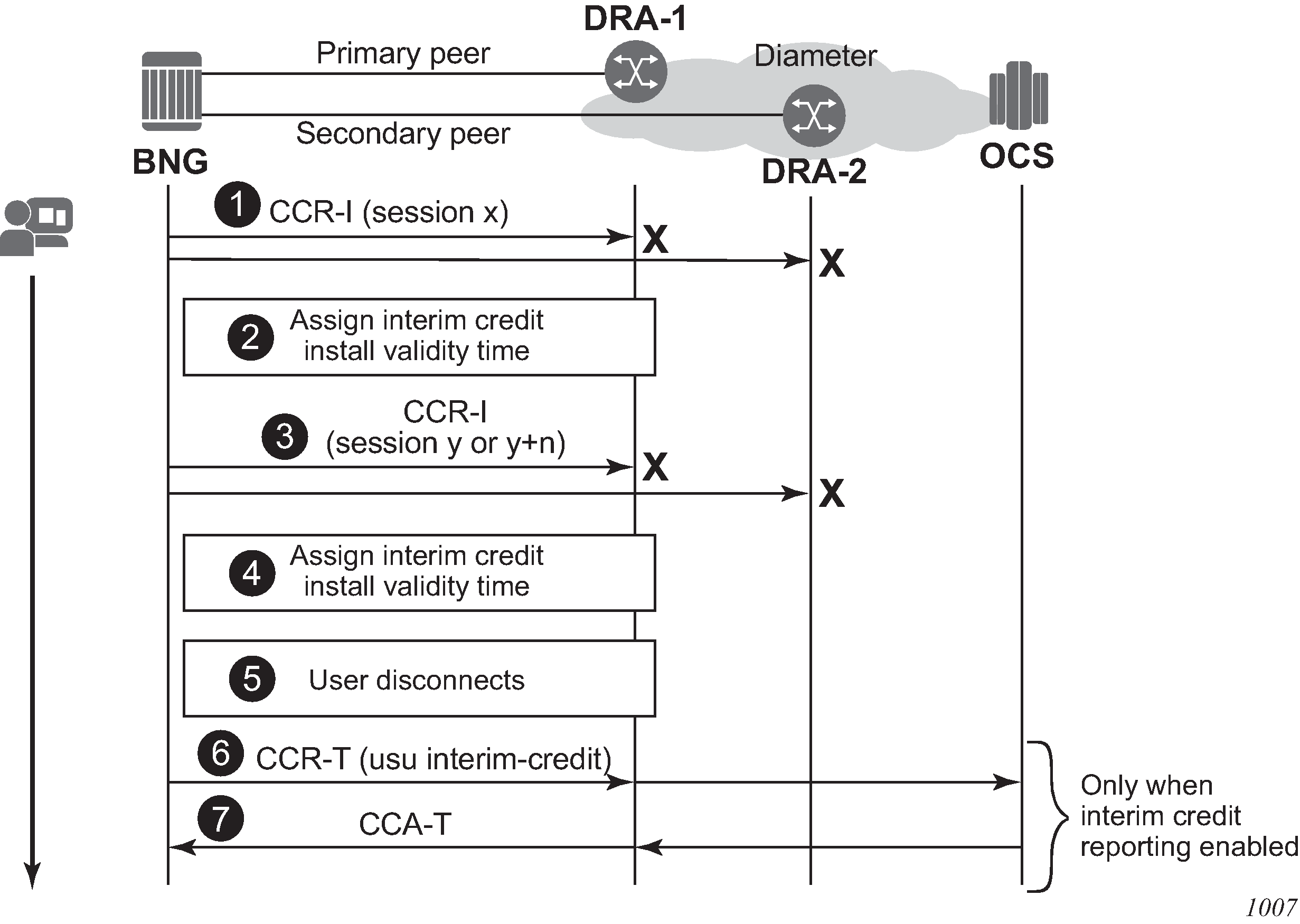
The initial Diameter Gy session setup fails: the CCR-I message sent to the primary peer times out or an error condition occurs that triggers Diameter Gy EFH. If failover is enabled, the CCR-I message is resent on the secondary peer. The CCR-I message sent to the secondary peer times out or an error condition occurs that triggers Diameter Gy EFH.
EFH becomes active for this user session. Interim credit is assigned to all rating groups and, optionally, a validity time is installed.
Interim credit is exhausted for a rating group or a validity time expires. A new attempt is made to establish the Diameter Gy session with the OCS; a CCR-I message is sent to the primary peer. A timeout or an error condition occurs that triggers Diameter Gy EFH to become active. If failover is enabled, the CCR-I message is resent on the secondary peer. The CCR-I message sent to the secondary peer times out or an error condition occurs that triggers EFH.
Interim credit is assigned to all rating groups and, optionally, a validity time is installed.
The user disconnects, resulting in a termination of the user session.
If interim credit reporting is enabled, a CCR-T is sent reporting the accumulated consumed interim credit.
If the OCS becomes reachable, a CCA-T may be received. Because the Diameter Gy session was not established with the OCS, the result code is DIAMETER_UNKNOWN_SESSION_ID.
Maximum number of attempts is reached
The call flow in EFH call flow - maximum attempts reached shows a scenario where the maximum attempts is reached to establish a Diameter Gy session with the OCS.
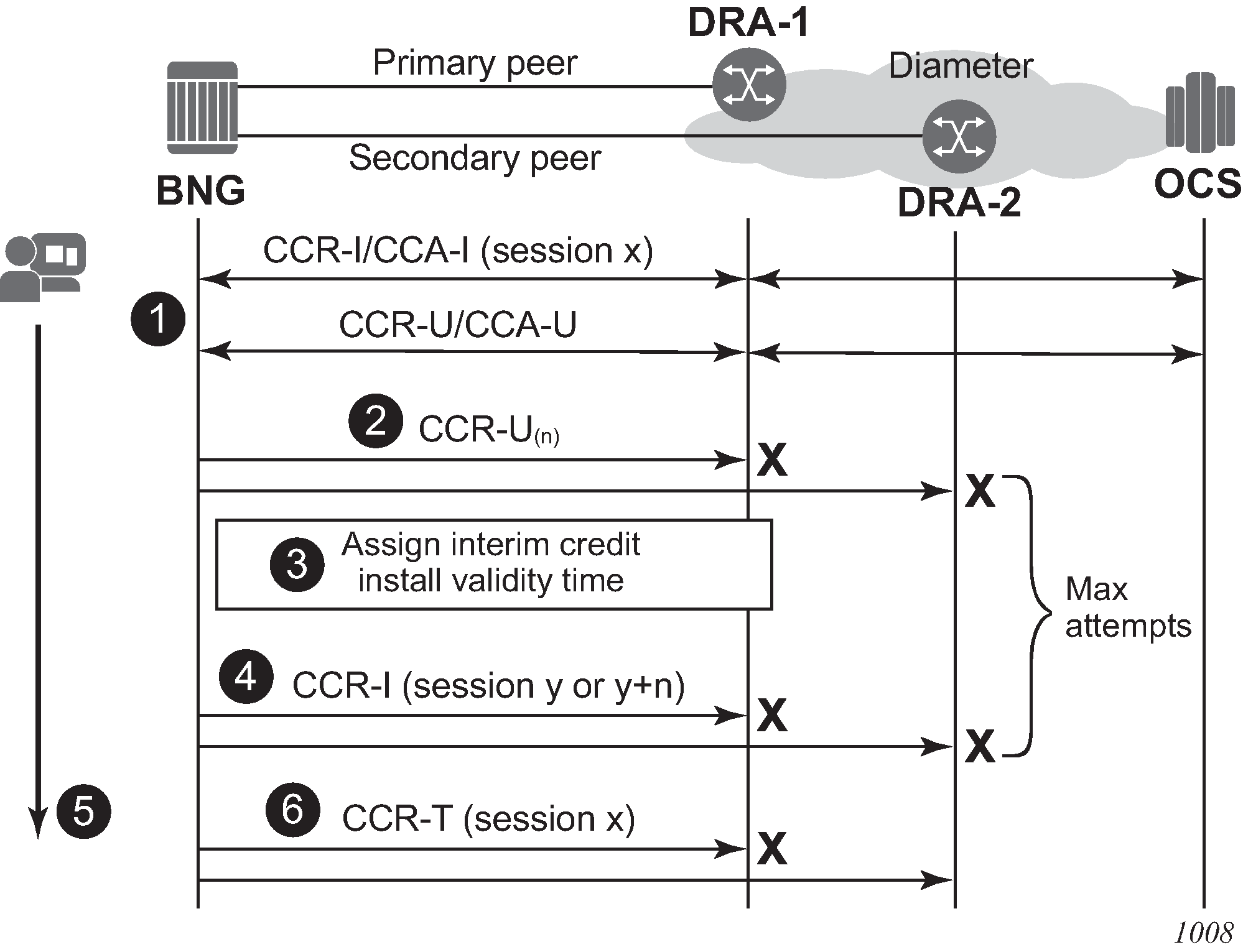
A Diameter Gy session is in progress.
An update message sent to the primary peer times out or an error condition occurs that triggers Diameter Gy EFH. If failover is enabled, the CCR-U message is resent on the secondary peer. The CCR-U message sent to the secondary peer times out or an error condition occurs that triggers Diameter Gy EFH.
EFH becomes active for this user session. Interim credit is assigned to all rating groups and, optionally, a validity time is installed.
Interim credit is exhausted for a rating group or a validity time expires. A new attempt is made to establish the Diameter Gy session with the OCS; a CCR-I message is sent to the primary peer. A new session ID is used for the first attempt. For subsequent attempts, a configuration command determines if a new or the same session ID is used. A timeout or an error condition occurs that triggers Diameter Gy EFH to become active. If failover is enabled, the CCR-I message is resent on the secondary peer. The CCR-I message sent to the secondary peer times out or an error condition occurs that triggers EFH.
Steps 3 and 4 are repeated until the maximum attempts for interim credit is reached.
The user session is disconnected; that is, the subscriber hosts are deleted from the system.
When interim credit reporting is enabled, a CCR-T is sent, reporting the accumulated consumed interim credit: the unreported quota from the initial session x and the accumulated interim credit.
EFH activation triggered during Final Unit Indication
This section describes two scenarios where EFH is activated during a graceful service termination initiated by the OCS with a Final Unit Indication (FUI) AVP. A graceful service termination with FUI action equal to REDIRECT or RESTRICT_ACCESS relies on a validity time or RAR to trigger a new credit negotiation with the OCS. Because the OCS is unreachable, it cannot be verified if a new quota has been granted. With EFH enabled, interim credit is assigned to guarantee service to the user until the connectivity with OCS is restored.
In the first scenario shown in EFH call flow - FUI scenario 1, the OCS initiates the graceful service termination with the Final-Unit-Action AVP = REDIRECT or RESTRICT_ACCESS. EFH is activated immediately after the out-of-credit action is installed.
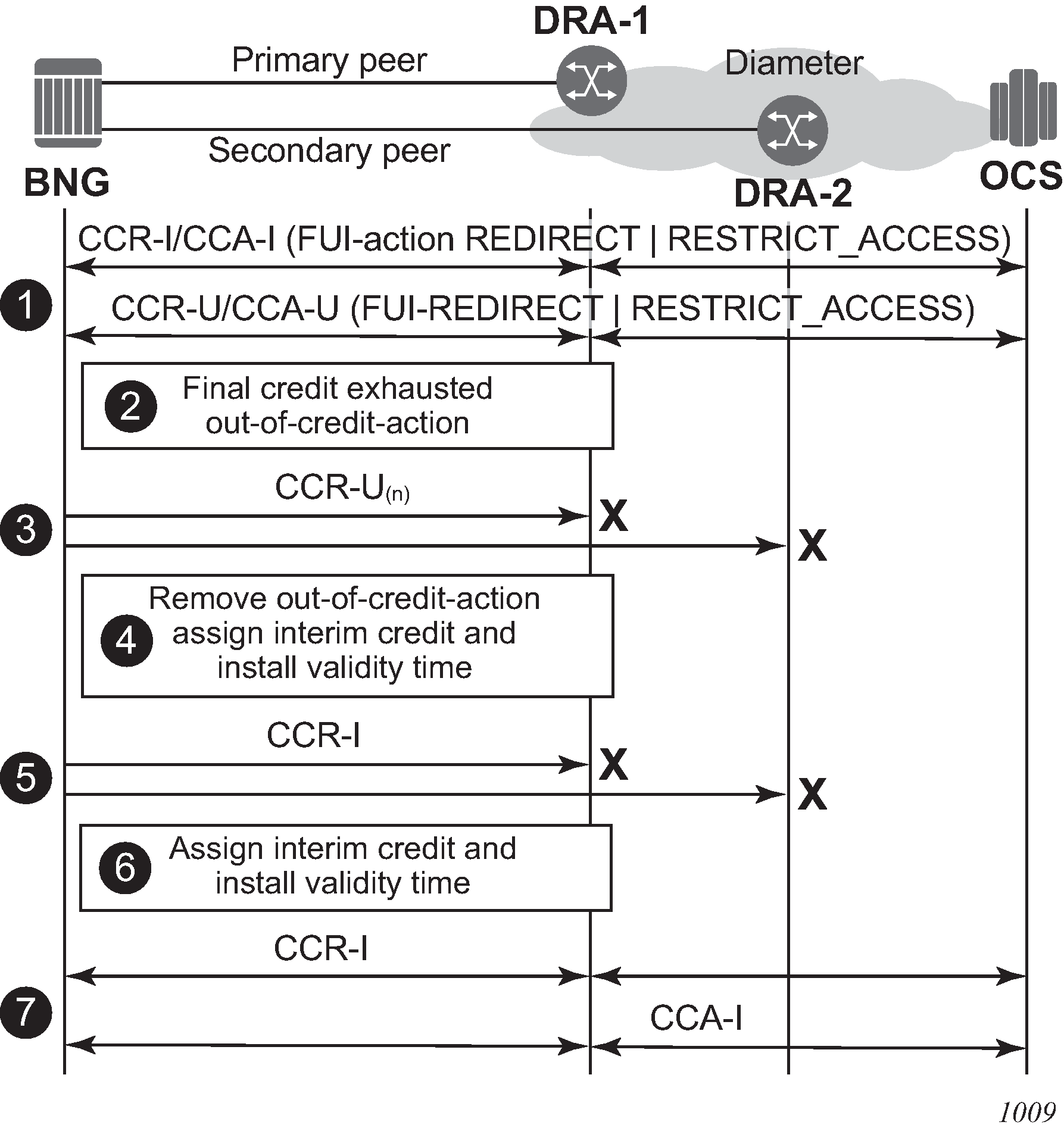
A Diameter Gy session is in progress. Either the CCA-I or a CCA-U contains the Final-Unit-Indication AVP and the Final-Unit-Action AVP is set to REDIRECT or RESTRICT_ACCESS.
The final assigned credit is exhausted and because the Final-Unit-Action AVP is different from TERMINATE, the provisioned out-of-credit action is installed. A CCR-U is sent to the OCS to notify it that the Final-Unit-Action has started.
The CCR-U message sent to the primary peer times out or an error condition occurs that triggers diameter Gy EFH. If failover is enabled, the CCR-U message is resent on the secondary peer. The CCR-U message sent to the secondary peer times out or an error condition occurs that triggers Diameter Gy EFH.
EFH becomes active for this user session. Interim credit is assigned to all rating groups and, optionally, a validity time is installed. The out-of-credit action is removed.
Interim credit is exhausted for a rating group or a validity time expires. A new attempt is made to establish the Diameter Gy session with the OCS and a CCR-I message (new session ID) is sent to the primary peer. A timeout or an error condition occurs that triggers Diameter Gy EFH to become active. If failover is enabled, the CCR-I message is resent on the secondary peer. The CCR-I message sent to the secondary peer times out or an error condition occurs that triggers EFH.
A new interim credit is assigned to all rating groups and, optionally, a validity time is installed.
Interim credit is exhausted for a rating group or a validity time expires. A new attempt is made to establish the Diameter Gy session with the OCS. A CCR-I is sent with the same or a new session ID to the primary peer. Whether the same or a new session ID is used is determined by a configuration command.
A CCA-I answer message is received. EFH becomes inactive and the user session continues with the new established credit control session. Optionally, the used interim credit can be reported via the new established session.
In the second scenario shown in EFH call flow - FUI scenario 2, the OCS initiates the graceful service termination with the Final-Unit-Action AVP = REDIRECT or RESTRICT_ACCESS. EFH is activated after the FUI validity time expires.
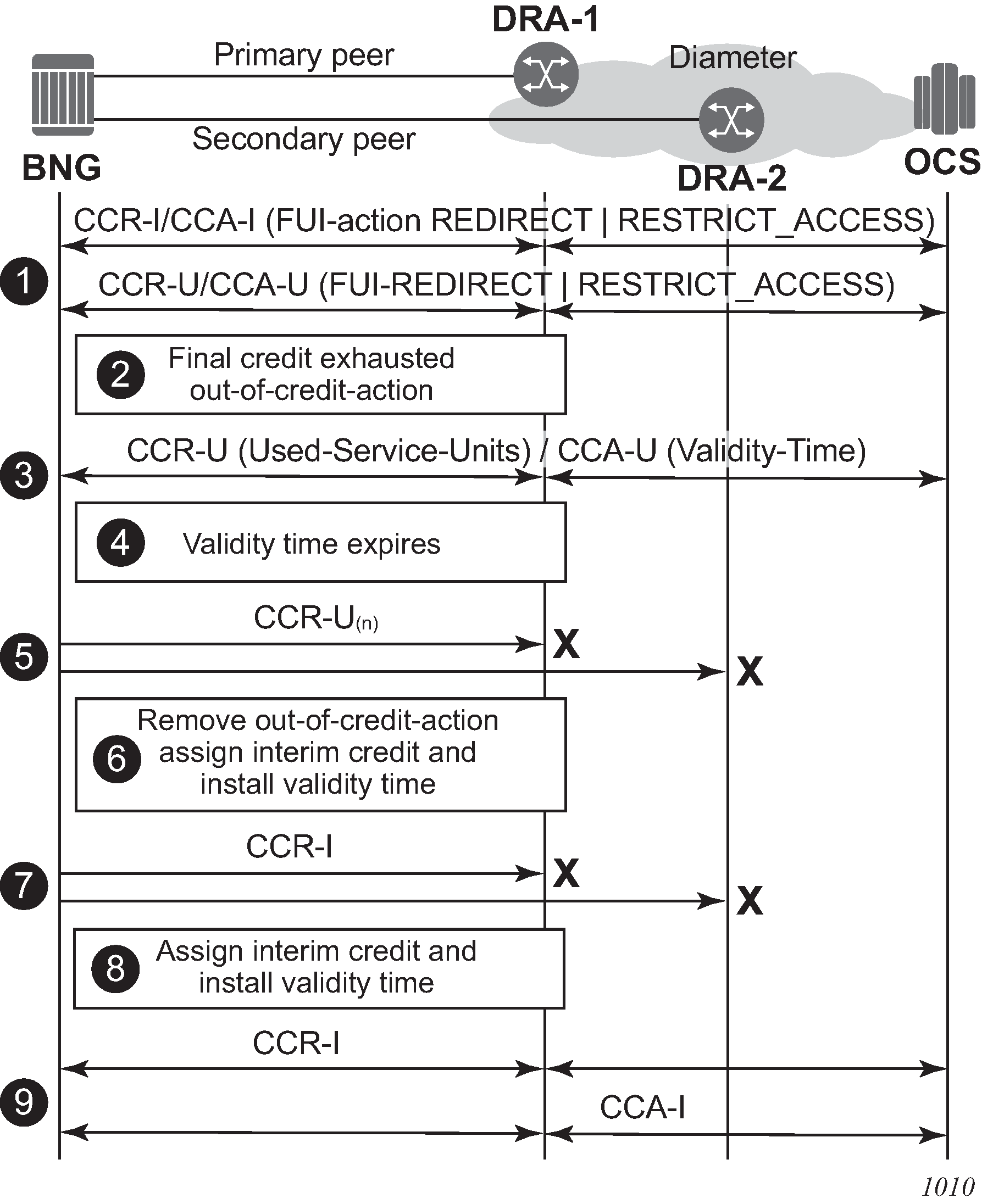
A diameter Gy session is in progress. Either the CCA-I or a CCA-U, contains the FUI AVP and Final-Unit-Action AVP = REDIRECT or RESTRICT_ACCESS.
The final assigned credit is exhausted and because the Final-Unit-Action is different from TERMINATE, the configured out-of-credit action is installed.
A CCR-U is sent to the OCS to notify that the Final-Unit-Action has started. The server responds with CCA-U containing a validity time.
The validity time expires.
The subsequent CCR-U message sent to the primary peer times out or an error condition occurs that triggers Diameter Gy EFH. If failover is enabled, the CCR-U message is resent on the secondary peer. The CCR-U message sent to the secondary peer times out or an error condition occurs that triggers Diameter Gy EFH.
EFH becomes active for this user session. Interim credit is assigned to all rating groups and, optionally, a validity time is installed. The out-of-credit action is removed.
Interim credit is exhausted for a rating group or a validity time expires. A new attempt is made to establish the Diameter Gy session with the OCS; a CCR-I message is sent to the primary peer. For the first attempt, a new session ID is used. For subsequent attempts, a configuration command determines if a new or the same session ID is used. A timeout or an error condition occurs that triggers Diameter Gy EFH to become active. If failover is enabled, the CCR-I message is resent on the secondary peer. The CCR-I message sent to the secondary peer times out or an error condition occurs that triggers EFH.
A new interim credit is assigned to all rating groups and, optionally, a validity time is installed.
Interim credit is exhausted for a rating group or a validity time expires. A new attempt is made to establish the Diameter Gy session with the OCS, a CCR-I message is sent to the primary peer.
A CCA-I answer message is received. EFH becomes inactive and the user session continues with the new established credit control session. Optionally, the used interim credit can be reported via the new established session.
Gy CCR-T replay
In diameter credit control, if the OCS is unreachable, EFH can be enabled to re-establish a Gy session with the OCS when the server becomes reachable again. This guarantees that no usage information is lost for billing. EFH applies to new and ongoing subscriber sessions.
If the OCS is unreachable after subscribers disconnect, the CCR-T that contains the final usage reporting is lost. CCR-T replay is a mechanism to recover final usage reporting data during OCS failure by replaying the CCR-T at configured intervals for a configured maximum lifetime or until an answer (CCA-t) is received from the OCS.
When enabled, CCR-T replay is triggered after:
a CCR-T transmit failure occurs. If session failover is enabled, the CCR-T transmit is retried on the secondary peer.
no CCA-t is received within the configured timeout. If session failover is enabled, the CCR-T is retried on the secondary peer.
CCR-T replay illustrates CCR-T replay in action when the OCS is unreachable.
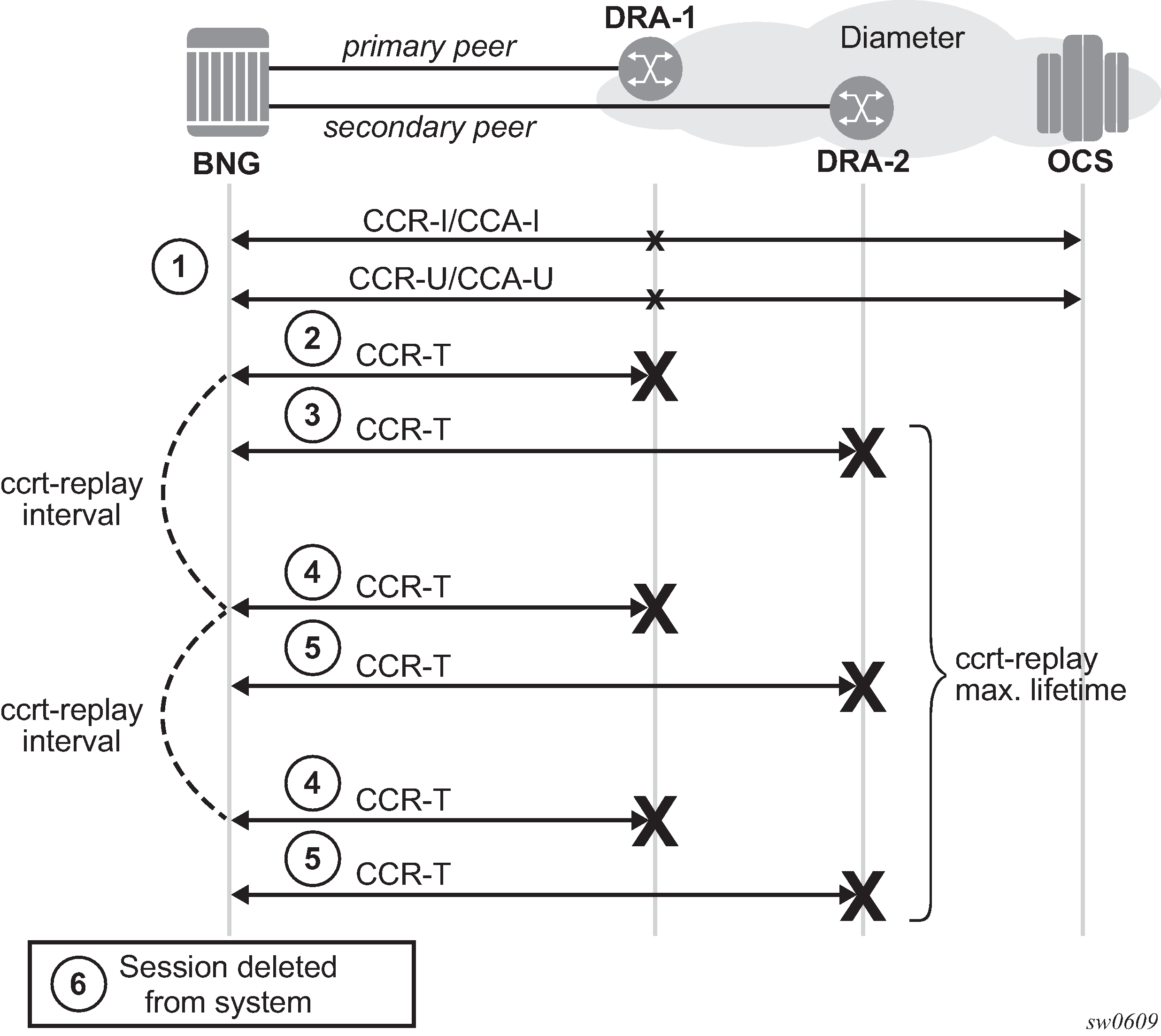
Where:
A diameter Gy session is in progress.
The subscriber disconnects, triggering the diameter Gy session to terminate. A CCR-T sent to the primary peer times out or an error condition occurs that triggers ccrt-replay.
If failover is enabled, the CCR-T is retried on the secondary peer. The CCR-T to the secondary peer times out or an error condition occurs that triggers ccrt-replay.
The CCR-T is replayed at the configured ccrt-replay interval until a valid answer is received or until the configured ccrt-replay max-lifetime is reached.
If failover is enabled, CCR-T replay is retried on the secondary peer.
The diameter Gy session in CCR-T replay is deleted when crrt-replay max-lifetime expires. An event is generated containing the Diameter Gx session ID.
The following configuration example enables CCR-T replay for Diameter Gy sessions:
Example:
configure subscriber-mgmt
diameter-application-policy diam-gy-1 create
gy
ccrt-replay
interval 1800
max-lifetime 12
no shutdown
exit
exit
exit
The ccrt-replay interval value can be configured in seconds between 60 seconds (1 minute) and 86,400 seconds (24 hours).
The ccrt-replay max-lifetime value can be configured in hours between 1 hour and 24 hours.
Use the show subscriber-mgmt diameter-session ccrt-replay command to display Diameter Gy sessions that are in CCR-T replay mode.
Use the show subscriber-mgmt diameter-session ccrt-replay diameter-application-policy name command to display Diameter Gy sessions from the specified diameter application policy that are in CCR-T replay mode and per-diameter application policy statistics for those sessions.
Use the clear subscriber-mgmt diameter-session ccrt-replay diameter-application-policy name sessions command to drop all Diameter Gy sessions that are in CCR-T replay mode.
Use the clear subscriber-mgmt diameter-session ccrt-replay diameter-application-policy name statistics command to clear the CCR-T replay statistics and update the ‟Statistics last cleared time” timestamp.
Policy management via Gx interface
Gx is a reference point in the network architecture model describing mobile service delivery. The network elements are described in various technical documents under the umbrella of 3GPP and are used to deliver, manage, report on and charge end-user traffic for mobile users. The Gx reference point is used for policy control and charging control. As shown in Gx reference point, it is placed between a policy server (Policy and Rule Charging Function (PCRF)) and a traffic forwarding node (Policy and Charging Enforcement Function) that enforces rules set by the policy server.
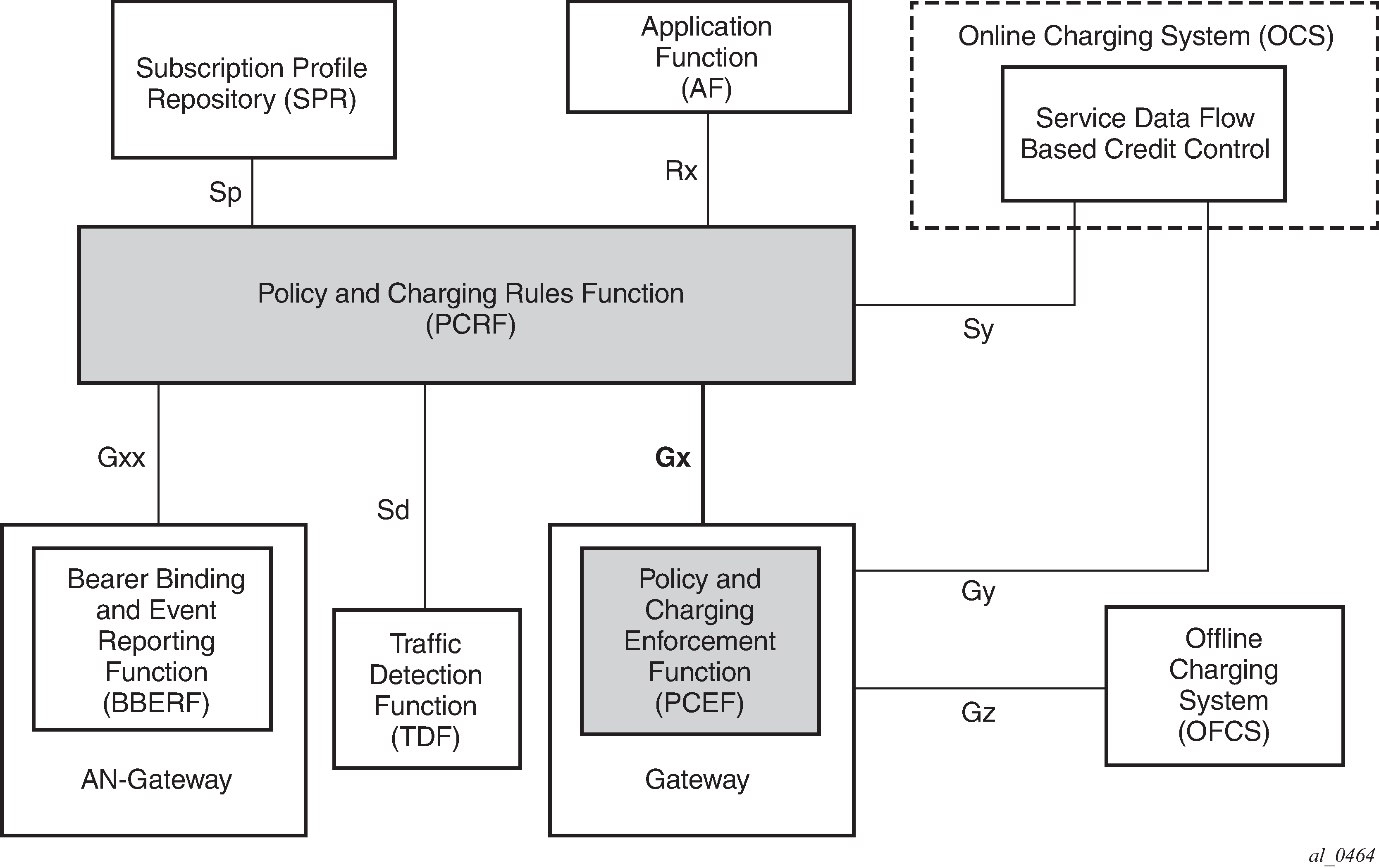
The Gx reference point is defined in the Policy and Charging Control (PCC) architecture within 3GPP standardization body. The PCC architecture is defined in the document 23.203 while the Gx functionality is defined in the document 29.212. Gx is an application of the Diameter protocol (RFC 3588/6733).
Although the Gx reference point is defined within 3GPP standardization body (spurred by mobile/wireless industry) its applicability has spread to wire-line operation as well. For example, mobile operators that also have fixed line customers (residential plus business) would like to streamline policy management in their mobile and non-mobile domains with a single and already existing Gx based policy management infrastructure. In other words they want to integrate policy management of nodes serving fixed line subscribers into the system that is currently managing mobile subscriber base.
In such mixed environments, the node plays the role of a PCEF with an integrated TDF (Traffic Detection Function, or Application Awareness [AA] in ALU terminology) where policies and charging rules can be managed via PCRF.
With Wi-Fi Offload as a new emerging application, supporting Gx reference point on nodes is becoming even more important.
The Gx interface on the node encompasses the following functionality:
Per subscriber host policy management
Usage-Monitoring
Gx is applicable to ESM as well as to AA.
Gx protocol
The Gx application is defined as a vendor specific Diameter application, where the vendor is 3GPP and the Application-ID for Gx application is 16777238. The vendor identifier assigned to 3GPP by IANA is 10415.
When a Diameter protocol defined over the Gx interface, the node (PCEF) acts as a Diameter Client and the PCRF acts as a Diameter server. The Gx Diameter application uses existing Diameter command codes from the Diameter Base Protocol (RFC 6733) and Diameter Credit Control Application (RFC 4006), both of which are already implemented on the node.
Gx is using Attribute-Value Pairs (AVPs) for data representation within its messaging structures (command codes). AVPs in Gx come from various sources:
Gx-specific AVPs defined in 3GPP Gx specification TS 29.212.
Reused AVPs from other existing Diameter applications (RFC 4006, RFC 4005, and so on), other 3GPP specifications, ETSI, and so on.
RADIUS reused attributes (AVP codes 0-255 are reserved for RADIUS re-used attributes)
Vendor-specific AVPs
The initialization and maintenance of the connection between the node (PCEF) and the PCRF is defined by the underlying Diameter protocol as defined in RFC 3588/6733.
Policy assignment models
Subscriber and AA policies on the node (PCEF with integrated TDF) is assigned through the Gx protocol from the policy server (PCRF).
There are two modes of operation:
Pull mode
The policy creation or modification is solicited by the node.
Push mode
The policy change is unsolicited by the node.
In the pull mode, during the host creation process, a user is authenticated by the AAA server. This process is independent from PCRF. After the user is authenticated and the IP address is allocated to it, the node sends a request for policies to the PCRF via CCR-I messages (initialization request message). This communication occurs via the Gx interface. The subscriber-host must be uniquely identified in this request toward the PCRF. This sub-identification over the Gx interface could be by means of IP address, username, SAP ID, and so on.
Based on the user identification, PCRF submits policies to the node. Those policies can range from subscriber strings (sub/sla-profiles/AA-profiles) to QoS and filter-related parameters.
In the push mode, the PCRF initiates the mid-session policy change through the Re-Authentication Request (RAR) message (Policy assignment models).
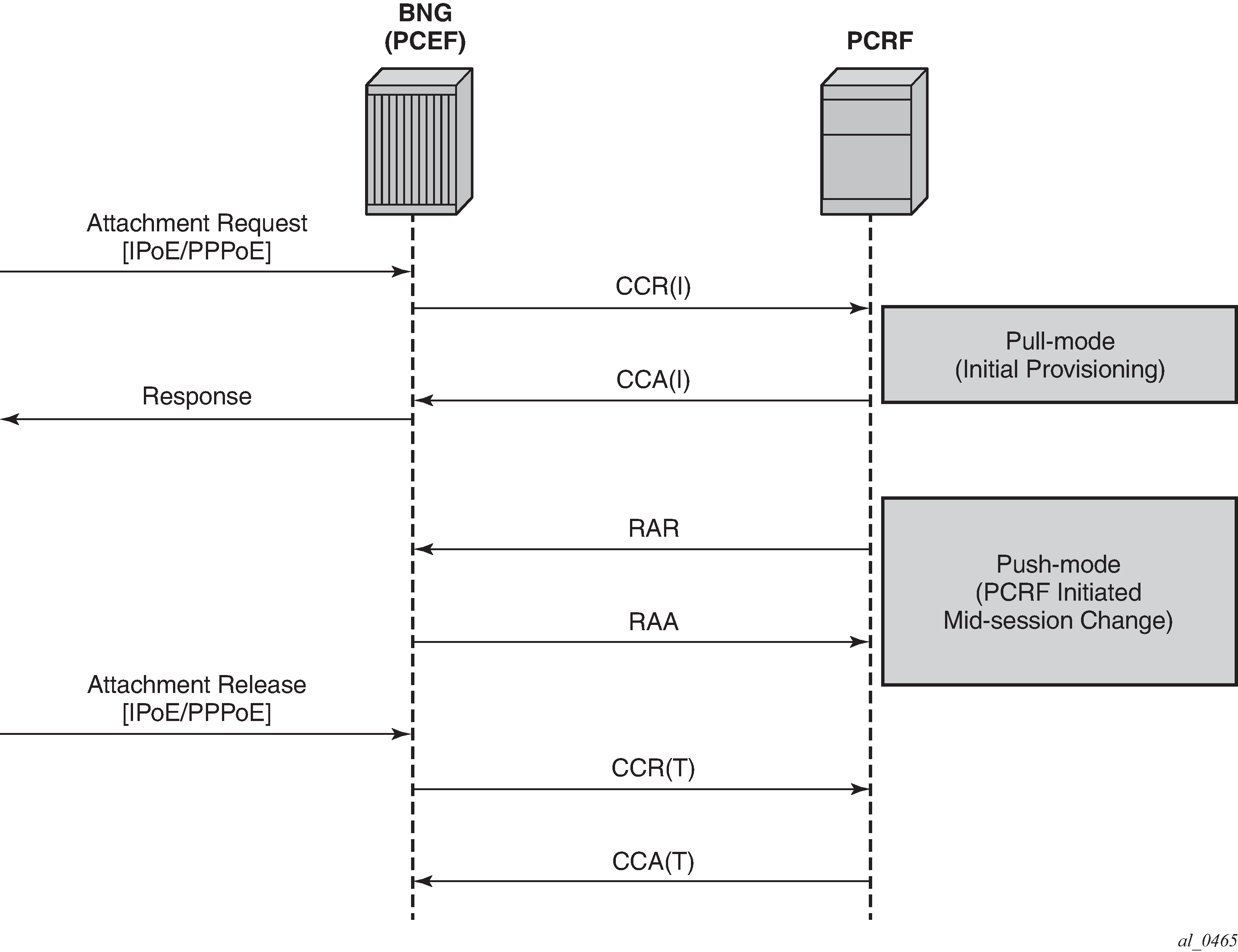
If that Usage-Monitoring is requested, the PCRF submitted policy changes are triggered by the Credit Control Request (Update) messages. This is based on ESM or AA Usage Monitoring. After the specified usage threshold is reached on the session-level, credit-category level, pcc rule level or application level on the node, the Usage-Monitoring is reported from the node to the PCRF in the CCR-U message. See the 7450 ESS, 7750 SR, and VSR Multiservice ISA and ESA Guide for details on AA based Usage-Monitoring (On-demand usage reporting).
Alternatively, PCRF can request usage reporting on-demand via the rar command.
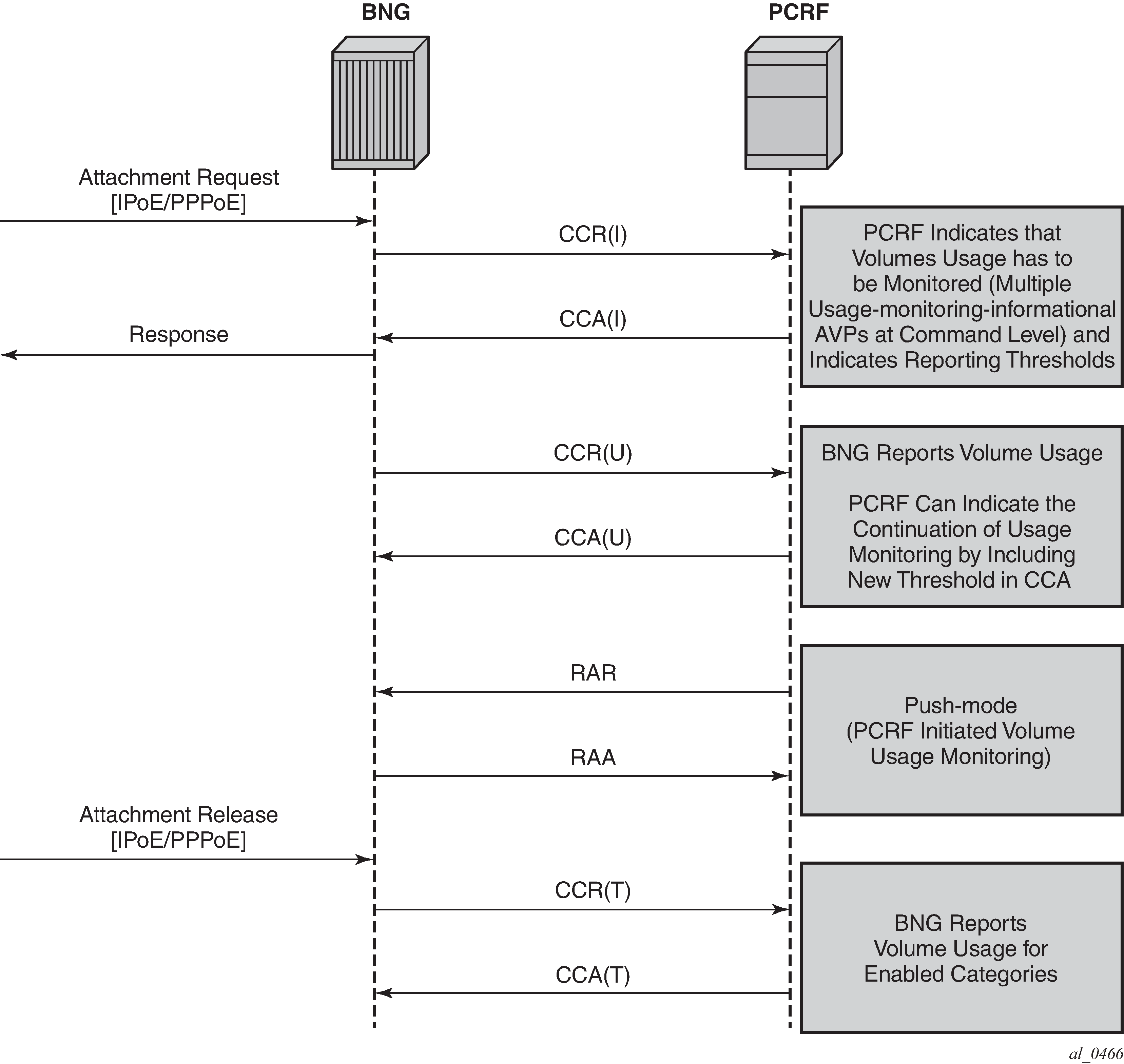
IP-CAN session – Gx session identification
The IP Connectivity Access Network (IP-CAN) session is a concept that has roots in mobile applications. A policy rule via the Gx interface can be applied/modified to an entity that is identified as an IP-CAN session (in addition to individual bearers within the IP-CAN session, the bearer concept is currently not applicable to the BNG). For example, a UE (user interface or simply a mobile phone) can host several services, each of which appears as a separate IP-CAN session associated with the same IP address. For example, in mobile technologies, an IP-CAN session can be defined as <IP_address, APN, IMSI>, where:
APN (Access Point Name) is the service identifier
IMSI (International Mobile Subscriber Identification) is the UE identifier (SIM Card)
In wireline environment (ESM deployments), an IP-CAN session identifies an entity to which the policy can be applied or modified. In SR OS, this can be a single or dual stack IPoE host, IPoE session, or PPPoE session.
For the purpose of identifying the subscriber host or session in the SR OS node in all Gx-related transactions, the SR OS node generates a unique Gx session-id AVP (RFC 6733, §8.8) per single or dual stack IPoE host, IPoE session, or PPPoE session. Note that the Gx Session-Id AVP is not the same as the Acct-Session-Id attribute used in RADIUS accounting.
If the IPoE session is enabled, the Gx session key can be based on one of the following combinations (configuration dependent):
{SAP,MAC}
-
{SAP,MAC,Circuit-Id}; the Circuit-Id must be present in the packet
-
{SAP,MAC,Remote-Id}; the Remote-Id must be present in the packet
If the IPoE session is disabled, the Gx session key for IPoE hosts (dual or single stack) is, by default, based on the {SAP,MAC} combination.
In an environment where a Layer 3 node is in front of the BNG, the MAC address of arriving packets are that of the Layer 3 node. Then, it is not possible to differentiate between IPoE hosts on the same SAP unless the IPoE session concept is enabled in SR OS. Each IPoE session must have a Circuit-id or Remote-id as a differentiator.
A session concept is native to PPPoE where the Gx session equates to a single or dual stack PPPoE session. This means that the Gx session key is based on a {MAC,SAP, PPPoE session-id} combination.
User identification in PCRF
The following identification related AVPs are sent to the PCRF through Gx messages to aid in IP-CAN session identification:
subscription-id AVP (RFC 4006, §8,46)
This can be used to identify the subscribers on the PCRF. For the supported fields within the subscription-id AVP, see the 7750 SR and VSR Gx AVPs Reference Guide.
NAS-Port-Id AVP (RFC 2869 / §5.17; RFC 4005 / §4.3)
AN-GW-Address AVP (3GPP 29.212 / §5.3.49)
Calling-Station-ID AVP (RFC 4005 / §4.6)
user-equipment-info AVP (RFC 4006, §8.49)
logical-access-id AVP (ETSI TS 283 034)
This contains the circuit-id from DHCPv4 Option (82,1) or interface-id from DHCPv6 option 18. The vendor-id is set to ETSI (13019).
physical-access-id AVP (ETSI TS 283 034)
This contains remote-id from DHCPv4 option (82,2) or DHCPv6 option 37. The vendor-id is set to ETSI (13019).
Physical and logical access IDs are also defined in BBF TR-134 (§7.1.4.1).
PDP to PEP direction parameters shows PDP to PEP direction parameters.
| Parameter | Category | Type | Description |
|---|---|---|---|
Logical access ID |
User identification |
Octet String |
The identity of the logical access to which the user device is connected. It is stored temporarily in the AAA function connected to PDP. This corresponds to the Agent ID in case of IPv4 and to the interface ID of DHCP option 82 for IPv6. |
Physical Access ID |
User identification |
UTF8String |
The identity of the physical access to which the user device is connected. It is stored temporarily in the AAA function connected to the PDP. This corresponds to the Agent Remote ID. |
A Subscription-id AVP is most commonly used to identify the subscriber but any combination of the above listed parameters can be used to uniquely identify the IP-CAN session on PCRF and consequently identify the subscriber.
In addition, NAS-Port, NAS-Port-Type, and Called-Station-ID AVPs from RFC 4005 (§4.2, §4.4, §4.5) can be passed to the PCRF.
NAS-Port-Id as subscription-id
The node allows the NAS-Port-Id to be carried within the Subscription-Id AVP. Because the NAS-Port-Id may not be unique network-wide (two independent nodes may use the same NAS-Port-Id), there is a need for another identifier in conjunction with NAS-Port-Id to make the Subscription-Id unique across the network. This additional identifier is a custom string that can be appended to the NAS-Port-Id. It is defined when the NAS-Port-Id is configured for inclusion in Gx messages. See the 7450 ESS, 7750 SR, and VSR RADIUS Attributes Reference Guide for information to format NAS-Port-Id AVP on the node.
The string can be used to identify the location of the node. For example:
@ALU-MOV-SITE-1
An example of the augmented NAS-Port-Id would look like:
NAS-Port-Id = lag-1.1/1/2:23.2000@ALU-MOV-SITE-1
where: 'lag-1.1/1/2:23.2000' is the part referencing the SAP on the node (port + vlan tags) and the '@ALU-MOV-SITE-1' is the node itself.
The NAS-Port-Id can be then inserted in the Subscription-Id AVP.
Gx interface and ESM subscriber instantiation
Policy management via Gx enables operators to consolidate policy management systems used in wireline (mostly based on RADIUS/CoA) and wireless environment (PCRF/Gx) into a single system (PCRF/Gx).
The model for policy instantiation/modification via Gx is similar to the one using RADIUS CoA. The authentication and IP address assignment is provided outside of Gx while the policy management function is provided via Gx.
Some PCRFs may require that the IP address information is passed from the node in CCR-I. This assumes that the IP address assignment phase (via LUDB, RADIUS or DHCP Server) is completed before the PCRF is contacted via CCR-I. Message flow for various protocols (DHCP, AAA, Gx) related to IPv4 subscriber-host instantiation phase is shown in Message slow during DHCPv4 host instantiation phase.
CCR-I message is sent to the PCRF after DHCP Ack is received from the DHCP server. Relaying DHCP Ack to the client in the final phase of the host instantiation process depends on the answer from the PCRF and the configuration settings of the fallback function if the answer is not received.
This model allows the IP address of the host to be sent in the CCR-I message, even though the subscriber-host is not fully instantiated at the time when the CCR-I message is generated.
AAA/LUDB must still be used for authentication and assignment of parameters necessary to place the subscriber host in the correct routing context (service-id, grp-id, msap-policy).
The start of the accounting process fits into this model because the host is not instantiated until the policy information from all sources (Gx, AAA, defaults) is known. After the final sub-profile (containing the acct-policy) is known, the host is instantiated and accounting can consequently be activated.
If the IP address cannot be assigned via Gx, and this functionality is outside of the Gx scope (3GPP TS 23.203 Rel12, Annex S, IP-CAN Session Establishment section).
The purpose of the CCR-I message is the following:
To notify the PCRF that the sub-host was about to be instantiated on the node. Consequently, the PCRF creates a Gx session for the subscriber host if the CCR-I is successfully processed by PCRF.
To identify the subscriber host in the PCRF, the PCRF uses the subscriber host identification information to identify the policy (for the subscriber host) that needs to be submitted to the node. The policy rules can be sent via CCA-i immediately following the initial CCR-I or they can be modified at any time during the subscriber-host lifetime through RAR messages.
Message slow during DHCPv4 host instantiation phase shows the message flow during the DHCPv4 host instantiation phase.
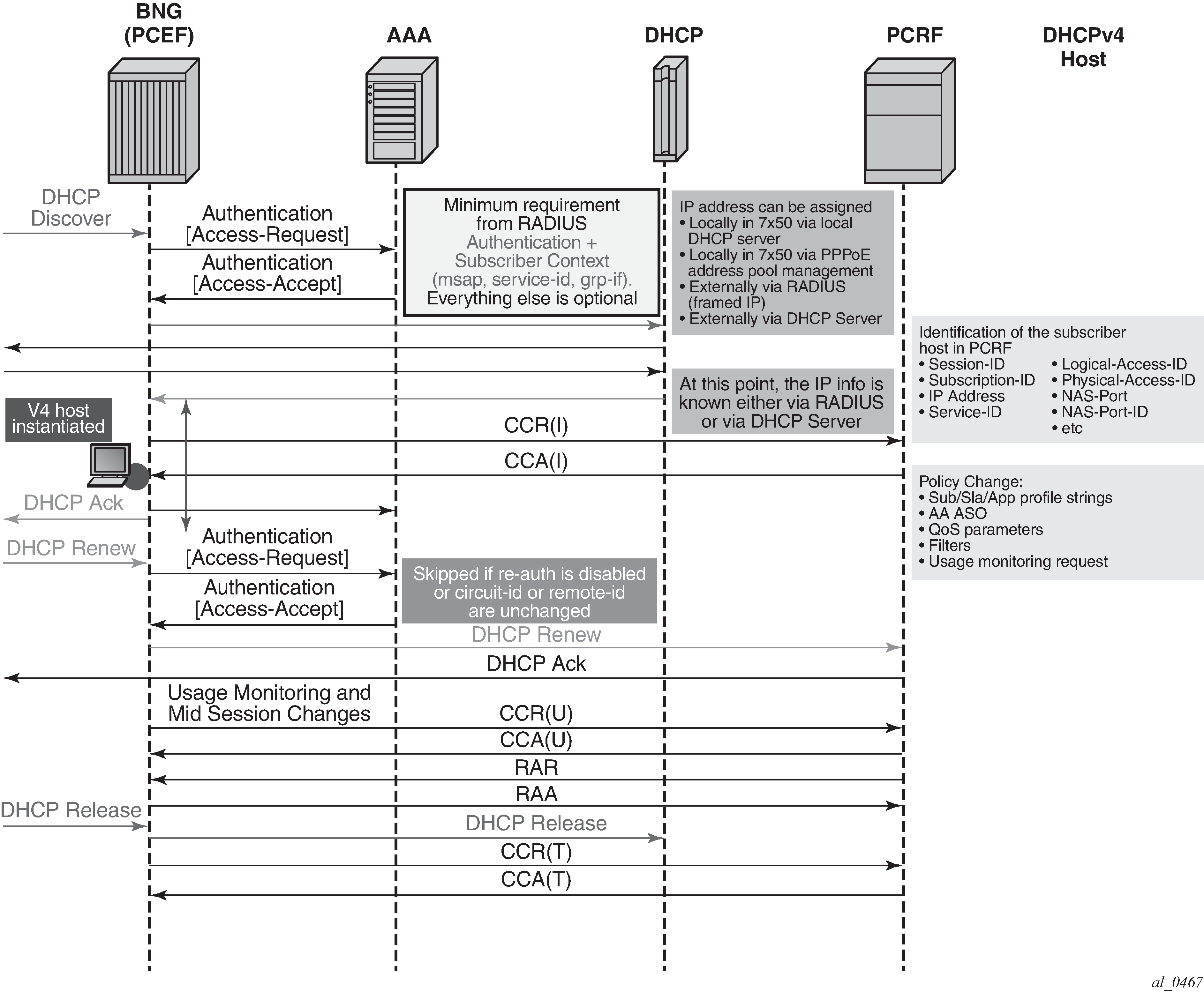
Message flow for PPPoEv4 host is similar. The host is instantiated after the answer from PCRF is received.
However, IPCP negotiation and Gx negotiation (CCR/CCA) are performed in parallel, independently of each other, and therefore the node does not wait for the Gx session to be established before the last IPCP ConfAck is sent (as it is for DHCP ACK).
After the host is instantiated on the node (after the CCA-i is received or as defined by the fallback action if the PCRF is not available), the Accounting-Start message is sent by the node (assuming that accounting is enabled).
The message flow is shown in Message flow during PPPoEv4 host instantiation phase.
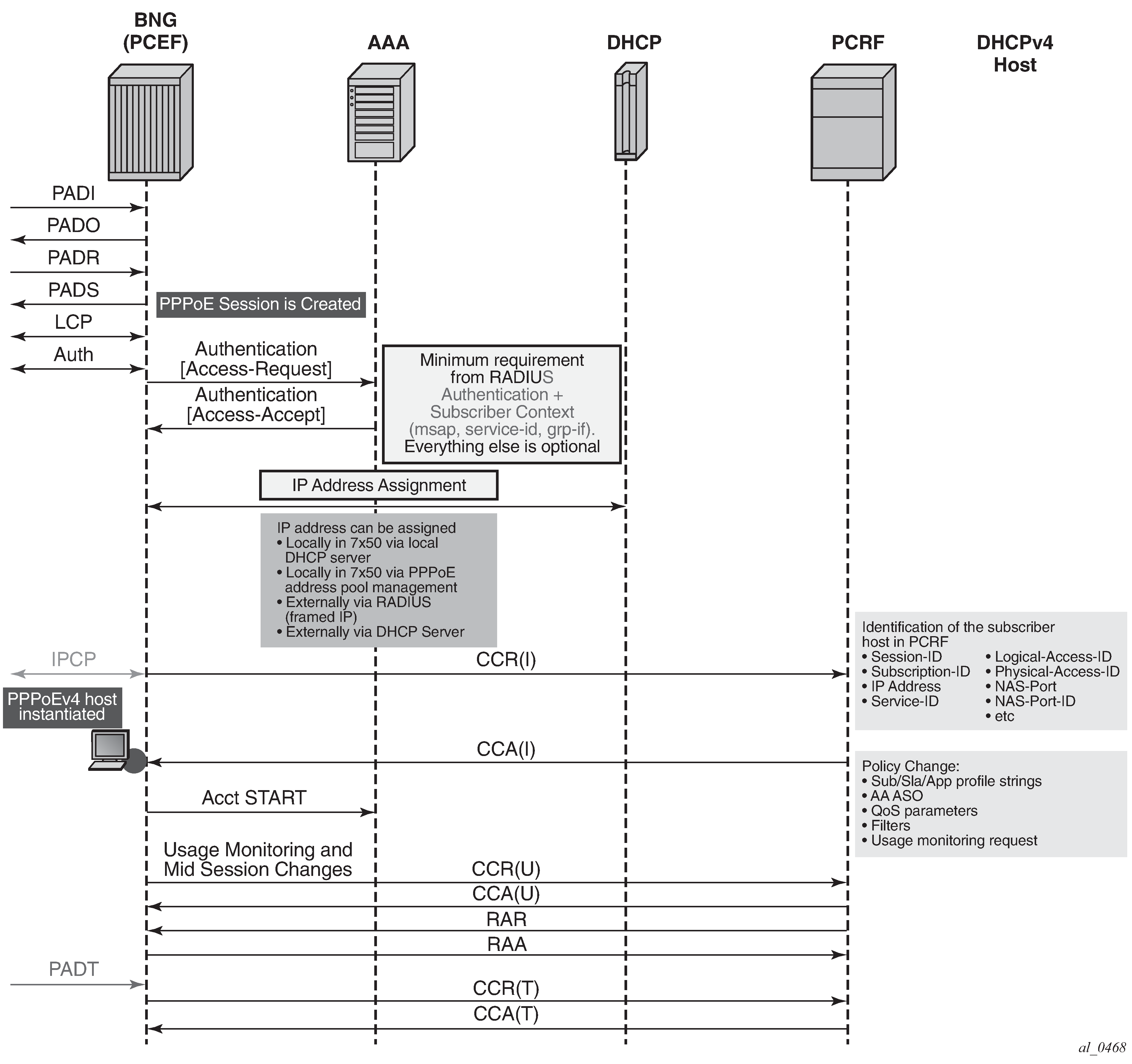
The host is created when the Gx session is established and therefore the subscriber host transitions into the traffic forwarding state when the Gx processing is completed. If the PCRF is unavailable or unresponsive, the host creation or termination is driven by the fallback configuration.
Gx and dual-stack hosts
Dual-stack (DS) hosts are treated as a single session from the Gx perspective, regardless whether an IPoE session concept is enabled. The difference between the IPoE session and non-IPoE session concept is related to the identification of the hosts for identification and policy management purposes.
If the IPoE session concept is disabled, a dual-stack host is identified by its {MAC,SAP} combination. Consequently, the key used for Gx session creation is based on the same {MAC,SAP} combination.
In some scenarios, this is not sufficient to differentiate hosts on the same SAP for Gx policy management purposes. As a result. a single Gx session is created for all hosts on that SAP. To avoid this creation, the IPoE session concept must be enabled in SR OS, where a Circuit-id or a Remote-id can be used for further differentiation between the Gx managed entities (subscriber-hosts).
The PCRF submits the policy rules per Gx session. The rules are then be applied to the underlying entity that is managed by this Gx session (single or dual stack IPoE host or IPoE session). For PPPoE deployment, the Gx session is automatically tied to the PPPoE session. A notion of a session is native to PPPoE (there is a session ID in PPPoE), and therefore, it is more natural to conceptualize the relationship between a PPPoE session (for single of dual-stack hosts) and a Gx session. By contrast, the concept of a session for IPoE is artificial, and which is why additional consideration is required for IPoE hosts, as described above.
The following example examines a case where IPoE session concept is disabled and consequently the IPoE dual-stack host is tied by a {MAC,SAP} combination.
The CCR-I contains the IP address that was first allocated (meaning, the first IP address that triggered the session creation). The request for the second IP address family triggers (if enabled by configuration) an additional CCR-U that carries the IP address allocation update to the PCRF along with the UE_IP_ADDRESS_ALLOCATE (18) event.
Separately, the CCR-U content mirrors the content of the CCR-I with exception of the pre- allocated IP address or addresses. A single Gx message (CCR-I or CCR-U) carries the update for the DHCPv6 IA-NA+IA-PD and DHCPv6/PPPoE NA+PD address/prefix. This assumes that the NA+PD is requested in a single DHCP message.
Similarly, for the Gx session teardown, the CCR-U messages are sent carrying the UE_IP_ADDRESS_RELEASE event, followed by the CCR-T message.
The message flow is depicted in Gx and DS session instantiation.
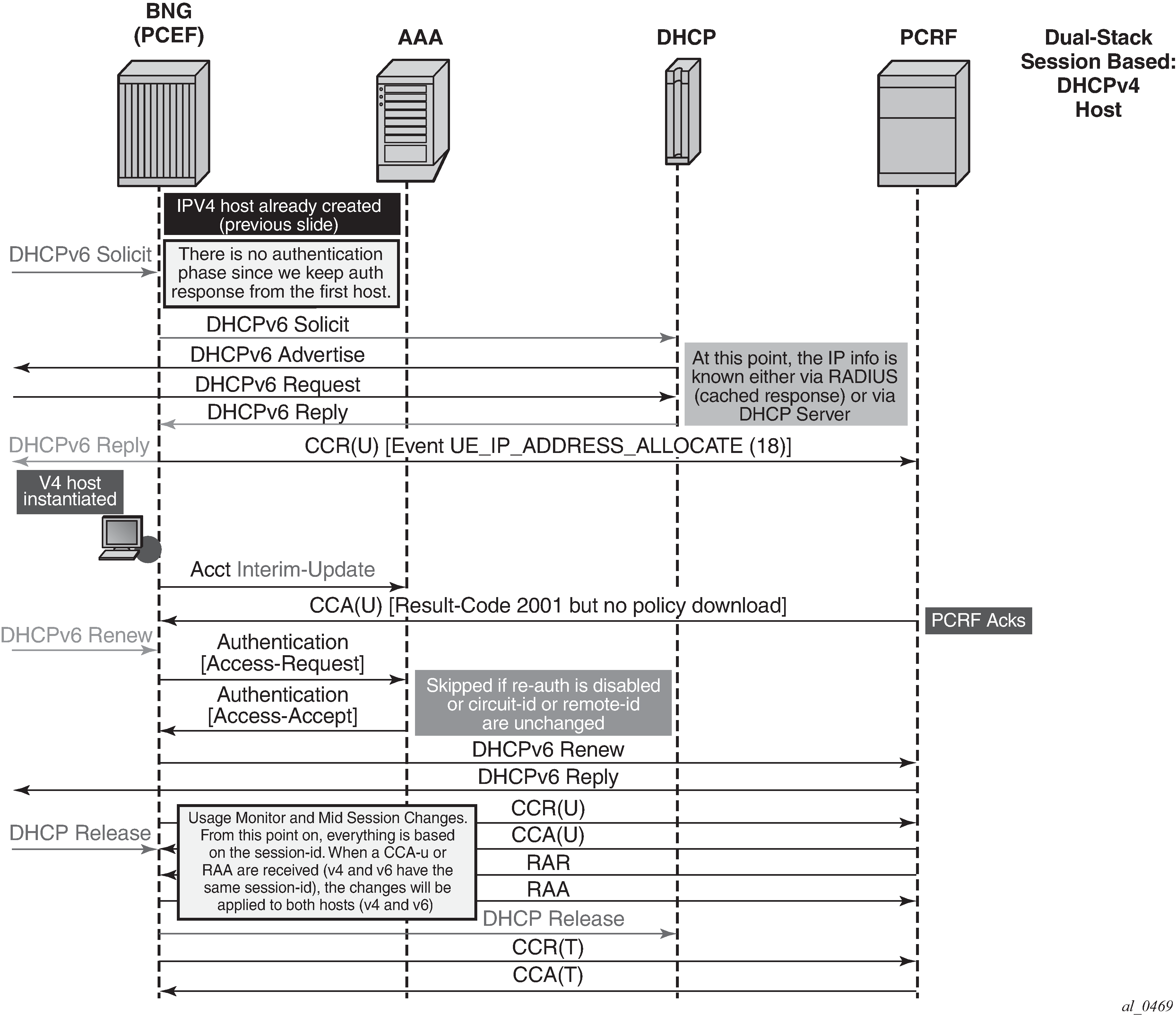
For Dual-Stack PPPoE host, the CCR-I is sent when the first IP address is assigned to the host. In the example in Gx and DS session instantiation, processing of the DHCPv6 Replay and CCR-U messages is performed in parallel. In other words, sending the DHCPv6 Reply message to the client is not delayed until the response from the PCRF is received. The reason being is that the Gx session is already established (triggered by the IPv4 host in our example) and all parameters for IPv4 and IPv6 are already known as received in CCA-i. Then, the CCR-U message is simply a notification message, informing the PCRF about the new IPv6 address/prefix being assigned to an existing client.
Gx and PPPoEv6-DHCP
For PPPoE v6 hosts, the IPv6 address is not obtained during the IPCP phase (only the interface-id is negotiated). Then, the node waits until the IPv6 address/prefix is allocated to the IPv6 hosts before it sends the CCR-I message. Otherwise, the IP address would not be available in CCR-I. This is shown in Gx and PPPoEv6 host instantiation.
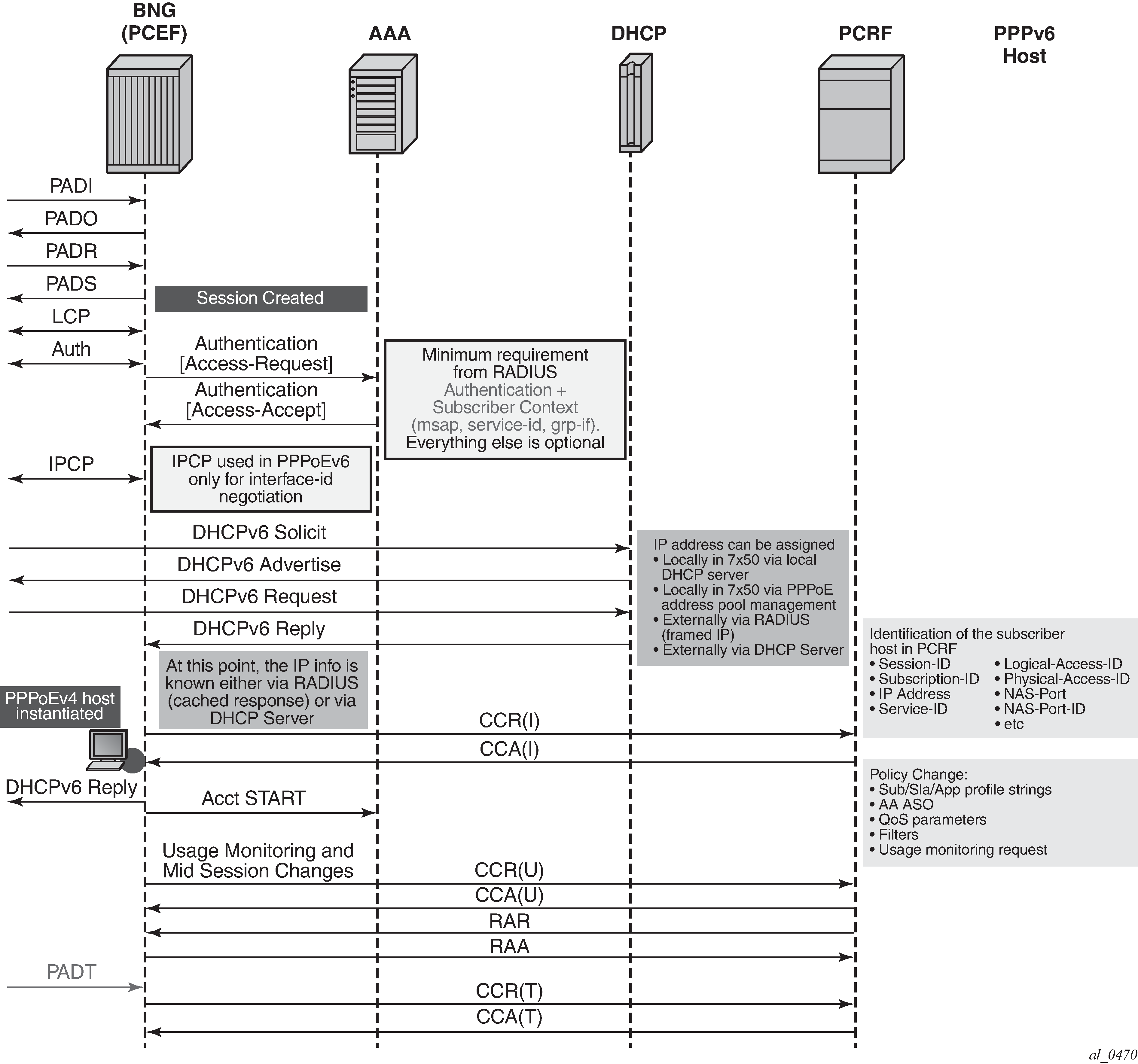
Gx fallback function
The Gx fallback functionality refers to the behavior related to the subscriber host instantiation in situations where the PCRF is unresponsive while peering connections are up or the PCRF is unavailable with all peering connections down. This functionality affects only Gx session processing related to CCR-I messages on the node and has no effect on already established Gx sessions.
The fallback behavior can be controlled via the local configuration on the node or can be controlled via AVPs provided by PCRF.
PCRF-provided AVPs that control fallback behavior are:
CC-Session-Failover AVP with the following values:
FAILOVER_NOT_SUPPORTED
FAILOVER_SUPPORTED
Credit-Control-Failure-Handling AVP with the following values:
TERMINATE
CONTINUE
RETRY_AND_TERMINATE
If the fallback-related AVPs are not provided via PCRF, the node can provide a local configuration option to define the fallback behavior. If the response from the PCRF cannot be obtained, the local configuration can allow the subscriber host to be instantiated with default parameters, or alternatively the local configuration can deny subscriber host instantiation.
PCRF provided AVPs overrule the local configuration.
The local configuration that defines Gx fallback behavior can be found under the following CLI hierarchy:
config
subscr-mgmt
diam-appl-plcy
on-failure
failover {enabled|disabled}
handling {continue|retry-and-terminate|terminate}
The failover configuration option (equivalent to CC-Session-Failover AVP) controls whether the secondary peer is used in if the primary peer is unresponsive. The unresponsiveness is determined by the timeout of the previously sent message.
The handling configuration option (equivalent to Credit-Control-Failure-Handling AVP) controls whether the subscriber is terminated or instantiated with default parameters if the PCRF is unresponsive.
| Handling: CONTINUE | Handling: RETRY-AND-TERMINATE | Handling: TERMINATE | |
|---|---|---|---|
Failover: ENABLED |
|||
After the message sent to the primary peer times out, the secondary peer (and consecutive peers after that) is attempted. After the message times out after it has been sent to all available peers, the HANDLING action is examined to determine whether to terminate the host instantiation attempt or whether to use default parameters to instantiate the host. |
After the message times out after it has been sent to all available peers, the subscriber host is instantiated with default parameters (if they are configured) |
After the message times out after it has been sent to all available peers, the subscriber host instantiation is terminated. |
After the message sent to the primary peer times out, the subscriber host instantiation is terminated. |
Failover: DISABLED |
|||
After the message sent to the primary peer times out, the HANDLING action is examined to determine whether to terminate the host instantiation attempt or whether to use default parameters to instantiate the host. |
After the message sent to the primary server times out, the subscriber host is instantiated with default parameters (if they are configured) |
After the message sent to the primary peer times out, the subscriber host is terminated. |
After the message sent to the primary peer times out, the subscriber host is terminated. |
The CCR retransmissions are controlled by the tx-timer command under diameter-application-policy.
If all peers are down (no connections are open), the handling action determines the behavior. If the action is set to continue, the subscriber host is immediately instantiated with the default-settings (provided that the defaults are available). In all other action cases, the host instantiation is immediately terminated.
Gx CCR-I replays
As described in the previous section, the subscriber host can optionally be (configuration controlled) established with default settings (sla-profile, sub-profile, app-profile) if the PCRF is not available to answer the CCR-I. This results in a subscriber-host state mismatch between the node and the PCRF, where the subscriber-host is established on the node but there is no corresponding Gx session established in the PCRF.
To resolve this situation, ESM periodically sends CCR-I for the Gx orphaned subscriber-host until the response from PCRF is received. The CCR-I is periodically retransmitted every 60 seconds.
Gx CCR-T replays
Termination of the subscriber-host on the node without termination of the corresponding Gx session in PCRF results in a state mismatch between the node and the PCRF, whereby the host Gx session is present in the PCRF while it is removed from the node.
Some PCRFs can cope with such out-of-sync condition by periodically auditing all existing Gx sessions. For example, a probing RAR can be sent periodically for each active Gx session. The sole purpose of this probing RAR is to solicit a response from the PCEF (node) and provide indication on whether the corresponding Gx session is alive on the node or is vanished. The ‛probing’ RAR can contain an Event-Trigger that is already applied on the node, or if none is applied, then the Event-Trigger can contain NO_EVENT_TRIGGER. In either case, the probing RAR does not cause any specific action to be taken in the node and it is used only to solicit reply from PCRF.
To minimize the impact on performance, probing RARs are sent infrequently; therefore, it may take days to discover a stale Gx session on the PCRF. The node supports a mechanism that can clear the stale session in the PCRF sooner. It does this by replaying CCR-T messages until the correct response from the PCRF is received (CCA-t). The CCR-T messages are replayed up to 24 hours. Both the interval at which the CCR-T messages are replayed and the max-lifetime period are configurable. If the max-lifetime period expires before a valid answer is received, the CCR-T is deleted and a log is generated. The log contains Gx session ID.
The T-bit (retransmission bit) is set in all replayed CCR-T messages.
The following command clears all orphaned sessions on the node for a specified Diameter application policy:
clear subscriber-mgmt diameter-session ccrt-replay diameter-application-policy gx-policy-name sessions
RAR and CCR-T replay
Certain scenarios allow the PCRF to send a RAR message to an orphaned Gx session running CCR-T replays on the node. The ESM host associated with the orphaned Gx session does not exist and therefore RAR cannot be applied.
In this scenario, the node replies with RAA carrying Result-Code= DIAMETER_UNKNOWN_ SESSION_ID (5002).
CCR-T replay and multi-chassis redundancy
The first CCR-T reply for each Gx session is synchronized, but the consecutive CCR-T replays for the same Gx sessions are not synchronized. When the answer (CCA-t) is received, the CCR-T replay is terminated and this event (deletion of CCR-T replay) is synchronized to the other node.
CCR-T replays are sent from the node that was in SRRP active state at the time when the CCR-T was initiated. They continue to be sent from the same node even if the SRRP is switched over in the meantime.
This entire process can be thought of as if the CCR-T initiating node (active SRRP) armed its MCS peer with CCR-T replay for a Gx session. This occurs at the very beginning, when a CCR-T replay is first initiated for a Gx session. The armed node stays silent until the MCS peer that is actively sending CCR-T replays for a Gx session, reboots. Only when the MCS peer reboots, the armed node starts sending CCR-T replays for a Gx session in the following fashion: first message is sent with cleared T-bit, followed by replays at the configured replay interval and a fresh 24 hour lifetime.
CCR-T replay and high availability
On CPM switchover, the newly active CPM resumes the CCR-T replay with the T-bit set until the lifetime, which is synchronized between the CPMs, expires.
Automatic updates for IP address allocation/de-allocation
During the subscriber-host setup phase, the first allocated IP address is sent in the CCR-I message from the node to the PCRF.
Each subsequent IP address allocation or de-allocation for the same host can optionally trigger a CCR-U, notifying the PCRF of the IP address allocation/de-allocation event.
This behavior can be enabled via the following CLI command:
configure
subscriber-mgmt
diameter-application-policy <pol-name>
gx
[no] report-ip-addr-event
The IP address allocation/de-allocation event driven CCR-U message carries the respective event code [UE_IP_ADDRESS_ALLOCATE(18) or UE_IP_ADDRESS_RELEASE(19)] along with the corresponding IP address.
The IP address allocation/de-allocation events are applicable to the following addresses:
Framed-IP-Address (AVP Code 8) IPv4
Framed-IPv6-Prefix (AVP Code 97) SLAAC
Delegated-IPv6Prefix (AVP Code 123) IA-PD
Alc-IPv6-Address (AVP Code 1023) IA-NA
These event-codes are only sent in CCR-U messages and not in CCR-I and CCR-T messages (when the host is instantiated and terminated).
Examples:
IPv6 attachment request arrives with two IP addresses: IA-NA and IA-PD. This is a new host. CCR-I is generated with two IP addresses included (IA-NA and IA-PD, assuming that request for their allocation is carried in the same DHCPv6 message).
Afterward, the attachment request for an IPv4 address arrives on the same host. CCR-U is generated with the event UI_IP_ADDRESS_ALLOCATE and corresponding AVP (framed-address) is sent to the PCRF. No IP address other than this new IPv4 address is sent.
RAR is received for the (any) policy change. The node replies with RAA and it contains all three IP addresses (AVPs) that have been allocated to the host.
If the IP address notification event is enabled, the node-originated Gx message carries all known IP addresses/prefixes associated with the subscriber-host (Gx session), unless those messages contain one of the two event codes:
UE_IP_ADDRESS_ALLOCATE(18) or UE_IP_ADDRESS_RELEASE(19).
If one of those two events is present in the Gx message, the IP address/prefix carried in that message is only relevant to the event contained in the message (address/prefix allocated or released).
If the IP address notification event is disabled, the node only sends the IP address from the first host. This IP address is included in all messages related to the Gx session. If this IP address is removed (de-allocated) mid-session from the dual-stack host, the node stops advertising it, or any other address, from Gx messages for that particular session.
DHCPv4/v6 re-authentication and RADIUS CoA interactions with Gx
If re-authentication for DHCPv4/v6 hosts is enabled, any policy changes that may be submitted during re-authentication (for example sla-profile update via Access-Accept) overwrites the one previously applied, regardless of the source of the policy update. For example, if that the Gx policy is applied to a subscriber host via RAR (mid-session policy update) and then later an overlapping policy with different values is submitted via RADIUS or LUDB during the re-authentication phase, the RADIUS/LUDB submitted policy overwrites the one applied via Gx. In other words, the origin of the current policy in effect is not maintained internally in the system and therefore the overlapping policy update cannot be prioritized according to the source of the policy.
The following guidelines should be followed if the policy is provided via Gx:
If LUDB access is enabled, there should be no overlap between the LUDB provided parameters and Gx provided parameters. LUDB is accessed during every DHCP lease renew process and consequently parameters configured via LUDB would overwrite parameters provided by Gx.
If LUDB access is enabled, there should be no overlap between the LUDB provided parameters and Gx provided parameters. LUDB is accessed during every DHCP lease renew process and consequently parameters configured via LUDB would overwrite parameters provided by Gx.
If re-authentication is enabled, there should be no overlap between the RADIUS provided parameters and Gx provided parameters. With re-authentication enabled, RADIUS is contacted during every DHCP lease renew process and consequently parameters configured via RADIUS would overwrite parameters provided by Gx.
These guidelines are not applicable for PPPoE subscriber-hosts because re-authentication cannot be enabled for PPPoE hosts. Consequently, LUDB or RADIUS parameters cannot override Gx provided parameters.
Coexistence of RADIUS CoA and Gx for the same host is allowed. The two policy change mechanisms are independent of each other and therefore, they can override each other. For example, if the RADIUS CoA for policy change for the host is received, the policy is updated but the PCRF (Gx) is not notified of the change. If both policy management mechanisms are deployed simultaneously, then it is the operator’s responsibility to synchronize the actions between the two.
Gx, ESM and AA
Although the ESM subscriber and the AA subscriber are two separate instantiations on the node, their policy management and Usage-Monitoring are handled uniformly through a single Gx session.
ESM subscriber-host vs AA subscriber
Because ESM and AA modules are part of integrated service offering (ESM with residential AA on the same node), they share the same subscriber-id string. However, Gx interface in ESM is primarily applicable to hosts (basic entity to which policy is applied) while AA has no awareness of hosts. AA is only aware of subscribers (which is, in broader terms, a collection of hosts within a residence). See the 7450 ESS, 7750 SR, and VSR Multiservice ISA and ESA Guide for details on Application Assurance concepts.
AA subscriber state
AA subscriber state must exist for App-profiles and ASO overrides to be applied.
The app-profile for the aa-sub is applied explicitly by a CCR-I or RAR message with an AVP AA-App-Profile-Name.
App-profiles interact with ASO characteristics in this way:
The AA-App-Service-Options AVP within the app-profile assignment is optional at subscriber instantiation time and may be used later to modify the policy.
The newly submitted AA-App-Profile-Name AVP overwrites the one that is already applied. Any ASO AVPs that is received within the Gx message is applied.
Note: If an app-prof AVP is present, even if it is the same app-profile as currently applied, all previous ASO override policies are removed for the sub.
The state of the subscriber policy attributes is modified by ASO AVPs in this way:
The app profile can define one or more ASO characteristics attributed to a subscriber.
If there are multiple ASO AVPs for the same characteristic in the message, the first one takes effect.
There is no explicit delete of ASO overrides (the PCRF can always resend or change the app-profile to delete all overrides).
Policy management via Gx
A policy change can be implicitly requested by the node at IP-Can session establishment time via the CCR-I command. The node supplies user identification attributes to the PCRF so that the PCRF can identify rules to be applied. However, the node does not explicitly request specific policy update, for example via Event-Trigger = RESOURCE_MODIFICATION_REQUEST.
Another way to request a policy update on the node is via the rar command in a PUSH model.
Gx policies on the node can be enforced via these three mechanisms:
Gx-based overrides
This refers to subscriber related overrides (sub/sla/aa-profile, subscriber-id, QoS, filter, category-map, and so on).
PCC rules or IP-criterion based rules
This refers to fully constructed Policy and Charging Control (PCC) rules with multiple qos/filter actions per rule and its own traffic classification.
NAS filter entry inserts via Gx
This refers to basic permits or denies entries, similar to ACL filter entries.
Gx-based overrides
Gx-based overrides refer to the activation or modification of the existing subscriber host-related objects on the node.
Subscriber host-related objects are shown in ESM objects managed via various policies and profiles. A subscriber represents a residence or home and it is identified by Subscriber-Id string on the node. A subscriber on the node can consist of multiple hosts in a bridged home environment or a single host in a routed home environment.
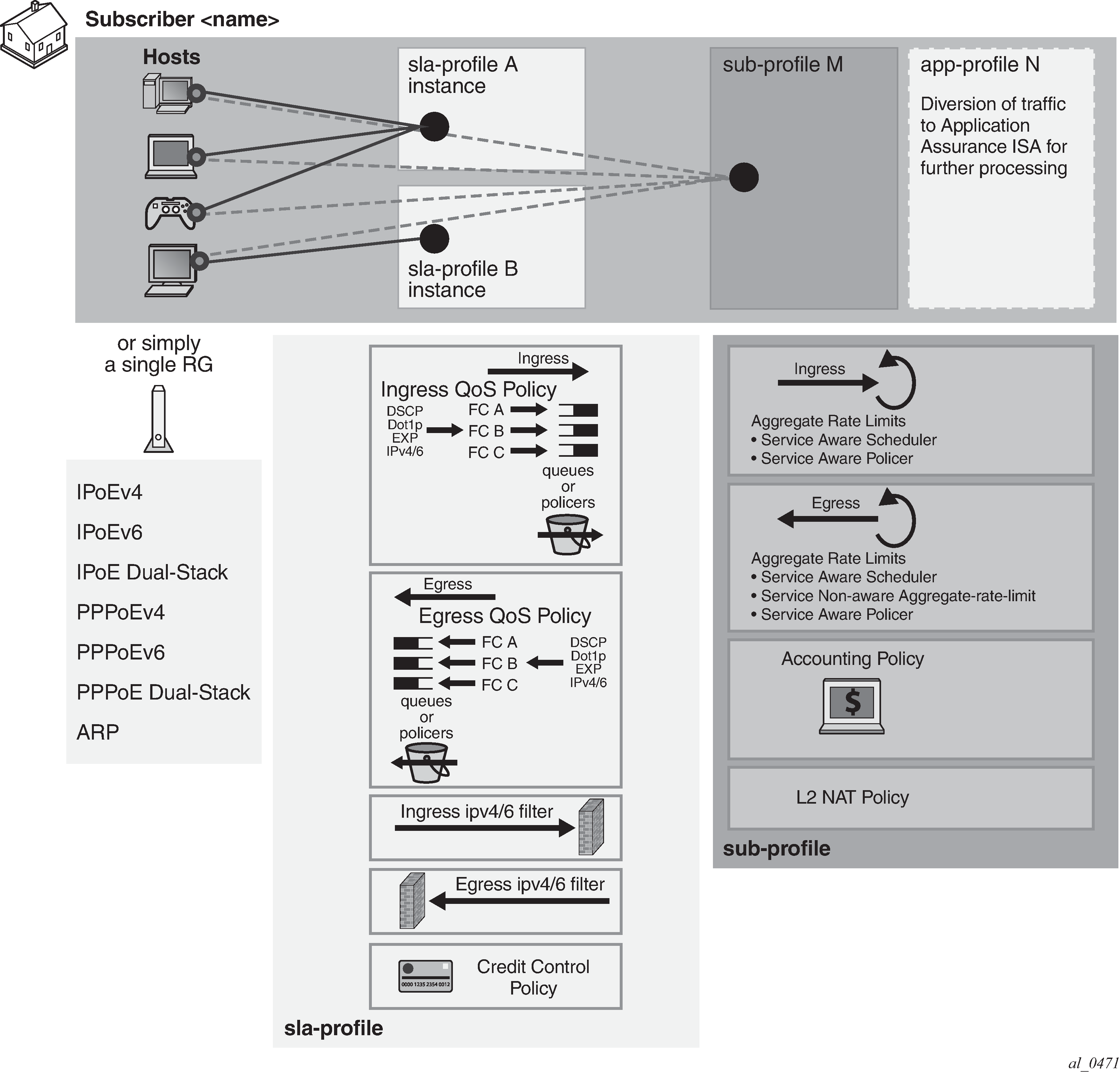
The two basic concepts in ESM context are sla-profile with its associated objects and sub-profile with its associated objects.
Sla-profile defines a service level (rates, queues, filters) for a group of hosts sharing the same sla-profile instance within the subscriber. There can be multiple sla-profile instances per subscriber.
Sub-profile defines aggregate rate of the subscriber along with accounting policy. There is only one sub-profile per subscriber.
Instantiation of Gx overrides
For a list of Gx related AVPs supported on the node, see the 7750 SR and VSR Gx AVPs Reference Guide.
Gx overrides are installed via Charging-Rule-Install AVP (for ESM or AA) or ADC-Rule-Install AVP (for AA only – 3GPP Release 11) sent from the PCRF toward the node.
AVP Format:
Charging-Rule-Install ::= < AVP Header: 1001 >
*[ Charging-Rule-Definition ]
*[ Charging-Rule-Name ]
*[ AVP ]
ADC-Rule-Install ::= < AVP Header: 1092 >
*[ ADC-Rule-Definition ]
*[ ADC-Rule-Name ]
*[ AVP ]
Every Gx override must have a Charging-Rule-Name (ESM) or ADC-Rule-Name (AA - 3GPP Release 11 and Release 12) associated with it. This is important for returning the override status from the node to the PCRF upon the override instantiation.
The objects (subscriber-hosts) to which the new overrides are applied must exist on the node; otherwise, the override installation fails.
The parameters defining a new override simply replaces the existing parameters that are already applied to the subscriber-host, without the need to remove the previously installed parameters.
There are four types of overrides that are currently supported via Gx:
ESM string overrides (sla/sub/app-profiles, subscriber-id)
update of subscriber host QoS information (queue rate change)
filter override for the subscriber host (including one-time http redirect)
category-map installation/override
HTTP redirect override within the filter
A Charging-Rule-Name AVP within the Charging-Rule-Install grouped AVP can have several meanings:
It can directly reference a preconfigured filter in the system.
It can directly reference a preconfigured subscriber profile (sla and sub).
It can directly reference a preconfigured category map.
It can directly reference an ESM string (such as an inter-destination-string used to associate the subscriber host with a Vport configuration).
Or, if there is an HTTP redirect override, it serves as a special container within which the HTTP redirect URL is defined. Note that HTTP redirect override is not to be confused with PCC rule-based HTTP redirect.
In all of the above cases, the existing objects applied to the subscriber-host is replaced with the referenced object.
It is important to distinguish two locations for invoking the Charging-Rule-Name AVP for overrides:
-
directly under the Charging-Rule-Install AVP
Then, the Charging-Rule-Name references the predefined structures (profiles, filter-ids, cat-maps, and so on) on the node. The type of the structure is contained within the Charging-Rule-Name AVP in the form of a reserved keyword that has to be prepended to the identifier of structure:
Filter installation/overrides:
-
Charging-Rule-Name = Ingr-v4:<id>
-
Charging-Rule-Name = Ingr-v6:<id>
-
Charging-Rule-Name = Egr-v4:<id>
-
Charging-Rule-Name = Egr-v6:<id>
-
Charging-Rule-Name = In-Othr-v4:<id> (othr - one-time-http-redirect)
-
Charging-Rule-Name = In-Othr-v6:<id> (othr - one-time-http-redirect)
Subscriber-Id override:
-
Charging-Rule-Name = Sub-Id:sub-id-string
Profile installation/overrides:
-
Charging-Rule-Name = Sla-Profile:sla-profile-name
-
Charging-Rule-Name = Sub-Profile:sub-profile-name
Inter-destination string override:
-
Charging-Rule-Name = Inter-Dest:inter-dest-string
Usage-Monitoring:
-
Charging-Rule-Name = Cat-Map:category-map-name
AA:
-
Charging-Rule-Name = AA-UM:<string-name>
-
Charging-Rule-Name=AA-Functions:<string-name>
In summary, the reserved prefixes ingr-v4:,ingr-v6:, egr-v4:, egr-v6:, in-othr-v4:, in-othr-v6:, sub-id:, sla-profile:, sub-profile:, inter-dest:, cat-map:, aa-um: and aa-functions: have special meaning within the Charging-Rule-Name AVP on the node.
One exception to this is HTTP redirect override, which is described separately.
-
-
under the Charging-Rule-Install
Charging-Rule-Definition AVP. In this case, the override itself is not pre-provisioned on the node but instead, directly defined in the Charging-Rule-Definition. Part of the override definition is the name assignment via Charging-Rule-Name AVP. The Charging-Rule-Name AVP is used to report on the override status.
For example, the Charging-Rule-Name AVP for QoS overrides is an arbitrary name. This AVP is part of Charging-Rule-Definition AVP in which QoS-Information is provided. Such Charging-Rule-Name is used to report errors related to instantiation of the override.
Another example of the override defined within the Charging-Rule-Definition AVP is HTTP redirect override:
Charging-Rule-Name = v4-http-url:<name> Redirect-Information ::= < AVP Header: 1085 > [ Redirect-Address-Type ] [ Redirect-Server-Address ]and
Charging-Rule-Name = v6-http-url:<name> Redirect-Information ::= < AVP Header: 1085 > [ Redirect-Address-Type ] [ Redirect-Server-Address ]The ADC-Rule-Name AVP within the ADC-Rule-Install grouped AVP handles application policy related processing (AA). This AVP is applicable under the ADC-Rule-Install—ADC-Rule-Definition AVP. In this case the ADC rule itself is not pre-provisioned on the node but instead directly defined in the ADC-Rule-Definition. In AA, such rule definition can define AA overrides that are applied to the subscriber. In other words, the existing objects for the subscriber are replaced with the ones referenced in the rule. Part of the ADC rule definition is the ADC rule name assignment via ADC-Rule-Name AVP. The ADC-Rule-Name defined in such manner is used to report on the rule status.
The AA-Functions: prefix in the ADC rule name is reserved for ADC rule definitions applicable to AA-functions (namely, app-profile and ASOs):
ADC-Rule-Name = AA-Functions:aa-rule-name
Then the aa-rule-name is an arbitrary name that is used in rule status reporting.
If that ADC-Rule-Name is used in AA Usage-Monitoring, the ‟AA-Functions:” prefix must not be present (Usage-Monitoring in AA is covered in detail in the 7450 ESS, 7750 SR, and VSR Multiservice ISA and ESA Guide).
Note: AA-Function AVP and AA-Usage-Monitoring cannot coexist in the same ADC rule.
The Charging-Rule-Definition AVP (AVP code 1003, 3GPP 29.212 §5.3.4) is of type Grouped, and it defines the override sent by the PCRF to the node.
The Charging-Rule-Name in this AVP can be arbitrarily set and it is used to uniquely identify the override in error reporting.
Charging-Rule-Definition ::= < AVP Header: 1003 >
{ Charging-Rule-Name }
[ QoS-Information ]
[ Nas-Filter-Rule]
[ Alc-NAS-Filter-Rule-Shared]
*[ AVP ]
The ADC-Rule-Definition AVP (AVP code 1094, 3GPP 29.212 §5.3.87) is of type Grouped, and it defines the ADC override sent by the PCRF to the node. The ADC-Rule-Name AVP within the ADC-Rule-Definition AVP uniquely identifies the ADC policy rule and it is used to reference to a policy rule in communication between the node and the PCRF within one IP CAN session.
ADC-Rule-Definition ::= < AVP Header: 1094 >
{ ADC-Rule-Name }
[AA-Functions]
*[ AVP ]
HTTP redirect override
HTTP redirect override submitted via the Gx interface overrides the current URL string defined in the filter that is currently applied to the subscriber-host. The override is implemented through the standard Redirect-Information AVP nested within the Charging-Rule-Definition (CRD) AVP.
IPv4:
Charging-Rule-Install
Charging-Rule-Definition
Charging-Rule-Name = v4-http-url:<name>
Redirect-Information ::= < AVP Header: 1085 >
[ [ Redirect-Address-Type ]
[ [ Redirect-Server-Address ]
IPv6:
Charging-Rule-Install
Charging-Rule-Definition
Charging-Rule-Name = v6-http-url:<name>
Redirect-Information ::= < AVP Header: 1085 >
[ Redirect-Address-Type ]
[ Redirect-Server-Address ]
The keywords v4-http-url and v6-http-url are special keywords that must be part of the Charging-Rule-Name (CRN) AVP. These keywords can be followed by an arbitrary string name.
The purpose of the <name> string in the CRN AVP is for the PCRF to differentiate between different HTTP redirect overrides. However, the name string in the context of the http url host override command in a filter has no meaning on the node, and therefore it is ignored. This means that there can be only one HTTP redirect override per host and per address family on a node.
The outcome of this Gx directive (Redirect-Information AVP without the Flow-Information AVP within the Charging-Rule-Definition AVP) is the override of the HTTP redirect URL in the currently applied subscriber-host filter. The filter definition must explicitly allow overrides via the allow-radius-override keyword.
As long as the override rule is present in the system (meaning, it has been submitted via the Gx and has not been explicitly removed since), the override tries to enforce itself when both of the following two conditions are met:
A filter with the action http-redirect is applied to the subscriber-host. This is valid whether the filter was there when the rule was submitted, or whether the filter was applied after the rule was submitted.
-
The filter definition allows http-redirect overrides (filter with the allow-radius-override keyword).
If the above conditions are not met, the override is accepted (the node responds with RAA=OK) and stored by the system, although it is not applied until the above conditions are met.
For the HTTP URL host, the CRD directive must not contain any flow information or any other action besides the Redirect-Information AVP. Otherwise, the Diameter encoding fails and an error response is generated for RAR while CCR-I is silently dropped.
Removal of overrides
With the exception of HTTP redirect override, overrides cannot be removed by the Charging-Rule-Remove AVP. They can only be overridden, and consequently the Charging-Rule-Remove AVP is ignored. It is ignored only for regular overrides and not for PCC rules (see PCC rules) or for HTTP redirect override. An HTTP redirect override can be removed whether it is active (a filter with HTTP redirect action is applied) or inactive (a filter without HTTP redirection is applied).
Charging-Rule-Remove ::= < AVP Header: 1002 >
Charging-Rule-Name = v4-http-url:<name>
Charging-Rule-Name = v6-http-url:<name>
The name string in the CRN AVP is ignored in the context of HTTP redirect override. This means that the removal of HTTP redirect override with any name removes the currently installed HTTP redirect override.
Similarly, the installation of the HTTP redirect override replaces any currently installed HTTP redirect override, regardless of the name string (implicit removal of the current HTTP redirect override, followed by the installation of the new one).
The node replies with RAA=OK if a properly formatted Charging-Rule-Remove directive with any name is received for HTTP redirect override.
Examples of Gx overrides
The instantiation of HTTP redirect overrides via the Gx can be summarized as:
-
The Central AVP for the Gx overrides in SR OS is the Charging-Rule-Install AVP. Multiple overrides can be submitted to an node via a single Charging-Rule-Install AVP, or each Gx override can be submitted via its own Charging-Rule-Install AVP.
-
Gx override is identified by the Charging-Rule-Name AVP. This AVP is also used to report on the status of Gx override. The Charging-Rule-Name can reference a pre-configured construct on the node (profiles, cat-maps, filters) or it can be assigned by PCRF to identify the PCRF defined override (QoS policy modifications, HTTP redirect AA ASO modifications, and so on).
-
With the exception of the HTTP redirect override, overrides cannot be removed by the Charging-Rule-Remove AVP. They can only be overridden. The Charging-Rule-Remove AVP is ignored for Gx overrides.
The following is an example of Gx override instantiation where all Gx overrides are submitted under a single Charging-Rule-Install AVP. The AVPs in this example can be included in the CCA-i, CCA-u or RAR messages sent from the PCRF.
The outcome of the override is the following:
-
The subscriber-id is overridden with the new name ‛residence-1’.
-
New ingress v4 and egress v6 filters are installed.
-
New sub-profiles and sla-profiles are applied to the subscriber host.
-
The subscriber host is associated with the Vport named vport-AN-1.
-
The existing HTTP redirect URL is overwritten with a new URL.
-
Characteristics for queues 5 and 7 are overridden.
-
The egress rate limit for the subscriber is overridden.
-
ASOs are overridden.
Charging-Rule-Install ::= <AVP Header: 1001>
Charging-Rule-Name <AVP Header: 1005> = ‟sub-id:residence-1”
Charging-Rule-Name <AVP Header: 1005> = ‟ingr-v4:7”
Charging-Rule-Name <AVP Header: 1005> = ‟eggr-v6:5”
Charging-Rule-Name <AVP Header: 1005> = ‟Sub-Profile:prem”
Charging-Rule-Name <AVP Header: 1005> = ‟Sla-Profile:voip+data”
Charging-Rule-Name <AVP Header: 1005> = ‟Inter-Dest:vport-AN-1”
Charging-Rule-Definition <AVP Header: 1003>
Charging-Rule-Name <AVP Header: 1005> ‟v4-http-url:http-redir-1”
Redirect-Information < AVP Header: 1085 >
Redirect-Address-Type < AVP Header: 433 > = 2 -> URL type
Redirect-Server-Address < AVP Header: 435 > =
‟http://www.operator.com/portal.php?mac=$MAC”
Charging-Rule-Definition <AVP Header: 1003>
Charging-Rule-Name <AVP Header: 1005> = ‟premium-service”
QoS-Information <AVP Header: 1016>
Alc-Queue <AVP Header; vnd ALU; 1016>
Alc-Queue-id <AVP Header; vnd ALU; 1007> = 5
Max-Requested-Bandwidth-UL <AVP Header: 516> = 10000
Max-Requested-Bandwidth-DL <AVP Header: 515> = 100000
Guaranteed-Bitrate-UL <AVP Header: 1026> = 5000
Guaranteed-Bitrate-DL <AVP Header: 1027> = 50000
Alc-Committed-Burst-Size-UL <AVP Header; vnd ALU; 1008> = 1000
Alc-Maximum-Burst-Size-UL <AVP Header; vnd ALU; 1009> = 2000
Alc-Committed-Burst-Size-DL <AVP Header; vnd ALU; 1010> = 1000
Alc-Maximum-Burst-Size-DL <AVP Header; vnd ALU; 1011> = 2000
Alc-Queue <AVP Header; vnd ALU; 1006>
Alc-Queue-id <AVP Header; vnd ALU; 1007> = 7
Max-Requested-Bandwidth-UL <AVP Header: 516> = 10000
Max-Requested-Bandwidth-DL <AVP Header: 515> = 100000
Guaranteed-Bitrate-UL <AVP Header: 1026> = 5000
Guaranteed-Bitrate-DL <AVP Header: 1027> = 50000
Alc-Committed-Burst-Size-UL <AVP Header; vnd ALU; 1008> = 1000
Alc-Maximum-Burst-Size-UL <AVP Header; vnd ALU; 1009> = 2000
Alc-Committed-Burst-Size-DL <AVP Header; vnd ALU; 1010> = 1000
Alc-Maximum-Burst-Size-DL <AVP Header; vnd ALU; 1011> = 2000
Alc-Sub-Egress-Rate-Limit <AVP Header; vnd ALU; 1016> = 10000
ADC-Rule-Install ::= <AVP Header: 1092>
ADC-Rule-Definition <AVP Header: 1094>
ADC-Rule-Name <AVP Header: 1096> = ‟AA-Functions:apps”
AA-Functions
AA-App-Profile-Name = ‟apps-prof”
AA-App-Service-Options
AA-App-Serv-Options-Name = ‟bitttorent”
AA-App-Serv-Options-Value = ‟low-prio-1mbps”
AA-App-Service-Options
AA-App-Service-Options-Name = ‟ftp”
AA-App-Service-Options-Value = ‟hi-prio”
In the following example, all Gx overrides are submitted via a separate Charging-Rule-Install AVP:
Charging-Rule-Install ::= <AVP Header: 1001>
Charging-Rule-Name <AVP Header: 1005> = ‟sub-id:residence-1”
Charging-Rule-Install ::= <AVP Header: 1001>
Charging-Rule-Name <AVP Header: 1005> = ‟ingr-v4:7”
Charging-Rule-Install ::= <AVP Header: 1001>
Charging-Rule-Name <AVP Header: 1005> = ‟eggr-v6:5”
Charging-Rule-Install ::= <AVP Header: 1001>
Charging-Rule-Name <AVP Header: 1005> = ‟Sub-Profile:prem”
Charging-Rule-Install ::= <AVP Header: 1001>
Charging-Rule-Name <AVP Header: 1005> = ‟Sla-Profile:voip+data”
Charging-Rule-Install ::= <AVP Header: 1001>
Charging-Rule-Name <AVP Header: 1005> = ‟Inter-Dest:Gx-inserted-string”
Charging-Rule-Install ::= <AVP Header: 1001>
Charging-Rule-Definition <AVP Header: 1003>
Charging-Rule-Name <AVP Header: 1005> ‟v4-http-url:http-redir-1”
Redirect-Information < AVP Header: 1085 >
Redirect-Address-Type < AVP Header: 433 > = 2 URL type
Redirect-Server-Address < AVP Header: 435 > =
‟http://www.operator.com/portal.php?mac=$MAC”
Charging-Rule-Install ::= <AVP Header: 1001>
Charging-Rule-Definition <AVP Header: 1003>
Charging-Rule-Name <AVP Header: 1005> = ‟premium-service”
QoS-Information <AVP Header: 1016>
Alc-Queue <AVP Header; vnd ALU; 1016>
Alc-Queue-id <AVP Header; vnd ALU; 1007> = 5
Max-Requested-Bandwidth-UL <AVP Header: 516> = 10000
Max-Requested-Bandwidth-DL <AVP Header: 515> = 100000
Guaranteed-Bitrate-UL <AVP Header: 1026> = 5000
Guaranteed-Bitrate-DL <AVP Header: 1027> = 50000
Alc-Committed-Burst-Size-UL <AVP Header; vnd ALU; 1008> = 1000
Alc-Maximum-Burst-Size-UL <AVP Header; vnd ALU; 1009> = 2000
Alc-Committed-Burst-Size-DL <AVP Header; vnd ALU; 1010> = 1000
Alc-Maximum-Burst-Size-DL <AVP Header; vnd ALU; 1011> = 2000
Alc-Queue <AVP Header; vnd ALU; 1006>
Alc-Queue-id <AVP Header; vnd ALU; 1007> = 7
Max-Requested-Bandwidth-UL <AVP Header: 516> = 10000
Max-Requested-Bandwidth-DL <AVP Header: 515> = 100000
Guaranteed-Bitrate-UL <AVP Header: 1026> = 5000
Guaranteed-Bitrate-DL <AVP Header: 1027> = 50000
Alc-Committed-Burst-Size-UL <AVP Header; vnd ALU; 1008> = 1000
Alc-Maximum-Burst-Size-UL <AVP Header; vnd ALU; 1009> = 2000
Alc-Committed-Burst-Size-DL <AVP Header; vnd ALU; 1010> = 1000
Alc-Maximum-Burst-Size-DL <AVP Header; vnd ALU; 1011> = 2000
Alc-Sub-Egress-Rate-Limit <AVP Header; vnd ALU; 1016> = 10000
ADC-Rule-Install ::= <AVP Header: 1092>
ADC-Rule-Definition <AVP Header: 1094>
ADC-Rule-Name <AVP Header: 1096> = ‟AA-Functions:apps”
AA-Functions
AA-App-Profile-Name = ‟apps-prof”
AA-App-Service-Options
AA-App-Service-Options-Name = ‟bitttorent”
AA-App-Service-Options-Value = ‟low-prio-1mbps”
AA-App-Service-Options
AA-App-Service-Options-Name = ‟ftp”
AA-App-Service-Options-Value = ‟hi-prio”
Gx overrides (QoS rates, sub/sla-profiles, filters, and so on) can be examined individually with subscriber specific operational commands. In the example below, fields in bold can be overridden.
show service active-subscribers detail
========================================================================
Active Subscribers
========================================================================
------------------------------------------------------------------------
Subscriber residence-1 (prem)
-------------------------------------------------------------------------------
I. Sched. Policy : basic_policy
E. Sched. Policy : N/A E. Agg Rate Limit: 10000
I. Policer Ctrl. : N/A
E. Policer Ctrl. : N/A
Q Frame-Based Ac*: Disabled
Acct. Policy : N/A Collect Stats : Disabled
Rad. Acct. Pol. : N/A
Dupl. Acct. Pol. : N/A
ANCP Pol. : N/A
HostTrk Pol. : N/A
IGMP Policy : N/A
MLD Policy : N/A
Sub. MCAC Policy : N/A
NAT Policy : N/A
Def. Encap Offset: none Encap Offset Mode: none
Avg Frame Size : N/A
Vol stats type : full
Preference : 5
Sub. ANCP-String : "iope-left-dupl"
Sub. Int Dest Id : "Gx-inserted-string"
Igmp Rate Adj : N/A
RADIUS Rate-Limit: N/A
Oper-Rate-Limit : 10000
show service id 10 subscriber-hosts detail
=============================================================
Subscriber Host table
=============================================================
Sap Subscriber
IP Address
MAC Address PPPoE-SID Origin Fwding State
-------------------------------------------------------------
[1/1/5:6.2] iope-sub
192.168.0.11
00:00:65:06:02:01 N/A DHCP Fwding
-------------------------------------------------------------
Subscriber-interface : int1
Group-interface : g1
Sub Profile : prem
SLA Profile : voip+data
App Profile : apps-prof
Egress Q-Group : N/A
Egress Vport : N/A
Acct-Session-Id : D896FF0000001852EDFF46
Acct-Q-Inst-Session-Id: D896FF0000001952EDFF51
Address Origin : DHCP
OT HTTP Rdr IP-FltrId : N/A
OT HTTP Rdr Status : N/A
OT HTTP Rdr Fltr Src : N/A
HTTP Rdr URL Override : N/A
GTP local break-out : No
PCC rules
A generic use case for flow-based dynamic policy is related to customized network level treatment of on-demand services. Such services can represent a wide range of applications, such as video-on-demand or access to a specific application in the network. The service can be identified by traffic destination parameters or DSCP bits. After the service is identified, a set of actions can be applied to the service (rate change, forwarding-class change, Usage-Monitoring, and so on).
Typical flow of events for service activation is shown in Generic use case for IP criterion-based policy change via Gx:
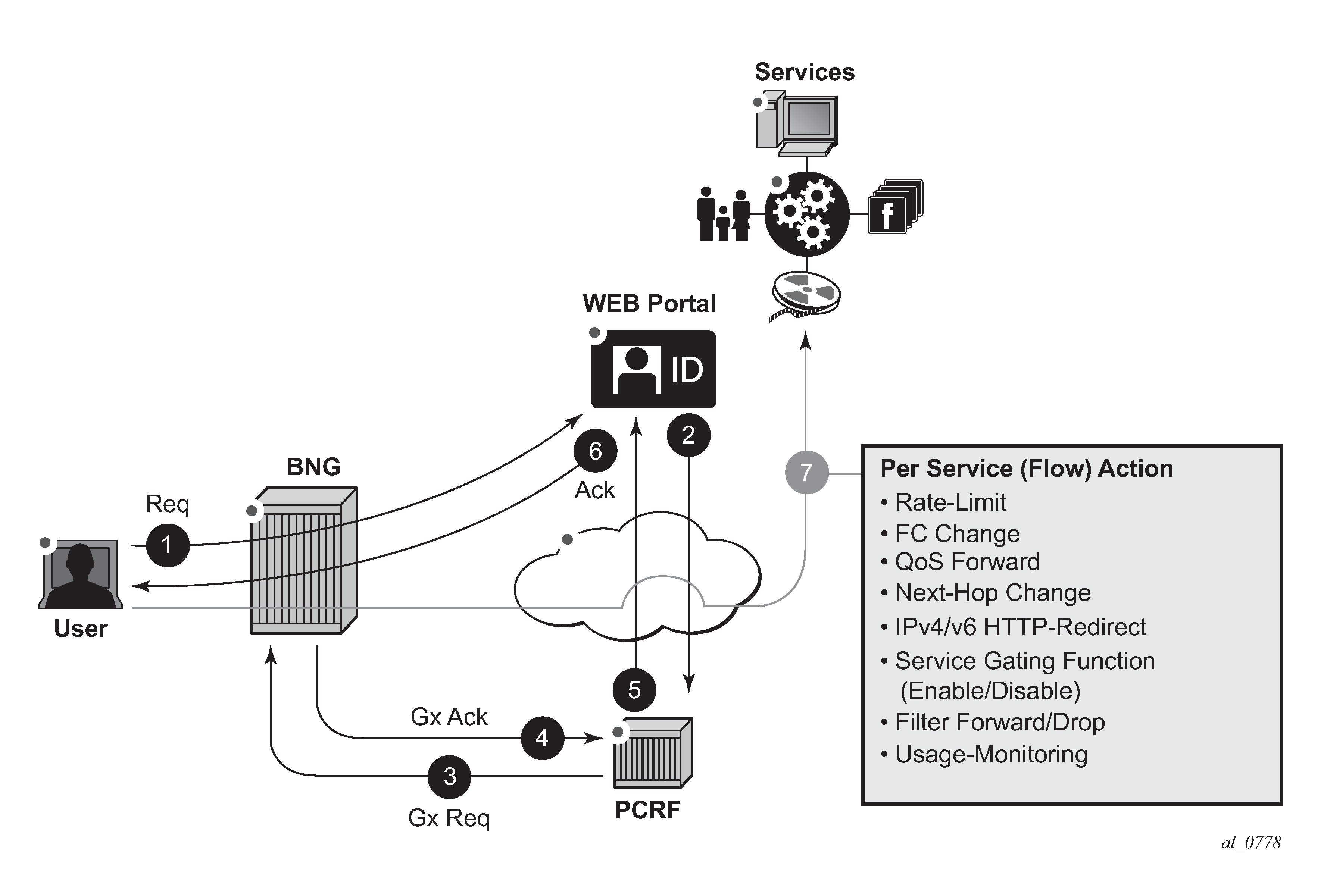
1) An established user subscribes to a service in the network via a Web portal at any time.
2) After the authentication/payment is accepted, the back end (for example, the Web portal integrated in OSS) identifies the service and submits the parameters defining the network delivery of the offered service to the PCRF.
3) The PCRF converts those parameters into rules and submits those rules to the subscriber-host on the BNG via the Gx. The rules identify the service on the network level (destination IP@ and port) along with the needed action.
4, 5, and 6) Before the service can be started, the action of individual policy management elements must be acknowledged to ensure that the resources for the service delivery are available and instantiated before the service is delivered to the subscriber.
7) The service traffic can be started from the subscriber side. Network requirements for the successful service delivery are enforced on a per flow or DSCP basis as defined by the PCC rule.
PCC rule concept
A PCC rule consists of traffic classifiers (Flow-Information AVPs) required for traffic identification, and one or more actions associated with such classified traffic. PCC rules are unidirectional, which means that each rule is applied on ingress or egress. They are provisioned from PCRF via Gx interface.
Traffic classification is based on:
5 Tuple (IPv4 and IPv6)
DSCP bits. When the content hosting device cannot be identified by the IP address, port and protocol, the DSCP marking can be used instead. Then, the DSCP marking is set by the client application and the markings should be preserved throughout the network until they reach the BNG.
Supported actions are:
rate limiting (in | out)
forwarding class (FC) change (in | out)
QoS forward (in | out)
next hop redirect (in)
service ID redirect (in)
HTTP redirect (in)
service gating function (in | out)
filter forward/drop (in | out)
Usage-Monitoring (in | out)
PCC rule instantiation
A PCC rule that is submitted to the node via PCRF is internally instantiated using two basic policy constructs, QoS policy and filter policy (ACL). This internal division is transparent to the operator at the time of the rule provisioning. The operator perceives Gx as a unified method for provisioning policy rules, whether the rule is QoS-related or filter-related.
The type of action within the PCC rule determines whether the PCC rule is split between the QoS policy and the filter policy.
Rules with actions:
rate limit
forwarding class change
QoS forward; matching traffic is forwarded without QoS actions and do not match on the next entry (match and exit behavior). This is equivalent to an allowlist entry.
Usage-Monitoring
are converted into a QoS policy while the rules with actions:
next hop redirect
service ID redirect
HTTP redirect
gate function (enable/drop)
filter forward/drop
are converted into filter rules.
The operator should be aware of this division for dimensioning (scaling) purposes. Operational commands can be used to reveal resource consumption on the node.
A PCC rule is addressed to a subscriber-host (single stack or dual stack) via the diameter session-id. However, qos-policy-related entries are applied per sla-profile instance because the qos resources are allocated per sla-instance. An sla-profile instance and sla-profile are two distinct concepts. An sla-profile instance is an instantiation of the sla-profile which is a configuration concept in which parameters are defined. An sla-profile is instantiated per a subscriber-host, or multiple subscriber-hosts can share an sla-profile instance as long as they belong to the same SAP and have the same subscriber ID.
This means that all hosts sharing the same sla-profile instance inherits the change. The sla-profile instance and sla-profile are two distinct concepts. The sla-profile instance is an instantiation of the sla-profile which is a configuration concept in which parameters are defined. The sla-profile is instantiated per a subscriber-host, or multiple subscriber-hosts can share an sla-profile instance as long as they belong to the same SAP and have the same subscriber-id.
Filter-related entries are applied per each subscriber-host, whether the hosts are sharing or not sharing an sla-profile instance.
The concept of splitting the rules is shown in PCC rule conversion on the node.
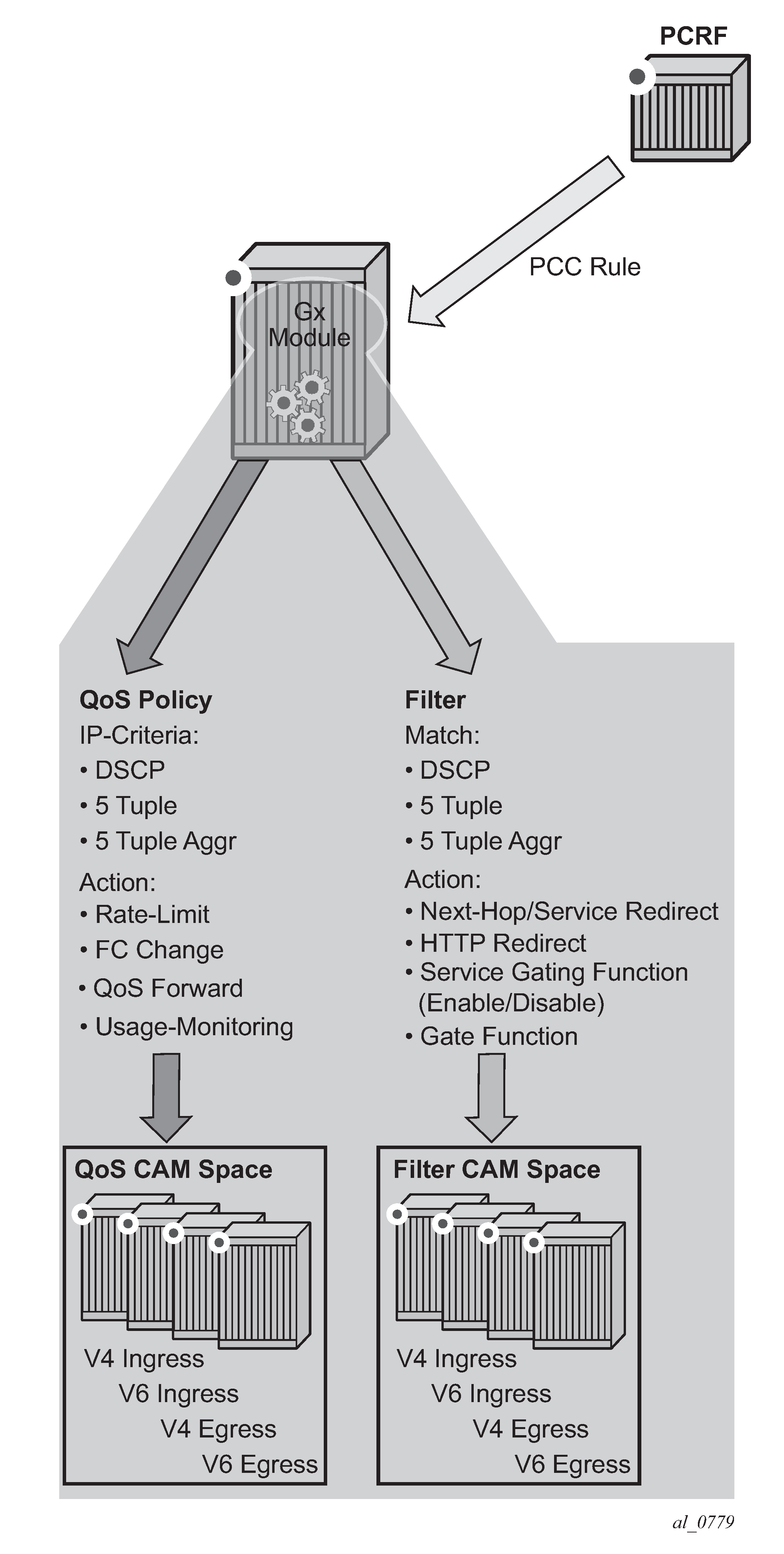
The PCC rule instantiation fails if a PCC rule contains only actions without any classification, or if it contains only classification without any actions.
Base QoS-policy and base filter
Subscriber host must have an explicit static (or base) filter or qos-policy before any dynamic entries can be inserted via Gx. For example, a base filter/qos-policy can be referenced by a sla-profile when the subscriber is instantiated. However, the parameters in the base qos-policy and base filter cannot be modified via Gx.
In the absence of explicitly defined qos-policy for the subscriber host, the default qos-policy 1 is in effect. Then, PCC rules with a QoS-related action cannot be applied.
PCC rule entries can be inserted in specifically allocated range in the base filter or qos-policy. The insertion point is controlled by the operator. This is shown in Static and dynamic QoS-policy/filter entries. The entries reserved for PCC rules start at the beginning of the range specified by the following CLI command:
sub-insert-shared-pccrule start-entry <entry-id> count <count>
under the following CLI hierarchy:
config>filter>ip-filter>
config>filter>ipv6-filter
config>qos>sap-ingress>
config>qos>sap-egress>
An entry corresponds to a Flow-Information AVP and is equivalent to a match condition defined as any combination of the following parameters under a filter or qos-policy ip-criteria:
source IP address
destination IP address
source port or port range
destination port or port range
protocol
DSCP
Such defined entry maps into a single CAM entry with exception of port range configured as match criteria whereby a single port range command can expand into multiple CAM entries.
Static entries in filter/qos-policy can be inserted before and after the range reserved for PCC rules.
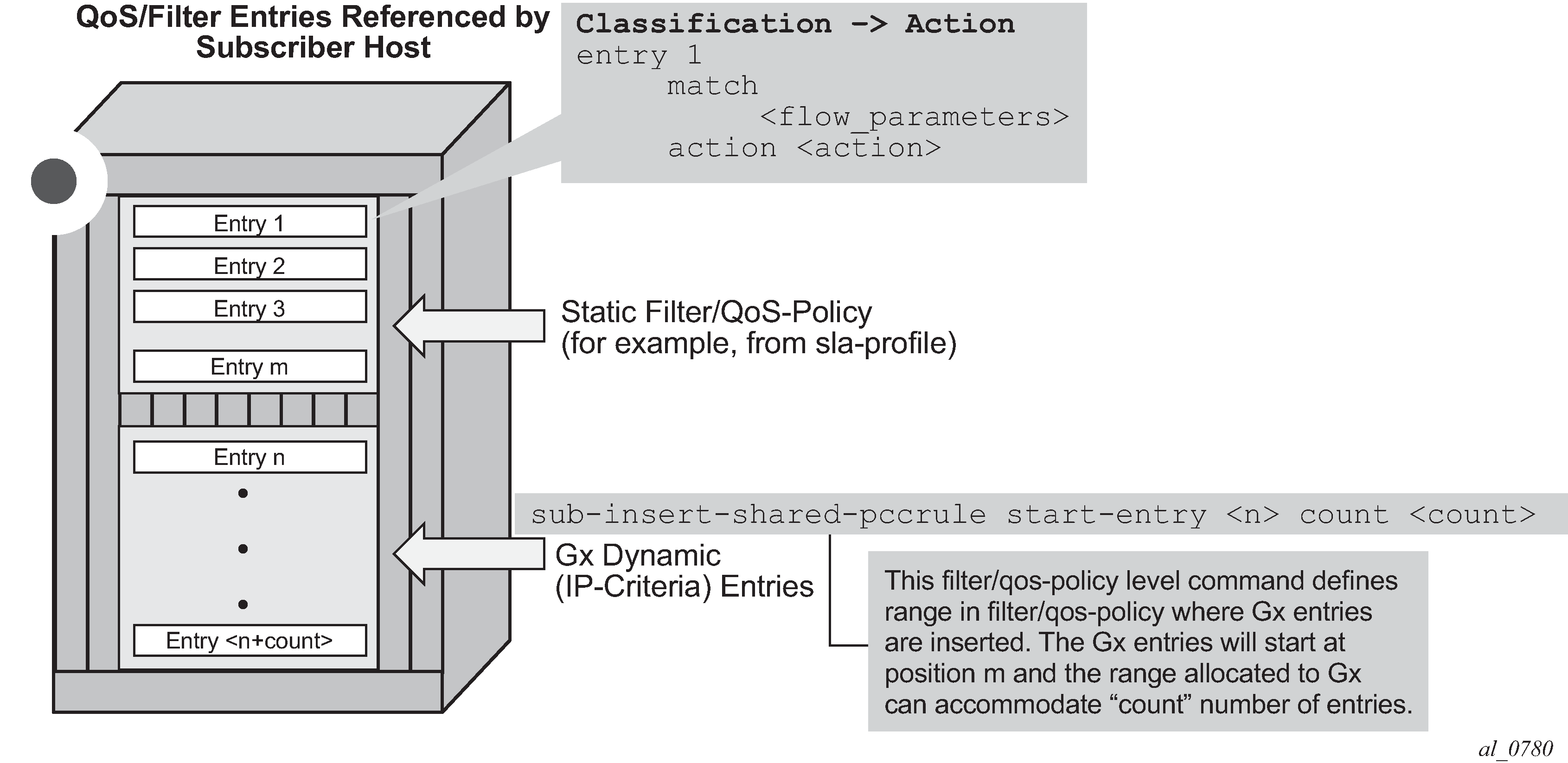
Generic policy sharing and rule sharing
Policy (defined in this context as a collection of static and dynamic rules) sharing between the subscriber hosts is depicted in Policy cloning. To simplify CAM scaling explanations, the examples in this section assume that one rule within the policy occupies exactly one CAM entry. For simplicity, only PCC rules are shown but in reality a subscriber-host policy consist of PCC rules together with the base qos-policy/filter.
A policy, as a set of rules, can be shared amongst the subscriber-hosts. However, when a new rule is added to one of the subscriber-host, the newly created set of rules for this host becomes unique. Hence, a new policy for the subscriber-host is instantiated. This new policy consumes additional resources for all the old rules (clone of the old policy) along with the new rule. Figure below shows that a new policy (3) is instantiated when rule D is added to User 1, even though the rules A, B and C remain the same for Users 1 and 2. Policy 3 is a newly cloned with the same rules as Policy 1, and then Rule D is added onto it. On the other hand, when the rule C is applied to User 3, the set of rules becomes identical to the set of rules for User 2. Thus the two can start sharing rules and therefore the resources are freed.
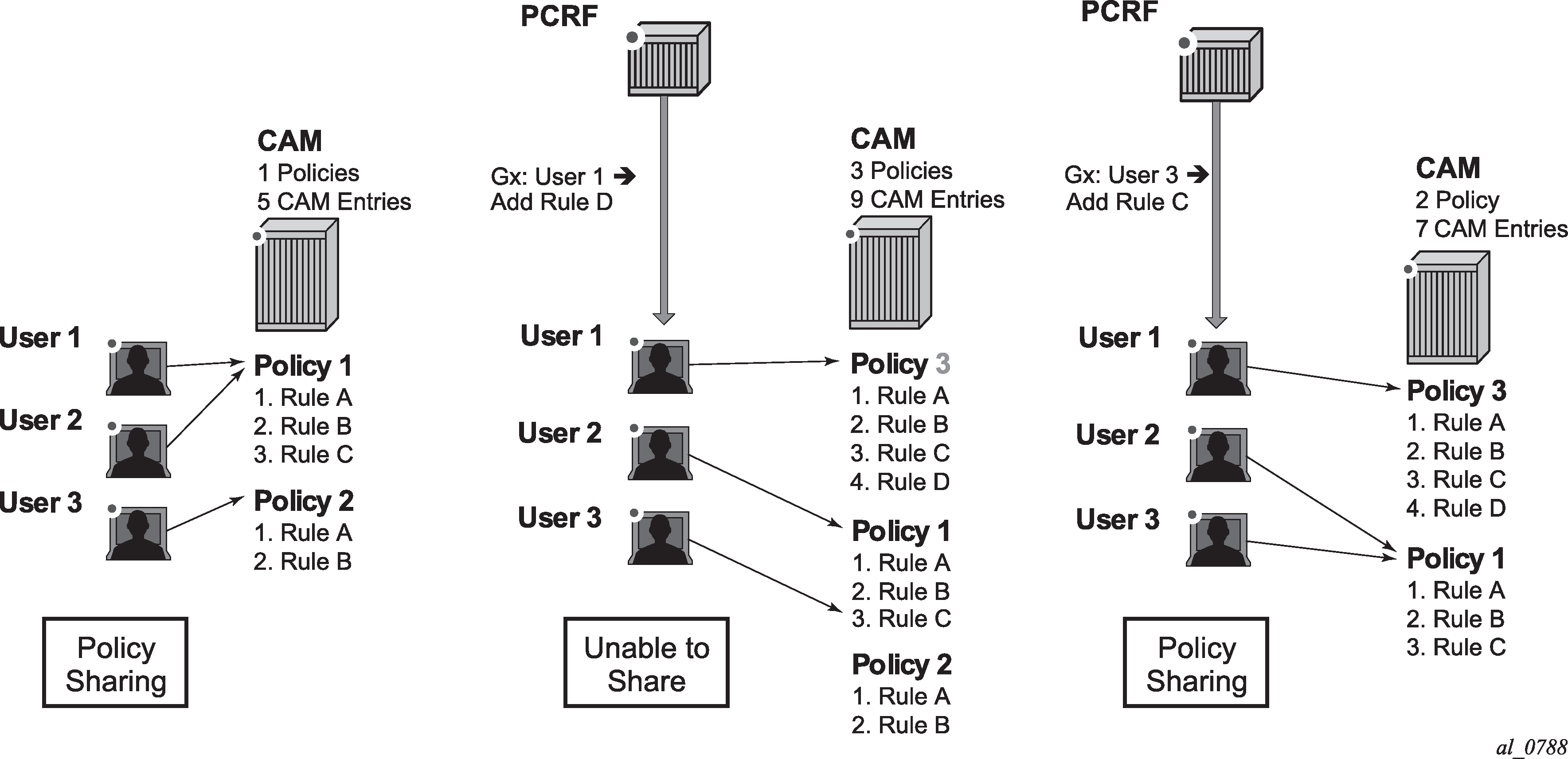
PCC rule name and PCC rule removal
Each PCC rule has a subscriber-host scope and it is referred to it by its name which is assigned by the operator on PCRF. The rules with exactly the same content but different rule names are evaluated into separate rules. To optimize performance and maximize scale, it is recommended that the rules sharing the same content have the same name (as provisioned in the PCRF).
PCC rules can be removed from the node via a Gx directive by referencing the PCC rule name. The rule name is supplied via the Charging-Rule-Name AVP at the time of the rule submission to the node by the PCRF. There is no Gx mechanism that would remove all PCC rules at once. Each PCC rule must be removed individually.
The AVP used to remove the rule from the node is:
Charging-Rule-Remove ::= < AVP Header: 1002 >
*[ Charging-Rule-Name ]
An example of rule instantiation and rule removal is shown in Policy removal by name.
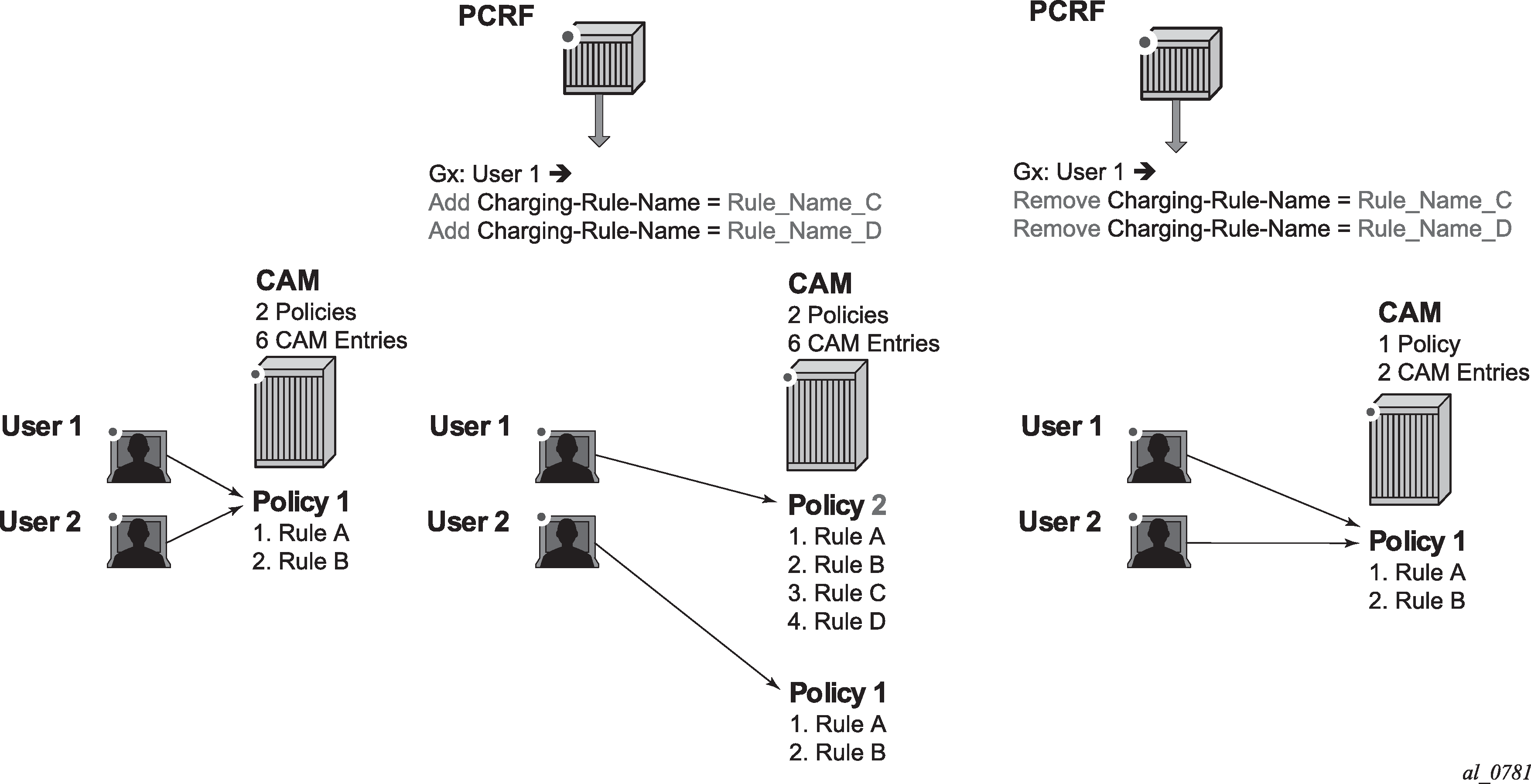
Gx rule ordering
Entries in IPv4/v6 filter and QoS policy created via CLI are ordered according to the numerical value associated with each entry command (which corresponds to the match condition) within the policy. CLI rules can be re-ordered with the renum command (in filters and QoS policies).
On the other hand, the PCC rules are ordered in one of the two ways. The difference between ordering of the entries with the rules, and the ordering of the rules themselves is:
PCC rules are prioritized according to the Precedence AVP within the Charging-Rule-Definition AVP. They are inserted within the subscriber-host policy, according to the Precedence AVP relative to the other PCC rules already applied to the subscriber-host. A PCC rule with a lower Precedence value is applied before a rule with a higher Precedence value.
The ordering behavior according to the Precedence is shown in PCC rule ordering - priority model.
Figure 29. PCC rule ordering - priority model 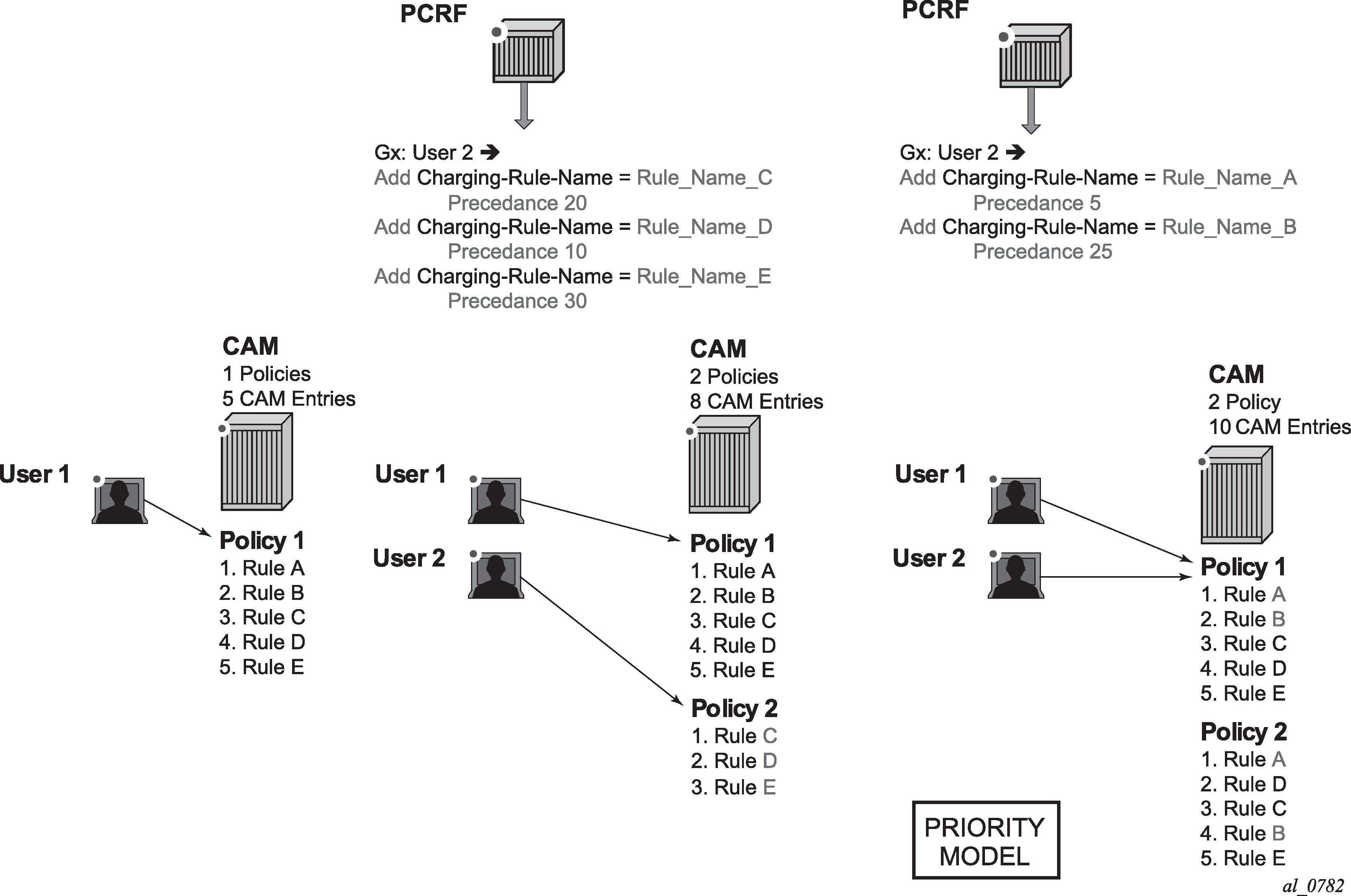
Automatic optimization of PCC rules. Automatic optimization is used in cases where the PCC rule order is not important to the operator. Then, the node optimizes the rule ordering to achieve the best possible scale by maximizing rule sharing. This optimization (or internal rule ordering) is performed for PCC rules without the Precedence AVP, or for PCC rules with the same Precedence value.
The premise of the automatic rule optimization is shown in PCC rule ordering - priority model.
Figure 30. Rule ordering - optimization model 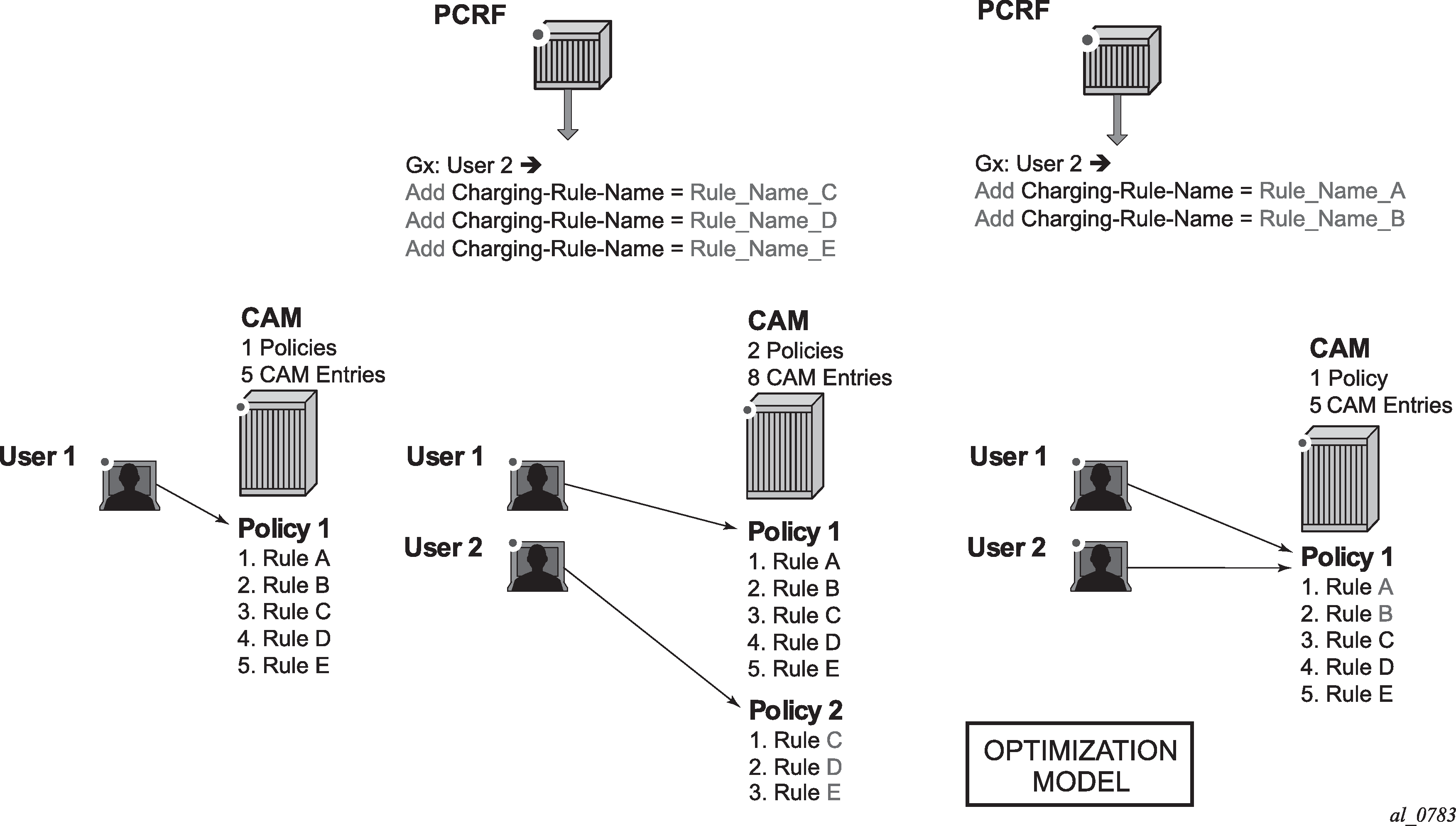
The ordering of PCC rules has no effect on the ordering of the static entries in the base qos-policy or filter.
Mixing of the PCC rules with the Precedence AVP and without Precedence AVP is allowed for the same subscriber-host. PCC rules without the Precedence AVP are inserted at the end of all PCC rules that do have the Precedence value set explicitly. In other words, the Precedence value for PCC rules without the explicitly configured Precedence AVP is assumed to be the highest. The PCC rules without the Precedence value are automatically inserted at the bottom of the PCC rule range.
A distinction should be made between the order of PCC rules in a PCC rule set and the order between the entries within each PCC rule. A PCC rule contains a group of classifiers that are all associated with the same actions. Therefore, the order of the entries (equivalent to match conditions) within any specific PCC rule does not matter (all entries result in the same action). For this reason, PCC rules with identical name and identical entries but different order of the entries are automatically ordered in a way that would allow more optimal sharing of the rules between different subscribers.
PCC rule override
A PCC rule applied to a subscriber-host on the node can be overridden by re-submitting the PCC rule with the same name but different contents.
If at least one new flow is sent in the PCC rule update, then the existing flows are removed and replaced with the new flow. If no new flows are submitted, then the existing flows stay in place.
If there are conflicting parameters between the existing rule and the modified rule (for example the combination of the unsupported actions), the PCC rule override fails.
Aggregation of IP-criterion
An action with a PCC rule can be applied for a set of IP-criterion.
For example, a single policer can be instantiated for a set of flows for rate-limiting purposes.
A pseudo Gx directive would look like this:
Charging-Rule-Install — Directive to install the rule in 7750 SR
Charging-Rule-Definition — PCC rule definition created on PCRF
Charging-Rule-Name = Rule-1 — PCC rule name
Flow1 — match-criteria for flow 1
Flow2 — match-criteria for flow 2
Flow 2 — match-criteria for flow 3
Rate-limit — rate-limiting action applicable as an aggregate action for all 3 flows
All three flows are fed into the same rate limiter (policer).
Combining IPv4 and IPv6 entries within the rule
IPv4 flow entries and IPv6 flows entries can be combined within the same PCC rule. The actions that carry the IP address are address-type-specific (for example next-hop-redirect). All other actions (rate-limit, FC change, and so on) are universal and it are applied to both flow types (IPv4 and IPv6). The node automatically sorts out flow types (IPv4 and IPv6) within the rule and apply corresponding actions.
If the rule contains a mismatching flow type and actions (for example, IPv4 flows and IPv6 specific actions), the rule is rejected. It is the operator’s responsibility to ensure that the address-type-specific actions in the rule have corresponding flows to which they can be applied.
Gx rules with multiple actions and action sharing
PCC rules can contain multiple actions. For the list of support action combinations, see the PCC rules.
Alc-NAS-Filter-Rule-Shared AVP vs Flow-Information AVP
A Gx rule (as defined in a single Charging-Rule-Definition AVP) can contain either Flow-Information AVP or Alc-NAS-Filter-Rule-Shared AVP, but not both simultaneously.
Presence of either AVP within the Charging-Rule-Definition AVP determines the mode of operation for the rule:
Alc-NAS-Filter-Rule-Shared AVP indicates the mode of operation in which the permit or deny action is part of the flow definition itself (Alc-NAS-Filter-Rule-Shared AVP). This mode of operation is referred as NAS filter inserts. The basic format of the AVP is the following (RFC 4849 and 4005; AVP Code 400):
<action> <direction> <protocol> from <source> to <destination> <options>.
There can be multiple ip-criteria definitions within the rule per subscriber-host, and each ip-criteria carries its own permit/deny action. There can be only one such rule (Charging-Rule-Definition) per subscriber-host. The rule entries are installed within the filter range defined by the following command:
sub-insert-shared-radius start-entry <entry-id> count <count>
under the following CLI hierarchy:
config>filter>ip-filter>
config>filter>ipv6-filter
Such rule cannot be removed by the Charging-Rule-Remove directive referencing the rule name. Instead, each such Gx rule overwrites the previous one.
Flow-Information AVP indicates the mode of operation whereby all the flows in the rule share the same actions carried in separate AVPs. This mode of operation is referred to as PCC rule inserts. The rule entries are installed within the filter or qos-policy range defined by the following command:
sub-insert-shared-pccrule start-entry <entry-id> count <count>
under the following CLI hierarchy:
config>filter>ip-filter>
config>filter>ipv6-filter>
config>qos>sap-ingress>
config>qos>sap-egress>
There can be multiple flow based rules present in an orderly fashion and each rule can be individually removed by referencing its name.
Both modes of operation are supported simultaneously for the subscriber host.
RADIUS and Gx interaction
Gx and RADIUS (CoA) policy management interfaces are simultaneously supported for the same subscriber-host.
RADIUS and Gx share the same entries for filter entry inserts (NAS-Filter-Rules and Alc-NAS-Filter-Rule-Shared) and therefore the most recent insert overrides the previous one. Similar logic applies to subscriber-string overrides and QoS overrides, where the most recent source, overrides the previous one.
However, PCC rules (IP-criteria based Gx rules) are provisioned in a separate filter ‛entry’ space from RADIUS and Gx filter inserts and therefore the PCC rules and RADIUS/Gx based filter inserts can independently coexist.
Filter/QoS-policy entry order is shown in CAM table population. The order of configuration blocks (static, PCC rules or NAS filter inserts) is configurable. For example, an operator can specify that static filter entries are populated before PCC rules which are then populated before NAS filter inserts.
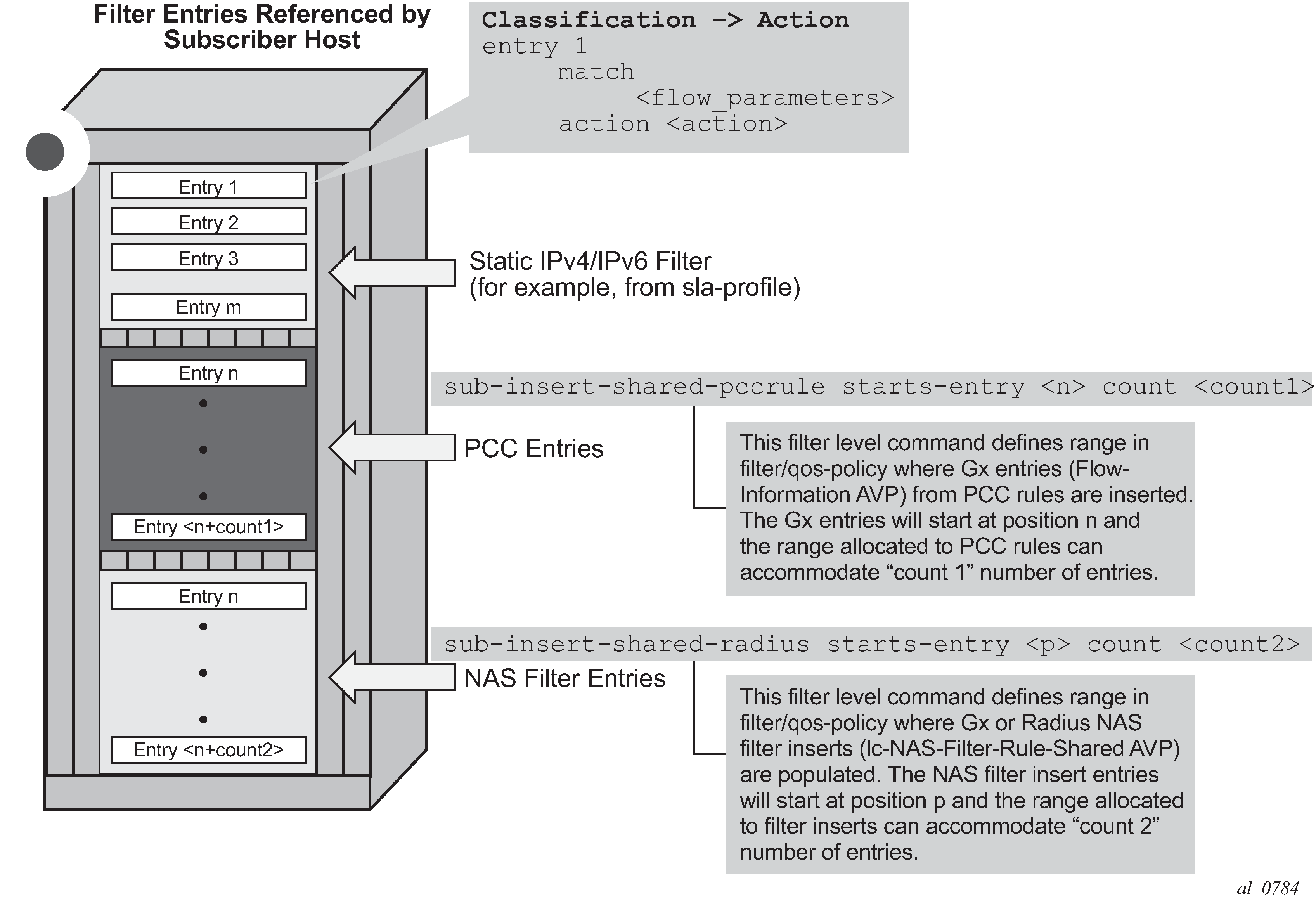
Bulk changes while Gx rules are active
When PCC rules are applied to a subscriber-host, the operator can modify some of the CLI parameters in the base QoS or filter policies. For example, the operator can add and remove terms in the base ACL filter.
CLI modifiable parameters in base QoS policy that contains clones lists the parameters in the QoS policy that can be changed. Adding or removing queue and policer, re-mapping of FC, modifying the DSCP map or adding or removing static IPv4 or IPv6 criteria entries with action different from FC, profile, or priority is not allowed.
Modified parameters in the base QoS policy or filter referenced in the sla-profile affects all subscribers using this sla-profile. Replacing the base QoS or filter policy in sla-profile is not allowed for any subscriber-host if a clone of the base QoS or filter policy exist anywhere in the system.
However, replacing the base filter ID for a host using CoA or Gx override is allowed. Then, only the targeted host is affected and all existing PCC rules for this host are merged with the new filter.
| CLI |
|---|
config>qos>sap-ingress>queue |
[no] cbs - Specify CBS |
drop-tail low [no] percent-reduction-from-mbs - Specifies the drop tail for out-of-profile packets |
[no] mbs - Specify MBS |
[no] packet-byte-of* - Specify packet byte offset |
[no] parent - Specify the scheduler to which this queue feeds |
[no] percent-rate - Specify percent rates (CIR and PIR) |
[no] rate - Specify rates (CIR and PIR) |
config>qos>sap-egress>queue |
[no] cbs - Specify CBS rate |
drop-tail low [no] percent-reduction-from-mbs - Specifies the drop tail for out of profile packets |
drop-tail exceed [no] percent-reduction-from-mbs - Specifies the drop tail for exceed profile packets |
drop-tail high [no] percent-reduction-from-mbs - Specifies the drop tail for in profile packets |
drop-tail highplus [no] percent-reduction-from-mbs - Specifies the drop tail for inplus profile packets |
[no] mbs - Specify MBS rate |
[no] parent - Specify the scheduler to which this queue feeds |
[no] percent-rate - Specify percent rates (CIR and PIR) |
[no] port-parent - Specify the port-scheduler to which this queue feeds |
[no] rate - Specify rates (CIR and PIR) |
[no] packet-byte-of* - Specify packet byte offset |
config>qos>sap-ingress>policer |
[no] cbs - Specify CBS |
[no] high-prio-only - Specify high priority only percent-of-mbs |
[no] mbs - Specify MBS |
[no] packet-byte-of* - Specify packet byte offset |
[no] parent - Specify the arbiter to which this policer feeds |
[no] percent-rate - Specify percent rates (CIR and PIR) |
[no] rate - Specify rates (CIR and PIR) |
config>qos>sap-egress>policer |
[no] cbs - Specify Cbs |
[no] high-prio-only - Specify high priority only percent-of-mbs |
[no] mbs - Specify Mbs |
[no] packet-byte-of* - Specify packet byte offset |
[no] parent - Specify the scheduler to which this policer feeds |
[no] percent-rate - Specify percent rates (CIR and PIR) |
[no] rate - Specify rates (CIR and PIR) |
config>qos>sap-ingress>ip-criteria>entry>match |
config>qos>sap-egress>ip-criteria>entry>match |
config>qos>sap-ingress>ipv6-criteria>entry>match |
config>qos>sap-egress>ipv6-criteria>entry>match |
PCC rule direction
PCC rules are unidirectional. The PCC rule direction is determined based on the value of the Flow-Direction AVP within the Flow-Information AVP. In the absence of the Flow-Direction AVP, the PCC rule direction is determined based on the Flow-Description AVP (as part of IPFilterRule direction field). Both of these AVPs (Flow-Direction and Flow-Description) are part of the PCC rule definition.
If the action within the PCC rule is in conflict with the direction of the flow, the PCC rule instantiation fails. For example, an error is raised if the flow direction is UPSTREAM, while the action is ‛Max-Requested-Bandwidth-DL’ (downstream bandwidth limit).
Action
A PCC rule may contain multiple actions. Each action is carried in a separate, action specific AVP. The action specified in the flow-description>ipfilter rule data type is ignored. If rule contains multiple instances of the same action, each with a different value, the last occurrence of the action value is in effect.
Not all of the action types can be applied at the same time. The allowed combination of the actions per direction is described in CLI modifiable parameters in base QoS policy that contains clones and Failure reporting .
Rate-limiting action (ingress, egress)
Rate-limiting action is implemented via policers. The policer is dynamically created at the PCC rule instantiation time. The rate can be enforced based on Layer 2 rates or Layer 3 rates.
Dynamically instantiated policers have their own policer ID range to avoid the conflict with static policers.
The dynamically created policers shares common properties configured under the dynamic-policer CLI hierarchy:
configure
qos
sap-ingress/egress
dynamic-policer
stat-mode <stat_mode>
parent <arbiter-name> [weight <weight-level>] [level <level>
mbs <size> [bytes | kilobytes]
cbs <size> [bytes | kilobytes]
packet-byte-offset {add <add-bytes> | subtract <sub-bytes>}
range start-entry <entry-id> count <count>
The configured dynamic policer parameters can be overridden per PCC rule by including the Alc-Dynamic-Policer grouped AVP in the QoS-Information AVP. All AVPs are optional and when specified override the configured value:
ingress PCC rules
+--1046 Alc-Dynamic-Policer +--1039 Alc-Policer-Parent +--1022 Alc-Arbiter-Name +--1040 Alc-Parent-Level +--1041 Alc-Parent-Weight +--1008 Alc-Committed-Burst-Size-UL +--1009 Alc-Maximum-Burst-Size-UL +--1042 Alc-Stat-Mode-UL +--1044 Alc-Packet-Byte-Offset-UL-
egress PCC rules
+--1046 Alc-Dynamic-Policer +--1039 Alc-Policer-Parent +--1022 Alc-Arbiter-Name +--1040 Alc-Parent-Level +--1041 Alc-Parent-Weight +--1010 Alc-Committed-Burst-Size-DL +--1011 Alc-Maximum-Burst-Size-DL +--1043 Alc-Stat-Mode-DL +--1045 Alc-Packet-Byte-Offset-DL
The policer rates are part of PCC rule itself and are not part of static configuration.
The generic Gx directive for rate-limiting action is:
Charging-Rule-Install ::= <AVP Header: 1001>
Charging-Rule-Definition <AVP Header: 1003>
Charging-Rule-Name <AVP Header: 1005>
QoS-Information <AVP Header: 1016>
Max-Requested-Bandwidth-UL <AVP Header: 516> [bps] 3GPP 29.214 §5.3.15
Max-Requested-Bandwidth-DL <AVP Header: 515> [bps] 3GPP 29.214 §5.3.14
Guaranteed-Bitrate-UL <AVP Header: 1026> [bps] 3GPP 29.214 §5.3.26
Guaranteed-Bitrate-DL <AVP Header: 1027> [bps] 3GPP 29.214 §5.3.25
The above rate limits refer to PIR and CIR rates of the dynamic policer in the respective direction.
Dynamic policers and queue mappings
Once traffic is processed by the dynamic policers on ingress, the traffic flows through the policer-output-queues shared queues. Traffic through dynamic policers always bypass subscriber queues or policers on ingress that are statically configured in the base QoS policy.
Similar behavior is exhibited when static policers are configured on egress. Traffic outputting dynamic policer is never mapped to another static policer. Instead, such traffic is mapped to the corresponding shared queue in a queue-group. By default, this queue-group is the policer-output-queue group. However, the selection of the queue-group is configurable.
In contrast to the above, traffic processed by dynamic policers can be fed into statically configured subscriber (local) queues on egress. Dynamic policers and subscriber queues are tied through the forwarding-class.
The policer to local queue mapping and inheritance of the forwarding-class is shown. In this example, the mapping of traffic —> forwarding-class in rule 2 (flow 2) depends on the DSCP bits in the traffic flow. If the DSCP value in this traffic flow are different from the explicitly configured DSCP values in the static (base) QoS policy, then traffic is mapped to the default forwarding-class.
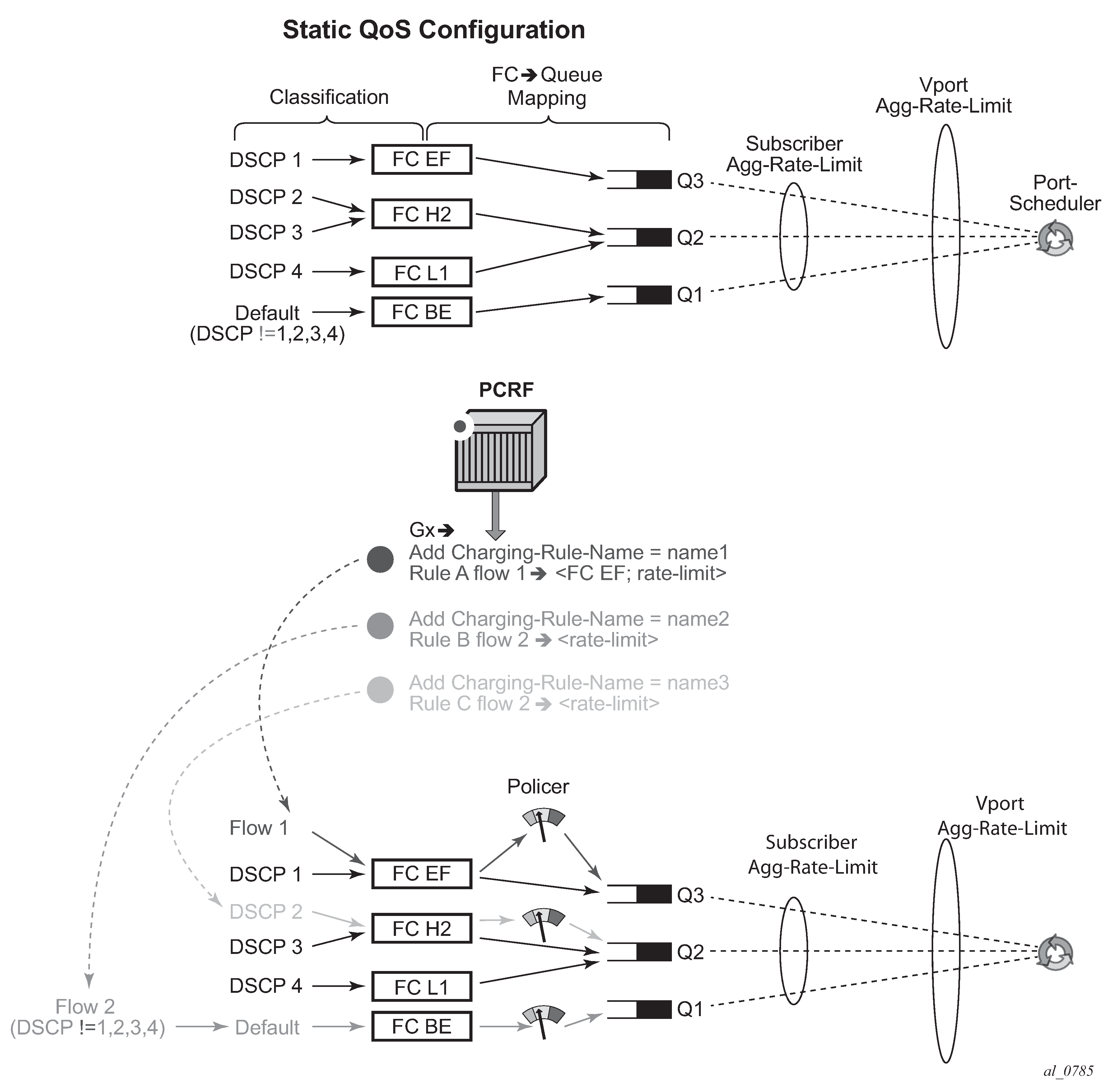
Dynamic policer rates and accounting statistics
By default, policer rates are configured based on Layer 2 frame length (for example, the Ethernet header plus the IP packet). This can be changed by the packet-byte-offset (PBO) command under the policer. If the policer is fed into a local queue, the PBO of the policer does not affect the PBO of the local queue it is feeding.
The rates for local subscriber queues can be independently measured based on Layer 2 or Layer 1 frame length and the queue statistics can be measured based on Layer 1, Layer 2 or Layer 3 (IP-only) frame length. The IP-only stats for queues can be configured in the sub-prof>volume-stats-type {ip|default}.
Dynamic policer (instantiated because of rate limiting or usage-monitoring action in PCC rules) statistics are not reported in RADIUS-based accounting. On egress, this has no effect on volume counters in RADIUS-based accounting, because the dynamic policers are normally fed into local queues whose statistics are reported in RADIUS-based accounting. However, on ingress, the dynamic policers are always fed into the queue-group queues which are excluded from RADIUS based accounting. The consequence is that the ingress RADIUS-based accounting lacks statistics for the traffic that is flowing via dynamic policers.
If the dynamic policer is feeding a local queue, the aggregate statistics in show commands for such queue are not reported to avoid double counting (because the traffic statistics in show commands are already reported for the dynamic policer). However, the per-queue statistics are reported in show commands, irrespective of whether the policer is mapped to the local queue or not.
To avoid losing aggregate SAP or subscriber stats in show commands, the recommendation is to have policers feed into local queues which are not already mapped to an FC. For example:
queue 4 create //Not counted since policer 2 is feeding it
exit
policer 2 create
exit
fc be create
queue 4 //Not counted
exit
fc l1 create
queue 4 //Not counted
exit
fc ef create
policer 2 queue 4
exit
FC BE, FC2 L1 —> queue 4
FC EF —> policer 2, queue 4
Then, traffic from queue 4 is not counted in aggregate stats at all and consequently the aggregate accounting information is lost for FC BE and FC L1.
Forwarding-class change (ingress, egress)
Traffic can be re-prioritized via PCC rule by re-classification into a different forwarding class. The forwarding-class can be changed in several cases.
The original static mapping between traffic type, forwarding-class and the queue/policer in the base qos-policy is configured outside of the ip-criteria CLI hierarchy.
For example:
config>qos>sap-egress#
dscp af11 fc "af"
Such mapping is configured outside of CAM and therefore it has lower evaluation priority than the mapping configured via PCC rule which is installed in CAM.
The original static mapping is provisioned in the base qos-policy via ip-criteria CLI hierarchy.
For example:
config>qos>sap-egress>#
ip-criteria
entry 40000 create
match
dscp af11
exit
action fc "af"
exit
exit
Then, the configured entry range for PCC rules must precede the static entry (match criteria) in which the original forwarding-class is configured. The insertion point (entry) is controlled via configuration: sub-insert-shared-pccrule start-entry <entry-id> count <count> command under the qos-policy.
In both of the above cases, the following PCC rule would override forwarding-class for traffic with DSCP value of 10 (af11 traffic class) from value af to h2.
Charging-Rule-Install
Charging-Rule-Definition
Charging-Rule-Name = fc-change
Flow-Information
ToS-Traffic-Class = 00101000 11111100
Flow-Direction = 1
QoS-Information
QoS-Class-Identifier = 2
The eight forwarding classes are mapped to QCIs (3GPP TS 23.203 §6.1.7.2) in the manner displayed in Forwarding class and QCI mapping.
| Forwarding class | QCI |
|---|---|
|
BE |
QCI 8 |
|
L2 |
QCI 7 |
|
AF |
QCI 6 |
|
L1 |
QCI 4 |
|
H2 |
QCI 2 |
|
EF |
QCI 3 |
|
H1 |
QCI 1 |
|
NC |
QCI 5 |
The generic Gx directive for forwarding-class change:
Charging-Rule-Install ::= <AVP Header: 1001>
Charging-Rule-Definition <AVP Header: 1003>
Charging-Rule-Name <AVP Header: 1005>
QoS-Information <AVP Header: 1016> 3GPP 29.212 §5.3.16
QoS-Class-Identifier <AVP Header: 1028> 3GPP 29.212 §5.3.17
QoS forward (ingress and egress)
Create an ip-criteria or ipv6-criteria entry with no action specified. Matching traffic is forwarded without a QoS action and not match on a next entry (match and exit behavior). This is equivalent to an allowlist entry. CLI equivalent:.
config>qos
sap-ingress | sap-egress <id> create
ip-criteria | ipv6-criteria
entry <id> create
match
<5-tuple | dscp>
exit
action
exit
exit
The generic Gx directive for QoS forwarding:
Charging-Rule-Install ::= <AVP Header: 1001>
Charging-Rule-Definition <AVP Header: 1003>
Charging-Rule-Name <AVP Header: 1005>
Alc-QoS-Action = Forward (1) <AVP Header: 1028>
Next hop redirect (ingress)
The next hop redirection explicitly or implicitly changes the next hop for the traffic flow within the same service ID (routing context) or a different service ID (routing context).
If the next hop is not explicitly provided, the next hop is selected automatically, according to the routing lookup in the referenced service ID.
The generic Gx directive:
Charging-Rule-Install <AVP Header: 1001>
Charging-Rule-Definition <AVP Header: 1003>
Charging-Rule-Name <AVP Header: 1005>
Alc-Next-Hop :: <AVP Header: 1023>
Alc-Next-Hop-IP <AVP Header: 1024>
Alc-V4-Next-Hop-Service-id <AVP Header: 1025>
Alc-V6-Next-Hop-Service-id <AVP Header: 1026>
This action overwrites the routing table lookup based on the destination IP and sets the next hop to the:
IPv4/6 address within the same service ID
IPv4/6 address within a different service ID
The next hop search is indirect, which means that if the explicitly provided next hop in the PCC rule cannot be found in the routing table, then an additional routing table lookup is performed to find the path (next hop) to the indirect next hop from the PCC rule.
If only the service-id is specified in PCC rule (without the next hop), then the next hop is selected from the specified service-id based on the destination IP address of the packet.
HTTP redirect (ingress)
HTTP redirect uses Redirect-Information AVP from 3GPP 29.212, §5.3.82.
The generic Gx directive:
Redirect-Information < AVP Header: 1085 >
Redirect-Support < AVP Header: 1086 >
Redirect-Address-Type < AVP Header: 433 >
Redirect-Server-Address < AVP Header: 435 >
Filter forward/drop (ingress and egress)
This action is used to control traffic flow within a PCC rule by using ALU specific AVP. PCC rules are utilizing filters and QoS policies as distinct building blocks. This action within a PCC rule creates an IP or IPv6 filter entry with an action forward or drop.
The CLI equivalent follows:
config>filter
ip-filter | ipv6-filter <id> create
entry <id> create
match
<5-tuple | dscp>
exit
action
forward | drop
exit
exit
exit
The generic Gx directive for filter forward/drop is implemented through ALU specific AVP:
Charging-Rule-Install ::= <AVP Header: 1001>
Charging-Rule-Definition <AVP Header: 1003>
Charging-Rule-Name <AVP Header: 1005>
Alc-Filter-Action = Forward (1) <AVP Header: 1027>
Alc-Filter-Action = Drop (2)
Service gating function
The service gating function is used to enable or disable the service that is represented by the PCC rule. This action is enforced through a Flow-Status AVP (AVP code 511) - 3GPP 29.214, §5.3.11. The system supports the following values (actions) for the Flow-Status:
- enabled (2)
- enables all actions specified within the PCC rule. Note that although Flow-Status (service gating function) is considered an action, in this context it is used to enable all other actions that are explicitly set within the PCC rule.
- disabled (2)
- disable all action specified within the PCC rule and drops the traffic
The service gating function is applicable in the direction that is associated with the rule (PCC rules in the system are unidirectional).
Flow-Status is by default enabled (2) (if the Flow-Status AVP is not explicitly specified within the PCC rule). Flow-Status=Enabled must be accompanied by one or more additional actions in the same PCC rule (see Gx rules with multiple actions and action sharing for a list of allowed simultaneous actions), otherwise the PCC rule instantiation in the node fails.
If the Flow-Status is set to disabled (3), all other actions within the same rule loses their meaning because the packet is dropped. The disabled directive disables the flow of packet through the system. A disabled Flow-Status is equivalent to the Alc-Filter-Action = Drop (2).
This AVP is carried inside of Charging-Rule-Definition (3GPP 29.212, §5.3.5):
Charging-Rule-Definition ::= < AVP Header: 1003 >
{ Charging-Rule-Name }
*[ Flow-Information ]
[ Flow-Status ]
[ QoS-Information ]
[ Precedence ]
*[ Flows ]
[ Monitoring-Key]
[ Redirect-Information ]
*[ AVP ]
PCC rule provisioning example
The following is an example of PCC rule provisioning in a CCA-I message:
<CC-Answer> ::= < Diameter Header: 272, PXY >
< Session-Id >
{ Auth-Application-Id }
{ Origin-Host }
{ Origin-Realm }
[ Result-Code ]
[ Experimental-Result ]
{ CC-Request-Type }
{ CC-Request-Number }
*[ Supported-Features ]
*[ Event-Trigger ]
[ Origin-State-Id ]
Charging-Rule-Install ::= <AVP Header: 1001> -> host instantiation
Charging-Rule-Name = ‟ingr-v4:7”
Charging-Rule-Name = ‟eggr-v6:5”
Charging-Rule-Name = ‟Sub-Profile:prem”
Charging-Rule-Name = ‟Sla-Profile:voip+data”
Charging-Rule-Name = ‟Inter-Dest:vport-AN-1”
Charging-Rule-Install —> service instantiation
Charging-Rule-Definition
Charging-Rule-Name = ‟service-1” —> should be able to remove the rule by name later on
Flow-Information —> traffic flow definition
Flow-Description = ‟permit in 6(TCP) from any to ip 10.10.10.10/32 40000-40010"
ToS-Traffic-Class = 00101000 11111100] —> DSCP definition (value mask). In case of the DSCP, Flow-Direction (1080) AVP must be included.
Flow-Direction = UPSTREAM —> traffic flow direction
QoS-Information <AVP Header: 1016>
Max-Requested-Bandwidth-UL = 10000000 —> UPSTREAM rate definition (not downstream, since the traffic flow direction is IN)
QoS-Class-Identifier = 3 —> EF forwarding class; in general one of 8 forwarding-classes (FC) in 7450 ESS and 7750 SR (be|l2|af|l1|h2|ef|h1|nc). This is used for re-prioritization of the traffic.
In this example the host is instantiated using the two Charging-Rule-Install AVPs. The first is used to instantiate the host. The second is used to instantiate the IP-criterion based service named service-1. Service-1 is defined as the upstream traffic flow with traffic class AF11, destined for the TCP port range 40000-40010 on the node with IP address 10.10.10.10/32.
The actions for this traffic flow are:
rate-limit of 10M
change forwarding-class to AF11
Operational aspects
The commands used to examine dynamic rules and NAS filter inserts associated with the subscriber hosts are shown in Overview of PCC rule-related operational commands.
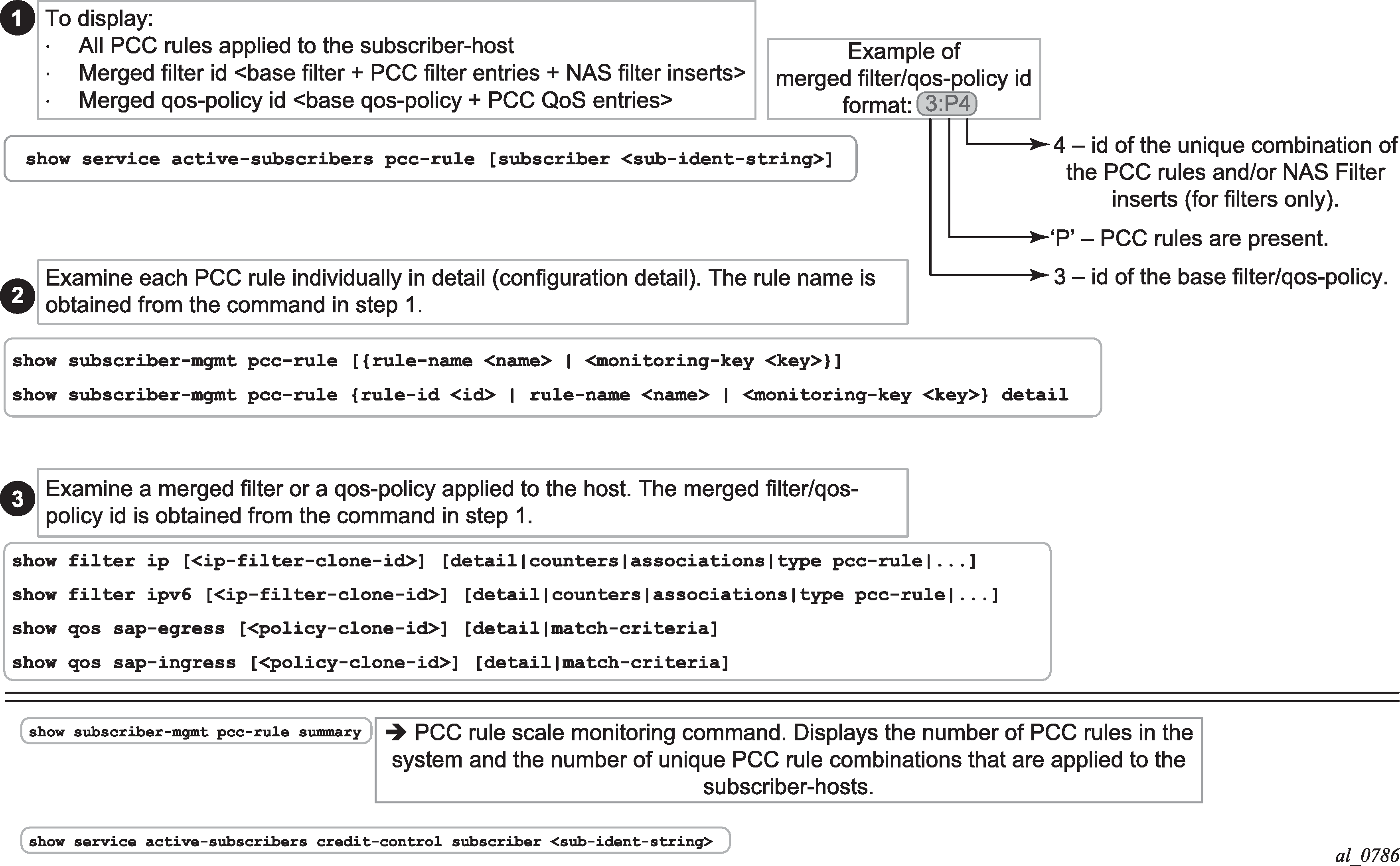
PCC rules and capacity planning
One of the most important factors to be considered for capacity planning with PCC rules is the number of unique policies that are applied to subscribers.
A unique policy constitutes a base a QoS policy or filter ID along with all PCC rules that are applied to a subscriber or a set of subscribers.
Now examine an example where there are ‛n’ PCC rules in the system (‛n’ qos rules and ‛n’ ACL filter rules). Those rules are applied to IPv4 traffic in ingress direction. Further, assume that the PCC rules do not have defined Precedence AVP, which means that the system can optimize their order for maximum sharing and maximized scale. Then, ‛n’ PCC rules can be combined by various permutation into 2^n-1 unique combinations Next assumption is that there are five possible base qos-policies for IPv4 traffic in ingress direction and five possible base filters for IPv4 traffic in the ingress direction.
Given the above, the unique PCC rule combinations (2^n-1) together with five base QoS polices produce 5*(2^n-1) unique qos-policies per ingress IPv4. Same logic can be applied for ingress IPv4 filters.
This exercise must be repeated for egress direction as well as for IPv6 type traffic, by taking into consideration the number of respective base qos-policies/filters and the number of PCC rules.
When the number of unique policy combinations is determined and ensured that it is within the system limits, each policy must be further evaluated to determine the number of entries it takes in CAM.
PCC rule scaling example
Example of the scaling limits for PCC rules depicts an example relevant to capacity planning with focusing on understanding the scaling limits pertaining to the number of PCC rules and their mutual combinations when they are applied to the subscriber hosts.
This example is focuses on an IPv4 filter applied in ingress direction but similar logic can be used in understanding other policy types (QoS, egress, IPv6).
The system/line card limits in this example are set to the following values for illustration purposes only:
Number of PCC rules per system is 1K.
Max number of rules per subscriber host is 64.
Max number of combinations of the PCC rules (or services) that are active (applied to the subscriber-hosts) per system is 4K.
Max ingress IPv4 filter CAM entries per FP2/FP3 is 64k.
Max filters per system is 16k.
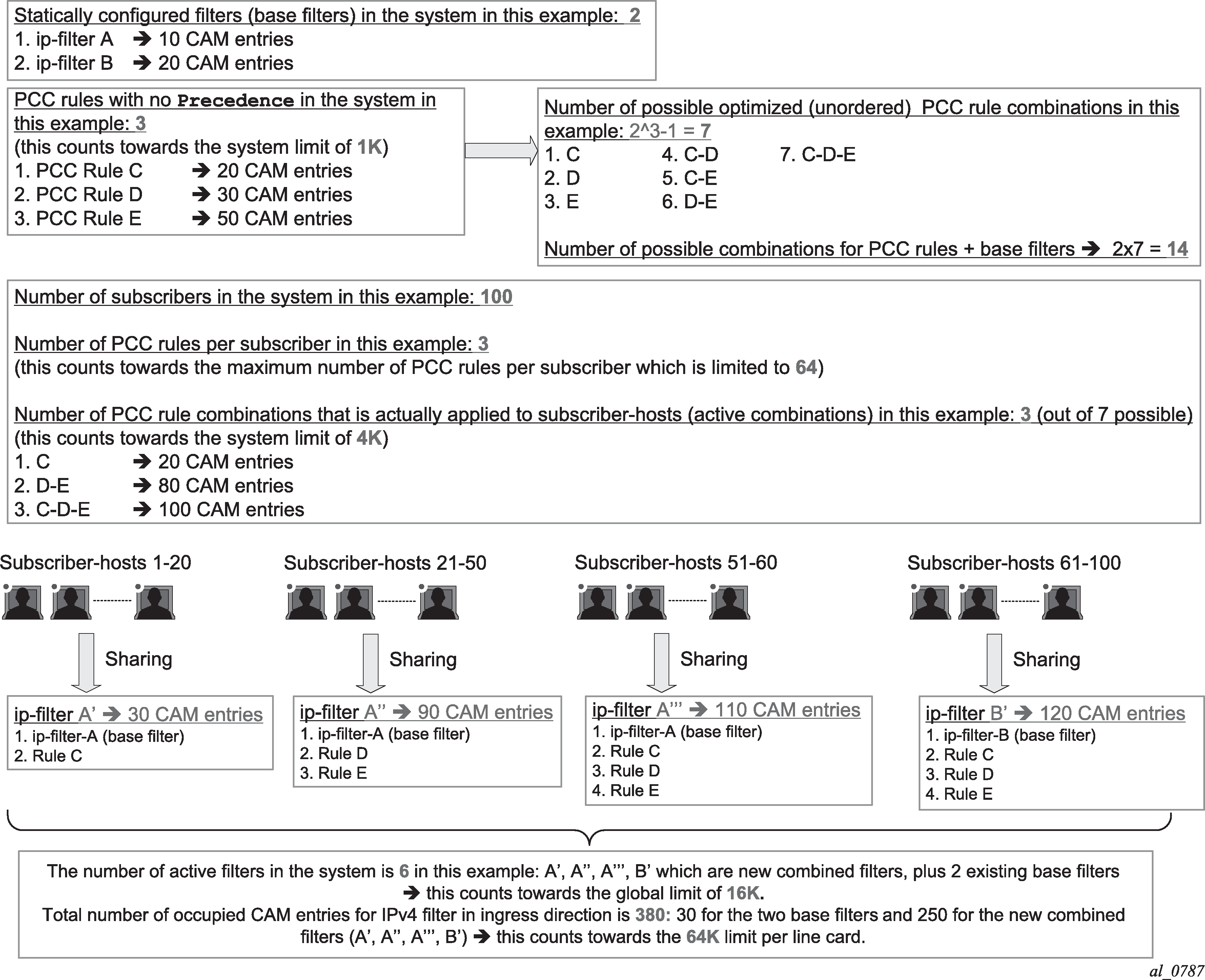
NAS filter inserts
Gx filter entries inserted via the NAS-Filter-Rule are subscriber-host-specific entries. This means that in the upstream direction, the source IP address in the NAS-Filter-Rule is always internally set by the node to the IP address of the subscriber host itself. Similarly, in the downstream direction, the destination IP address in the NAS-Filter-Rule is set by the node to be the IP address of the subscriber-host itself.
On the other hand, the entries in the Alc-NAS-Filter-Rule-Shared AVP are processed as received without any modifications. This means that such entries can be shared with all the hosts that have the same Alc-NAS-Filter-Rule-Shared applied.
Similar to QoS overrides, NAS filter entries are not predefined on the node but instead they are defined under the Charging-Rule-Install — Charging-Rule-Definition AVP.
The Charging-Rule-Name AVP for NAS filter inserts is an arbitrary name that is part of Charging-Rule-Definition AVP in which NAS-Filter-Rule AVP or Alc-NAS-Filter-Rule-Shared is provided. Such Charging-Rule-Name is used to report errors related to instantiation of the inserts.
Examples of NAS entry inserts
The following AVPs identify NAS filter inserts that are applied to a subscriber host. Those AVPs can be included in CCA-i, CCA-u or RAR message sent from the PCRF.
Charging-Rule-Install ::= <AVP Header: 1001>
Charging-Rule-Definition <AVP Header: 1003>
Charging-Rule-Name <AVP Header: 1005> = ‟allow-all”
Alc-NAS-Filter-Rule-Shared <AVP Header: 158> = "permit in ip from any to any "ASCII NUL" permit out ip
from any to any"
In this example, the filter entry defined in Alc-NAS-Filter-Rule-Shared AVP is inserted in the clone of the existing base filter for the subscribers.
Error handing and rule failure reporting in ESM
The Gx rule (overrides, PCC rules or NAS filter inserts) instantiation failure can occur on two levels:
AVP decoding level in the Diameter
The Gx message contains an unrecognized AVP with the M-bit set. Then, all Gx rules (ESM, UM and AA) in the message are rejected and the CCR-U with the Charging-Rule-Report AVP (rule status) and Error-Massage AVP (failure description) or an RAA message with the appropriate Result-Code AVP (fail – 5xxx), Error-Message AVP (description) and the Failed-AVP AVP are sent to the PCRF.
Invalid content of a supported AVP with the M-bit set triggers the same response. Invalid content of an AVP refers to the malformed syntax of an AVP that carries the type of the AVP value implicitly embedded in the AVP value itself. Consider sla-profile:rule-name-1 string. then, the sla-profile: refers to the type of the value carried in the Charging-Rule-Name AVP. The value that the Charging-Rule-Name carries is rule-name-1 and this value represents the sla-profile name already configured on the node (as opposed to filter, sub-profile, category-map, and so on). If the sla-profile is misspelled (type is unrecognized), the entire AVP is un-decodable.
Gx rule instantiation level in ESM, UM or AA
Each module (ESM, UM or AA) would fail all rules destined for it. The failure of a Gx rule within a module can be caused by referencing non-existing profile (for example sla-profile:unknown-name) or a lack of resources on the node. Then, a CCR-U message from the respective module is sent with the Rule-Report-Status AVP listing all the rules destined for this module and the corresponding Error-Message AVP describing the cause for the failure.
Another example that can cause all rules with the ESM module to fail would be invalid combination of actions within the rule.
AVP decoding failure in Gx
Reporting an AVP decoding problem in Gx is described in the following example:
A Gx directive is received to install two overrides on the node. The two overrides are supposed to change the sla-profiles and sub-profiles for the subscriber host. The AVP that is used to change the sla-profile is miss-formatted. The predefined sla-profile keyword in the Charging-Rule-Install AVP is misspelled as spa-profile instead of sla-profile.
Charging-Rule-Install ::= <AVP Header: 1001>
Charging-Rule-Name <AVP Header: 1005> = ‟Sub-Profile:prem”
Charging-Rule-Name <AVP Header: 1005> = ‟Spa-Profile:voip+data”
Because the Charging-Rule-Name AVP has the M-bit set, the whole message fails and an error is reported. No rules within this Gx message is installed (not even the valid ones, then this would be the Charging-Rule-Name = ‟Sub-Profile:prem”).
The nature of the error depends on the original directive sent by the PCRF (RAR or CCA – push or pull model).
If the directive from the PCRF is passed with the cca command, the response is CCR-U with the following error related AVPs:
[ Error-Message ] — ‟Invalid value spa-profile:voip+data”
Charging-Rule-Report ::= < AVP Header: 1018 >
*[ Charging-Rule-Name ] — Spa-Profile:voip+data
[ PCC-Rule-Status ] — INACTIVE (1)
[ Rule-Failure-Code ] — GW/PCEF_MALFUNCTION (4)
Charging-Rule-Report ::= < AVP Header: 1018 >
*[ Charging-Rule-Name ] — Sub-Profile:prem
[ PCC-Rule-Status ] — INACTIVE (1)
[ Rule-Failure-Code ] — GW/PCEF_MALFUNCTION (4)
Failed-AVP ::= < AVP Header: 279 >
Charging-Rule-Name = Spa-Profile:voip+data
If the directive is passed to the node through RAR, the node responds with the following RAA message:
Failed-AVP ::= < AVP Header: 279 >
Charging-Rule-Name = Spa-Profile:voip+data
Result-Code ::= < AVP Header: 268 > = DIAMETER_INVALID_AVP_VALUE (5004)
Similarly, if the number of filter entries for each entry type (NAS-Filter-Rule — host-specific or Alc-NAS-Filter-Rule-Shared — shared) exceeds the maximum supported number (see the 7750 SR and VSR Gx AVPs Reference Guide), the whole message fails the decoding phase.
The reason that the Result-Code AVP is present in the RAA message and not in the CCR-U message is that this code is only allowed to be present in the answer messages, according to the standard.
ESM rule-installation failure
This assumes that the rule installation directives are successfully passed from the Gx module to the ESM module and the failure to install rules occurs in the ESM module.
In the Gx override example below, the referenced sla-profile is unknown. Then, all directives passed to the ESM module fails and consequently no rules or overrides are installed. The sub-profile change fails as well although the prem sub-profile is known in the system.
Charging-Rule-Install ::= <AVP Header: 1001>
Charging-Rule-Name <AVP Header: 1005> = ‟Sub-Profile:prem”
Charging-Rule-Name <AVP Header: 1005> = ‟Sla-Profile:unknown”
The error reporting flow is as follows:
If the directives are passed using the CCA command, the response is CCR-U command with the following error related AVPs:
[ Error-Message ] — ‟sla-profile ‛unknown’ lookup failed” Charging-Rule-Report ::= < AVP Header: 1018 > *[ Charging-Rule-Name ] — Sla-Profile:unknown [ PCC-Rule-Status ] — INACTIVE (1) [ Rule-Failure-Code ] — GW/PCEF_MALFUNCTION (4) Charging-Rule-Report ::= < AVP Header: 1018 > *[ Charging-Rule-Name ] — Sub-Profile:prem [ PCC-Rule-Status ] — INACTIVE (1) [ Rule-Failure-Code ] — GW/PCEF_MALFUNCTION (4)-
If the directive is passed to the node with RAR, the node responds with the following messages:
RAA = OK because the Gx module successfully processed the AVP parsing.
The RAA is followed by CCR-U, triggered by the rule instantiation failure in ESM module. CCR-U contains the following AVP related to the rule status:
[ Error-Message ] — ‟sla-profile ‛unknown’ lookup failed” Charging-Rule-Report ::= < AVP Header: 1018 > *[ Charging-Rule-Name ] — Sla-Profile:unknown [ PCC-Rule-Status ] — INACTIVE (1) [ Rule-Failure-Code ] — GW/PCEF_MALFUNCTION (4) Charging-Rule-Report ::= < AVP Header: 1018 > *[ Charging-Rule-Name ] — Sub-Profile:prem [ PCC-Rule-Status ] — INACTIVE (1) [ Rule-Failure-Code ] — GW/PCEF_MALFUNCTION (4)
Similar behavior would be exhibited if the directive is sent to the UM or AA modules. However, ESM, UM, and AA are separate modules and failure to install rules in one module does not affect rule installation in another.
Failure reporting in AA
Failure reporting in AA is performed in similar fashion as in ESM.
Instead of Charging-Rule-Report AVP, the ADC-Rule-Report is used:
ADC-Rule-Report ::= < AVP Header: 1097 >
*[ ADC-Rule-Name ]
[ PCC-Rule-Status ]
[ Rule-Failure-Code ]
*[ AVP ]
Summary of failure reporting
Failure reporting summarizes Gx failure reporting on the node.
| Failure event | Gx message received via CCA (pull model) | Gx message received via RAR (push model) |
|---|---|---|
AVP decoding/interpreting failure; M-bit cleared |
Ignore AVP |
Ignore AVP |
AVP decoding/interpreting failure; M-bit set |
CCR-U is sent by the node. CCR-U contains:
No rules within the message is instantiated on the node. |
RAA is sent by the node. RAA contains:
No rules within the message is instantiated on the node. |
Rule failure in ESM |
CCR-U is sent by the node. CCR-U contains:
No rules is instantiated in the ESM module. |
RAA with the Result-Code AVP ‛success’ (2001) is sent by the node, followed by a CCR-U. CCR-U contains:
No rules is instantiated in the ESM module. |
Rule failure in Usage-Monitoring (UM) |
CCR-U is sent by the node. CCR-U contains:
No rules is instantiated in the UM module. |
RAA with the Result-Code AVP ‛success’ (2001) is sent by the node, followed by a CCR-U. CCR-U contains:
No rules is instantiated in the UM module. |
Rule failure in AA |
CCR-U is sent by node. CCR-U contains:
No AA rules is instantiated in the AA module. |
RAA with the Result-Code AVP ‛success’ (2001) is sent by the node, followed by CCR-U. CCR-U contains:
No rules is instantiated in the AA module. |
Usage-Monitoring and reporting
Usage-Monitoring and reporting refers to the collection and reporting of octets (volume) that a service or application on the node has consumed during a specific period. The usage on the node is reported via the Gx interface to the PCRF. Based on this information, the PCRF can apply a specific action (policy change) to the entity being monitored. For example, QoS can be modified, or the service can be blocked when specific thresholds are reached.
Usage-Monitoring and reporting is performed over a single Gx session for the ESM/AA subscriber. In other words, there is only a single session for an ESM subscriber-host and corresponding AA subscriber. Via this single Gx session, Usage-Monitoring can be requested simultaneously in ESM context (PCC rule level, credit-category or IP-CAN session) and AA context (application based Usage-Monitoring).
For volume based usage monitoring in dual-homed system, see Gx Usage Monitoring in dual-homed systems.
ESM Usage-Monitoring - what is being monitored
In the ESM context, volume consumption (octets - 3GPP 23.203 §4.4) can be monitored on three levels:
per entire IP-CAN session
per credit-category
per PCC rule
Usage-Monitoring can be monitored simultaneously on all three levels.
An IP-CAN session on the node represents a subscriber-host whose service types are determined by the sla-profile instance. In per IP-CAN session volume monitoring, the aggregated queue or policer counters are reported per direction (in or out). This includes dynamic policers that are instantiated as a result of a Gx action; for example, rate-limiting.
The following configuration is necessary to allow per IP-CAN session level Usage-Monitoring to be enabled for sessions associated with the category map:
configure
subscriber-mgmt
category-map <category-map-name> [create]
gx-session-level-usage
If the sla-profile instance changes mid-session, the counters are reset.
One obvious difference between regular RADIUS accounting and Gx Usage-Monitoring is that in RADIUS accounting the cumulative byte number for sla-profile instance is presented in each report (interim-updates or stop acct messages), while in Usage-Monitoring this count is reset between the two reports (when the quota is reached, the usage report is triggered).
Per credit-category monitoring refers to volume monitoring of a single queue/policer or a set of queues/policers within the sla-profile instance. Each queue/policer (or set of queues/policers as a subset of the sla-profile instance) represents a service for which the Usage-Monitoring is required. Those queues/policers (services) are organized on the node in credit categories.
*A:7750>config>subscr-mgmt>cat-map# info
----------------------------------------------
activity-threshold 1
credit-exhaust-threshold 50
category "queue1" create
queue 1 ingress-egress
exit
category "queue3-5" create
queue 3 ingress-egress
queue 5 ingress-egress
exit
category "rest-queues" create
queue 2 egress-only
queue 4 egress-only
queue 6 egress-only
queue 7 egress-only
queue 8 egress-only
exit
----------------------------------------------
Each service category has a name that is used to reference the category in Usage-Monitoring and reporting.
The category-map (predefined on the node) that is used in Usage-Monitoring can be associated with the subscriber-host through the following methods (in the order of priority):
PCRF — Charging-Rule-Install AVP that references the category map in Charging-Rule-Name = cat-map:<cat-map-name>
LUDB
RADIUS
Python script
PCC rule Usage-Monitoring reports volume usage per flow or set of flows. PCC rule Usage-Monitoring is described in a separate section below.
Usage-Monitoring for the subscriber host can be configured on the node, but it is not active until it is turned on by the PCRF either via CCA-i, CCA-u or RAR.
Usage-Monitoring can be enabled per ingress or egress direction or as total count. However monitoring the total count and per direction count are mutually exclusive. For example, total Usage-Monitoring cannot be enabled simultaneously with ingress (or egress) Usage-Monitoring for the same monitoring entity (session or category).
AA Usage-Monitoring – what is being monitored
In AA, charging groups (CG), application groups (AG) and applications are monitored. See the 7450 ESS, 7750 SR, and VSR Multiservice ISA and ESA Guide for details.
Requesting Usage-Monitoring in ESM
Gx Usage-Monitoring is activated explicitly from the PCRF via CCA-I, CCA-U or RAR. It is triggered via the Usage-Monitoring-Information AVP along with the event-trigger = usage-report (33). The Usage-Monitoring-Information AVP contains the following AVPs:
Usage-Monitoring-Information::= < AVP Header: 1067 >
[ Monitoring-Key ]
0,2 [ Granted-Service-Unit ]
0,2 [ Used-Service-Unit ]
[ Usage-Monitoring-Level ]
[ Usage-Monitoring-Report ]
[ Usage-Monitoring-Support ]
There could be multiple instances of Usage-Monitoring-Information AVP present in a single CCA or RAR messages. For example, simultaneous Usage-Monitoring for IP-CAN session level, credit-category level or pcc rule level can be requested.
Usage-Monitoring-Level for IP-CAN session is set to SESSION_LEVEL (0)
Usage-Monitoring-Level for category-map is set to PCC_RULE_LEVEL (1)
Usage-Monitoring-Level for PCC rules is set to PCC_RULE_LEVEL (1)
Reporting accumulated usage
The node reports usage information to the PCRF under the following conditions:
when a usage threshold is reached
when all pcc rules associated with the monitoring are removed or deactivated
when Usage-Monitoring is explicitly disabled by PCRF
when a session is terminated
when requested by PCRF (on demand)
To report accumulated usage for a specific monitoring-key, the node sends a CCR with the Usage-Monitoring-Information AVP containing the accumulated usage information since the last report. For each of the enabled monitoring-keys, the Usage-Monitoring-Information AVP includes the Monitoring-Key AVP and the accumulated volume usage in the Used-Service-Unit AVP.
A usage report on the node can be triggered by reaching the usage threshold communicated to the node by the PCRF in the CCR-U message carrying accumulated usage for that monitoring entity along with the Event-Trigger AVP set to USAGE_REPORT.
In response to the CCR-U message, the PCRF communicates to the node via a CCA-u message whether the Usage-Monitoring should continue:
If the new thresholds for the currently monitored entity/levels are provided in Granted-Service-Units AVP, the Usage-Monitoring continues.
If the thresholds are not included in Granted-Service-Units AVP, the Usage-Monitoring stops.
Thresholds are incremental. For example, if the quota of 100 MB is submitted to the node, the usage should be reported when that quota is reached. At that point, the user can be granted another 100 MB. The new usage report on the node is triggered when another 100 MB are accumulated. Absence of the threshold for an entity in the CCA-u message is an indication that the Usage-Monitoring should stop.
When the PCRF informs the node that Usage-Monitoring should stop (by not including thresholds in CCA-u), the node does not report usage which has accumulated between sending the CCR and receiving the CCA.
Another possibility of usage reporting is on-demand. In this scenario, usage for one or more monitoring keys is reported whether the usage threshold has been reached. This is achieved by sending the node the Usage-Monitoring-Report AVP (within the Usage-Monitoring-Information AVP) set to USAGE-MONITORING_REPORT_REQUIRED. If the Monitoring-Key AVP is omitted in such a request, Usage-Monitoring for all enabled entities is reported to the PCRF.
If that the credit-category is removed from the subscriber host (the sla-profile instance referencing the category-map is changed for the subscriber host), the node reports the outstanding usage in a CCR-U message with the Event-Trigger set to USAGE_REPORT.
Disabling Usage-Monitoring
When the PCRF explicitly disables Usage-Monitoring on the node, the node reports the accumulated usage which has occurred while Usage-Monitoring was enabled.
To disable Usage-Monitoring for an entity, the PCRF sends the Usage-Monitoring-Information AVP referencing only the applicable monitoring entity with the Monitoring-Key AVP and the Usage-Monitoring-Support AVP set to USAGE_MONITORING_DISABLED.
When the PCRF disables Usage-Monitoring in a RAR or CCA command, the node sends new a CCR-U with the Event-Trigger AVP set to "USAGE_REPORT" to report the accumulated usage for the disabled Usage-Monitoring entities.
Usage-Monitoring for PCC rules
Each PCC rule for which Usage-Monitoring is required, contains Monitoring-Key AVP.
Charging-Rule-Definition ::= < AVP Header: 1003 >
{ Charging-Rule-Name }
*[ Flow-Information ]
[ Flow-Status ]
[ QoS-Information ]
[ Precedence ]
[ Monitoring-Key]
*[ AVP ]
Usage-Monitoring for PCC rules is implemented through a dynamic policer. The policer is instantiated at the time when the PCC rule with Monitoring-Key AVP is installed.
The same monitoring-key can be used in multiple PCC rules assuming that these rules are for the same direction. In other words, the charging rule is rejected if the same monitoring-key is used for ingress and egress.
Session termination
At IP-CAN session termination, the node sends the accumulated usage information for all entities for which Usage-Monitoring is enabled in the CCR-T.
Usage Monitoring when multiple subscriber hosts or sessions share an SLA profile instance
A Diameter Gx session from which Usage Monitoring is started controls the Usage Monitoring for the entire SLA profile instance. Only one Diameter Gx session can control the Usage Monitoring per SPI at a specific time. That is, Usage Monitoring can only be started from a single Gx session when multiple subscriber hosts or sessions share an SLA profile instance.
The session ID of the Diameter Gx session that controls the Usage Monitoring is displayed as the ‟Diameter Session Gx” field in the output of the following show command.
# show service active-subscribers credit-control [subscriber <sub-ident-string>]
===============================================================================
Active Subscribers
===============================================================================
-------------------------------------------------------------------------------
Subscriber sub-1 (sub-profile-1)
-------------------------------------------------------------------------------
-------------------------------------------------------------------------------
(1) SLA Profile Instance sap:1/1/2:10 - sla:sla-profile-1
-------------------------------------------------------------------------------
Category Map : catmap-1
Diameter Session Gx : bng1.domain.com;1490015297;7
Number of categories
static : 2
gx-session : 0
gx-pcc : 1
Category Name : cat-1
Ingress Queues : 1
Egress Queues : 1
Ingress Policers : (Not Specified)
Egress Policers : (Not Specified)
No monitoring
HTTP Rdr URL Override: (Not Specified)
Category Name : cat-2
Ingress Queues : 2
Egress Queues : 2
Ingress Policers : (Not Specified)
Egress Policers : (Not Specified)
No monitoring
HTTP Rdr URL Override: (Not Specified)
Category Name : fl_um1_up
Volume Used : 0 Volume Available : 100000
HTTP Rdr URL Override: (Not Specified)
-------------------------------------------------------------------------------
A Diameter Gx session stops being the controlling Gx session for Usage Monitoring of the SLA profile instance in the following situations:
The Gx session controlling Usage Monitoring for an SLA profile instance is terminated, for example, because the associated subscriber session is disconnected. A CCR-T is sent immediately reporting the usage.
All Usage Monitoring is disabled form the controlling Gx session. A CCR-U is sent immediately reporting the usage.
When the Usage Monitoring terminates, the usage of subscriber hosts or sessions sharing the SLA profile instance is no longer accounted for. Usage Monitoring can now be started from another Diameter Gx session, which then becomes the controlling Gx session for Usage Monitoring on the SLA profile instance.
Usage-Monitoring examples
For the description of the specific AVP, see the 7750 SR and VSR Gx AVPs Reference Guide.
IP-CAN session Usage-Monitoring
A category-map with gx-session-level-usage-monitoring must be associated with the subscriber host or session:
configure
subscriber-mgmt
category-map cat-map-1 create
gx-session-level-usage
PCRF in RAR sends the following AVPs (among all the other mandatory ones: session-id, and so on.)
Usage-Monitoring-Information
Monitoring-Key = ‟any-string”
Granted-Service-Unit
CC-Input-Octets = 1000000
CC-Output-Octets = 1000000
Usage-Monitoring-Level = session_level(0)
Event-Trigger = USAGE_REPORT
The node reports usage when the thresholds are reached some time later in the CCR-U. The usage is monitored internally on the node based on the current sla-profile instance.
Usage-Monitoring-Information
Monitoring-Key = ‟any-string”
Used-Service-Unit
CC-Input-Octets = 1000000
CC-Output-Octets = 1000000
The PCRF instructs the node to continue Usage-Monitoring with the new thresholds in the CCA-U:
Usage-Monitoring-Information
Monitoring-Key = ‟any-string”
Granted-Service-Unit
CC-Input-Octets = 1000000
CC-Output-Octets = 1000000
Usage-Monitoring-Level = session_level(0)
Category Usage-Monitoring
Assume that the following category-map is associated with the subscriber host:
*A:7750>config>subscr-mgmt>cat-map# info
----------------------------------------------
activity-threshold 1
credit-exhaust-threshold 50
category "queue1" create
queue 1 ingress-egress
exit
category "queue3-5" create
queue 3 ingress-egress
queue 5 ingress-egress
exit
category "rest-queues" create
queue 2 egress-only
queue 4 egress-only
queue 6 egress-only
queue 7 egress-only
queue 8 egress-only
exit
The PCRF sends the following AVPs in the RAR message (among all the other mandatory ones: session-id, and so on.)
Charging-Rule-Install
Charging-Rule-Name = Cat-Map:cat1 — cat-map rule install
Usage-Monitoring-Information
Monitoring-Key = ‟queue-1”
Granted-Service-Unit
CC-Input-Octets = 1000000
CC-Output-Octets = 1000000
Usage-Monitoring-Level = PCC_RULE_LEVEL (1)
Usage-Monitoring-Information
Monitoring-Key = ‟queue-3-5”
Granted-Service-Unit
CC-Input-Octets = 2000000
CC-Output-Octets = 2000000
Usage-Monitoring-Level = PCC_RULE_LEVEL (1)
Event-Trigger = USAGE_REPORT
The node reports usage when the thresholds are reached some time later in the CCR-U:
Usage-Monitoring-Information
Monitoring-Key = ‟queue-1”
Used-Service-Unit
CC-Input-Octets = 1000000
CC-Output-Octets = 1000000
Usage-Monitoring-Information
Monitoring-Key = ‟queue-3-5”
Used-Service-Unit
CC-Input-Octets = 2000000
CC-Output-Octets = 2000000
The PCRF instructs the node to continue Usage-Monitoring with the new thresholds in the CCA-U:
Usage-Monitoring-Information
Monitoring-Key = ‟queue-1”
Granted-Service-Unit
CC-Input-Octets = 1000000
CC-Output-Octets = 1000000
Usage-Monitoring-Level = PCC_RULE_LEVEL (1)
Usage-Monitoring-Information
Monitoring-Key = ‟queue-3-5”
Granted-Service-Unit
CC-Input-Octets = 2000000
CC-Output-Octets = 2000000
Usage-Monitoring-Level = PCC_RULE_LEVEL (1)
Event triggers
The PCRF may subscribe to an event trigger on the node. The PCRF subscribes to new event triggers or removes armed event triggers unsolicited at any time. When an event matching the event trigger occurs, the node reports the event to the PCRF. The event triggers that are required in procedures are unconditionally reported (for example, IP address allocation/de-allocation) from the node, while the PCRF may subscribe to the remaining events (for example Usage-Monitoring).
When sent from the PCRF to the node, the Event Trigger AVP indicates an event that triggers an action in the node. When sent from the node to the PCRF, the Event Trigger AVP indicates that the corresponding event has occurred. If no Event Trigger AVP is included in a CCA or RAR operation, any previously provisioned event trigger is still applicable.
The PCRF may remove all previously provided event triggers by providing the Event-Trigger AVP set to the value NO_EVENT_TRIGGERS. When an Event-Trigger AVP is provided with this value, no other Event-Trigger AVP is provided in the cca or rar command. Upon reception of an Event-Trigger AVP with this value, the node does not inform the PCRF of any event except for those events that are always reported and do not require provisioning from the PCRF.
When the PCRF subscribes to one or more event triggers by using the rar command, the node sends the corresponding currently applicable values to the PCRF in the RAA if available, and in this case, the Event-Trigger AVPs are not included.
For a list of the supported events on the node, see the 7750 SR and VSR Gx AVPs Reference Guide.
Subscriber verification
At any time, the PCRF can query the node for the presence of the subscriber-host via a RAR message.
The node responds with the following result-codes in RAA:
DIAMETER_SUCCES (2001) — subscriber active
DIAMETER_UNKNOWN_SESSION_ID (5002) — subscriber does not exist
Subscriber termination
The PCRF can request IP-CAN session termination on the node via two messages:
a RAR directive with the Session-Release-Cause AVP to the node
ASR
Upon the arrival of either of those messages, the node starts the IP-CAN session termination procedure (CCR-T with a corresponding Termination-Cause AVP is sent to the PCRF). This is described in the 3GPP 29.212 document, §4.5.9.
For a list of the supported Termination-Cause AVP values on the node, see the 7750 SR and VSR Gx AVPs Reference Guide.
Mobility support in Wi-Fi
When a Wi-Fi subscriber moves between the access points (APs), a CCR-U message is triggered on the node, carrying the Called-Station-Id AVP. The Called-Station-Id AVP carries the MAC IP address of the new AP. This functionality allows the PCRF to make a location-based policy decision.
This functionality is enabled via event trigger USER_LOCATION_CHANGE (13) [3GPP 29.212, §5.3.7] sent to the node by a PCRF in a CCA or RAR message.
The same event is reported back from the node to the PCRF in a CCR-U message when the user location changes.
Redundancy
Redundancy in Gx relies on the Diameter redundancy mechanisms described in Diameter redundancy.
Persistency and Origin-State-ID AVP
Persistency and Origin-State-ID AVP (RFC 6733, §8.6 and §8.16).
Persistency (saving the state of IPoE hosts on the compact flash) for Gx sessions is not supported. This means that, on reboot, the node restores the subscriber-hosts from the persistency but the Gx session awareness for the recovered hosts is lost. Any previously applied QoS or filter overrides are lost. However, subscriber-strings (subscriber-id, sub-profile, sla-profile, aa-profile) can be made persistent and can be preserved across reboots.
The Origin-State-Id (OSI) AVP is not stored in persistency. If the node reboots, the Origin-State-ID AVP is set to boot time (UTC).
The Origin-State-Id AVP is contained in the CER messages and application messages that are sent from the node to the PCRF/DRA. In the other direction, sent by the PCRF to the node, the OSI is ignored.
To restore a lost session after the reboot, the node initiates a CCR-I message for every host that has recovered from persistency. The CCR-I contains the new session-id and origin-state-id. Based on this CCR-I, it is expected that the PCRF returns the most current policy for the host.
Overload protection
Each SR OS node has a receiving queue per Gx application (ESM, UM, AA). Each queue can hold 10,000 messages. While the queue is in the overloaded state, the SR OS node replies to every new RAR message with the RAA (ACK) immediately followed by a CCR-U message containing the error-message with the description ‛Overload’. This can be considered as explicit signaling toward the PCRF notifying it of the condition on the SR OS node.
If the messages in the overwhelmed queue do not require sending an answer (in case that the overwhelmed queue contains CCA-I/U messages), the TCP window fills up, TCP ACKs are not sent and consequently this IS an implicit notification to the PCRF to slow down.
If the SR OS node receives a response from an overloaded PCRF (Result-Code = DIAMETER_TOO_BUSY), the SR OS node timeouts (tx-timer) the originally sent message. After the message is timed out, the configuration settings (on-failure) determines whether to trigger the peer-failover procedure or not (Peer-failover based on DIAMETER_TOO_BUSY Result-Code is recommended in RFC6733, §7.1.3.
Supported-Features AVP in Gx
The Supported-Features AVP is used to negotiate common supported features between PCEF and PCRF on a Gx session. The list of supported features on SR OS and their AVP format is described in the 7750 SR and VSR Gx AVPs Reference Guide.
Extended bandwidth 5G new radio feature
The Gx specification Release 15 (3GPP doc 29.212) and the Rx specification (3GPP doc 29.214) define extended AVPs for higher bandwidth values which are used to accommodate the need for higher speeds offered to the subscribers in 5G-enabled networks.
The difference between the non-extended and extended AVPs carrying the bandwidth value is in their units. The bandwidth unit for non-extended bandwidth AVPs is defined in b/s, while extended bandwidth AVPs are in kb/s, increasing the upper limit of the supported bandwidth by a scale of 1000. The value for QoS rates carried in those AVPs is a 32-bit value. In b/s units, this amounts to a maximum supported rate of 232 - 1 = 4 294 967 295 b/s or approximately 4.3 Gb/s. In kb/s, this equals over 4 Tb/s.
Support for the extended AVPs that can carry rate information in kb/s is enabled through the negotiated Extended Bandwidth 5G New Radio (Extended-BW-NR) feature (§5.4.1, 3GPP doc 29212). This feature is negotiated during Gx session establishment phase (CCR-I/CCA-I), between the PCEF and PCRF.
Extended-BW-NR feature is defined as:
Vendor-Id = 10415 (3GPP)
Feature-List-Id = 2
Feature-List = bit 7 (bitmask 00000000 00000000 00000000 10000000 to 0x80) with the AVP flag rule set to O (Optional)
Feature-List-Id = 2 is included in the CCR-I message only if the following conditions are met:
Application is on Gx.
Extended-BW-NR feature is enabled.
config subscr-mgmt diam-appl-plcy gx features extended-bwSupported-Features AVP is enabled.
config subscr-mgmt diam-appl-plcy gx include-avp supported-features
After the Extended-BW-NR feature is successfully negotiated, the following AVPs with units in kb/s are supported:
Extended-GBR-DL (AVP code 2850)
Extended-GBR-UL (AVP code 2851)
Extended-Max-Requested-BW-DL (AVP code 554)
Extended-Max-Requested-BW-UL (AVP code 555)
Extended-APN-AMBR-DL(AVP code 2848)
Extended-APN-AMBR-UL (AVP code 2849)
Transmission of extended bandwidth AVPs during Gx session initiation
The node initiating the Gx session (sending the CCR-I message) with support for extended bandwidth AVPs is not aware of whether the peering node supports extended bandwidth AVPs at the session initiation time. The extended-BW-NR feature flag is negotiated from both sides during session negotiation.
For this reason, if the bandwidth information carrying AVPs needs to be transmitted in the CCR-I message during session initiation and the bandwidth value is greater than 232 - 1, both AVPs, non-extended and extended, must be transmitted.
The non-extended bandwidth AVP is set to the value of 232 - 1 (maximum value).
The extended bandwidth AVP is set to the real bandwidth value.
If the receiving node supports extended AVPs, it processes the received extended bandwidth AVP with the real value; otherwise it processes the non-extended bandwidth AVP with the maximum value.
In SR OS, only APN-related bandwidth AVPs are transmitted during session negotiation and, therefore, their processing should adhere to the above described behavior.
Processing the extended bandwidth AVPs
When both AVP types (standard and extended) are received, while SR OS is supporting extended type (Extended-BW-NR), the extended AVP is processed and the standard one is ignored.
If the extended AVP type is not supported, that is if the Extended-BW-NR is not enabled, and a message with extended bandwidth AVPs is received, one of the following occurs:
If the M-bit in the extended type AVP is set, SR OS returns an error.
If the M-bit in the extended type AVP is not set, SR OS ignores the extended type and processes the standard type.
Diameter NASREQ application
The Diameter NASREQ application is used for Authentication, Authorization, and Accounting services in the Network Access Server (NAS) environment. The SR OS supports a stateless operation of NASREQ authentication and authorization, interacting with a NASREQ server that does not maintain session state.
Subscriber host or session authentication results in an AA-Request (AAR) message being sent to the Diameter NASREQ server. An Auth-Session-State AVP with value equal to 1 (No State Maintained) is included in the AAR to inform the server of the stateless mode. The server responds with an AA-Answer (AAA) message and must include the Auth-Session-State AVP with value equal to 1 (No State Maintained), together with the authorization AVPs.
Diameter NASREQ accounting is not supported.
Supported Diameter NASREQ messages lists the supported Diameter NASREQ messages. Vendor-specific AVPs are shown as: v-<vendor-id>-<AVP id>.
| Diameter message | Code | |
|---|---|---|
AAR |
AA-Request |
265 |
AAA |
AA-Answer |
265 |
Diameter NASREQ authentication is supported for IPoE hosts and sessions, PPPoE PTA PAP/CHAP authentication. Diameter NASREQ authentication is not supported for L2TP LAC/LNS.
NASREQ and RADIUS authentication cannot be configured simultaneously on a capture-sap, local-user-database, or group-interface. They have the same priority in the hierarchy of different sources (such as local user database, Gx, defaults, and so on) for obtaining the subscriber host or session authorization parameters.
Multi-chassis redundancy is supported via separate Diameter NASREQ peers on each redundant node. Each node of the multi-chassis redundancy pair has its own Diameter Identity (origin host or realm). The subscriber host or session is authenticated on the BNG where it is initially connected. Because of the stateless operation, there is no need to synchronize NASREQ session state. Alternatively, Diameter Multi-Chassis Redundancy can be deployed as described in Diameter redundancy.
The following rules apply for stateless NASREQ re-authentication:
For PPPoE sessions, there is no re-authentication.
For the IPoE host model, only forced re-authentication of DHCP renews when the circuit ID, interface ID, or remote ID has changed.
For the IPoE session model, re-authentication of DHCP renews when the ipoe-session min-auth-interval expired or forced re-authentication of DHCP renews when the circuit ID, interface ID, or remote ID has changed.
Stateless NASREQ authentication can be complemented with Diameter Gx policy management for policy control and mid-session changes. Diameter NASREQ and Gx applications are supported simultaneously on a single Diameter peer.
Sample Diameter NASREQ call flow shows a sample call flow for a subscriber using Diameter NASREQ for authentication and Diameter Gx for policy management.
AA-Answer message — accepted authorization AVPs lists the authorization AVPs that are accepted in a Diameter NASREQ AA-Answer message. Vendor-specific AVPs are shown in the table as: v-<vendor-id>-<AVP-id>.
| AVP ID | AVP name | Description |
|---|---|---|
1 |
User-Name |
Overrides the ‟Radius User-Name”. |
8 |
Framed-IP-Address |
The IPv4 address of the subscriber host. |
9 |
Framed-IP-Netmask |
The IPv4 netmask of the subscriber host. |
22 |
Framed-Route |
IPv4 managed route to be configured on the NAS for a routed subscriber host. |
25 |
Class |
Opaque value; echoed in RADIUS accounting. |
88 |
Framed-Pool |
The name of an IPv4 address pool. |
97 |
Framed-IPv6-Prefix |
SLAAC IPv6 prefix (wan-host). |
99 |
Framed-IPv6-Route |
IPv6 managed route to be configured on the NAS for a v6 routed subscriber host. |
100 |
Framed-IPv6-Pool |
The name of an IPv6 IA-NA address pool (wan-host). |
123 |
Delegated-IPv6-Prefix |
DHCPv6 IA-PD IPv6 prefix (pd-host). |
26.6527.9 |
Alc-Primary-Dns |
The IPv4 address of the primary DNS server. |
26.6527.10 |
Alc-Secondary-Dns |
The IPv4 address of the secondary DNS server. |
26.6527.11 |
Alc-Subsc-ID-Str |
Unique subscriber ID string. |
26.6527.12 |
Alc-Subsc-Prof-Str |
Subscriber profile string. |
26.6527.13 |
Alc-SLA-Prof-Str |
SLA profile string. |
26.6527.16 |
Alc-ANCP-Str |
ANCP string. |
26.6527.17 |
Alc-Retail-Serv-Id |
The service-id of the retailer to which this subscriber host belongs. |
26.6527.18 |
Alc-Default-Router |
The default gateway for the user (DHCP option [3] default-router for a DHCPv4 proxy) |
26.6527.28 |
Alc-Int-Dest-Id-Str |
Intermediate destination ID string. |
26.6527.29 |
Alc-Primary-Nbns |
The IPv4 address of the primary NetBios Name Server (NBNS). |
26.6527.30 |
Alc-Secondary-Nbns |
The IPv4 address of the secondary NetBios Name Server (NBNS). |
26.6527.31 |
Alc-MSAP-Serv-Id |
Service ID where the managed SAP is to be created. |
26.6527.32 |
Alc-MSAP-Policy |
Managed SAP policy used to create the MSAP. |
26.6527.33 |
Alc-MSAP-Interface |
Group-interface name where the managed SAP is to be created. |
26.6527.45 |
Alc-App-Prof-Str |
Application profile string. |
26.6527.99 |
Alc-Ipv6-Address |
DHCPv6 IA-NA IPv6 address (wan-host). |
26.6527.105 |
Alc-Ipv6-Primary-Dns |
The IPv6 address of the primary DNSv6 server. |
26.6527.106 |
Alc-Ipv6-Secondary-Dns |
The IPv6 address of the secondary DNSv6 server. |
26.6527.131 |
Alc-Delegated-Ipv6-Pool |
The name of an IPv6 IA-PD prefix pool (pd-host). |
26.6527.161 |
Alc-Delegated-Ipv6-Prefix-Length |
DHCPv6 IA-PD prefix length (pd-host). |
26.6527.174 |
Alc-Lease-Time |
The lease-time for proxy, in seconds. |
26.6527.181 |
Alc-SLAAC-IPv6-Pool |
The name of an IPv6 SLAAC prefix pool (wan-host). |
26.6527.1036 |
Alc-SPI-Sharing |
grouped AVP Sets the SLA Profile Instance (SPI) sharing method for this subscriber session to SPI sharing per group or default. |
26.6527.1037 |
Alc-SPI-Sharing-Type |
Must be included in an Alc-SPI-Sharing grouped AVP. Sets the SPI sharing method. value 0 = default as specified in the SLA profile with def-instance-sharing. The Alc-SPI-Sharing-Id AVP should not be present. value 2 = per group; the group identifier is specified with the Alc-SPI-Sharing-Id AV. |
26.6527.1038 |
Alc-SPI-Sharing-Id |
Must be included in an Alc-SPI-Sharing grouped AVP. Specifies the group identifier when SPI sharing is per group. |
Sample configuration steps
To specify the peers to reach the Diameter NASREQ server in a diameter peer policy:
configure
aaa
diameter-peer-policy "diameter-peer-policy-1" create
description "Diameter NASREQ peer policy"
applications nasreq
origin-host "bng@nokia.com"
origin-realm "nokia.com"
peer "peer-1" create
address 172.16.3.1
destination-realm "myDSCRealm.com"
no shutdown
exit
exit
To specify the Diameter NASREQ application specific parameters, such as AVP format and values, in a Diameter application policy:
configure
subscriber-mgmt
diameter-application-policy "diameter-nasreq-policy-1" create
description "Diameter NASREQ application policy"
application nasreq
diameter-peer-policy "diameter-peer-policy-1"
nasreq
user-name-format mac
include-avp
circuit-id
nas-port-id
nas-port-type
remote-id
exit
exit
exit
To apply the Diameter NASREQ application policy as Diameter authentication policy at a VPLS capture SAP, at an IES/VPRN group-interface or at a local user database:
configure
service
vpls 10 customer 1 create
sap 1/1/4:*.* capture-sap create
---snip---
diameter-auth-policy "diameter-nasreq-policy-1"
ies 1000 customer 1 create
subscriber-interface "sub-int-1" create
---snip---
group-interface "group-int-1-1" create
---snip---
diameter-auth-policy "diameter-nasreq-policy-1"
vprn 2000 customer 1 create
subscriber-interface "sub-int-1" create
---snip---
group-interface "group-int-1-1" create
---snip---
diameter-auth-policy "diameter-nasreq-policy-1"
configure
subscriber-mgmt
local-user-db "ludb-1" create
ipoe
host "ipoe-host-1" create
---snip---
diameter-auth-policy "diameter-nasreq-policy-1"
ppp
host "ppp-host-1" create
diameter-auth-policy "diameter-nasreq-policy-1"
If no AA-Answer message is received from the primary or secondary Diameter peer, then the host or session can be instantiated with the configured defaults. This is achieved by the following NASREQ application policy configuration:
configure
subscriber-mgmt
diameter-application-policy "diameter-nasreq-policy-1" create
on-failure failover enabled handling continue
To enable flexible integration with different NASREQ servers, a Python policy can be configured on the Diameter node. The Python script can interact on the AVPs present in the AA-Request and AA-Answer messages.
configure
python
python-policy "py-policy-nasreq-1" create
diameter aar direction egress script "NasreqAar"
diameter aaa direction ingress script "NasreqAaa"
configure
aaa
diameter-peer-policy "diameter-peer-policy-1" create
---snip---
python-policy "py-policy-nasreq-1"
Diameter redundancy
Diameter redundancy is supported on multiple levels:
High Availability (HA)
This refers to control plane redundancy with dual Control Plane Modules (CPMs) in a single chassis configuration. User sessions for Diameter applications are fully synchronized between CPMs.
However, the TCP connections with peers are not synchronized and after a CPM switchover, the TCP connections need to be re-established. Once the TCP peering connections are re-established, communication on the user level (NASREQ/Gx/Gy) is resumed without the loss of any user sessions.
peer and server failover
An existing user session can be rerouted to an alternate peer or server if the currently used peer or server fails.
multi-chassis redundancy
Diameter sessions are synchronized on the application level (through ESM if Gx and NASREQ) between two redundant SR nodes. Only one of those two nodes maintain a peering connection with the agent or server. As a result, the agent or server interacts with the redundant pair through a single peering connection.
Diameter peer and server failover
Peer and server failover mechanisms in the SR OS are concerned with retransmission of Diameter request messages and selection of alternative network paths toward the destinations during network failures. Both mechanisms (peer and server failover) assume that there are multiple peers, paths, and possibly redundant servers available in the network that can serve requests redundantly.
Peer failover involves the selection of the next best peer for a Diameter request message that have failed to be delivered over the current peer because of an explicit error notification or simply because of a peer failure. The selection of the next best peer in the SR node is based on forwarding and routing lookups performed in the Diameter base.
However, server failover is concerned with Diameter application servers (NASREQ, Gx, Gy) that may or may not be directly connected to an SR node. From an SR node viewpoint, the server failover procedure involves retransmission of request messages that are not successfully acknowledged by the Diameter application servers (NASREQ, Gx, Gy). Such unacknowledged request messages can be attributed to the loss of a specific Diameter application server and as a result be optionally retransmitted in a way that allows delivery of the retransmitted message to an alternate and possibly redundant Diameter application server.
Application answer messages do not rely on peer or server failover procedures because their forwarding is governed on a hop-by-hop basis (the exact reverse path of the request message).
Diameter peer failover
Each configured Diameter node in SR OS can support several peers that are simultaneously open. Only one of those peers is used to forward application messages for a specific user session. If there are multiple peers for the same realm, then the next-hop peer with the numerically lowest preference value is selected. If all peers have same preference for a specific realm, then the peer index is used to break the tie.
Peer failover is performed by a Diameter base protocol and is supported only for application request messages (for example, a peer failover does not apply to a CER message). Events that trigger peer failover can be categorized as:
explicit notifications from a peer through an error message, informing the recipient of the error message that the peer cannot deliver the request message to the destination
The receipt of the DIAMETER_UNABLE_TO_DELIVER (3002) or DIAMETER_TOO_BUSY (3004) protocol error messages triggers a retransmission of the original request messages to the next best peer. The retransmission bit (T-bit) in the retransmitted message is set. At the same time, the Tx timer (a configurable parameter in the SR OS) is started. Continued errored replies (3002/3004) for the retransmitted messages over newly selected peers continue to trigger the selection of the next best peer until:
a valid peer is found
all eligible peers are attempted without success
the Tx timer expires
If there are no viable peers available to deliver the request message (3002/3004 errors received from all attempted peers), or the Tx timer expires, the Diameter base notifies the application layer (NASREQ, Gx, Gy) which may invoke a server failover procedure (if enabled on the application level by configuration).
termination of an active peering connection
A peering connection can be explicitly closed by either side because of a Disconnect-Peer-Request message attributed to the timeout of the watchdog messages or any other error on the TCP transport level. Termination of an active peer triggers a search for the next best peer through forwarding/routing for all messages in the transmit queue toward that peer. The T-bit is set on all retransmitted messages.
If no eligible peers are left, the Diameter base notifies the application layer (NASREQ, Gx, Gy) which may invoke a server failover procedure (if enabled on the application level through configuration).
The destination-host AVP in the retransmitted messages because of the peer failover remains the same as in the original request message.
Diameter server failover
After the Diameter application is notified by the Diameter base that it is unable to deliver the message to the destination, the Diameter application can invoke a server failover procedure. A server failover procedure is enabled through configuration in the Diameter application policy (failure handling).
The server failover procedure on the Diameter application level provides the opportunity for one last retransmission of the original Diameter request messages, but this time with the destination-host AVP cleared in the retransmitted message. The T-bit in the retransmitted messages is set.
Clearing the destination-host AVP allows delivery of the application message to any server in the realm supporting that application. The retransmitted application request message is successfully processed on such server only if the applications servers are redundant and synchronized.
Diameter multi-chassis redundancy
Diameter multi-chassis redundancy offers a protection mechanism against network failures where the Diameter application sessions are synchronized and preserved after the chassis switchover.
Two redundant Diameter SR nodes appear as a single Diameter entity, while maintaining a single peering connection with each network peer (in other words, only one BNG in the pair forms a peering connection with a Diameter peer on the network side). With this configuration, each network node (agents and servers) maintains a single, unambiguous path toward the pair of redundant SR nodes. The SR node selected to maintain this peering connection is chosen through the Multi-Chassis Synchronization (MCS) protocol that runs between the two nodes. The decision about which node opens the peering connection is made on a per-peer basis, which means that the networks peering connections can be distributed over the pair of redundant SR nodes.
In a multi-chassis (or a dual-homed ) environment, an ESM subscriber is instantiated in both SR nodes. However, traffic for the subscriber is steered (in upstream and downstream direction) through the SR node with the SRRP in the Active state. Because the Diameter Base in the SR OS is not aware of the ESM subscribers and their (SRRP) states, an inter-peering Diameter connection is mandatory between the two redundant SR nodes. This peering connection is required to relay Diameter messages between the two redundant SR nodes if the SRRP is active on one node while the Diameter peering connection is open on the other node.
The concept of Diameter dual-homing is shown in Multi-chassis redundancy in DRA environment and Multi-chassis redundancy with directly connected servers.
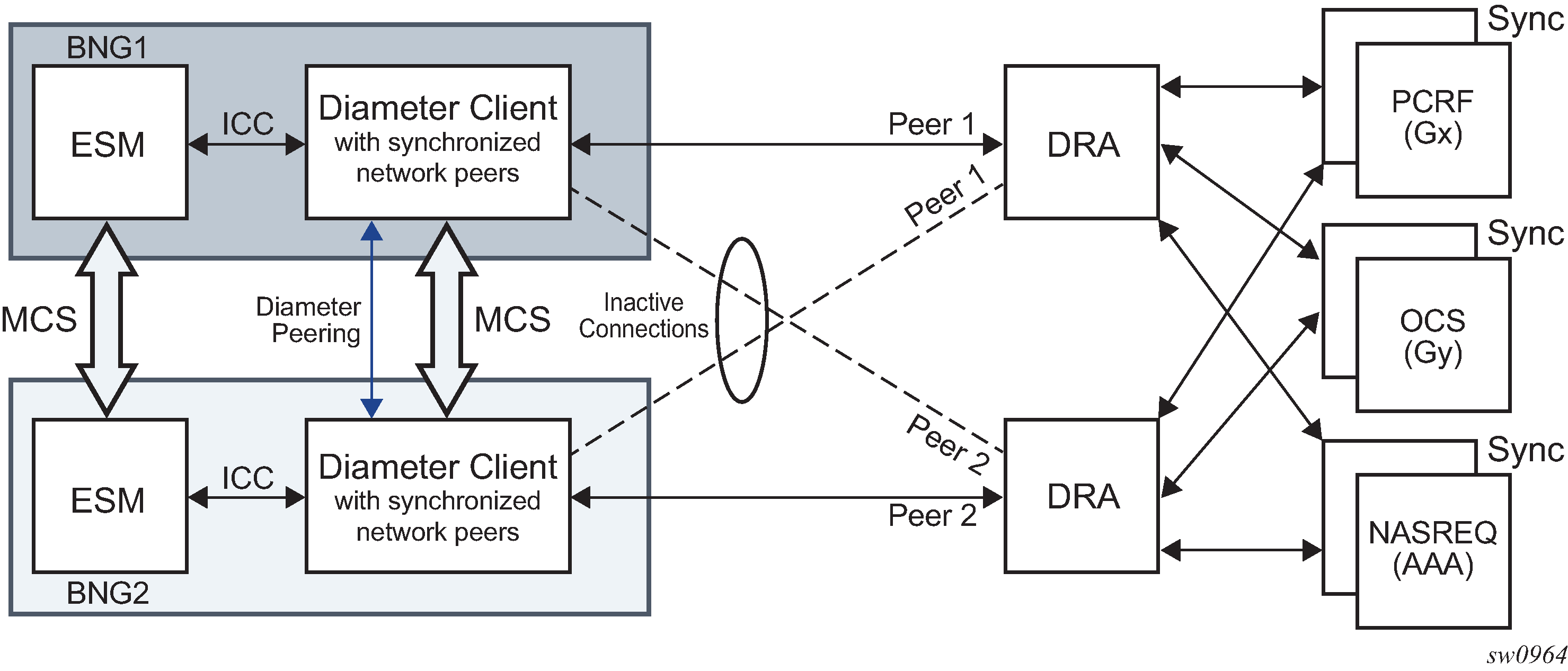
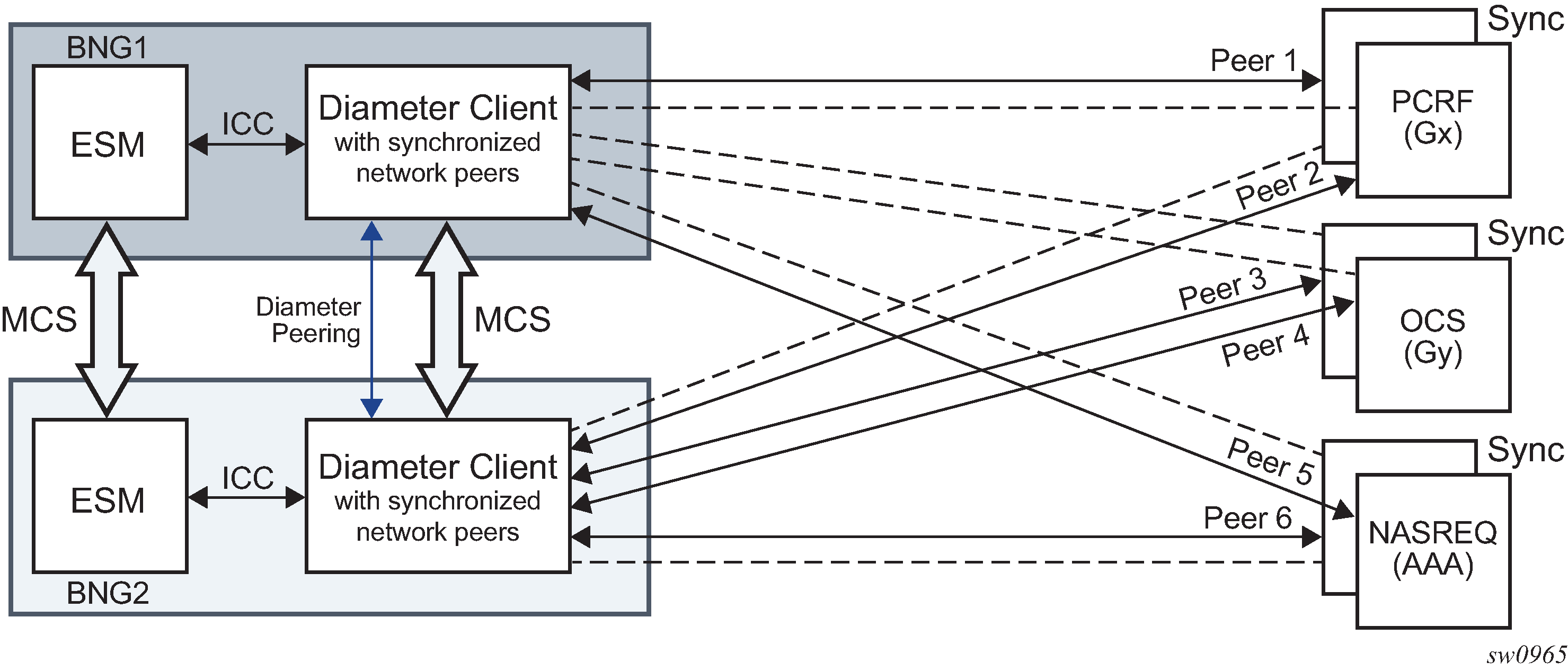
Single Diameter Identity (DI) per a pair of redundant diameter nodes
Both SR nodes in the redundant pair are configured with the same Diameter Identity (DI), the origin host and origin realm. This configuration is performed per Diameter node configuration context, and there can be multiple Diameter node configuration contexts per an SR node or a pair of redundant SR nodes.
Single peering connection per redundant pair
Only one node in the SR redundant pair is instructed to open a peering connection, while the other node keeps the connection to the same peer closed (inactive). A single peering connection from a pair of redundant SR nodes to the same Diameter network peer is essential for unambiguous transport of Diameter messages in an environment with:
a single realm spanning multiple redundant pairs
a pair of redundant SR nodes sharing the same Diameter Identity (DI)
If the open peering connection fails (such as a node reboot or a peer is closed or unavailable), the redundant SR node, upon detection of this event, immediately starts initiating the connection to the same peer.
Inter-peering connection
Inter-peering Diameter connection between the two redundant SR nodes is required to transport Diameter messages directly between them if the SR node with an active SRRP instance does not have a direct Diameter path to the agent or server. Instead, the messages must be sent over the inter-peering connection to the other SR node which is directly connected to the Diameter agent or server.
The synchronization mechanism between the two redundant nodes ensures that only one SR node initiates this inter-peer connection. The other (peering) SR node accepts this request but does not initiate it.
The watchdog timer for this peering connection should be set to the lowest configurable value.
Inter-peer as a default peer
If the Diameter request message is originated from a node (SRRP Active) that does not have direct connections to the agent or relevant Diameter servers, the request message must be sent to the inter peer which does have such connections. This is accomplished by designating the inter-peer as a default peer. A default peer is a peer used for all Diameter traffic that does not have an exact match for the destination-realm and application in the realm routing table. A default-peer is application (NASREQ/Gx/Gy) unaware. For routing loop avoidance information, see Diameter routing loop avoidance.
Because both redundant SR nodes have their default peers pointing to each other, a mechanism for routing loop prevention must be in place. This means that a Diameter message received from a peer, is never transmitted in the reverse direction back to this same peer (in other words, looped around).
Handling RARs
In a Diameter multi-chassis configuration, the SR node with SRRP in an Active state (where the subscriber is active) and the SR node with open relevant Diameter peering connections may not be co-located. As a result, it is possible that the RAR message is received on the SR node where the Diameter application (for example, Gx) is not active. In this case, the RAR message is re-routed from the default peer to the peering SR node where the SRRP is in the Active state, and the Diameter application is active.
If the default peer is not available, the RAR message is dropped and a DIAMETER_UNABLE_TO_DELIVER error message is sent back to the peer from which the RAR message was received.
Handling of the Route-Record AVP
An SR inserts the Route-Record AVP to all CCR messages that are passed through it. The Route-Record AVP is not added on the SR originating the message, but instead only on the transit SR, where messages are received from the inter-peer and passed to the network, or when they are received from the network and passed to the inter-peer.
The value inserted in the Route-Record AVP is the origin-host of the peer from which the message is received.
Checks that are performed on the Route-Record AVP are the following:
If the peer’s identity in any of the Route-Record AVPs in the received request messages matches the local host identity, then this means that a routing loop is detected (Diameter routing loop detection). The SR answers with the Result-Code AVP set to DIAMETER_LOOP_DETECTED.
Route-Record AVPs are examined in received request messages to determine whether the message should or should not be forwarded. Only the next-hop (peers) candidates for the route that are not in any of the Route-Record AVPs of the received message, are allowed to be used. If there are no such next-hop candidates, an error message with the Result-Code AVP set to DIAMETER_UNABLE_TO_DELIVER must be sent back to the peer.
Scenarios in which an SR can receive a request message are:
RAR from the inter-peer
RAR from a network peer
CCR-I/U/T message received from the inter-peer
CCR-I/U/T message is received from a network peer
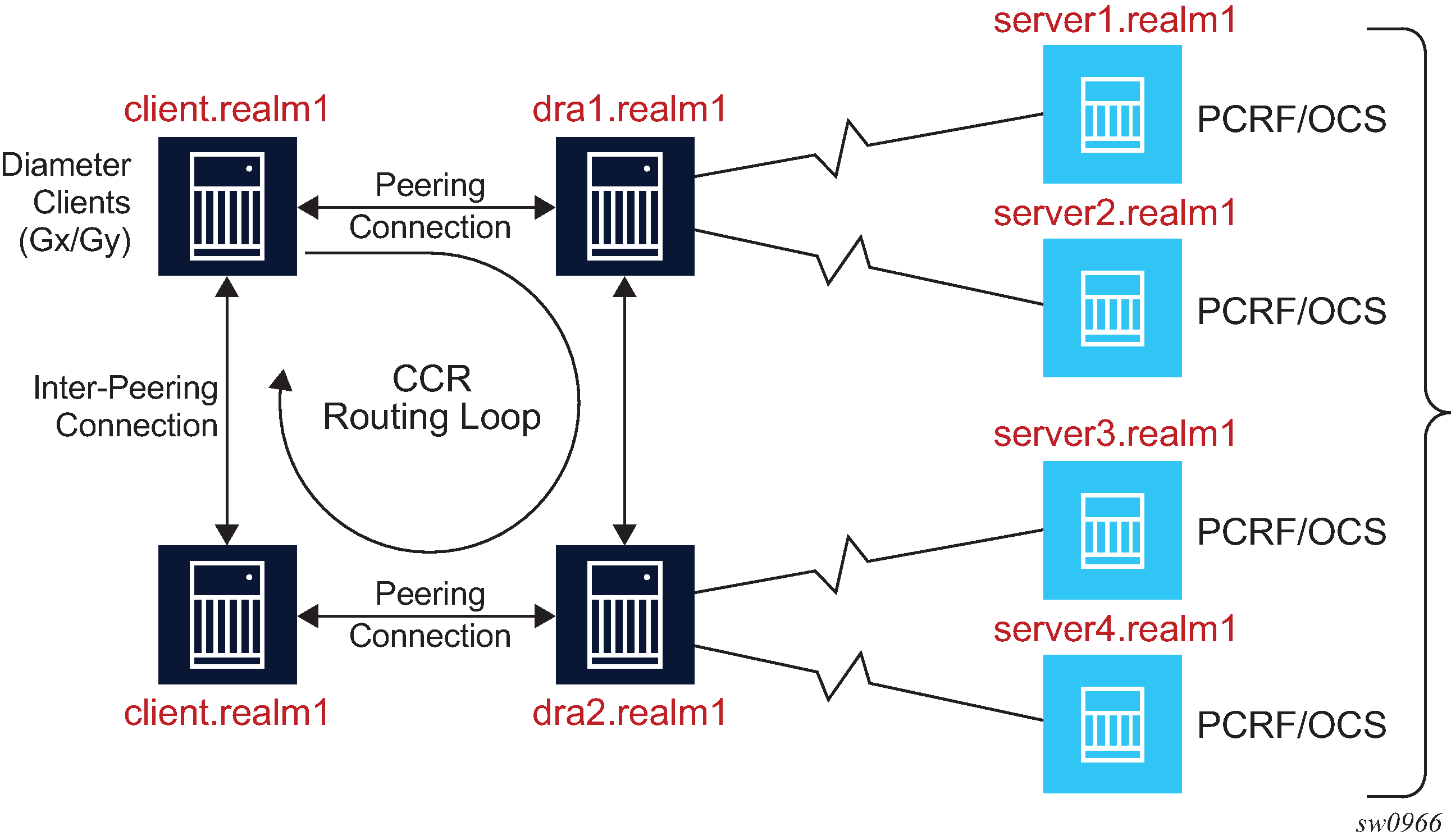
SRRP switchover
SRRP activity and Diameter peer activity are independent of each other, and consequently, an SRRP switchover that is because of an access link or path failure does not cause Diameter peers to switchover. However, a SRRP switchover can trigger a Diameter application to notify the application server (for example, PCRF) of this event. This is performed through the AN-GW-IP AVP which is reported in CCR-U message sent to the PCRF. AN-GW-IP AVP carries the IP address of the newly active SRRP SR node, where the application session is now active. This functionality is enabled on the application level by arming the Diameter client on SR node with the event-trigger ID 13 (USER_LOCATION_CHANGE) from the PCRF.
Unsupported failures
The following two scenarios are not protected by the Diameter multi-chassis redundancy:
Loss of the intra-peering (MCS) link. This scenario causes a split-brain scenario where both nodes act as stand-alone nodes and they both try to open peering connections to the Diameter servers.
SRRP Active-Active state, where the SRRP messaging path between the two SR nodes is broken and consequently, both SR nodes own the Diameter application session (for example, Gx session).
These two scenarios do not meet the minimum requirements (MCS and SRRP must be operational) for successful Diameter multi-chassis operation, and therefore, are not supported. However, after the valid control channel states are restored (intra-chassis link is restored or SRRP states become stable, Active or Standby), the expectation is that the redundant system brings itself up to a valid protecting state.
Peer preference in multi-chassis setup
Peer preference is a configuration parameter used to break the tie between multiple peers in the realm routing table leading to the same Diameter realm. Peer preference is a local configuration parameter and it does not transfer across the chassis. The peer with the numerically lowest preference value is preferred. As a result, peer preference may lose its meaning in the multi-chassis environment because the peers leading to the same realm may be distributed across both chassis.
The scenario can be clarified by the following example:
Peer 1 and Peer 2 are redundant peers and Peer 1 has a lower preference than Peer 2 on both SR nodes.
Because each SR node in Distributed peer connections has peering connection open to its own PCRF, the local peer preference loses its meaning. Peer 1 is used on BNG1 and Peer 2 is used on BNG2, although it may be needed that Peer 1 is always preferred over Peer 2.
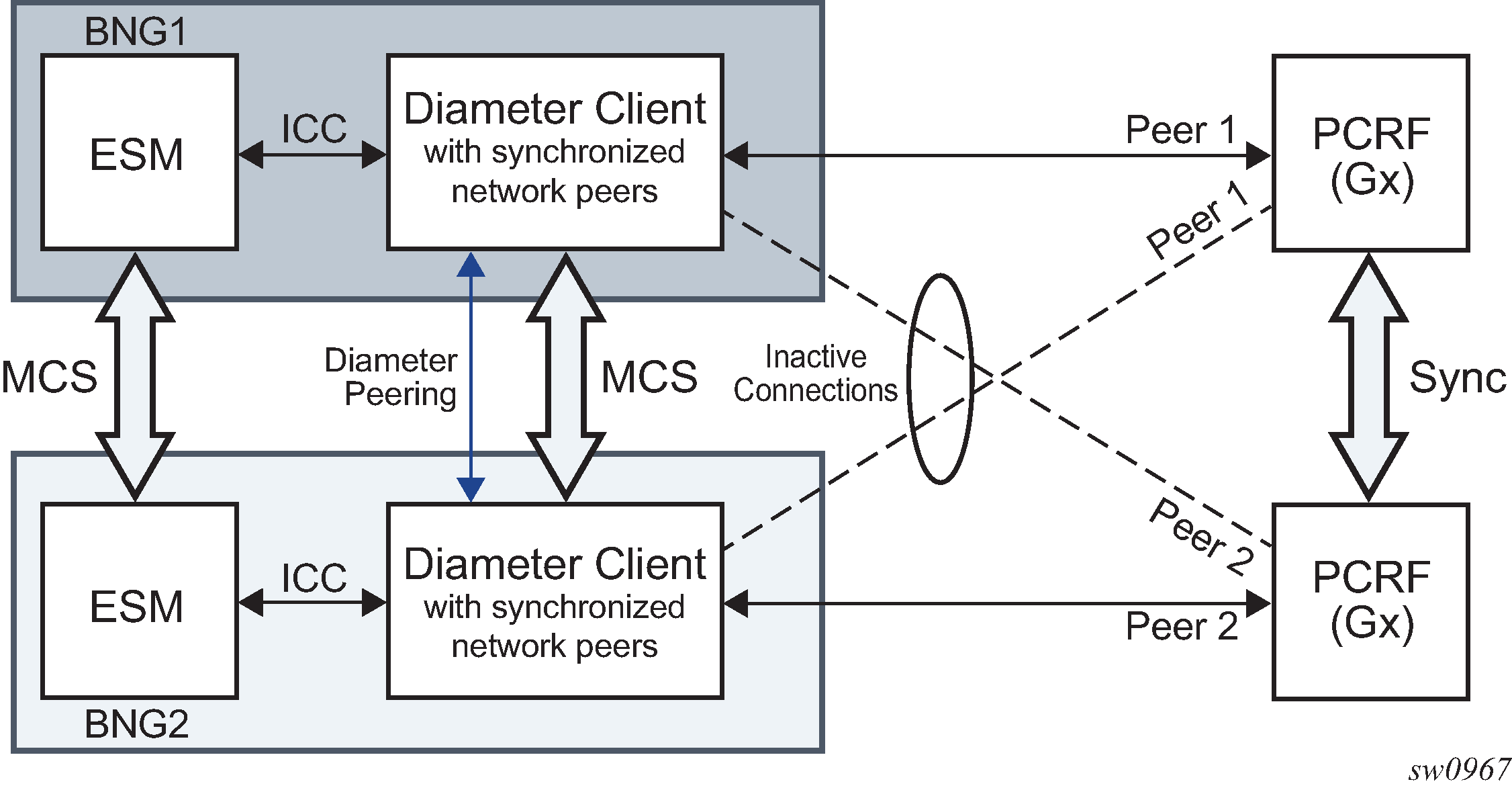
If the peering connections are colocated (Collocated peer connections), the preference parameter regains its meaning. In this case, Peer 1 is always selected over Peer 2.
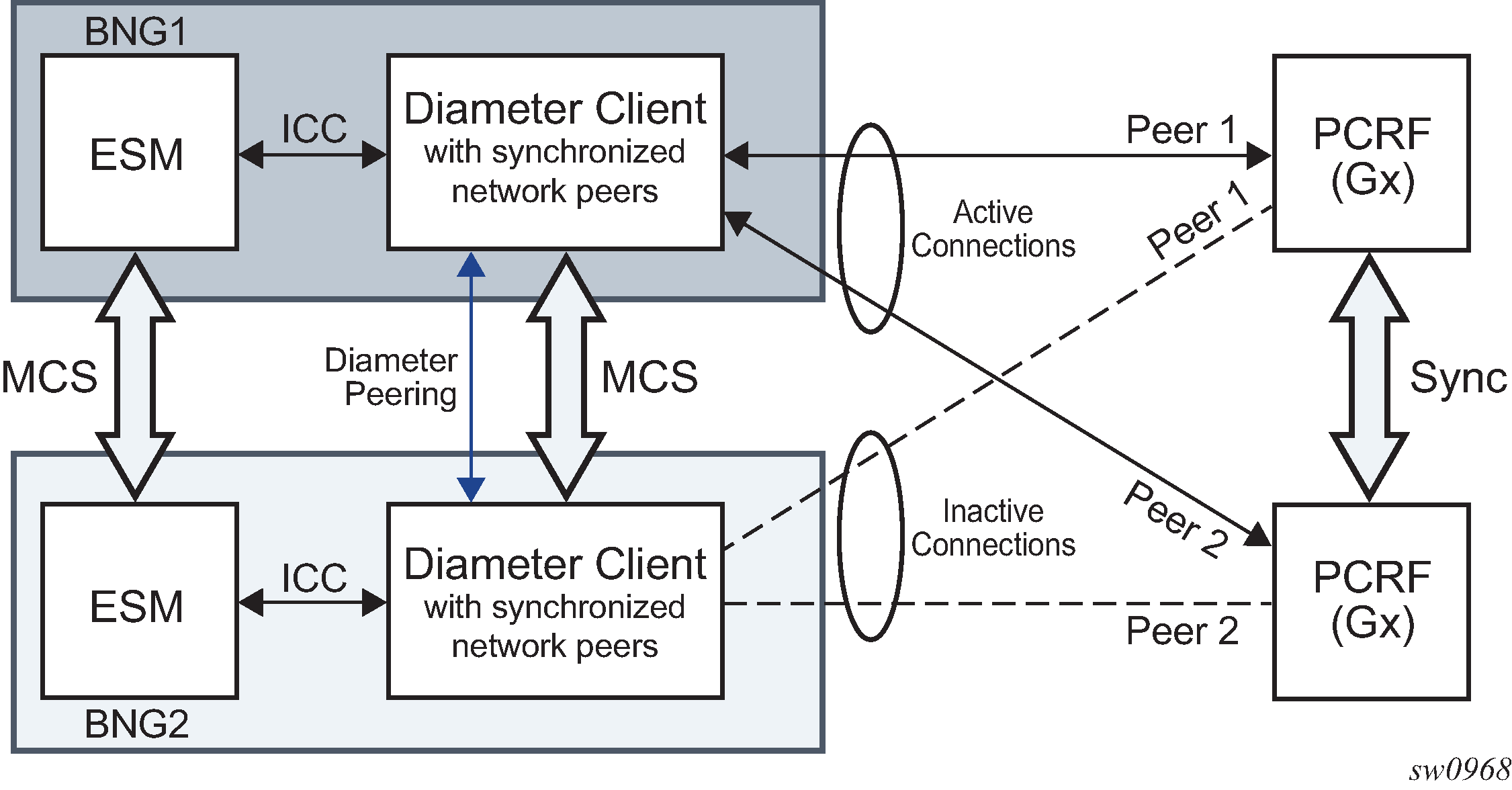
Gx Usage Monitoring in dual-homed systems
Gx Usage Monitoring (UM) relies on the Credit Control Instance (CCI) for the collection of byte counters. CCI is instantiated through a credit-category map (monitoring-key) and associated with the SLA profile instance (SPI) of the DHCP/PPPoE session. The bytes collected through CCI are periodically synchronized between the nodes. The synchronization of UM is automatically enabled for Gx/UM enabled subscribers in a dual-homed environment.
The direction of synchronization depends on the activity of a Gx sessions in ESM because UM is an integral part of Gx. Gx sessions in a dual-homed ESM environment follow the active or standby models, where the activity of Gx sessions can be distributed between the nodes, according to SRRP activity. SRRP as a basis of dual-homing in subscriber management is used to determine which node owns a Gx session. A Gx session maps to a IPoE/PPPoE session in a 1:1 manner. If multiple IPoE/PPPoE sessions share the same SLA profile instance (SPI), and with this the CCI, then the corresponding Gx sessions all share the same CCI. A Gx session under the SRRP instance in a master state is used to communicate with the PCRF servers, while the mirrored Gx session on the peering node with SRRP instance in the standby mode remains silent. In this context, Gx session can be considered as active or standby.
Although it is possible to have multiple Gx sessions per SPI, only one of the sessions can control UM at any time. In terms of UM, this Gx session can be referred to as a UM controlling Gx session. This is possible when there are multiple hosts or IPoE/PPPoE sessions per SPI, and each of them is associated with its own Gx session. Only when the UM is explicitly stopped via a session (RAR/CCA, or the UM controlling Gx session is terminated via CCR-T) can another Gx session take control over UM.
The initial quota for UM sent by the PCRF is always received by the active Gx session and the quota is periodically synchronized to the standby Gx session on the peering node. This is achieved with cooperation between ESM and Diameter in a dual-homed environment. When the quota is exhausted, only the active Gx session reports the exhausted quota to the server.
Gx communication with the DRA/PCRF is performed through Diameter Base and this functionality is described in Diameter base and Diameter multi-chassis redundancy.
Synchronization frequency
Synchronization frequency is configurable per diameter application policy and the minimum configurable value is five minutes. This interval is maintained per each individual Gx session associated with the relevant diameter application policy.
The configured synchronization interval governs the accuracy of UM in dual-homed systems where the switchover is caused by the sudden unavailability (crash, reboot, and so on) of the node on which a UM session is active.
Online configuration changes (while UM sessions are active) for synchronization interval are activated only for the new sessions that are established after the configuration is made.
Switchover triggered synchronization
A switchover, other than the one caused by a node loss, triggers an immediate synchronization of counters. This ensures better UM accuracy by synchronizing data up to the moment of the switchover, instead of up to the moment of the last periodic sync interval.
What is being synchronized
Credit quotas as received by the PCRF and UM counters are synchronized between dual homed nodes. However, the configuration is not synchronized or checked at the time of synchronization. This means that it is left to the operator to ensure that the UM configuration (for example, credit categories) is identical on both nodes.
Loss of inter-chassis link
Inter-chassis link (ICL) is used to transfer synchronization information. Any logical connectivity serves this purpose, but it is crucial that this link is redundant. The loss of this link is a faulty scenario where the control channel for UM synchronization between the two chassis is broken. In this case, both nodes remain operational in a stand-alone mode and they continue to forward traffic. After the ICL is recovered, the UM counters are re-synchronized from the active to standby node automatically within the configured synchronization interval.
Master-to-Master SRRP scenario
In a Master-to-Master scenario, the SRRP connectivity between the two nodes is lost and consequently both nodes transition into a master SRRP state. This means that in the downstream direction both nodes forward traffic (this depends on how the traffic is attracted on each node via routing). Similarly, in the upstream direction both nodes forward traffic, but the node selection is guided by the learning of VMAC (SRRP MAC) in the Layer 2 access network (the last received downstream packet determines the upstream path). The Master-to-Master state is, from the operational standpoint, an invalid and erroneous state where both nodes are sending synchronization messages to each other and at the same time they are rejecting them. The system recovers within one synchronization periodic interval after the valid SRRP state combination is restored (master/backup).
Usage counter collection with no credit grants received
Collecting usage counters without quota can occur when the original quota is exhausted and reported by the BNG, but the new quota is not given by Policy and Rule Charging Function (PCRF) while UM is still active (not explicitly disabled).
In this case, BNG continues counting. When the new quota is submitted, all consumed bytes up to this point are counted toward the new quota. For example, if 200 units are consumed since the last report, and then a new quota of 1000 units is issued, the 200 already consumed units are counted toward the new quota. For this reason, operators must avoid enabling UM without the quota. This can be achieved by:
disabling UM if it is not needed
submit a new quota by PCRF on every quota report exhaustion generated by the BNG
ISSU
The correct sequence of events during the (M)ISSU from a software release which does not support UM MCS (old release), to a software release that does support UM MCS (new release) is the following:
The old release has ESM and Gx synchronization enabled but the UM does not. This is because UM synchronization is not supported on older releases.
(M)ISSU is performed
The new software release boots up with UM still disabled. UM must be enabled via Gx directives send from PCRF.
The UM can now be enabled in the new release. When enabled, synchronization automatically takes place.
Diameter debugging
This section describes the debugging capabilities for troubleshooting a Diameter or Diameter application problem.
Debugging should be as specific as possible and limited to relevant messages only. Enabling detailed debugging for all diameter messages on a production node generates a flood of information and is not very helpful in isolating the problem; it can, however, be a valid scenario for lab testing.
Diameter debug output can be limited to:
messages to a specified origin or destination realm
Messages that have no origin or destination realm AVP to match against are also shown in this configuration.
debug diameter dest-realm dest.com origin-realm origin.com exit exitmessages of specified message types
debug diameter message-type ccr cca exit exitmessages sent or received on peers belonging to a specific Diameter peer policy. Up to eight diameter peer policies can be specified
debug diameter diameter-peer-policy "diameter-peer-policy-1" exit diameter-peer-policy "diameter-peer-policy-2" exit exit exitmessages sent or received on a specific Diameter peer
debug
diameter
diameter-peer "peer-1"
exit
exit
Only messages that match all specified criteria are shown in the debug output.
The diameter debug detail-level command can be set to
- low (default)
- displays the Diameter message header
- medium
- displays the Diameter message header and AVPs
- high
- displays the Diameter message header, AVPs, and a packet hex dump
debug
diameter
detail-level medium
exit
exit
For a per-diameter peer policy additional criteria can be specified to further restrict the debug output to:
messages sent or received on a specific Diameter peer
overrides the peer configuration at the debug diameter level
debug diameter diameter-peer-policy "diameter-peer-policy-1" diameter-peer "peer-1" exit exit exitmessages of specified message types
overrides the message type at the debug diameter level
debug diameter diameter-peer-policy "diameter-peer-policy-1" message-type ccr cca rar raa exit exit exitmessages from a diameter session where the diameter session is learned from Diameter application messages matching specified AVP values (avp-match criteria)
debug diameter diameter-peer-policy "diameter-peer-policy-1" avp-match 1 avp 443.444 octetstring ascii value "1/1/1:10.20@bng1" message-type ccr no shutdown exit exit exit exit
Only messages sent or received on a peer that belongs to the diameter peer policy and matches all specified criteria are shown in the debug output.
To restrict debug output to messages from a diameter session, AVP matching with session learning is required. AVP 263 Session-Id is the only Diameter AVP that is present in all messages of a Diameter session and is dynamically assigned when the Diameter session is initiated. The session ID is not useful to specify as criteria in debugging because its value is unknown upfront. Instead, using AVP matching, it is possible to learn the session ID from Diameter application messages (NASREQ, Gx, and Gy) matching a message type and one or multiple AVP values. All subsequent Diameter application messages that belong to the learned session ID are then included in the debug output, as shown in the following example:
debug
diameter
detail-level medium
diameter-peer-policy "diam-pol-1"
avp-match 1
avp 25 octetstring ascii value "trace-me"
avp 10415-1005 octetstring ascii value "sub-id:vip-1"
message-type cca
no shutdown
exit
avp-match 2
avp 443.444 octetstring ascii value "1/1/1:10.20@bng1"
message-type ccr
no shutdown
exit
message-type ccr cca rar raa
exit
message-type all
exit
exit
In this configuration, the debug output for Diameter messages is restricted to messages of type ccr, cca, rar, or raa that are sent or received on diameter peer policy ‟diam-pol-1” and that belong to Diameter sessions for which:
a CCA message is received with Class AVP = ‟trace-me” and 3GPP Charging-Rule-Name AVP = ‟sub-id:vip-1”. The session ID is learned from the message. All subsequent ccr, cca, rar, and raa messages with the same session ID are also shown until a relearning occurs: a new CCA message received matching the AVP criteria specified for this AVP match ID. If still available in the system, the corresponding CCR message is also shown.
a CCR message is received with subscription-id-data AVP = "1/1/1:10.20@bng1" (grouped within the subscription-id AVP). Session ID learning occurs for this AVP match ID and all subsequent ccr, cca, rar, and raa messages with the same session ID are shown as described above.
The rules for Diameter debug AVP matching are summarized below:
Diameter debug AVP match criteria are specified in an avp-match id command. Up to five AVP match IDs can be specified per diameter peer policy. For each AVP match ID, a unique Session ID is learned and the corresponding messages are logged in debug: OR function for all debug diameter diameter-peer-policy policy avp-match id commands.
For each AVP match ID, a message-type and at least one AVP ID criteria must be specified. Up to five AVP ID criteria can be specified per each AVP match ID. Session ID learning or relearning occurs when all specified AVP ID criteria are matched in any of the specified application message types: AND function for all debug diameter diameter-peer-policy policy avp-match id avp avp-id commands.
For each AVP in an AVP match, the AVP ID, type, and value should be specified:
avp-id is specified as [vendor-id-]avp-code[.avp-id] with nesting up to five levels deep. For example: ‟443.444” to indicate Subscription-Id. Subscription-Id-Data and ‟456.10415-871” to indicate Multiple-Services-Credit-Control.Quota-Holding-Time.
type corresponds to the type as defined in the standards or as defined in the Diameter Interface Specification document for vendor-specific AVPs. The following types are supported: octetstring (used for utf8string, octetstring and diameterid), integer32, integer64, unsigned32, unsigned64, and address. Any AVP can be specified as an octetstring in hex format.
value is the AVP value to be matched. Optionally the format in which the value is specified can be configured as ASCII or hex. A hex string is specified as "0xaabbcc…" (starting with "0x" followed by the hex nibbles).
The message type specified in an avp-match id command is only used as match criteria and does not limit the debug output:
debug diameter diameter-peer-policy "diam-pol-1" avp-match 1 avp 443.444 octetstring ascii value "1/1/1:10.20@bng1" message-type ccr no shutdown exit message-type ccr cca rar raa exit exit exitIn this configuration, the session ID is learned only from CCR messages with subscription-id data AVP = ‟1/1/1:10.20@bng1”. When the session ID is learned, all CCR, CCA, RAR and RAA messages from that session ID are shown in the debug output.
When at least one AVP match ID is configured with the debug diameter diameter-peer-policy policy avp-match id no shutdown command, only the messages for learned session IDs for the specified diameter peer policy are shown in the debug output. An AVP match ID in shutdown state is not active (session ID learning disabled and no debug messages are logged for this AVP match ID).
If the session ID learning happens based on a match in an Answer message, then the corresponding Request message is also logged in debug only if it was still available in the system.
Relearning occurs when a message from a session ID different from the learned session ID matches all specified AVP ID criteria in any of the specified application message types. The learned session ID for the AVP match ID is overwritten.
Messages from a learned session ID are no longer matched against the AVP match criteria. The same session ID is learned only once.
Learning or relearning events are reported in the debug output:
174 2016/01/21 15:31:02.63 UTC MINOR: DEBUG #2001 Base DIAMETER "DIAMETER: Session-Id learning diameter-peer-policy diameter-peer-policy-1 avp-match 1 learned Session-Id bng.origin.com;1453294062;8 (replacing Session-Id bng.origin.com;1453294062;7)"The learned session ID is deleted when the corresponding AVP match ID debug command is deleted or shutdown.
The tools>dump>debug>diam>avp-match-learned-session-id command displays the current learned Diameter session IDs for each Diameter application policy AVP match ID.