BGP
BGP overview
Border Gateway Protocol (BGP) is an inter-Autonomous System routing protocol. An Autonomous System (AS) is a set of routers managed and controlled by a common technical administration. BGP-speaking routers establish BGP sessions with other BGP-speaking routers and use these sessions to exchange BGP routes. A BGP route provides information about a network path that can reach an IP prefix or other type of destination. The path information in a BGP route includes the list of ASes that must be traversed to reach the route source; this allows inter-AS routing loops to be detected and avoided. Other path attributes that may be associated with a BGP route include the Local Preference, Origin, Next-Hop, Multi-Exit Discriminator (MED) and Communities. These path attributes can be used to implement complex routing policies.
The primary use of BGP was originally Internet IPv4 routing but multi-protocol extensions to BGP have greatly expanded its applicability. Now BGP is used for many purposes, including:
Internet IPv6 routing
inter-domain multicast support
L3 VPN signaling (unicast and multicast)
L2 VPN signaling (BGP auto-discovery for LDP-VPLS, BGP-VPLS, BGP-VPWS, multi-segment pseudowire routing, EVPN)
setup of inter-AS MPLS LSPs
distribution of flow specification rules (filters/ACLs)
The next sections provide information about BGP sessions, BGP network design, BGP messages and BGP path attributes.
BGP sessions
A BGP session is a TCP connection formed between two BGP routers over which BGP messages are exchanged. The three types of BGP sessions are as follows:
-
internal BGP (IBGP)
-
external BGP (EBGP)
-
confederation external BGP (confed-EBGP)
An IBGP session is formed when the two BGP routers belong to the same Autonomous System (AS). Routes received from an IBGP peer are not advertised to other IBGP peers unless the router is a route reflector. The two routers that form an IBGP session are usually not directly connected. BGP sessions shows an example of two Autonomous Systems that use BGP to exchange routes. In this example, the router ALA-A forms IBGP sessions with ALA-B and ALA-C.
An EBGP session is formed when the two BGP routers belong to different Autonomous Systems. Routes received from an EBGP peer can be advertised to any other peer. The two routers that form an EBGP session are often directly connected but multi-hop EBGP sessions are also possible. When a route is advertised to an EBGP peer the Autonomous System numbers of the advertising router are added to the AS Path attribute. In the example of BGP sessions, the router ALA-A forms an EBGP session with ALA-D.
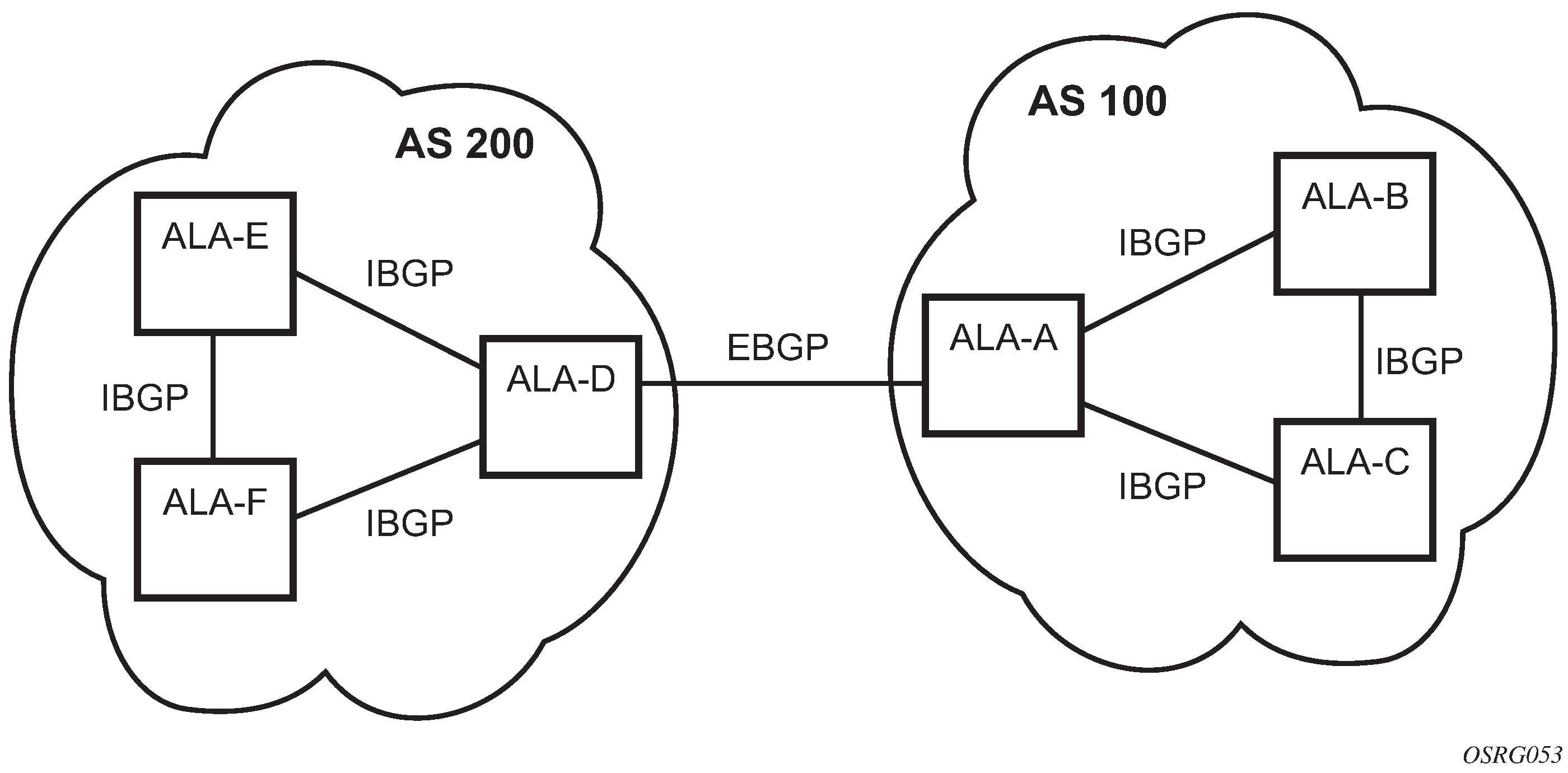
A confederation EBGP session is formed when the two BGP routers belong to different member Autonomous Systems of the same confederation. See BGP confederations for more information about BGP confederations.
SR OS supports both statically configured and dynamic (unconfigured) BGP sessions. Dynamic sessions are allowed when they are detected by either of the following mechanisms:
-
The source IP address of an incoming BGP TCP connection matches an IP prefix associated with dynamic BGP sessions. Use the following command to configure this prefix.
configure router bgp group dynamic-neighbor match prefix -
An ICMPv6 router advertisement message is received from a potential BGP router on an interface listed as a dynamic-neighbor interface. Use the following command to configure an interface for dynamic neighbors.
configure router bgp group dynamic-neighbor interface
Use the following command to configure a statically configured BGP session:
-
MD-CLI
configure router bgp neighbor -
classic CLI
configure router bgp group neighbor
This command accepts either an IPv4 or IPv6 address, which allows the session transport to be IPv4 or IPv6. By default, the router is the active side of TCP connections to statically configured remote peers, meaning that as soon as a session leaves the Idle state, the router attempts to set up an outgoing TCP connection to the remote neighbor in addition to listening on TCP port 179 for an incoming connection from the peer. If required, a statically configured BGP session can be configured for passive mode so that the router only listens for an incoming connection and does not attempt to set up the outgoing connection.
The source IP address used to set up the TCP connection to the statically configured or dynamic peer can be configured explicitly. Use the following command to configure the source IP address at the group level.
configure router bgp group local-addressUse the following command to configure the source IP address at the neighbor level:
-
MD-CLI
configure router bgp neighbor local-address -
classic CLI
configure router bgp group neighbor local-address
If the local-address command is not configured, the source IP address is determined as follows:
If the neighbor’s IP address belongs to a local subnet, the source IP address is this router’s IP address on that subnet.
If the neighbor’s IP address does not belong to a local subnet, the source IP address is this router’s system IP address.
In addition, it is possible to configure the local address with the name of the router interface. To configure the BGP local address to use the router interface’s IP address information, the local-address command is used in conjunction with the configured router interface name. Configuring the router interface as the local address is available at both the group level and the neighbor level.
When the router interface is configured as the local address, BGP inherits the address from the interface as follows:
BGPv4 sessions
The primary IPv4 address configured on the interface is used as the local address.
BGPv6 sessions
The primary IPv6 address configured on the interface is used as the local address.
If the corresponding IPv4 or IPv6 address is not configured on the router interface, the BGP sessions that have this interface set as the local address are kept down until an interface address is configured on the router interface.
If the primary IPv4 or IPv6 address is changed on the router interface and that interface is being used as the local address for BGP, then BGP bounces the link. This removes all routes advertised using the previous address and starts advertising those routes again using the newly configured IP address.
BGP session states
A BGP session is in one of the following states at any moment in time:
Idle
This is the state of a BGP session when it is administratively disabled. In this state no incoming TCP connection is accepted from the peer. When the session is administratively enabled it transitions out of the idle state immediately. When the session is restarted automatically it may not leave the idle state immediately if damp-peer-oscillations is configured, damp-peer-oscillations holds a session in the idle state for exponentially increasing amounts of time if the session is unstable and resets frequently.
-
Connect
This is the state of a BGP session when the router, acting in active mode, is attempting to establish an outbound TCP connection with the remote peer.
-
Active
This is the state of a BGP session when the router is listening for an inbound TCP connection attempt from the remote peer.
OpenSent
This is the state of a BGP session when the router has sent an OPEN message to its peer in reaction to successful setup of the TCP connection and is waiting for an OPEN message from the peer.
OpenConfirm
This is the state of a BGP session after the router has received an acceptable OPEN message from the peer and sent a KEEPALIVE message in response and is waiting for a KEEPALIVE message from the peer. TCP connection collision procedures may be performed at this stage. For more details, see the RFC 4271, A Border Gateway Protocol 4 (BGP-4).
Established
This is the state of a BGP session after the router has received a KEEPALIVE message from the peer. In this state BGP can advertise and withdraw routes by sending UPDATE messages to its peer.
Detecting BGP session failures
If a router suspects that its peer at the other end of an established session has experienced a complete failure of both its control and data planes the router should divert traffic away from the failed peer as quickly as possible to minimize traffic loss. There are various mechanisms that the router can use to detect such failures, including:
BGP session hold timer expiry (for more details about this mechanism, see Keepalive message)
peer tracking
BFD
fast external failover
When any one or these mechanisms is triggered the session immediately returns to the Idle state and a new session is attempted. Peer tracking, BFD and fast external failover are described in more detail in the following sections.
Peer tracking
When peer tracking is enabled on a session, the neighbor IP address is tracked in the routing table. If a failure occurs and there is no longer any IP route matching the neighbor address, or if the longest prefix match (LPM) route is rejected by the peer-tracking policy (configurable for the BGP router or VPRN service using the peer-tracking-policy command), after a 1-second delay the session is taken down. By default, peer-tracking is disabled on all sessions. The default peer-tracking policy allows any type of route to match the neighbor IP address, except aggregate routes and LDP shortcut routes.
Peer tracking was introduced when BFD was not yet supported for peer failure detection. Now that BFD is available, peer-tracking has less value and is used less often.
Bidirectional Forwarding Detection
SR OS supports setting up an asynchronous-mode BFD session to a BGP neighbor, so that the failure of the BFD session triggers an immediate teardown of the BGP session. When BFD is enabled on a BGP session, a one-hop or multihop BFD session is set up using the neighbor IP address, and the BFD settings are derived from the BFD configuration of the interface associated with the address. For multihop sessions, this is usually the system interface. With a 10 ms transit interval and a multiplier of 3, BFD can detect peer failure in as quickly as 30 ms.
By default, BGP only reacts to BFD sessions transitioning from up to down and does not wait for the BFD session to come back up to reestablish the affected BGP session or to consider the address of the peer (as a BGP next hop) reachable. However, when BFD Strict-Mode is active, that is, both sides have advertised the associated BGP capability and BFD is configured appropriately on each side, BGP blocks the BGP session from transitioning to established until the BFD session to the peer is up.
Strict-BFD cannot be used to control BGP session-state changes, but the user can use the next-hop-reachability command to configure the BGP next-hop resolution process to keep a next hop unresolved for as long as the associated BFD session stays down, and not to recover automatically based on route or tunnel reachability. When the next-hop-reachability command is enabled, routes received from one peer with a BGP next-hop address equal to the address of another peer are not affected by the BFD session to the other peer. The next-hop-reachability command only affects routes belonging to the following address families:
-
IPv4
-
IPv6
-
IPv4 VPN
-
IPv6 VPN
-
labeled unicast IPv4
-
labeled unicast IPv6
-
EVPN
-
IPv4 multicast
-
IPv6 multicast
-
IPv4 VPN multicast
-
IPv6 VPN multicast
Fast external failover
Fast external failover applies only to single-hop EBGP sessions. When fast external failover is enabled on a single-hop EBGP session and the interface associated with the session goes down the BGP session is immediately taken down as well, even if other mechanisms such as the hold-timer have not yet indicated a failure.
High availability BGP sessions
A BGP session reset can be very disruptive – each router participating in the failed session must delete the routes it received from its peer, recalculate new best paths, update forwarding tables (depending on the types of routes), and send route withdrawals and advertisements to other peers. It makes sense then that session resets should be avoided as much as possible and when a session reset cannot be avoided the disruption to the network should be minimized.
To support these objectives, the BGP implementation in SR OS supports two key features:
BGP high availability (HA)
BGP graceful restart (GR)
BGP HA refers to the capability of a router with redundant CPMs to keep established BGP sessions up whenever a planned or unplanned CPM switchover occurs. A planned CPM switchover can occur during In-Service Software Upgrade (ISSU). An unplanned CPM switchover can occur if there is an unexpected failure of the primary CPM.
BGP HA is always enabled on routers with redundant CPMs; it cannot be disabled. BGP HA keeps the standby CPM in-sync with the primary CPM, with respect to BGP and associated TCP state, so that the standby CPM is ready to take over for the primary CPM at any time. The primary CPM is responsible for building and sending the BGP messages to peers but the standby CPM reliably receives a copy of all outgoing UPDATE messages so that it has a synchronized view of the RIB-OUT.
BGP graceful restart
Some BGP routers do not have redundant control plane processor modules or do not support BGP HA with the same quality or coverage as 7450 ESS, 7750 SR, or 7950 XRS routes. When dealing with such routers or specific error conditions, BGP graceful restart (GR) is a good option for minimizing the network disruption caused by a control plane reset.
BGP GR assumes that the router restarting its BGP sessions has the ability and architecture to continue packet forwarding throughout the control plane reset. If this is the case, then the peers of the restarting router act as helpers and ‟hide” the control plane reset from the rest of the network so that forwarding can continue uninterrupted. Forwarding based on stale routes and hiding the ‟staleness” from other routers is considered acceptable because the duration of the control plane outage is expected to be relatively short (a few minutes). For BGP GR to be used on a session, both routers must advertise the BGP GR capability during the OPEN message exchange; see the BGP advertisement section for more details.
BGP GR is enabled on one or more BGP sessions by configuring the graceful-restart command in the global, group, or neighbor context. The command causes GR mode to be supported for the following active families:
IPv4 unicast
IPv6 unicast
VPN-IPv4
VPN-IPv6
label-IPv4
label-IPv6
L2-VPN
route-target (RTC)
flow-IPv4 (IPv4 FlowSpec)
flow-IPv6 (IPv6 FlowSpec)
Helper mode is activated when one of the following events affects an 'Established' session:
TCP socket error
new inbound TCP connection from the peer
hold timer expiry
peer unreachable
BFD down
-
sent or received NOTIFICATION messages, only if notifications are enabled using the following commands, and the peer set the ‟N” bit in its GR capability, and the NOTIFICATION is not a 'Cease' with subcode 'Hard Reset':
- MD-CLI
configure router bgp graceful-restart gr-notification configure router bgp group graceful-restart gr-notification configure router bgp neighbor graceful-restart gr-notification - classic
CLI
configure router bgp graceful-restart enable-notification configure router bgp group graceful-restart enable-notification configure router bgp group neighbor graceful-restart enable-notification
- MD-CLI
As soon as the failure is detected, the helping 7450 ESS, 7750 SR, or 7950 XRS router marks all the routes received from the peer as stale and starts a restart timer. The stale state is not factored into the BGP decision process, and it is not made visible to other routers in the network. The restart timer derives its initial value from the Restart Time carried in the last GR capability of the peer. The default advertised Restart Time is 300 seconds, but it can be changed using the restart-time command.
When the restart timer expires, helping stops if the session is not yet re-established. If the session is re-established before the restart timer expires and the new GR capability from the restarting router indicates that the forwarding state has been preserved, then helping continues and the peers exchange routes per the normal procedure.
When each router has advertised all its routes for a specific address family, it sends an End-of-RIB marker (EOR) for the address family. The EOR is a minimal UPDATE message with no reachable or unreachable Network Layer Reachability Information (NLRI) for the AFI or SAFI. When the helping router receives an EOR, it deletes all remaining stale routes of the AFI or SAFI that were not refreshed in the most recent set of UPDATE messages. The maximum amount of time that routes can remain stale (before being deleted if they are not refreshed) is configurable using the stale-routes-time.
BGP long-lived graceful restart
SR OS supports Long-Lived Graceful Restart (LLGR). LLGR is supported for the same address families as normal GR, as described in BGP graceful restart.
The LLGR procedures adhere to draft-uttaro-idr-bgp-persistence-03. LLGR is intended to handle more serious and longer-term outages than ordinary GR.
SR OS routers support LLGR in the context of both the restarting router (which experienced a restart or failure) and the helper or receiving router (which is a peer of the failed router). Both functionalities are enabled and disabled at the same time by adding the long-lived command under a graceful-restart configuration context.
When long-lived is applied to a session (and capability negotiation is not disabled), the OPEN message sent to the peer includes both the GR capability and the LLGR capability. Both capabilities list the same set of AFI/SAFI.
LLGR operations
If a BGP session protected by LLGR goes down because of a restart or failure of the peer, then the SR OS router activates GR+LLGR helper mode for all the protected AFI/SAFI. In GR+LLGR helper mode, the received routes of a particular AFI/SAFI are retained as stale routes for a maximum duration of:
restart-time + LLGR-stale-time
where:
restart-time is signaled in the GR capability of the peer (but overridden, if necessary, by the locally-configured helper-override-restart-time command).
LLGR-stale-time is signaled in the LLGR capability of the peer (but overridden, if necessary, by a locally-configured helper-override-stale-time command).
While the restart-timer is running, the SR OS router acts in the normal GR helper role. When the restart-timer elapses, the LLGR phase begins. When LLGR starts, the following tasks occur.
The LLGR-stale-time starts to count down.
Stale routes marked with the NO_LLGR community are immediately deleted.
Remaining stale routes are not preferred. The BGP best path selection algorithm is rerun with a new first step that prefers valid, non-stale LLGR routes over any stale LLGR routes.
If a de-preferenced stale route remains, the best and valid NH-reachable path for the NLRI is re-advertised, with an added LLGR_STALE community, to peers that signaled support for the LLGR capability. The route may be withdrawn or re-advertised toward peers that do not support LLGR, subject to the configuration of the advertise-stale-to-all-neighbors command and without-no-export command option.
LLGR ends for a particular AFI/SAFI when the LLGR-stale-time reaches zero. At that time, all remaining stale routes of the AFI/SAFI are deleted. The LLGR-stale-time is not stopped by re-establishment of the session with the failed peer; it continues until the EoR marker is received for the AFI/SAFI.
Stale routes may be deleted before the expiration of the LLGR-stale-time. If the session with the failed peer comes back up and one of the following is true, then the stale routes should be deleted immediately.
The GR or LLGR capability is missing.
The AFI/SAFI is missing from the LLGR capability.
The F bit is equal to 0 for the AFI/SAFI.
Receiving routes with LLGR_STALE community
When a router running SR OS Release 15.0.R4 or later receives a BGP route of any AFI/SAFI, with the LLGR_STALE community, the decision process considers the route less preferred than any valid, non-stale LLGR route for that NLRI. This logic applies even if the router is not configured as long-lived. If a route with an LLGR_STALE community is selected as the best path, then it is advertised to peers according to the configuration of the advertise-stale-to-all-neighbors command; if this command is absent (or the long-lived context is absent), then the route is advertised only to peers that advertised the LLGR capability.
BGP session security
TCP MD5 authentication
The operation of a network can be compromised if an unauthorized system is able to form or hijack a BGP session and inject control packets by falsely representing itself as a valid neighbor. This risk can be mitigated by enabling TCP MD5 authentication on one or more of the sessions. When TCP MD5 authentication is enabled on a session every TCP segment exchanged with the peer includes a TCP option (19) containing a 16-byte MD5 digest of the segment (more specifically the TCP/IP pseudo-header, TCP header and TCP data). The MD5 digest is generated and validated using an authentication key that must be known to both sides. If the received digest value is different from the locally computed one then the TCP segment is dropped, thereby protecting the router from spoofed TCP segments.
TTL security mechanism
The TTL security mechanism (GTSM) relies on a simple concept to protect BGP infrastructure from spoofed IP packets. It recognizes the fact that the vast majority of EBGP sessions are established between directly-connected routers and therefore the IP TTL values in packets belonging to these sessions should have predictable values. If an incoming packet does not have the expected IP TTL value it is possible that it is coming from an unauthorized and potentially harmful source.
TTL security is enabled using the ttl-security command. This command requires a minimum TTL value to be specified. When TTL security is enabled on a BGP session the IP TTL values in packets that are supposedly coming from the peer are compared (in hardware) to the configured minimum value and if there is a discrepancy the packet is discarded and a log is generated. TTL security is used most often on single-hop EBGP sessions but it can be used on multihop EBGP and IBGP sessions as well.
To enable TTL security on a single-hop EBGP session, configure ttl-security and multihop to a value of 255. To enable TTL security on a multihop EBGP session, configure ttl-security and multihop to match the expected TTL of (255 - hop count). The TTL value for both EBGP peers must be manually configured to the same value, as there is no TTL negotiation.
BGP address family support for different session types
When the base router has a neighbor identified by an IPv4 address, and therefore the transport of the BGP session uses IPv4 TCP, all MP-BGP address families available in SR OS are supported by that session.
When the base router has a neighbor identified by an IPv6 address, and therefore the transport of the BGP session uses IPv6 TCP, the following MP-BGP address families are supported:
ipv4
ipv6
mcast-ipv4
mcast-ipv6
vpn-ipv4
vpn-ipv6
evpn
flow-ipv6
label-ipv4
label-ipv6
bgp-ls
When a VPRN has a neighbor identified by an IPv4 address, and therefore the transport is IPv4 TCP, the following MP-BGP address families are supported:
ipv4
ipv6
mcast-ipv4
mcast-ipv6
flow-ipv4
flow-ipv6
label-ipv4
When a VPRN has a neighbor identified by an IPv6 address, and therefore the transport is IPv6 TCP, the following MP-BGP address families are supported:
ipv4
ipv6
mcast-ipv4
mcast-ipv6
flow-ipv6
BGP groups
BGP design concepts
BGP assumes that all routers within an Autonomous System can reach destinations external to the Autonomous System using efficient, loop-free intra-AS forwarding paths. This generally requires that all the routers within the AS have a consistent view of the best path to every external destination. This is especially true when each BGP router in the AS makes its own forwarding decisions based on its own BGP routing table. The basic BGP specification does not store any intra-AS path information in the AS Path attribute so basic BGP has no way to detect routing loops within an AS that arise from inconsistent best path selections.
There are 3 solutions for dealing the issues described above.
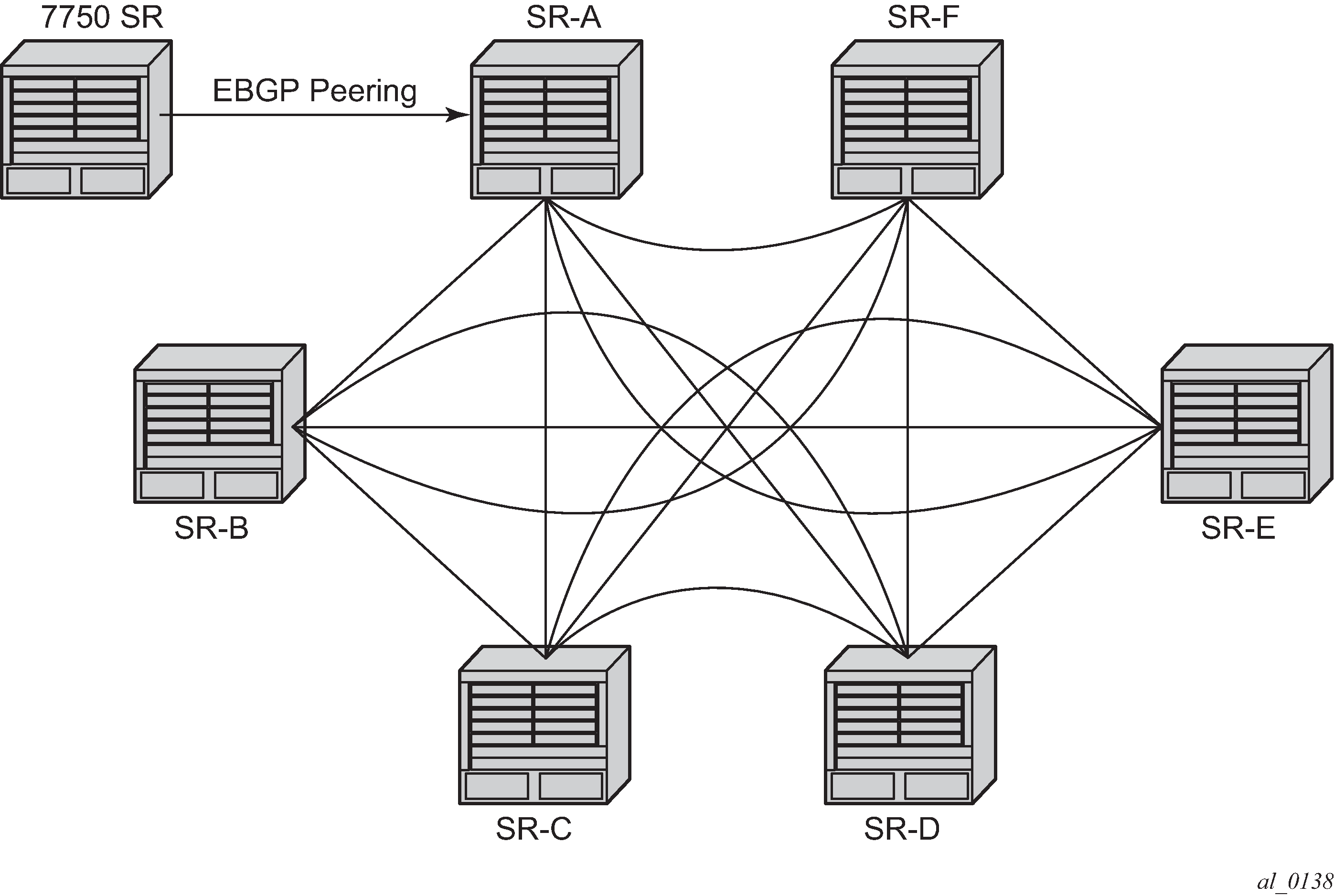
Create a full-mesh of IBGP sessions within the AS as shown in Fully meshed BGP configuration. This ensures routing consistency but does not scale well because the number of sessions increases exponentially with the number of BGP routers in the AS.
Use BGP route reflectors in the AS. Route reflection is described in the section titled Route reflection. BGP route reflectors allow for routing consistency with only a partial mesh of IBGP sessions within the AS.
-
Create a confederation of autonomous systems. BGP confederations are described in the section titled BGP confederations.
Route reflection
In a standard BGP configuration a BGP route learned from one IBGP peer is not re-advertised to another IBGP peer. This rule exists because of the assumption of a full IBGP mesh within the AS. As discussed in the previous section a full IBGP mesh imposes specific scaling challenges. BGP route reflection eliminates the need for a full IBGP mesh by allowing routers configured as route reflectors to re-advertise routes from one IBGP peer to another IBGP peer.
A route reflector provides route reflection service to IBGP peers called clients. Other IBGP peers of the RR are called non-clients. An RR and its client peers form a cluster. A large AS can be sub-divided into multiple clusters, each identified by a unique 32-bit cluster ID. Each cluster contains at least one route reflector which is responsible for redistributing routes to its clients. The clients within a cluster do not need to maintain a full IBGP mesh between each other; they only require IBGP sessions to the route reflectors in their cluster. If the clients within a cluster are fully meshed, consider using the following commands to disable client reflection of routes. The non-clients in an AS must be fully meshed with each other.
- MD-CLI
configure router bgp client-reflect configure router bgp neighbor client-reflect configure router bgp group client-reflect - classic
CLI
configure router bgp disable-client-reflect configure router bgp group neighbor disable-client-reflect configure router bgp group disable-client-reflect
BGP configuration with route reflectors depicts the same network as Fully meshed BGP configuration but with route reflectors deployed to eliminate the IBGP mesh between SR-B, SR-C, and SR-D. SR-A, configured as the route reflector, is responsible for reflection routes to its clients SR-B, SR-C, and SR-D. SR-E and SR-F are non-clients of the route reflector. As a result, a full mesh of IBGP sessions must be maintained between SR-A, SR-E and SR-F.
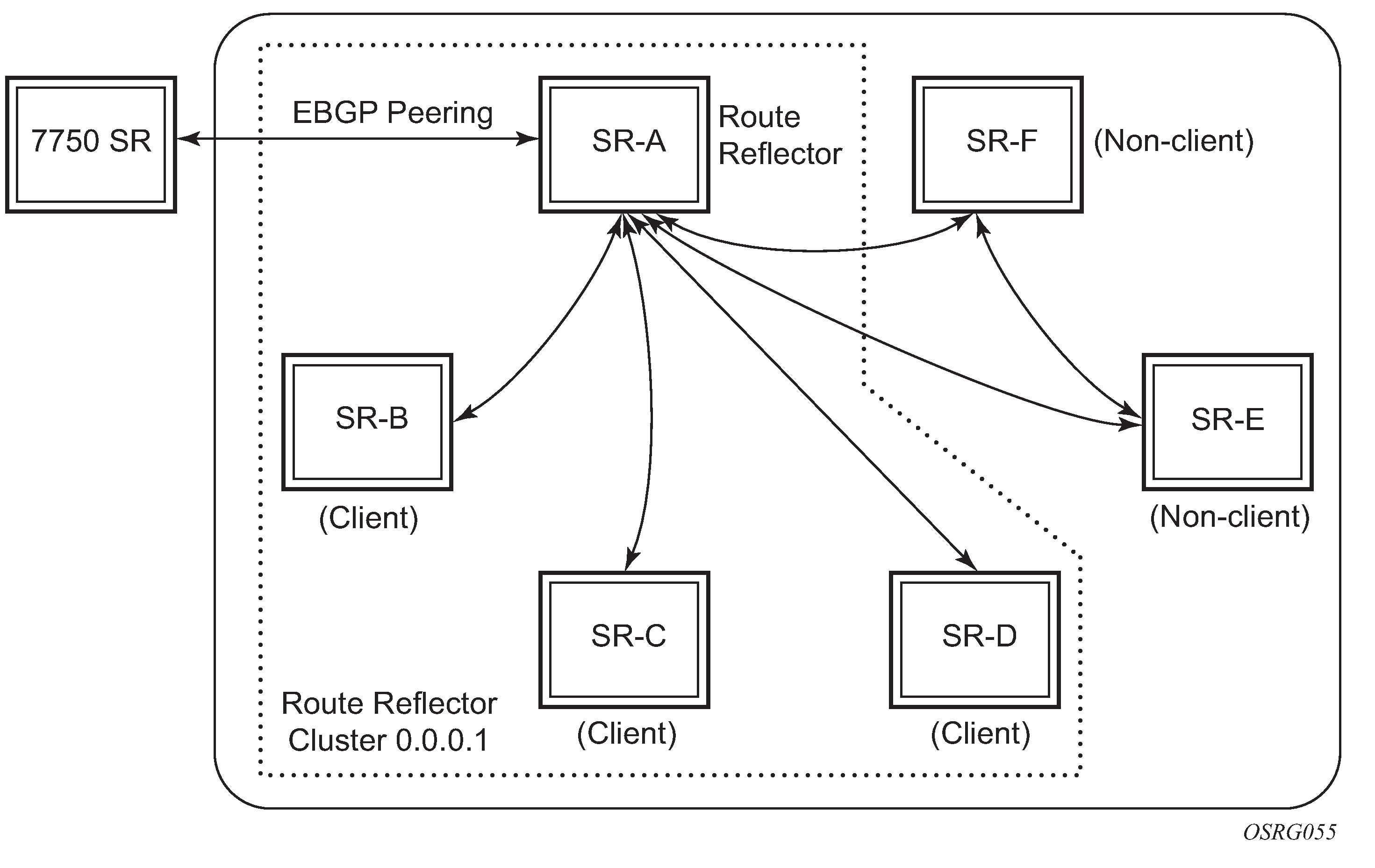
A router becomes a route reflector whenever it has one or more client IBGP sessions. Use the BGP cluster command to create a client IBGP session, which also indicates the cluster ID of the client. The typical practice is to use the router ID as the cluster ID, although this is not necessary.
Basic route reflection operation (without Add-Path configured) is summarized as follows.
If the best and valid path for an NLRI is learned from a client and client reflection of routes is not disabled, advertise that route to all clients, non-clients, and EBGP peers (as allowed by policy). If the client that advertised the best and valid path is a neighbor to which the split-horizon command (at the BGP group or neighbor level) applies, the route is not advertised back to the sending client. In the route that is reflected to clients and non-clients, the route reflector does the following:
- adds an ORIGINATOR_ID attribute if it did not already exist; the ORIGINATOR_ID indicates the BGP identifier (router ID) of the client that originated the route
prepends the cluster ID of the client that advertised the route and then the cluster ID of the client receiving the route (if applicable) to the CLUSTER_LIST attribute, creating the attribute if it did not previously exist
-
If the best and valid path for an NLRI is learned from a client and client reflection of routes is disabled, advertise that route to all clients in other clusters, non-clients, and EBGP peers (as allowed by policy). In the route that is reflected to clients in other clusters and non-clients, the router reflector does the following:
adds an ORIGINATOR_ID attribute if it did not already exist; the ORIGINATOR_ID indicates the BGP identifier (router ID) of the client that originated the route
prepends the cluster ID of the client receiving the route to the CLUSTER_LIST attribute, creating the attribute, if it did not previously exist
-
If the best and valid path for an NLRI is learned from a non-client, advertise that route to all clients and EBGP peers (as allowed by policy). In the route that is reflected to clients, the router reflector does the following:
-
adds an ORIGINATOR_ID attribute if it did not already exist; the ORIGINATOR_ID indicates the BGP identifier (router ID) of the non-client that originated the route
-
prepends the cluster ID of the client receiving the route to the CLUSTER_LIST attribute, creating the attribute if it did not previously exist
-
If the best and valid path for an NLRI is learned from an EBGP peer, advertise that route to all clients, non-clients and other EBGP peers (as allowed by policy). The ORIGINATOR_ID and CLIUSTER_LIST attributes are not added to the route.
If the best and valid path for an NLRI is locally originated by the RR (for example, it was learned through means other than BGP), it advertises that route to all clients, non-clients and EBGP peers (as allowed by policy). The ORIGINATOR_ID and CLUSTER_LIST attributes are not added to the route.
The ORIGINATOR_ID and CLUSTER_LIST attributes allow BGP to detect the looping of a route within the AS. If any router receives a BGP route with an ORIGINATOR_ID attribute containing its own BGP identifier, the route is considered invalid. In addition, if a route reflector receives a BGP route with a CLUSTER_LIST attribute containing a locally configured cluster ID, the route is considered invalid. Invalid routes are not installed in the route table and not advertised to other BGP peers.
BGP confederations
BGP confederations are another alternative for avoiding a full mesh of BGP sessions inside an Autonomous System (AS). A BGP confederation is a group of ASs managed by a single technical administration that appear as a single AS to BGP routers outside the confederation. The single externally visible AS is called the confederation ID. Each AS in the group is called a member AS and the ASN of each member AS is visible only within the confederation. For this reason, member ASNs are often private ASNs.
Within a confederation EBGP-type, sessions can be setup between BGP routers in different member ASs. These confederation-EBGP sessions avoid the need for a full mesh between routers in different member ASs. Within each member AS the BGP routers must be fully-meshed with IBGP sessions or route reflectors must be used to ensure routing consistency.
In SR OS, a confederation EBGP session is formed when the ASN of the peer is different from the local ASN and the peer ASN appears as a member AS in the configure router confederation context. You can configure the confederation ID and up to 15 members that are part of a confederation.
When a route is advertised to a confederation-EBGP peer the advertising router prepends its local ASN, which is its member ASN, to a confederation-specific sub-element in the AS_PATH that is created if it does not already exist. The extensions to the AS_PATH are used for loop detection but they do not influence best path selection (that is, they do not increase the AS Path length used in the BGP decision process). The MED, NEXT_HOP and LOCAL_PREF attributes in the received route are propagated unchanged by default. The ORIGINATOR_ID and CLUSTER_LIST attributes are not included in routes to confederation-EBGP peers.
When a route is advertised to an EBGP peer outside the confederation the advertising router removes all member AS elements from the AS_PATH and prepends its confederation ID instead of its local/member ASN.
BGP messages
BGP protocol operation relies on the exchange of BGP messages between peers. 7450 ESS, 7750 SR, 7950 XRS, and most other routers, support the following message types: Open message, Update message, Keepalive message, Notification message, and Route refresh message.
The minimum BGP message length is 19 bytes and the maximum is 4096 bytes. BGP messages appear as a stream of bytes to the underlying TCP transport layer, and so there is no direct association between a BGP message and a TCP segment. One TCP segment can include parts of one or more BGP messages. Immediately after session setup, the initial value for the maximum TCP segment size that can be sent toward a specific peer is the minimum of the following:
the MSS option value in the TCP SYN received from the peer, when the connection was established
the IP MTU of the initial outgoing interface used to route packets to the peer, minus 40 bytes (IPv4) or minus 60 bytes (IPv6)
the TCP MSS value in the BGP configuration of the peer, if there is a configuration and it specifies a value instead of the ip-stack option
As time elapses, the maximum sending segment size can fall below the initial value if path MTU discovery (PMTUD) is active on the session. PMTUD lowers the segment size when ICMP unreachable or packet-too-big messages are received. These messages indicate that the IP MTU of the link could not forward the unfragmentable packet and this IP MTU minus 40 (IPv4) or minus 60 (IPv6) bytes sets the new maximum segment size value.
Open message
After a TCP connection is established between two BGP routers the first message sent by each one is an Open message. If the received Open message is acceptable a Keepalive message confirming the Open is sent back. For more information, see BGP session states.
An Open message contains the following information:
Version
The current BGP version number is 4.
Autonomous system number
The 2-byte AS of the sending router. If the sending router has an ASN greater than 65535, this field has the special value 23456 (AS_TRANS). On a 7450, 7750, or 7950 router, the ASN in the Open message is based on the confederation ID (if the peer is external to the confederation), the global AS (configured using the autonomous-system command) or a session-level override of the global AS called the local AS (configured using the local-as command). More details about the use of local-AS are described in the section titled Using local AS for ASN migration. More details about 4-byte AS numbers are described in the section titled 4-octet autonomous system numbers.
Hold time
The proposed maximum time BGP waits between successive messages (Keepalive and/or Update) from its peer before closing the connection. The actual hold time is the minimum of the configured hold-time for the session and the hold-time in the peer's Open message. If this minimum is below the threshold configured with the following command option, the connection attempt is rejected:
- MD-CLI
configure router bgp neighbor hold-time minimum-hold-time - classic
CLI
configure service vprn bgp hold-time min
Note: Changes to the configured hold-time trigger a session reset.- MD-CLI
BGP identifier
The router ID of the BGP speaker. In Open messages, the BGP ID is derived from following:
- The router ID configured under BGP.
- If the router ID is not configured under BGP, the BGP ID comes from the configuration under the configure router or configure service vprn context.
- If the router ID is not configured for the router or service VPRN, the system interface IPv4 address is used.
Note: A change of the router ID in the configure router bgp context causes all BGP sessions to be reset immediately while other changes resulting in a new BGP identifier only take effect after BGP is shutdown and re-enabled.Options
Each of the option capabilities is TLV-encoded with a unique type code. The only optional capability that has been defined is the optional type. The optional type supports the process of BGP advertisement (see BGP advertisement for more information). The BGP router terminates the session if it receives an Open message with an unsupported optional type. Unless you disable the capability negotiation using the following command, the router always sends an optional type in its Open message:
- MD-CLI
configure router bgp group capability-negotiation false configure router bgp neighbor capability-negotiation false - classic
CLI
configure router bgp group disable-capability-negotiation configure router bgp group neighbor disable-capability-negotiation
- MD-CLI
Changing the autonomous system number
If the AS number is changed at the router level (configure router), the new AS number is not used until the BGP instance is restarted either by administratively disabling and enabling the BGP instance or by rebooting the system with the new configuration.
On the other hand, if the AS number is changed in the BGP configuration (configure router bgp), the effects are as follows.
A change of the local-AS at the global level causes the BGP instance to restart with the new local AS number.
A change of the local-AS at the group level causes BGP to re-establish sessions with all peers in the group using the new local AS number.
A change of the local-AS at the neighbor level causes BGP to re-establish the session with the new local AS number.
Changing a confederation number
Changing the confederation value on an active BGP instance does not restart the protocol. The change takes effect when the BGP protocol is (re) initialized.
BGP advertisement
BGP advertisement allows a BGP router to indicate to a peer, using the optional type, the features that it supports so that they can coordinate and use only the features that both support. Each capability is TLV-encoded with a unique optional type code. SR OS supports the following capability codes:
multi-protocol BGP (code 1)
route refresh (code 2)
outbound route filtering (code 3)
graceful restart (code 64)
4-octet AS number (code 65)
add-path (code 69)
Update message
Update messages are used to advertise and withdraw routes. An update message provides the following information:
Withdrawn routes length
The length of the withdrawn routes field that is described next (may be 0).
Withdrawn routes
The IPv4 prefixes that are no longer considered reachable by the advertising router.
Total path attribute length
The length of the path attributes field that is discussed next (may be 0).
Path attributes
The path attributes presented in variable length TLV format. The path attributes apply to all the NLRI in the UPDATE message.
Network layer reachability information (NLRI)
The IPv4 prefixes that are considered reachable by the advertising router.
For fast routing convergence, as many NLRI as possible are packed into a single Update message as possible. This requires identifying all the routes that share the same path attribute values.
Keepalive message
After a session is established, each router sends periodic Keepalive messages to its peer to test that the peer is still alive and reachable. If no Keepalive or Update message is received from the peer for the negotiated hold-time duration, the session is terminated. The period between one Keepalive message and the next is 1/3 of the negotiated hold-time duration or the value configured with the keepalive command, whichever is less. If the active hold-time or keepalive interval is zero, Keepalive messages are not sent. The default hold-time is 90 seconds and the default keepalive interval is 30 seconds.
A peer (reachability) failure is often detected through faster mechanisms than hold-timer expiry, as described in Detecting BGP session failures.
Notification message
When a non-recoverable error related to a particular session occurs a Notification message is sent to the peer and the session is terminated (or restarted if GR is enabled for this scenario). For more details, see BGP graceful restart. The Notification message provides the following information:
Error code
This indicates the type of error: message header error, Open message error, Update message error, Hold timer expired, Finite State Machine error, or Cease.
Error subcode
This provides more specific information about the error. The meaning of the subcode is specific to the error code.
Update message error handling
The approach to handling update message errors has evolved in the past couple of years. The original BGP protocol specification called for all update message errors to be handled the same way (that is, send a notification to the peer and immediately close the BGP session). This error handling approach was motivated by the goal to ensure protocol ‟correctness” above all else. But, it ignored several important points.
Not all UPDATE message errors truly have the same severity. If the NLRI cannot be extracted and parsed from an UPDATE message then this is indeed a ‟critical” error. But other errors such as incorrect attribute flag settings, missing mandatory path attributes, incorrect next-hop length/format, and so on. can be considered ‟non-critical” and handled differently.
Session resets are extremely costly in terms of their impact on the stability and performance of the network. For many types of UPDATE message errors, a session reset does not solve the problem because the root cause remains (for example, software error, hardware error or misconfiguration). If a session reset is absolutely necessary, then the operator should have some control over the timing.
Some degree of protocol ‟incorrectness” is tolerable for a short period of time as long as the network operator is fully aware of the issue. In this context, ‟incorrectness” typically means a BGP RIB inconsistency between routers in the same AS. Such inconsistency has become less and less of an issue over time as edge-to-edge tunneling of IP traffic (for example, BGP shortcuts, IP VPN) has reduced the number of deployments where IP traffic is forwarded hop-by-hop.
In recognition of these points and the general trend toward more flexibility in BGP error handling, SR OS supports a BGP configuration option called update-fault-tolerance that allows you to decide whether the router should apply new or legacy error handling procedures to update message errors. If the update-fault-tolerance command is configured, non-critical errors as described are handled using the ‟treat-as-withdraw” or ‟attribute-discard” approaches to error handling. These approaches do not cause a session reset. If the update-fault-tolerance command is not configured, legacy procedures continue to apply and all errors (critical and non-critical) trigger a session reset.
If the update-fault-tolerance command was previously configured and a non-critical error was already triggered, the BGP session is still reset if you disable the update-fault-tolerance command.
Route refresh message
A BGP router can send a Route Refresh message to its peer only if both have advertised the route refresh capability (code 2). The Route Refresh message is a request for the peer to re-send all or some of its routes associated with a particular pair of AFI/SAFI values. AFI/SAFI values are the same ones used in the MP-BGP capability (see the section titled Multi-protocol BGP attributes).
7450, 7750, and 7950 routers only send Route Refresh messages for AFI/SAFI associated with VPN routes that carry Route Target (RT) Extended Communities, such as VPN-IPv4, VPN-IPv6, L2-VPN, MVPN-IPv4 and MVPN-IPv6 routes. By default, routes of these types are discarded if, at the time they are received, there is no VPN that imports any of the route targets they carry. If at a later time a VPN is added or reconfigured (in terms of the route targets that it imports), a Route Refresh message is sent to all relevant peers, so that previously discarded routes can be relearned.
BGP path attributes
Path attributes are fundamental to BGP. A BGP route for a particular NLRI is distinguished from other BGP routes for the same NLRI by its set of path attributes. Each path attribute describes some property of the path and is encoded as a TLV in the Path Attributes field of the Update message. The type field of the TLV identifies the path attribute and the value field carries data specific to the attribute type. There are 4 different categories of path attributes:
Well-known mandatory
These attributes must be recognized by all BGP routers and must be present in every update message that advertises reachable NLRI toward a specific type of neighbor (EBGP or IBGP).
Well-known discretionary
These attributes must be recognized by all BGP routers but are not required in every update message.
Optional transitive
These attributes are allowed to be unrecognized by some BGP routers. If a BGP router does not recognize one of these attributes it accepts it, passes it on to other BGP peers, and sets the Partial bit to 1 in the attribute flags byte.
Optional non-transitive
These attributes are allowed to be unrecognized by some BGP routers. If a BGP router does not recognize one of these attributes it is quietly ignored and not passed on to other BGP peers.
SR OS supports the following path attributes, which are described in detail in upcoming sections:
ORIGIN (well-known mandatory)
AS_PATH (well-known mandatory)
NEXT_HOP (well-known, required only in Update messages with IPv4 prefixes in the NLRI field)
MED (optional non-transitive)
LOCAL_PREF (well-known, required only in Update messages sent to IBGP peers)
ATOMIC_AGGR (well-known discretionary)
AGGREGATOR (optional transitive)
COMMUNITY (optional transitive)
ORIGINATOR_ID (optional non-transitive)
CLUSTER_LIST (optional non-transitive)
MP_REACH_NLRI (optional non-transitive)
MP_UNREACH_NLRI (optional non-transitive)
EXT_COMMUNITY (optional transitive)
AS4_PATH (optional transitive)
AS4_AGGREGATOR (optional transitive)
CONNECTOR (optional transitive)
PMSI_TUNNEL (optional transitive)
TUNNEL_ENCAPSULATION (optional transitive)
AIGP (optional non-transitive)
BGP-LS (optional non-transitive)
LARGE_COMMUNITY (optional transitive)
Origin
The ORIGN path attribute indicates the origin of the path information. There are three supported values:
IGP (0)
EGP (1)
Incomplete (2)
When a router originates a VPN-IP prefix (from a non-BGP route), it sets the value of the origin attribute to IGP. When a router originates an BGP route for an IP prefix by exporting a non-BGP route from the routing table, it sets the value of the origin attribute to Incomplete. Route policies (BGP import and export) can be used to change the origin value.
AS path
The AS_PATH attribute provides the list of Autonomous Systems through which the routing information has passed. The AS_PATH attribute is composed of segments. There can be up to 4 different types of segments in an AS_PATH attribute: AS_SET, AS_SEQUENCE, AS_CONFED_SET and AS_CONFED_SEQUENCE. The AS_SET and AS_CONFED_SET segment types result from route aggregation. AS_CONFED_SEQUENCE contains an ordered list of member AS through which the route has passed inside a confederation. AS_SEQUENCE contains an ordered list of AS (including confederation IDs) through which the route has passed on its way to the local AS/confederation.
The AS numbers in the AS_PATH attribute are all 2-byte values or all 4-byte values (if the 4-octet ASN capability was announced by both peers).
A BGP router always prepends its AS number to the AS_PATH attribute when advertising a route to an EBGP peer. The specific details for a 7450, 7750, or 7950 router are described below.
When a route is advertised to an EBGP peer and the advertising router is not part of a confederation.
The global AS (configured using the autonomous-system command) is prepended to the AS_PATH if local-as is not configured.
The local AS followed by the global AS are prepended to the AS_PATH if local-as is configured.
Only the local AS (not the global AS) is prepended to the AS_PATH if the following command is configured:
- MD-CLI
configure router bgp local-as prepend-global-as false - classic
CLI
configure router bgp local-as no-prepend-global-as
- MD-CLI
Some or all private and reserved AS numbers (64512 to 65535 and 4200000000 to 4294967295 inclusive) can be removed or replaced from the AS_PATH if the remove-private command is configured.
When a route is advertised to an EBGP peer outside a confederation.
The confederation ID is prepended to the AS_PATH if local-as is not configured.
The local AS followed by the confederation ID are prepended to the AS_PATH if local-as is configured (the command option to not prepend the global AS has no effect in this scenario).
Member AS numbers are removed from the AS_PATH as described in the section titled BGP confederations.
Some or all private and reserved AS numbers (64512 to 65535 and 4200000000 to 4294967295 inclusive) can be removed or replaced from the AS_PATH if the remove-private command is configured.
When a route is advertised to a confederation-EBGP peer.
If the route came from an EBGP peer and local-as was configured on this session (without the private option) this local AS number is prepended to the AS_PATH in a regular AS_SEQUENCE segment.
The global AS (configured using the autonomous-system command) is prepended, as a member AS, to the AS_PATH if local-as is not configured.
The local AS followed by the global AS are prepended, as member AS, to the AS_PATH if local-as is configured.
Only the local AS is prepended, as a member AS, to the AS_PATH if local-as no-prepend-global-as is configured.
Some or all private and reserved AS numbers (64512 to 65535 and 4200000000 to 4294967295 inclusive) can be removed or replaced from the AS_PATH if the remove-private command is configured.
When a route is advertised to an IBGP peer.
No information is added to the AS_PATH if the route is locally originated or if it came from an IBGP peer.
The local AS number is prepended to the AS_PATH if the route came from an EBGP peer and local-as is configured without the private option.
The local AS number is prepended, as a member AS, to the AS_PATH if the route came from a confederation-EBGP peer and local-as is configured without the private option.
Some or all private and reserved AS numbers (64512 to 65535 and 4200000000 to 4294967295 inclusive) can be removed or replaced from the AS_PATH if the remove-private command is configured.
BGP import policies can be used to prepend an AS number multiple times to the AS_PATH, whether the route is received from an IBGP, EBGP or confederation EBGP peer. The AS path prepend action is also supported in BGP export policies applied to these types of peers, regardless of whether the route is locally originated or not. AS path prepending in export policies occurs before the global and/or local ASs (if applicable) are added to the AS_PATH.
When a BGP router receives a route containing one of its own autonomous system numbers (local or global or confederation ID) in the AS_PATH the route is normally considered invalid for reason of an AS path loop. However, SR OS provides a loop-detect command that allows this check to be bypassed. If it known that advertising specific routes to an EBGP peer results in an AS path loop condition and yet there is no loop (assured by other mechanisms, such as the Site of Origin (SOO) extended community), then as-override can be configured on the advertising router instead of disabling loop detection on the receiving router. The as-override command replaces all occurrences of the peer AS in the AS_PATH with the advertising router’s local AS.
AS override
The AS override feature can be used in VPRN scenarios where a customer is running BGP as the PE-CE protocol and some or all of the CE locations are in the same Autonomous System (AS). With normal BGP, two sites in the same AS would not be able to reach each other directly because there is an apparent loop in the AS path.
When the AS override option is configured on a PE-CE EBGP session, the PE rewrites the customer ASN in the AS path with the VPRN AS number as the route is advertised to the CE.
Using local AS for ASN migration
The description in the previous section does fully describe the reasons for using local-as. This BGP feature facilitates the process of changing the ASN of all the routers in a network from one number to another. This may be necessary if one network operator merges with or acquires another network operator and the two BGP networks must be consolidated into one autonomous system.
For example, suppose the operator of the ASN 64500 network merges with the operator of the ASN 64501 network and the new merged entity decides to renumber ASN 64501 routers as ASN 64500 routers, so that the entire network can be managed as one autonomous system. The migration can be carried out using the following sequence of steps.
Change the global AS of the route reflectors that used to be part of ASN 64501 to the new value 64500.
Change the global AS of the RR clients that used to be part of ASN 64501 to the new value 64500.
- Configure the following command on every EBGP session of each RR client migrated in step 2:
- MD-CLI
configure router bgp local-as as-number 64501 configure router bgp local-as prepend-global-as false - classic
CLI
configure router bgp local-as 64501 private no-prepend-global-as
- MD-CLI
This migration procedure has several advantages. First, customers, settlement-free peers and transit providers of the previous ASN 64501 network still perceive that they are peering with ASN 64501 and can delay switching to ASN 64500 until the time is convenient for them. Second, the AS path lengths of the routes exchanged with the EBGP peers are unchanged from before so that best path selections are preserved.
4-octet autonomous system numbers
When BGP was developed, it was assumed that 16-bit (2-octet) ASNs would be sufficient for global Internet routing. In theory a 16-bit ASN allows for 65536 unique autonomous systems but some of the values are reserved (0 and 64000-65535). Of the assignable space less than 10% remains available. When a new AS number is needed it is now simpler to obtain a 4-octet AS number. 4-octet AS numbers have been available since 2006. A 32-bit (4-octet) ASN allows for 4,294,967,296 unique values (some of which are again, reserved).
When 4-octet AS numbers became available it was recognized that not all routers would immediately support the ability to parse 4-octet AS numbers in BGP messages so two optional transitive attributes called AS4_PATH and AS4_AGGREGATOR were introduced to allow a gradual migration.
A BGP router that supports 4-octet AS numbers advertises this capability in its OPEN message. The capability information includes the AS number of the sending BGP router, encoded using 4 bytes (recall the ASN field in the OPEN message is limited to 2 bytes). By default, OPEN messages sent by 7450 ESS, 7750 SR, or 7950 XRS routers always include the 4-octet ASN capability. You can change this using the following command:
- MD-CLI
configure router bgp asn-4-byte false - classic
CLI
configure router bgp disable-4byte-asn
If a BGP router and its peer have both announced the 4-octet ASN capability, then the AS numbers in the AS_PATH and AGGREGATOR attributes are always encoded as 4-byte values in the UPDATE messages they send to each other. These UPDATE messages should not contain the AS4_PATH and AS4_AGGREGATOR path attributes.
If one of the routers involved in a session announces the 4-octet ASN capability and the other one does not, then the AS numbers in the AS_PATH and AGGREGATOR attributes are encoded as 2-byte values in the UPDATE messages they send to each other.
When a 7450 ESS, 7750 SR, or 7950 XRS router advertises a route to a peer that did not announce the 4-octet ASN capability.
If there are any AS numbers in the AS_PATH attribute that cannot be represented using 2 bytes (because they have a value greater than 65535) they are substituted with the special value 23456 (AS_TRANS) and an AS4_PATH attribute is added to the route if it is not already present. The AS4_PATH attribute has the same encoding as the AS_PATH attribute that would be sent to a 4-octet ASN capable router (that is, each AS number is encoded using 4 octets) but it does not carry segments of type AS_CONFED_SEQUENCE or AS_CONFED_SET.
If the AS number in the AGGREGATOR attribute cannot be represented using 2 bytes (because its value is greater than 65535) it is substituted with the special value 23456 and as AS4_AGGREGATOR attribute is added to the route if it is not already present. The AS4_AGGREGATOR is the same as the AGGREGATOR attribute that would be sent to a 4-octet ASN capable router (that is, the AS number is encoded using 4 octets).
When a 7450 ESS, 7750 SR, or 7950 XRS router receives a route with an AS4_PATH attribute it attempts to reconstruct the full AS path from the AS4_PATH and AS_PATH attributes, regardless of whether the 4byte ASN is disabled or not. The reconstructed path is the AS path displayed in BGP show commands. If the length of the received AS4_PATH is N and the length of the received AS_PATH is N+t, then the reconstructed AS path contains the t leading elements of the AS_PATH followed by all the elements in the AS4_PATH.
Next-hop
The NEXT_HOP attribute indicates the IPv4 address of the BGP router that is the next-hop to reach the IPv4 prefixes in the NLRI field. If the Update message is advertising routes other than IPv4 unicast routes the next-hop of these routes is encoded in the MP_REACH_NLRI attribute. For more details, see Multi-protocol BGP attributes.
The rules for deciding what next-hop address types to accept in a received BGP route and what next-hop address types to advertise as a BGP next-hop are address family dependent. The following sections summarize the key details.
Unlabeled IPv4 unicast routes
By default, IPv4 routes are advertised with IPv4 next-hops but on IPv6-TCP transport sessions they can be advertised with IPv6 next-hops if the advertise-ipv6-next-hops command (with the IPv4 option) applies to the session. To receive IPv4 routes with IPv6 next-hop addresses from a peer, the extended-nh-encoding command (with the IPv4 option) must be applied to the session. This advertises the corresponding RFC 5549, Advertising IPv4 Network Layer Reachability Information with an IPv6 Next Hop, capability to the peer.
Whenever next-hop-self applies to an IPv4 route, the next hop is set as follows.
If the peer whose routes are being advertised is an IPv4 transport peer (in other words, the neighbor address is IPv4), the BGP next-hop is the IPv4 local address used to setup the session.
If the peer toward which the routes are being advertised is an IPv6 transport peer (in other words, the neighbor address is IPv6), and the advertise-ipv6-next-hops command (with the ipv4 option) applies to the session, and the peer toward which the routes are being advertised opened the session by announcing an Extended NH Encoding capability for AFI =1, SAFI = 1 and next-hop AFI = 2, then the BGP next-hop is the IPv6 local address used to setup the session. Otherwise, for all other cases, the BGP next-hop is the IPv4 address of the system interface. If the system interface does not have an IPv4 address, the route is not advertised unless an export policy sets a valid IPv4 next-hop.
When an IPv4 BGP route is advertised to an EBGP peer, next-hop-self always applies except if the third-party-nexthop command is applied. Configuring third-party-nexthop allows an IPv4 route received from one EBGP peer to be advertised to another EBGP that is in the same IP subnet with an unchanged BGP next-hop.
When an IPv4 BGP route is re-advertised to an IBGP or confederation EBGP peer, the advertising router does not modify the BGP next-hop unless one of the following applies.
The BGP next-hop-self command is applied to the IBGP or confederation EBGP peer. This causes next-hop-self to be applied to all IPv4 routes advertised to the peer, regardless of the peer type from which they were received (IBGP, confederation-EBGP, or EBGP).
IPv4 routes are matched and accepted by a route policy entry, and this entry has a next-hop-self action. This applies next-hop-self as described above to only those routes matched by the policy entry.
IPv4 routes are matched and accepted by route policy entry, and this entry has a next-hop IP address action. This changes the BGP next-hop of only the matched routes to the IP address, if the IP address is an IPv4 address or an IPv6 address and the necessary conditions exist. The advertise-ipv6-next-hops command is configured appropriately and the peer opened the session with the correct RFC 5549 capability.
When an IPv4 BGP route is locally originated and advertised to an IBGP or confederation EBGP peer, the BGP next-hop is, by default, copied from the next hop of the route that was imported into BGP, with specified exceptions (for example, black-hole next-hop). When a static route with indirect next hop is re-advertised as a BGP route, the BGP next-hop is a copy of the indirect address. However, with route table import policies, BGP can be instructed to take the resolved next hop of the static route as the BGP next-hop address.
Unlabeled IPv6 unicast routes
SR OS routers never send or receive IPv6 routes with 32-bit IPv4 next-hop addresses.
When an IPv6 BGP route is advertised to an EBGP peer, next-hop-self always applies (except if the third-party-nexthop command is applied, as described in the following note). Next-hop-self results in one of the following outcomes.
If the EBGP session uses IPv4 transport, the BGP next-hop encodes the local-address used for setup of the session as an IPv4-compatible IPv6 address (all zeros in the first 96 bits followed by the 32 bit IPv4 local-address).
If the EBGP session uses IPv6 transport, the BGP next-hop is the local-address used to setup the session and this cannot be overridden, even by BGP export policy.
When an IPv6 BGP route is re-advertised to an IBGP or confederation-EBGP peer, the advertising router does not modify the BGP next-hop by default; however, this can be changed as follows.
If the BGP next-hop-self command is applied to the IBGP peer or confederation-EBGP peer, then this changes the BGP next-hop to the local-address used to setup the session (if the transport to the peer is IPv6) or to an IPv4-compatible IPv6 address derived from the IPv4 local-address used to setup the session (if the transport to the peer is IPv4). This command applies to all routes advertised to the peer, regardless of the peer type from which they were received (IBGP, confed-EBGP, or EBGP).
If IPv6 routes are matched and accepted by an export policy applied to an IBGP or confederation-EBGP session, and the matching policy entry has a next-hop-self action, this changes the BGP next-hop of only the matched routes to the local-address used to setup the session (if the transport to the peer is IPv6) or to an IPv4-compatible IPv6 address derived from the IPv4 local-address used to setup the session (if the transport to the peer is IPv4).
If IPv6 routes are matched and accepted by an export policy applied to an IBGP or confederation-EBGP session, and the matching policy entry has a next-hop IP address action, this changes the BGP next-hop of only the matched routes to the IP address, if the IP address is an IPv6 address. If the IP address is an IPv4 address the matched routes are treated as though they were rejected by the policy entry.
When an IPv6 BGP route is locally originated and advertised to an IBGP or confederation- EBGP peer, the BGP next-hop is, by default, copied from the next-hop of the route that was imported into BGP, with specified exceptions (for example, black-hole next-hop). When a static route with indirect next-hop is re-advertised as a BGP route, the BGP next-hop is a copy of the indirect address, however with route-table-import policies BGP can be instructed to take the resolved next-hop of the static route as the BGP next-hop address.
VPN-IPv4 routes
SR OS routers can send and receive VPN-IPv4 routes with IPv4 next-hops. They can also be configured (using the extended-nh-encoding command) to receive VPN-IPv4 routes with IPv6 next-hop addresses from selected BGP peers by signaling the corresponding Extended NH Encoding BGP capability to those peers during session setup. If the capability is not advertised to a peer, such routes are not accepted from that peer. Also, if the SR OS router does not receive an Extended NH Encoding capability advertisement for [NLRI AFI=1, NLRI SAFI=128, next-hop AFI=2] from a peer, it does not advertise VPN-IPv4 routes with IPv6 next-hops to that peer.
When a VPN-IPv4 BGP route is advertised to an EBGP peer, the next-hop-self command applies in the following cases:
-
The following command is configured:
- MD-CLI
configure router bgp inter-as-vpn - classic
CLI
configure router bgp enable-inter-as-vpn
- MD-CLI
-
The following command and the next-hop-self command are configured toward the EBGP peer:
- MD-CLI
configure router bgp subconfed-vpn-forwarding - classic
CLI
configure router bgp enable-subconfed-vpn-forwarding
- MD-CLI
Otherwise, there is no change to the next-hop and the next-hop-self command results in one of the following outcomes:
If the EBGP session uses IPv4 transport, the BGP next-hop is taken from the value of the local address used to set up the session.
If the EBGP peer has opened an IPv6-transport session by advertising an extended NH encoding capability with (NLRI AFI=1, NLRI SAFI=128, next-hop AFI=2) and, in the configuration of the local router, the session is associated with an advertise-ipv6-next-hops vpn-ipv4 command, then the BGP next-hop is set to the value of the IPv6 local address used to set up the session. Otherwise, the BGP next-hop is set to the IPv4 address of the system interface.
If inter-AS-VPN is enabled, the next-hop-self command applies automatically if a VPN-IPv4 BGP route is received from an EBGP peer and readvertised to an IBGP or confederation-EBGP peer. If the inter-AS-VPN is not enabled, but subconfederation VPN forwarding is enabled, the next-hop-self command can be set manually toward any IBGP or confederation-EBGP peer with the same label-swap forwarding behavior as provided by the inter-AS-VPN command. In either case, the next-hop-self command results in one of the following outcomes.
If the IBGP or confederation-EBGP session uses IPv4 transport, then the BGP next-hop is taken from the value of the local address used to set up the session.
If the IBGP or confederation-EBGP peer has opened an IPv6-transport session by advertising an extended NH encoding capability with (NLRI AFI=1, NLRI SAFI=128, next-hop AFI=2) and, in the configuration of the local router, the session is associated with an advertise-ipv6-next-hops vpn-ipv4 command, then the BGP next-hop is set to the value of the IPv6 local address used to set up the session. Otherwise, the BGP next-hop is set to the IPv4 address of the system interface.
When a VPN-IPv4 BGP route is reflected from one IBGP peer to another IBGP peer, the RR does not modify the next-hop by default. However, if the next-hop-self command is applied to the IBGP peer receiving the route and the following command is enabled, a next-hop-self and label swap behavior can be provided:
- MD-CLI
configure router bgp rr-vpn-forwarding - classic
CLI
configure router bgp enable-rr-vpn-forwarding
Alternatively, the same behavior can be achieved by configuring the following command and setting the next-hop-self command toward the targeted IBGP peer.
- MD-CLI
configure router bgp subconfed-vpn-forwarding - classic
CLI
enable-subconfed-vpn-forwarding
In either case, next-hop-self results in one of the following outcomes:
If the IBGP session receiving the reflected route uses IPv4 transport, the BGP next-hop is taken from the value of the local address used to set up the session.
If the IBGP session receiving the reflected route has opened an IPv6-transport session by advertising an extended NH encoding capability with (NLRI AFI=1, NLRI SAFI=128, next-hop AFI=2) and, in the configuration of the local router, the session is associated with an advertise-ipv6-next-hops vpn-ipv4 command, then the BGP next-hop is set to the value of the IPv6 local address used to set up the session. Otherwise, the BGP next-hop is set to the IPv4 address of the system interface.
When a VPN-IPv4 BGP route is reflected from one IBGP peer to another IBGP peer, the following command is configured, and the VPN-IPv4 route is matched and accepted by an export policy entry with a next-hop IP address action, the BGP next-hop of the matched routes changes to the next-hop IP address:
- MD-CLI
configure router bgp rr-vpn-forwarding - classic
CLI
configure router bgp enable-rr-vpn-forwarding
The exception to this is if the next-hop IP address is an IPv6 address and the receiving IBGP peer did not advertise an extended NH encoding capability with (NLRI AFI=1, NLRI SAFI=128, next-hop AFI=2), or in the configuration of the local router, the session is not associated with an advertise-ipv6-next-hops vpn-ipv4 command. In this case, the route is treated as though it was rejected by the policy entry.
VPN-IPv6 routes
SR OS routers never send or receive VPN-IPv6 routes with 32-bit IPv4 next-hop addresses.
When a VPN-IPv6 BGP route is advertised to an EBGP peer, the next-hop-self command applies in the following cases:
-
The following command is configured:
- MD-CLI
configure router bgp inter-as-vpn - classic
CLI
configure router bgp enable-inter-as-vpn
- MD-CLI
-
The following command and the next-hop-self command are configured toward the EBGP peer:
- MD-CLI
configure router bgp subconfed-vpn-forwarding - classic
CLI
configure router bgp enable-subconfed-vpn-forwarding
- MD-CLI
Otherwise, there is no change to the next-hop. The next-hop-self command results in one of the following outcomes:
If the EBGP session uses IPv4 transport, then the BGP next-hop is set to the IPv4 local address used to set up the session but encoded as an IPv4-mapped IPv6 address (for example, with the IPv4 address in the least significant 32 bits of a ::FFFF/96 prefix).
If the EBGP session uses IPv6 transport and it is associated with an advertise-ipv6-next-hops vpn-ipv6 command, the BGP next-hop is set to the value of the IPv6 local address used to set up the session. Otherwise, the BGP next-hop is set to the IPv4 address of the system interface encoded as an IPv4-mapped IPv6 address (for example, with the IPv4 address in the least significant 32 bits of a ::FFFF/96 prefix).
If inter-AS-VPN is enabled, the next-hop-self command applies automatically if a VPN-IPv6 BGP route is received from an EBGP peer and re-advertised to an IBGP or confederation-EBGP peer. If inter-AS-VPN is not enabled, but the subconfederation VPN forwarding is enabled, the next-hop can be set manually toward any IBGP or confederation EBGP peer, with the same label-swap forwarding behavior as provided by the inter-AS-VPN configuration. In either case, the next-hop-self command results in one of the following outcomes.
If the IBGP or confederation EBGP session uses IPv4 transport, then the BGP next-hop is set to the IPv4 local address used to set up the session but encoded as an IPv4-mapped IPv6 address (for example, with the IPv4 address in the least significant 32 bits of a ::FFFF/96 prefix).
If the IBGP or confederation EBGP session uses IPv6 transport and it is associated with an advertise-ipv6-next-hops vpn-ipv6 command, the BGP next-hop is set to the value of the IPv6 local address used to set up the session. Otherwise, the BGP next-hop is set to the IPv4 address of the system interface encoded as an IPv4-mapped IPv6 address (for example, with the IPv4 address in the least significant 32 bits of a ::FFFF/96 prefix).
When a VPN-IPv6 BGP route is reflected from one IBGP peer to another IBGP peer, the RR does not modify the next-hop by default. However, if the next-hop-self command is applied to the IBGP peer receiving the route and the following command is configured, a next-hop-self command and label swap behavior can be provided:
- MD-CLI
configure router bgp rr-vpn-forwarding - classic
CLI
configure router bgp enable-rr-vpn-forwarding
Alternatively, the same behavior can be achieved by configuring the following command and setting the next-hop-self command toward the targeted IBGP peer:
- MD-CLI
configure router bgp subconfed-vpn-forwarding - classic
CLI
configure router bgp enable-subconfed-vpn-forwarding
In either case, the next-hop-self command results in one of the following outcomes:
If the IBGP session receiving the reflected route uses IPv4 transport then the BGP next-hop is set to the IPv4 local-address used to set up the session but encoded as an IPv4-mapped IPv6 address (for example, with the IPv4 address in the least significant 32 bits of a ::FFFF/96 prefix).
If the IBGP session receiving the reflected route uses IPv6 transport and it is associated with an advertise-ipv6-next-hops vpn-ipv6 command, the BGP next-hop is set to the value of the IPv6 local address used for set up of the session. Otherwise, the BGP next-hop is set to the IPv4 address of the system interface encoded as an IPv4-mapped IPv6 address (for example, with the IPv4 address in the least significant 32 bits of a ::FFFF/96 prefix).
When a VPN-IPv6 BGP route is reflected from one IBGP peer to another IBGP peer, the following command is configured, and the VPN-IPv6 route is matched and accepted by an export policy entry with a next-hop IP address action, the BGP next-hop of the matched routes changes to the next-hop IP address, if the IP address is specified as a 128-bit IPv6 address. If the IP address is specified as a 32-bit IPv4 address, the BGP next-hop changes to an IPv4-mapped IPv6 address encoding IP address.
- MD-CLI
configure router bgp rr-vpn-forwarding - classic
CLI
configure router bgp enable-rr-vpn-forwarding
Label-IPv4 routes
SR OS routers can always send and receive label-IPv4 routes with IPv4 next-hops. They can also be configured (using the extended-nh-encoding command) to receive label-IPv4 routes with IPv6 next-hop addresses from selected BGP peers by signaling the corresponding Extended NH Encoding BGP capability to those peers during session setup. If the capability is not advertised to a peer then such routes are not accepted from that peer. Also, if the SR OS router does not receive an Extended NH Encoding capability advertisement for [NLRI AFI=1, NLRI SAFI=4, next-hop AFI=2] from a peer then it is not advertise label-IPv4 routes with IPv6 next-hops to that peer.
When a label-IPv4 BGP route is advertised to an EBGP peer, next-hop-self applies unless the EBGP session has next-hop-unchanged enabled for the label-ipv4 address family. Next-hop-self results in one of the following outcomes.
If the EBGP session uses IPv4 transport, then the BGP next-hop is taken from the value of the local-address used to setup the session.
If the EBGP peer opened an IPv6-transport session by advertising an extended NH encoding capability with (NLRI AFI=1, NLRI SAFI=4, next-hop AFI=2) AND, in the configuration of the local router, the session is associated with an advertise-ipv6-next-hops label-ipv4 command, then the BGP next-hop is set to the value of the IPv6 local-address used for setup of the session. Otherwise, the BGP next-hop is set to the IPv4 address of the system interface.
When a label-IPv4 BGP route is received from an EBGP peer and re-advertised to an IBGP or confederation-EBGP peer, next-hop-self applies unless the IBGP or confederation EBGP session has next-hop-unchanged enabled for the label-ipv4 address family. Next-hop-self results in one of the following outcomes.
If the IBGP or confederation EBGP session uses IPv4 transport, then the BGP next-hop is taken from the value of the local-address used to setup the session.
If the IBGP or confederation EBGP peer opened an IPv6-transport session by advertising an extended NH encoding capability with (NLRI AFI=1, NLRI SAFI=4, next-hop AFI=2) AND, in the configuration of the local router, the session is associated with an advertise-ipv6-next-hops label-ipv4 command then the BGP next-hop is set to the value of the IPv6 local-address used for setup of the session. Otherwise, the BGP next-hop is set to the IPv4 address of the system interface
When a label-IPv4 BGP route is reflected from one IBGP peer to another IBGP peer, the RR does not modify the next-hop by default. However, if the next-hop-self command is applied to the IBGP peer receiving the route, then this results in one of the following outcomes.
If the IBGP session receiving the reflected route uses IPv4 transport, then the BGP next-hop is taken from the value of the local-address used to setup the session.
If the IBGP session receiving the reflected route opened an IPv6-transport session by advertising an extended NH encoding capability with (NLRI AFI=1, NLRI SAFI=4, next-hop AFI=2) AND, in the configuration of the local router, the session is associated with an advertise-ipv6-next-hops label-ipv4 command then the BGP next-hop is set to the value of the IPv6 local-address used for setup of the session. Otherwise, the BGP next-hop is set to the IPv4 address of the system interface.
When a label-IPv4 BGP route is reflected from one IBGP peer to another IBGP peer and the label-IPv4 route is matched and accepted by an export policy entry with a next-hop IP-address action, this changes the BGP next-hop of the matched routes to the IP address, except if the IP address is an IPv6 address and the receiving IBGP peer did not advertise an extended NH encoding capability with (NLRI AFI=1, NLRI SAFI=128, next-hop AFI=2) or, in the configuration of the local router, the session is not associated with an advertise-ipv6-next-hops label-ipv4 command. In this case, the route is treated as though it was rejected by the policy entry.
Label-IPv6 routes
SR OS routers never send or receive label-IPv6 routes with 32-bit IPv4 next-hop addresses.
When a label-IPv6 BGP route is advertised to an EBGP peer, the next-hop-self command applies unless the EBGP session has the next-hop-unchanged command enabled for the label-ipv6 address family. Using the next-hop-self command results in one of the following outcomes:
If the EBGP session uses IPv4 transport, then the BGP next-hop is taken from the value of the local address used to set up the session and encoded as an IPv4-mapped IPv6 address.
If the EBGP peer opened an IPv6 transport session and it is associated with an advertise-ipv6-next-hops label-ipv6 command then the BGP next-hop is set to the value of the IPv6 local address used for set up of the session. Otherwise, the BGP next-hop is set to the IPv4 address of the system interface encoded as an IPv4-mapped IPv6 address.
When a label-IPv6 BGP route is received from an EBGP peer and re-advertised to an IBGP or confederation EBGP peer, the next-hop-self command applies unless the IBGP or confederation EBGP session has the next-hop-unchanged command enabled for the label-IPv6 address family. Using the next-hop-self command results in one of the following:
If the IBGP or confederation EBGP session uses IPv4 transport, the BGP next-hop is taken from the value of the local address used to setup the session and encoded as an IPv4-mapped IPv6 address.
If the IBGP or confederation EBGP peer opened an IPv6 transport session and it is associated with an advertise-ipv6-next-hops label-ipv6 command, the BGP next-hop is set to the value of the IPv6 local address used for set up of the session. Otherwise, the BGP next-hop is set to the IPv4 address of the system interface encoded as an IPv4-mapped IPv6 address.
Next-hop resolution
To use a BGP route for forwarding, a BGP router must know how to reach the BGP next-hop of the route. The process of determining the local interface or tunnel used to reach the BGP next-hop is called next-hop resolution. This process depends on the type of route (the AFI/SAFI) and various configuration settings.
The following process applies to the next-hop resolution of IPv4 and IPv6 (unlabeled) unicast routes:
-
When an IPv4 or IPv6 route is received with an IPv4-mapped IPv6 address as a next hop, BGP next-hop resolution is based on the embedded IPv4 address, which is matched with either IPv4 routes or IPv4 tunnels, depending on the configuration. The IPv4-mapped IPv6 address is never interpreted as an IPv6 address and is not matched with IPv6 routes or IPv6 tunnels.
-
By default, BGP routes are ineligible to resolve a BGP next hop. Use the following command to enable the use of BGP routes to resolve BGP next hops.
configure router bgp next-hop-resolution use-bgp-routesA maximum of four levels of recursion are supported.
-
The LPM route matching the BGP next-hop address is the only route considered for resolving the next hop. If the LPM route is ineligible to resolve the next hop, the BGP route is unresolved.
-
A VPN-leak route leaked from another router instance is eligible to resolve a BGP next hop, provided that it corresponds to a static route with direct next hops.
-
If the LPM route is rejected by the next-hop resolution policy configured by the user, the BGP next hop is unresolved, and all routes with that next hop are considered invalid and not advertised to peers.
-
BGP shortcuts are described in Next-hop resolution of BGP unlabeled IPv4 unicast routes to tunnels.
The following process applies to the next-hop resolution of VPN-IPv4 and VPN-IPv6 routes:
-
When an VPN-IPv4 or VPN-IPv6 route is received with an IPv4-mapped IPv6 address as next-hop, BGP next-hop resolution is based on the embedded IPv4 address and this IPv4 address is matched to IPv4 routes and/or IPv4 tunnels, depending on configuration. The IPv4-mapped IPv6 address is never interpreted as an IPv6 address to be compared to IPv6 routes or IPv6 tunnels.
-
If the VPN-IP route is imported into a VPRN, the next-hop is resolved to a tunnel based on the auto-bind-tunnel configuration of the importing VPRN. For more information, see the 7450 ESS, 7750 SR, 7950 XRS, and VSR Layer 3 Services Guide: IES and VPRN.
-
If the next-hop entry in the tunnel-table that resolves the VPN-IP route is rejected by the user-configured next-hop-resolution vpn-family-policy, the BGP next hop is unresolved and all the VPN-IP routes with that next hop are considered invalid.
-
If the VPN-IP route is received from an IBGP or EBGP peer, and the router is a next-hop-self RR or a model-B ASBR, the order of resolution is as follows:
-
local (interface) route
-
longest prefix-match static route, excluding default static routes, but only if allow-static is configured
-
tunnel, based on the transport-tunnel resolution-filter options for family VPN; for more information, see Next-hop resolution of BGP labeled routes to tunnels
-
The following process applies to the next-hop resolution of EVPN routes:
-
If an EVPN ES route is imported, the next hop is resolved to any tunnel in the tunnel-table. If there is no entry matching the next hop in the tunnel-table, a route matching the next hop in the route-table also resolves the next hop.
-
If the resolving route in the tunnel-table or the route-table is rejected by a user-configured next-hop-resolution vpn-family-policy, the ES route's next hop is unresolved.
-
If the ES route next hop is unresolved, the PE that advertised the route is not considered as candidate for Designated Forwarder (DF) election.
-
-
The imported AD per-ES and AD per-EVI routes are always shown as resolved and valid, irrespective of the next-hop resolution or the configuration of a next-hop-resolution vpn-family-policy.
-
With DF election, the router always considers the advertising PE a valid candidate, even if the AD routes next hops are unresolved.
-
However, if the AD per-EVI next hop is unresolved, EVPN traffic is not sent to the advertising PE. This is true for EVPN VPWS or multi-homing aliasing or backup procedures.
-
A matching tunnel-table entry can resolve the next-hop of an AD per-EVI route in an EVPN-MPLS service. A route-table entry (other than a shortcut) can resolve the AD per-EVI route next-hop in an EVPN-VXLAN service.
-
-
For any other imported EVPN service route, including IP prefix, IPv6 prefix, MAC/IP, Inclusive Multicast (IMET) and Selective Multicast (SMET) routes, the next hop is resolved as follows.
-
In EVPN-MPLS services, the next hop is resolved to a tunnel based on the auto-bind-tunnel configuration of the importing service.
-
In EVPN-VXLAN services, the next hop is resolved to a route in the route-table. That route cannot be a shortcut route.
-
If the next-hop entry in the tunnel-table or route-table that resolves the EVPN service route is rejected by the user-configured next-hop-resolution vpn-family-policy, the BGP next hop is unresolved and all the EVPN routes with that next hop are considered invalid.
-
The following process applies to the next-hop resolution of label-unicast IPv4 and label-unicast IPv6 routes:
-
When a BGP-LU route is received with an IPv4-mapped IPv6 address as the next-hop, BGP next-hop resolution is based on the embedded IPv4 address and this IPv4 address is matched to IPv4 routes or IPv4 tunnels, depending on the configuration. The IPv4-mapped IPv6 address is never interpreted as an IPv6 address to be compared to IPv6 routes or IPv6 tunnels.
-
If the BGP-LU route is received by a control-plane-only RR and the following commands are configured:
- MD-CLI
configure router bgp route-table-install false configure router bgp next-hop-resolution labeled-routes rr-use-route-table - classic
CLI
configure router bgp disable-route-table-install configure router bgp next-hop-resolution labeled-routes rr-use-route-tableIn this case the order of the resolution is as follows:
-
the local route
-
the longest prefix-match static route, excluding default static routes
Use this route to resolve the BGP next-hop if it is a static route with blackhole next-hop. For other types of static routes, use this route to resolve the next-hop only if allow-static is configured. If it is another type of static route, use it to resolve the next-hop only if allow-static is configured.
-
the longest prefix-match IGP route
-
- MD-CLI
-
If a label-unicast IPv4 route or label-unicast IPv6 route with a label (other than explicit-null) is received from an IBGP or EBGP peer and the router is not an RR with the rr-use-route-table command configured, the order of resolution is as follows:
-
the local route
-
the longest prefix-match static route, excluding default static routes
Use this route to resolve the BGP next-hop if it is a static route with a blackhole next-hop. If it is another type of static route, use it to resolve the next-hop only if allow-static is configured.
-
a tunnel, based on the transport-tunnel resolution-filter options for family label-ipv4 or label-ipv6 (depending on the situation); for more information, see Next-hop resolution of BGP labeled routes to tunnels
-
-
If a label-unicast IPv6 route with an IPv6 explicit-null label is received from an IBGP or EBGP peer and the router is not an RR with the rr-use-route-table command configured, the order of resolution is as follows:
-
the local route
-
the longest prefix-match static route, excluding default static routes
Use this route to resolve the BGP next-hop if it is a static route with a blackhole next-hop. If it is another type of static route, use it to resolve the next-hop only if allow-static is configured.
-
a tunnel, based on the transport-tunnel resolution-filter options for family label-ipv4; for more information, see Next-hop resolution of BGP labeled routes to tunnels
-
if the following command is enabled and the longest prefix length route that matches the next-hop is a BGP IPv4 unlabeled, BGP IPv6 unlabeled, or other 6PE route with an explicit-null label.
configure router bgp next-hop-resolution labeled-routes use-bgp-routes label-ipv6-explicit-nullUse that route, subject to the following conditions:
-
the resolving route cannot be a leaked route
-
an unlabeled IPv4 route or IPv6 route is ineligible to resolve the next-hop of a label-unicast IPv6 route if the unlabeled route has any of its own BGP next-hops resolved by an IGP route or a 6over4 route
-
the label-unicast IPv6 route can be recursively resolved by other label-unicast IPv6 routes with explicit-null so that the final route has up to four levels of recursion
-
-
Next-hop resolution of BGP unlabeled IPv4 unicast routes to tunnels
To enable the next-hop resolution of unlabeled IPv4 routes using tunnels in the tunnel table of the router, use the commands in the following context to configure the IPv4 family.
configure router bgp next-hop-resolution shortcut-tunnel familyThe family context provides commands to specify the resolution mode (any, disabled or filter) and set tunnel types that are eligible for use when filter mode is selected.
If the resolution mode is disabled, the next hops of unlabeled IPv4 routes can only be resolved by route table lookup.
If there are multiple tunnels in the tunnel table that are allowed by the any or filter resolution modes and that can resolve the BGP next-hop, the selection of the resolving tunnel is determined by factors such as route color, admin-tag-policy, tunnel-table preference, and LDP FEC prefix length.
If the disallow-igp command is enabled and no resolving tunnel is found in the tunnel table, no attempt is made to resolve the IPv4 BGP route using route table lookup.
The available tunneling options for IPv4 shortcuts are as follows:
BGP
This refers to IPv4 and IPv6 tunnels created by receiving BGP label-unicast IPv4 routes for /32 IPv4 prefixes and BGP label-unicast IPv6 routes for /128 IPv6 prefixes. The installation of BGP-LU IPv6 tunnels in TTM requires configuration of the following command:
- MD-CLI
configure router bgp label-allocation label-ipv6 explicit-null false - classic
CLI
configure router bgp label-allocation label-ipv6 disable-explicit-null
- MD-CLI
LDP
This refers to LDP FEC prefixes imported into the tunnel table. For resolution purposes, BGP selects the LDP FEC that is the longest-prefix-match (LPM) of the BGP next-hop address.
RSVP
This refers to RSVP tunnels in tunnel-table. This option allows BGP to use the best metric RSVP LSP to the address of the BGP next-hop. This address can correspond to the system interface or to another loopback interface of the remote BGP router. In the case of multiple RSVP LSPs with the same lowest metric, BGP selects the LSP with the lowest tunnel ID.
SR ISIS
This refers to segment routing tunnels (shortest path) to destinations reachable by the IS-IS protocol. This option allows BGP to use the segment routing tunnel in tunnel-table submitted by the lowest preference IS-IS instance or, in case of a tie, the lowest numbered IS-IS instance.
SR OSPF
This refers to segment routing tunnels (shortest path) to destinations reachable by the OSPF protocol. This option allows BGP to use the segment routing tunnel in the tunnel table submitted by the lowest preference OSPF instance or (in case of a tie) the lowest numbered OSPF instance.
SR policy
This refers to segment routing policies that are statically configured in the local router or learned via BGP routes (AFI 1/SAFI 73). For BGP to resolve the next-hop of an IPv4 route using an SR policy, the highest numbered color-extended community attached to the IPv4 route must match the color of the SR policy. Also if the CO bits of this color-extended community have the value 00 the BGP next-hop of the route must exactly match the endpoint of the SR policy.
SR TE
This refers to traffic engineered (TE) segment routing tunnels. This option allows BGP to use the best metric SR-TE tunnel to the address of the BGP next-hop. In the case of multiple SR-TE tunnels with the same lowest metric, BGP selects the tunnel with the lowest tunnel ID.
Next-hop resolution of BGP unlabeled IPv6 unicast routes to tunnels
To enable the next-hop resolution of unlabeled IPv6 routes using tunnels in the tunnel-table of the router, use the commands in the following context to configure the IPv6 family.
configure router bgp next-hop-resolution shortcut-tunnelIf the next-hop of the IPv6 BGP route contains an IPv4-mapped IPv6 address, the shortcut-tunnel configuration applies to the use of IPv4 tunnels and IPv4 routes that match the embedded IPv4 address in the BGP next-hop. If the BGP next-hop is any other IPv6 address the shortcut-tunnel configuration applies to the use of IPv6 tunnels and IPv6 routes that match the full address of the BGP next-hop.
The family ipv6 context provides commands to specify the resolution mode (any, disabled or filter) and the set of tunnel types that are eligible for use if the filter mode is selected.
If there are multiple tunnels in tunnel-table that are allowed by the any or filter resolution modes and that can resolve the BGP next-hop, the selection of the resolving tunnel is determined by factors such as route color, admin-tag-policy, tunnel-table preference, and LDP FEC prefix length.
If the resolution mode is set to disabled, the next-hops of unlabeled IPv6 routes can only be resolved by route table lookup.
If disallow-igp is enabled and no resolving tunnel is found in the tunnel table, no attempt is made to resolve the IPv6 BGP route using route table lookup.
The available tunneling options for IPv6 BGP routes with IPv4-mapped IPv6 next-hops are as follows:
BGP
This refers to IPv4 tunnels created by receiving BGP label-unicast IPv4 routes for /32 IPv4 prefixes.
LDP
This refers to /32 and shorter length LDP FEC prefixes imported into the tunnel table. For resolution purposes, BGP selects the LDP FEC that is the longest-prefix-match (LPM) of the BGP next-hop address.
RSVP
This refers to RSVP tunnels in tunnel-table. This option allows BGP to use the best metric RSVP LSP to the address of the BGP next-hop. This address can correspond to the system interface or to another loopback interface of the remote BGP router. In the case of multiple RSVP LSPs with the same lowest metric, BGP selects the LSP with the lowest tunnel ID.
SR ISIS
This refers to segment routing tunnels (shortest path) to destinations reachable by the IS-IS protocol. This option allows BGP to use the segment routing tunnel in tunnel-table submitted by the lowest preference IS-IS instance or (in case of a tie) the lowest numbered IS-IS instance.
SR OSPF
This refers to segment routing tunnels (shortest path) to destinations reachable by the OSPF protocol. This option allows BGP to use the segment routing tunnel in tunnel-table submitted by the lowest preference OSPF instance or (in case of a tie) the lowest numbered OSPF instance.
SR policy
This refers to segment routing policies that are statically configured in the local router or learned via BGP routes (AFI 1/SAFI 73). For BGP to resolve the next-hop of an IPv4 route using an SR policy the highest numbered color-extended community attached to the IPv4 route must match the color of the SR policy and if the CO bits of this color -extended community have the value 00 the BGP next-hop of the route must exactly match the endpoint of the SR policy.
SR TE
This refers to TE segment routing tunnels. This option allows BGP to use the best metric SR-TE tunnel to the address of the BGP next-hop. In the case of multiple SR-TE tunnels with the same lowest metric, BGP selects the tunnel with the lowest tunnel ID.
Next-hop resolution of BGP labeled routes to tunnels
Use the commands in the following context to configure next-hop resolution of BGP labeled routes.
configure router bgp next-hop-res labeled-routes transport-tunnelThe transport-tunnel context provides separate control for the different types of BGP label routes: label-IPv4, label-IPv6, and VPN routes (which includes both VPN-IPv4 and VPN-IPv6 routes). By default, all labeled routes resolve to LDP (even if the preceding CLI commands are not configured in the system).
If the resolution command option is set to disabled, the default binding to LDP tunnels resumes. If the resolution command option is set to any, the supported tunnel type selection is based on TTM preference. The order of preference of TTM tunnels is: RSVP, SR-TE, LDP, segment routing OSPF, segment routing IS-IS, and UDP.
The rsvp command instructs BGP to search for the best metric RSVP LSP to the address of the BGP next-hop. The address can correspond to the system interface or to another loopback used by the BGP instance on the remote node. The LSP metric is provided by MPLS in the tunnel table. In the case of multiple RSVP LSPs with the same lowest metric, BGP selects the LSP with the lowest tunnel ID.
The ldp command instructs BGP to search for an LDP LSP with a FEC prefix corresponding to the address of the BGP next-hop.
The bgp command instructs BGP to search for a BGP tunnel in TTM with a prefix matching the address of the BGP next-hop. A label-unicast IPv4 route cannot be resolved by another label-unicast IPv4 or IPv6 route. A label-unicast IPv6 route cannot be resolved by another label-unicast IPv6 route, but it can be resolved by a label-unicast IPv4 route.
When the sr-isis or sr-ospf option is enabled, an SR tunnel to the BGP next-hop is selected in the TTM from the lowest preference IS-IS or OSPF instance. If many instances have the same lowest preference, the lowest numbered IS-IS or OSPF instance is chosen.
The sr-te launches a search for the best metric SR-TE LSP to the address of the BGP next-hop. The LSP metric is provided by MPLS in the tunnel table. In the case of multiple SR-TE LSPs with the same lowest metric, BGP selects the LSP with the lowest tunnel ID.
The udp command instructs BGP to look for an MPLSoUDP tunnel to the address of the BGP next-hop.
If one or more explicit tunnel types are specified using the resolution-filter command, only these tunnel types are selected again following the TTM preference. The resolution command must be set to filter to activate the list of tunnel types configured under the resolution-filter command context.
Next-hop tracking
In SR OS next-hop resolution is not a one-time event. If the IP route or tunnel that was used to resolve a BGP next-hop is withdrawn because of a failure or configuration change an attempt is made to re-resolve the BGP next-hop using the next-best route or tunnel. If there are no more eligible routes or tunnels to resolve the BGP next-hop then the BGP next-hop becomes unresolved. The continual process of monitoring and reacting to resolving route/tunnel changes is called next-hop tracking. In SR OS next-hop tracking is completely event driven as opposed to timer driven; this provides the best possible convergence performance.
Next-hop indirection
SR OS supports next-hop indirection for most types of BGP routes. Next-hop indirection means BGP next-hops are logically separated from resolved next-hops in the forwarding plane (IOMs). This separation allows routes that share the same BGP next-hops to be grouped so that when there is a change to the way a BGP next-hop is resolved only one forwarding plane update is needed, as opposed to one update for every route in the group. The convergence time after the next-hop resolution change is uniform and not linear with the number of prefixes; in other words, the next-hop indirection is a technology that supports Prefix Independent Convergence (PIC). SR OS uses next-hop indirection whenever possible; there is no option to disable the functionality.
Entropy label for RFC 8277 BGP labeled routes
The router supports the MPLS entropy label, as specified in RFC 6790, on RFC 8277 BGP labeled routes. LSR nodes in a network can load-balance labeled packets in a more granular way than by hashing on the standard label stack. For more information, see the 7450 ESS, 7750 SR, 7950 XRS, and VSR MPLS Guide.
Entropy Label Capability (ELC) signaling is not supported for labeled routes representing BGP tunnels. Instead, ELC is configured at the head end LER using the following command.
configure router bgp override-tunnel-elcThis command causes the router to ignore any advertisements for ELC that may or may not be received from the network, and instead to assume that the whole domain supports entropy labels.
MED
The Multi-Exit Discriminator (MED) attribute is an optional attribute that can be added to routes advertised to an EBGP peer to influence the flow of inbound traffic to the AS. The MED attribute carries a 32-bit metric value. A lower metric is better than a higher metric when MED is compared by the BGP decision process. Unless the always-compare-med command is configured MED is compared only if the routes come from the same neighbor AS. By default, if a route is received without a MED attribute it is evaluated by the BGP decision process as though it had a MED containing the value 0, but this can be changed so that a missing MED attribute is handled the same as a MED with the maximum value. SR OS always removes the received MED attribute when advertising the route to an EBGP peer.
Deterministic MED
Deterministic MED is an optional enhancement to the BGP decision process that causes BGP to group paths that are equal up to the MED comparison step based on the neighbor AS. BGP compares the best path from each group to arrive at the overall best path. This change to the BGP decision process makes best path selection completely deterministic in all cases. Without deterministic-med, the overall best path selection is sometimes dependent on the order of route arrival because of the rule that MED cannot be compared in routes from different neighbor AS.
Local preference
The LOCAL_PREF attribute is a well-known attribute that should be included in every route advertised to an IBGP or confederation-EBGP peer. It is used to influence the flow of outbound traffic from the AS. The local preference is a 32-bit value and higher values are more preferred by the BGP decision process. The LOCAL_PREF attribute is not included in routes advertised to EBGP peers (if the attribute is received from an EBGP peer it is ignored).
In SR OS the default local preference is 100 but this can be changed with the local-preference command or using route policies. When a LOCAL_PREF attribute needs to be added to a route because it does not have one (for example, because it was received from an EBGP peer) the value is the configured or default local-preference unless overridden by policy.
Route aggregation path attributes
An aggregate route is a configured IP route that is activated and installed in the routing table when it has at least one contributing route. A route (R) contributes to an aggregate route (S1) if all of the following conditions are true:
the prefix length of (R) is greater than the prefix length of (S1)
the prefix bits of (R) match the prefix bits of (S1) up to the prefix length of (S1)
there is no other active aggregate route (S2) with a longer prefix length than (S1) that meets the previous two conditions
(R) is actively used for forwarding and is not an aggregate route
(R) is accepted by the route policy that is associated with (S1); if there is no configured route policy then (R1) is by default considered accepted
When an aggregate route is activated by a router, it is not installed in the forwarding table by default. In general though, it is advisable to specify a black-hole next-hop option for an aggregate route, so that when it is activated it is installed in the forwarding table with a black-hole next-hop; this avoids the possibility of creating a routing loop. SR OS also supports the option to program an aggregate route into the forwarding table with an indirect next-hop; in this case, packets matching the aggregate route but not a more-specific contributing route are forwarded toward the indirect next-hop instead of being discarded.
An active aggregate route can be advertised to a BGP peer (by exporting it into BGP) and this can avoid the need to advertise the more-specific contributing routes to the peer, reducing the number of routes in the peer AS and improving overall scalability. When a router advertises an aggregate route to a BGP peer the attributes in the route are set as follows.
The ATOMIC_AGGREGATE attribute is included in the route if at least one contributing route has the ATOMIC_AGGREGATE attribute or the aggregate route was formed without the as-set command option and at least one contributing route has a non-empty AS_PATH. The ATOMIC_AGGREGATE attribute indicates that some of the AS numbers present in the AS paths of the contributing routes are missing from the advertised AS_PATH.
The AGGREGATOR attribute is added to the route. This attribute encodes, by default, the global AS number (or confederation ID) and router ID (BGP identifier) of the router that formed the aggregate, but these values can be changed on a per aggregate route basis using the aggregator command option. The AS number in the AGGREGATOR attribute is either 2 bytes or 4 bytes (if the 4-octet ASN capability was announced by both peers). The router ID in the aggregate routes advertised to a particular set of peers can be set to 0.0.0.0 using the aggregator-id-zero command.
The BGP next-hop is set to the local-address used with the peer receiving the route regardless of the BGP next-hops of the contributing routes.
The ORIGIN attribute is based on the ORIGIN attributes of the contributing routes as described in RFC 4271.
The information in the AS_PATH attribute depends on the as-set option of the aggregate route.
If the as-set option is not specified the AS_PATH of the aggregate route starts as an empty AS path and has elements added per the description in AS path.
If the as-set option is specified and all the contributing routes have the same AS_PATH then the AS_PATH of the aggregate route starts with that common AS_PATH and has elements added per the description in AS path.
If the as-set option is specified and some of the contributing routes have different AS paths the AS_PATH of the aggregate route starts with an AS_SET and/or an AS_CONFED_SET and then adds elements per the description in AS path.
The COMMUNITY attribute contains all of the communities from all of the contributing routes unless the discard-component-communities command option is configured for the aggregate route. It also contains the communities associated directly with the aggregate route itself (up to 12 per aggregate route).
No MED attribute is included by default.
Note: SR OS does not require all the contributing routes to have the same MED value.
Community attributes
A BGP route can be associated with one or more communities. There are three kinds of BGP communities:
standard communities (each 4 bytes in length, all packed into a path attribute with type code 8)
extended communities (each 8 bytes in length, potentially many possible subtypes, all packed into a path attribute with type code 16)
large communities (each 12 bytes in length, all packet into a path attribute with type code 32)
Standard communities
In a standard community, the first two bytes usually encode the AS number of the administrative entity that assigned the value in the last two bytes. In SR OS, a standard community value is configured using the following format:
The colon is a required separator character. In route policy applications, multiple standard community values can be matched with a regular expression in the following format:
where regex1 and regex2 are two regular expressions that are evaluated one numerical digit at a time.
The following well-known standard communities are understood and acted upon accordingly by SR OS routers.
NO_EXPORT
When a route carries this community, it must not be advertised outside a confederation boundary (for example, to EBGP peers).
NO_ADVERTISE
When a route carries this community, it must not be advertised to any other BGP peer.
NO_EXPORT_SUBCONFED
When a route carries this community, it must not be advertised outside a member AS boundary (for example, to confed-EBGP peers or EBGP peers.
LLGR_STALE
When a route carries this community, it indicates that the route was propagated by a router that is a long-lived graceful restart helper and normally (in the absence of LLGR) the route would have been withdrawn.
NO_LLGR
When a route carries this community, it indicates that the route should not be retained and used past the normal graceful restart window of time.
BLACKHOLE
When a route carries this community, it indicates that the route should be installed into the FIB with a blackhole next-hop.
Standard communities can be added to or removed from BGP routes using BGP import and export policies. When a BGP route is locally originated by exporting a static or aggregate route into BGP, and the static or aggregate route has one or more standard communities, these community values are automatically added to the BGP route. This may affect the advertisement of the locally originated route if one of the well-known communities is associated with the static or aggregate route.
To remove all the standard communities from all routes advertised to a BGP peer, use the following command:
- MD-CLI
configure router bgp send-communities standard false - classic
CLI
configure router bgp disable-communities standard
Extended communities
Extended communities serve specialized roles. Each extended community is eight bytes. The first one or two bytes identifies the type or sub-type and the remaining six or seven bytes identify a value. Some of the more common extended communities supported by SR OS include:
Transitive 2-octet AS-specific
Route target (type 0x0002)
Route origin (type 0x0003)
OSPF domain ID (type 0x0005)
Source AS (type 0x0009)
L2VPN identifier (type 0x000A)
Non-transitive 2-octet AS-specific
Link bandwidth (0x4004)
Transitive 4-octet AS-specific
Route target (type 0x0202)
Route origin (type 0x0203)
OSPF domain ID (type 0x0205)
Source AS (type 0x0209)
Transitive IPv4-address-specific
Route target (type 0x0102)
Route origin (type 0x0103)
OSPF domain ID (type 0x0105)
L2VPN identifier (type 0x010A)
VRF route import (type 0x010B)
Transitive opaque
OSPF route type (type 0x0306)
-
Color extended community (type 0x030B)
Non-transitive opaque
BGP origin validation state (type 0x4300)
Transitive experimental
FlowSpec traffic rate (type 0x8006)
-
FlowSpec traffic action (type 0x8007)
-
FlowSpec redirect (type 0x8008)
-
FlowSpec traffic-remarking (0x8009)
-
Layer 2 info (type 0x800A)
Transitive FlowSpec
FlowSpec interface-set (type 0x0702)
Non-transitive FlowSpec
FlowSpec interface-set (type 0x4702)
Extended communities can be added to or removed from BGP routes using BGP import and export policies. When a BGP route is locally originated by exporting a static or aggregate route into BGP, and the static or aggregate route has one or more extended communities, these community values are automatically added to the BGP route.
To remove all the extended communities from all routes advertised to a BGP peer, use the following command:
- MD-CLI
configure router bgp send-communities extended false - classic
CLI
configure router bgp disable-communities extended
Large communities
Each large community is a 12-byte value, formed from the logical concatenation of three 4-octet values: a Global Administrator part, a Local Data part 1, and Local Data part 2. The Global Administrator is a four-octet namespace identifier, which should be an Autonomous System Number assigned by IANA. The Global Administrator field is intended to allow different Autonomous Systems to define large communities without collision. Local Data Part 1 is a four-octet operator-defined value and Local Data Part 2 is another four-octet operator-defined value.
In SR OS, a large community value is configured using the format <ext-asnum>:<ext-comm-val>:<ext-comm-val>; the colon is a required separator character between each of the 4-byte values. In route policy applications, it is possible to match multiple large community values with a regular expression in the format <regex1>&<regex2>&<regex3>, where regex1, regex2 and regex3 are three regular expressions, each evaluated one numerical (decimal) digit at a time.
Large communities can be added to or removed from BGP routes using BGP import and export policies. When a BGP route is locally originated by exporting a static or aggregate route into BGP, and the static or aggregate route has one or more large communities, these community values are automatically added to the BGP route.
To remove all the large communities from all routes advertised to a BGP peer, use the following command:
- MD-CLI
configure router bgp send-communities large false - classic
CLI
configure router bgp disable-communities large
Route reflection attributes
The ORIGINATOR_ID and CLUSTER_LIST are optional non-transitive attributes that play a role in route reflection, as described in the section titled Route reflection.
Multi-protocol BGP attributes
As discussed in the BGP chapter overview the uses of BGP have increased well beyond Internet IPv4 routing because of its support for multi-protocol extensions, or more simply MP-BGP. MP-BGP allows BGP peers to exchange routes for NLRI other than IPv4 prefixes - for example IPv6 prefixes, Layer 3 VPN routes, Layer 2 VPN routes, FlowSpec rules, and so on. A BGP router that supports MP-BGP indicates the types of routes it wants to exchange with a peer by including the corresponding AFI (Address Family Identifier) and SAFI (Subsequent Address Family Identifier) values in the MP-BGP capability of its OPEN message. The two peers forming a session do not need to indicate support for the same address families. As long as there is one AFI/SAFI in common the session establishes and routes associated with all the common AFI/SAFI can be exchanged between the peers.
The list of AFI/SAFI advertised in the MP-BGP capability is controlled entirely by the family commands. The AFI/SAFI supported by the SR OS and the method of configuring the AFI/SAFI support is summarized in Multi-protocol BGP support in SR OS.
| Name | AFI | SAFI | Configuration commands |
|---|---|---|---|
IPv4 unicast |
1 |
1 |
family ipv4 |
IPv4 multicast |
1 |
2 |
family mcast-ipv4 |
IPv4 labeled unicast |
1 |
4 |
family label-ipv4 |
NG-MVPN IPv4 |
1 |
5 |
family mvpn-ipv4 |
MDT-SAFI |
1 |
66 |
family mdt-safi |
VPN-IPv4 |
1 |
128 |
family vpn-ipv4 |
VPN-IPv4 multicast |
1 |
129 |
family mcast-vpn-ipv4 |
RT constrain |
1 |
132 |
family route-target |
IPv4 flow-spec |
1 |
133 |
family flow-ipv4 |
IPv6 unicast |
2 |
1 |
family ipv6 |
IPv6 multicast |
2 |
2 |
family mcast-ipv6 |
IPv6 labeled unicast |
2 |
4 |
family label-ipv6 |
NG-MVPN IPv6 |
2 |
5 |
family mvpn-ipv6 |
VPN-IPv6 |
2 |
128 |
family vpn-ipv6 |
IPv6 flow-spec |
2 |
133 |
family flow-ipv6 |
Multi-segment PW |
25 |
6 |
family ms-pw |
L2 VPN |
25 |
65 |
family l2-vpn |
EVPN |
25 |
70 |
family evpn |
To advertise reachable routes of a particular AFI/SAFI a BGP router includes a single MP_REACH_NLRI attribute in the UPDATE message. The MP_REACH_NLRI attribute encodes the AFI, the SAFI, the BGP next-hop and all the reachable NLRI. To withdraw routes of a particular AFI/SAFI a BGP router includes a single MP_UNREACH_NLRI attribute in the UPDATE message. The MP_UNREACH_NLRI attribute encodes the AFI, the SAFI and all the withdrawn NLRI. While it is valid to advertise and withdraw IPv4 unicast routes using the MP_REACH_NLRI and MP_UNREACH_NLRI attributes, SR OS always uses the IPv4 fields of the UPDATE message to convey reachable and unreachable IPv4 unicast routes.
4-octet AS attributes
The AS4_PATH and AS4_AGGREGATOR path attributes are optional transitive attributes that support the gradual migration of routers that can understand and parse 4-octet ASN numbers. The use of these attributes is discussed in the section titled 4-octet autonomous system numbers.
AIGP metric
The accumulated IGP (AIGP) metric is an optional non-transitive attribute that can be attached to selected routes (using route policies) to influence the BGP decision process to prefer BGP paths with a lower end-to-end IGP cost, even when the compared paths span more than one AS or IGP instance. AIGP is different from MED in several important ways:
AIGP is not intended to be transitive between completely distinct autonomous systems (only across internal AS boundaries)
AIGP is always compared in paths that have the attribute, regardless of whether they come from different neighbor AS or not
AIGP is more important than MED in the BGP decision process (see the section titled BGP decision process)
AIGP is automatically incremented every time there is a BGP next-hop change so that it can track the end-to-end IGP cost. All arithmetic operations on MED attributes must be done manually (for example, using route policies)
In the SR OS implementation, AIGP is supported only in the base router BGP instance and only for the following types of routes: IPv4, label-IPv4, IPv6 and label-IPv6. The AIGP attribute is only sent to peers configured with the aigp command. If the attribute is received from a peer that is not configured for aigp or if the attribute is received in a non-supported route type the attribute is discarded and not propagated to other peers (but it is still displayed in BGP show commands).
When a 7450, 7750, or 7950 router receives a route with an AIGP attribute and it re-advertises the route to an AIGP-enabled peer without any change to the BGP next-hop the AIGP metric value is unchanged by the advertisement (RIB-OUT) process. But if the route is re-advertised with a new BGP next-hop the AIGP metric value is automatically incremented by the route table (or tunnel table) cost to reach the received BGP next-hop and/or by a statically configured value (using route policies).
BGP routing information base
The entire set of BGP routes learned and advertised by a BGP router make up its BGP Routing Information Base (RIB). Conceptually the BGP RIB can be divided into 3 parts:
RIB-IN
LOC-RIB
RIB-OUT
The RIB-IN (or Adj-RIBs-In as defined in RFC 4271) holds the BGP routes that were received from peers and that the router decided to keep (store in its memory).
The LOC-RIB contains modified versions of the BGP routes in the RIB-IN. The path attributes of a RIB-IN route can be modified using BGP import policies. All of the LOC-RIB routes for the same NLRI are compared in a procedure called the BGP decision process that results in the selection of the best path for each NLRI. The best paths in the LOC-RIB are the ones that are actually ‛usable’ by the local router for forwarding, filtering, auto-discovery, and so on.
The RIB-OUT (or Adj-RIBs-Out as defined in RFC 4271) holds the BGP routes that were advertised to peers. Normally a BGP route is not advertised to a peer (in the RIB-OUT) unless it is ‛used’ locally but there are exceptions. BGP export policies modify the path attributes of a LOC-RIB route to create the path attributes of the RIB-OUT route. A particular LOC-RIB route can be advertised with different path attribute values to different peers so there can exist a 1:N relationship between LOC-RIB and RIB-OUT routes.
The following sections describe many important BGP features in the context of the RIB architecture described above.
RIB-IN features
SR OS implements the following features related to RIB-IN processing:
UPDATE message fault tolerance; this is described in the section titled Update message error handling
BGP import policies
BGP import policies
The import command is used to apply one or more policies (up to 15) to a neighbor, group or to the entire BGP context. The import command that is most-specific to a peer is the one that is applied. An import policy command applied at the neighbor level takes precedence over the same command applied at the group or global level. An import policy command applied at the group level takes precedence over the same command specified on the global level. The import policies applied at different levels are not cumulative. The policies listed in an import command are evaluated in the order in which they are specified.
When an IP route is rejected by an import policy it is still maintained in the RIB-IN so that a policy change can be made later on without requiring the peer to re-send all its RIB-OUT routes. This is sometimes called soft reconfiguration inbound and requires no special configuration in SR OS.
When a VPN route is rejected by an import policy or not imported by any services it is deleted from the RIB-IN. For VPN-IPv4 and VPN-IPv6 routes this behavior can be changed by configuring the mp-bgp-keep command; this option maintains rejected VPN-IP routes in the RIB-IN so that a Route Refresh message does not have to be issued when there is an import policy change.
LOC-RIB features
SR OS implements the following features related to LOC-RIB processing:
BGP decision process
BGP route installation in the route table
BGP route installation in the tunnel table
BGP fast reroute
QoS Policy Propagation via BGP (QPPB)
policy accounting
route flap damping (RFD)
These features are discussed in the following sections.
BGP decision process
When a BGP router has multiple paths in its RIB for the same NLRI, its BGP decision process is responsible for deciding which path is the best. The best path can be used by the local router and advertised to other BGP peers.
On 7450 ESS, 7750 SR, and 7950 XRS routers, the BGP decision process orders received paths based on the following sequence of comparisons. If there is a tie between paths at any step, BGP proceeds to the next step.
Select a valid route over an invalid route. If a BGP route is invalid because its next-hop it is not resolved then it may still be advertisable if there are no valid routes. For example, an unresolved route can be reflected by a route reflector if it is not trying to set next-hop-self.
Prefer a route for which disable-route-table-install does not apply over a route for which disable-route-table-install has been specified.
Prefer a non-stale route over a stale route (in the context of long-lived graceful restart).
A default route generated by the send-default command is less preferred than a default route programmed by other means.
Select the route with the lowest origin validation state, where Valid<Not-Found<Invalid.
Select the route with the numerically lowest route-table preference. For VPN-IP routes this also consider the number of VPRNs that imported the route.
Select the route with the highest local preference.
Select the route with an AIGP metric. If they both have an AIGP metric, select the route with the lowest sum of:
AIGP metric value stored with the LOC-RIB copy of the route
route-table or tunnel-table cost between the calculating router and the BGP next-hop in the received route
Select the route with the shortest AS path. AS numbers in AS_CONFED_SEQ and AS_CONFED_SET elements do not count toward the AS path length. This step is skipped if as-path-ignore is configured for the address family.
Select the route with the lowest Origin (IGP<EGP<Incomplete).
Select the route with the lowest MED. Only compare MED for non-imported routes that have the same neighbor AS by default. A missing MED attribute is considered equivalent to a MED value 0 by default. Defaults can be changed by using the always-compare-med command.
-
Select the route with the lowest owner type (BGP < BGP-label < BGP-VPN).
Prefer routes learned from EBGP peers over routes learned from IBGP and confed-EBGP peers.
Select the route with the lowest route-table or tunnel-table cost to the NEXT_HOP. This step is skipped if ignore-nh-metric is configured, or if the routes are associated with different RIBs. For VPN-IP routes received by a router without any configured VPRN services, next-hop cost is determined from the route-table cost.
Select the route with the lowest next-hop type. Resolutions made in the route table are preferred to resolutions made in the tunnel-table. This step is skipped if ignore-nh-metric is configured, or if the routes are associated with different RIBs.
Select the route received from the peer with the lowest router ID; this comes from the ORIGINATOR_ID attribute (if present) or the BGP identifier of the peer (received in its OPEN message). If ignore-router-id is configured, keep the current best path and skip the remaining steps.
Select the route with the shortest CLUSTER_LIST length.
Select the route received from the peer with the lowest IP address.
For VPN-IP routes imported into a VPRN, select the route with the lowest route-distinguisher value.
BGP route installation in the route table
Each BGP RIB with IP routes (unlabeled IPv4, labeled-unicast IPv4, unlabeled IPv6, and labeled-unicast IPv6) submits its best path for each prefix to the common IP route table, unless the disable-route-table-install command is configured or the selective-label-ipv4-install command has prevented the installation. The best path is selected by the BGP decision process. The default preference for BGP routes submitted by the label-IPv4 and label-IPv6 RIBs (these appear in the route table and FIB as having a BGP-LABEL protocol type) can be modified by using the label-preference command. The default preference for BGP routes submitted by the unlabeled IPv4 and IPv6 RIBs can be modified by using the preference command.
The BGP instance level disable-route-table-install command can be configured on control-plane route reflectors that are not involved in packet forwarding (that is, those that do not modify the BGP next hop). This command improves performance and scalability. The disable-route-table-install policy action can be applied to BGP routes matching a peer import policy to conserve FIB space on a router that is in the datapath, for example, a router that should advertise BGP routes with itself as next hop even though it has not installed those routes into its own forwarding table.
The configure router bgp selective-label-ip no-install command behaves similarly to the disable-route-table-install policy action for BGP-LU routes on a next-hop-self router. For information about route table entry installation on BGP-LU routes, see Selective download of labeled unicast routes on next-hop-self routers.
If a BGP RIB has multiple BGP paths for the same IPv4 or IPv6 prefix that qualify as the best path up to a specific point in the comparison process, then a specified number of these multipaths can be submitted to the common IP route table. This is called BGP multipath and must be explicitly enabled using one or more commands in the multi-path context. These commands specify the maximum number of BGP paths, including the overall best path, that each BGP RIB can submit to the route table for any particular IPv4 or IPv6 prefix. If ECMP, with a limit of n, is enabled in the base router instance, then up to n paths are selected for installation in the IP FIB. In the data-path, traffic matching the IP route is load-shared across the ECMP next hops based on a per-packet hash calculation.
By default, the hashing is not sticky, meaning that when one or more of the ECMP BGP next hops fail, all traffic flows matching the route are potentially moved to new BGP next hops. If required, a BGP route can be marked (using the sticky-ecmp action in route policies) for sticky ECMP behavior so that BGP next hop failures are handled by moving only the affected traffic flows to the remaining next hops as evenly as possible. If new ECMP BGP next hops become available for a marked BGP, then route flows are moved as evenly as possible onto the resultant set of next hops. For more information about sticky ECMP, see BGP support for sticky ECMP.
A BGP route to an IPv4 or IPv6 prefix is a candidate for installation as an ECMP next hop only if it meets all of the following criteria:
-
The multipath route must be the same type of route as the best path (same AFI/SAFI and, in some cases, same next-hop resolution method).
-
The multipath route must tie with the best path for all criteria of greater significance than next-hop cost, except for criteria that are configured to be ignored.
-
If the best path selection reaches the next-hop cost comparison, the multipath route must have the same next-hop cost as the best route, unless unequal-cost is configured.
-
The multipath route must not have the same BGP next hop as the best path or any other multipath route.
-
The multipath route must not cause the ECMP limit of the routing instance to be exceeded. Use the ecmp command to configure the ECMP limit of the routing instance.
-
The multipath route must not cause the applicable maximum paths limit to be exceeded.
-
The multipath route must have the same neighbor AS in its AS path as the best path if restrict is set to same-neighbor-as.
By default, any path with the same AS path length as the best path, regardless of the neighbor AS, is eligible to be considered a multipath.
-
The route must have the same AS path as the best path if restrict is set to exact-as-path.
By default, any path with the same AS path length as the best path, regardless of the AS numbers, is eligible to be considered a multipath.
SR OS also supports IBGP multipath. In some topologies, a BGP next hop is resolved by an IP route that has multiple ECMP next hops. When ibgp-multipath is not configured, only one of the ECMP next hops is programmed as the next hop of the BGP route in the IOM. When ibgp-multipath is configured, the IOM attempts to use all the ECMP next hops of the resolving route in the forwarding state. Although the name of the ibgp-multipath command implies that it is specific to IBGP-learned routes, this is not the case. It also applies to routes learned from any multi-hop BGP session including routes learned from multi-hop EBGP peers.
The multi-path and ibgp-multipath commands are not mutually exclusive and work together. The first context enables ECMP load-sharing across different BGP next hops (corresponding to different BGP routes) while the ibgp-multipath enables ECMP load-sharing across the next hops of IP routes that resolve the BGP next hops.
Finally, ibgp-multipath does not control traffic load sharing toward a BGP next hop that is resolved by a tunnel, as when dealing with BGP shortcuts or labeled routes (VPN-IP, label-IPv4, or label-IPv6). When a BGP next hop is resolved by a tunnel that supports ECMP, the load-sharing of traffic across the ECMP next hops of the tunnel is automatic.
SR OS supports direct resolution of a BGP next hop to multiple RSVP-TE or SR-TE tunnels. In addition, a BGP next hop can be resolved by multiple LDP ECMP next hops that each correspond to a separate LDP-over-RSVP or LDP-over-SRTE tunnel. It is also possible for a BGP next hop to be resolved by an IGP shortcut route that has multiple RSVP-TE or SR-TE tunnels as its ECMP next hops.
BGP support for sticky ECMP
Each sticky ECMP route uses 64 distribution buckets to apportion flows onto the available next hops. Sticky ECMP flow distribution as next hops are removed part 1, Sticky ECMP flow distribution as next hops are removed part 2, and Sticky ECMP flow distribution as next hops are removed part 3 provide an example of the distribution of flows over multiple BGP next hops as next hops are removed.
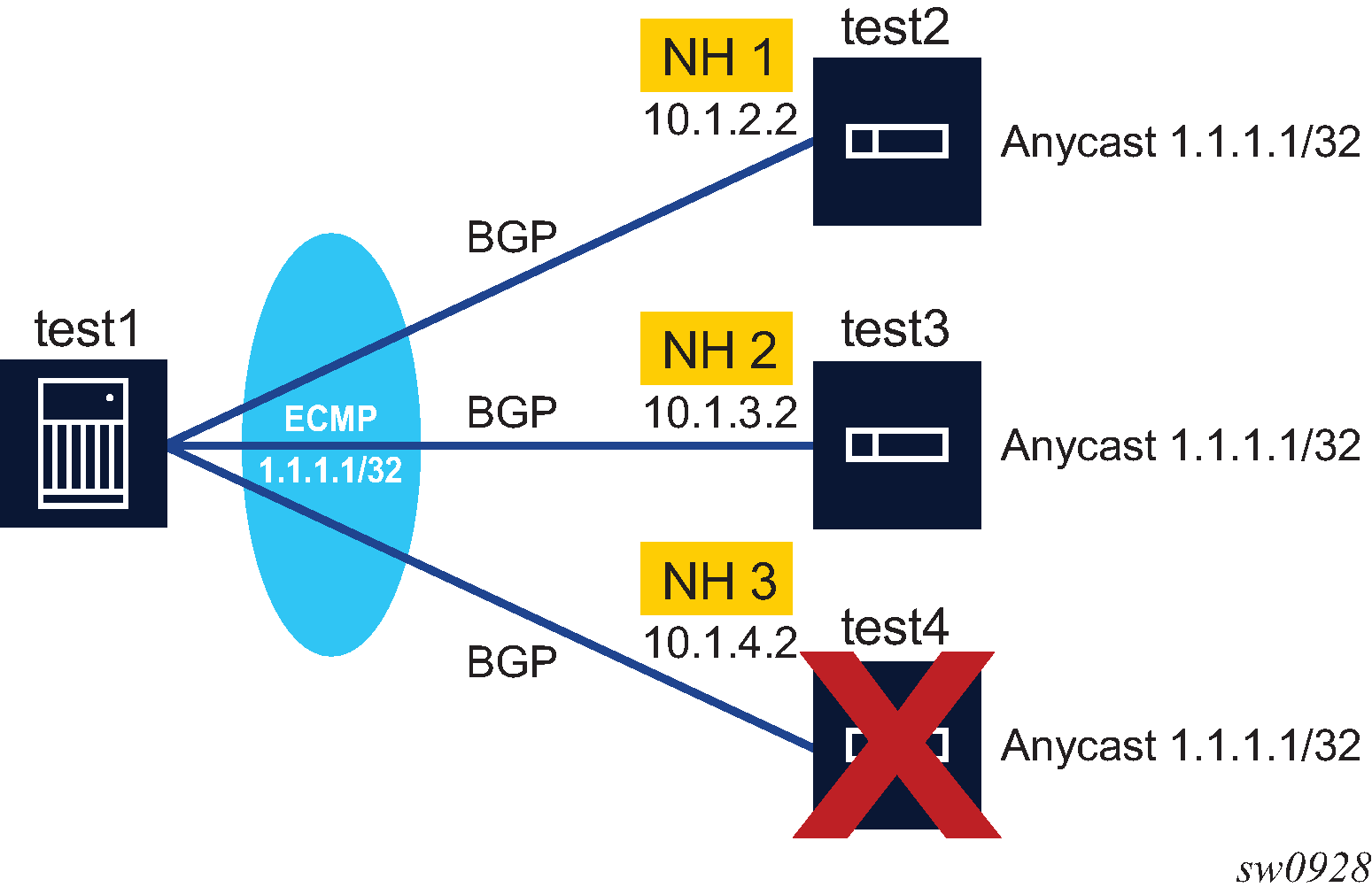
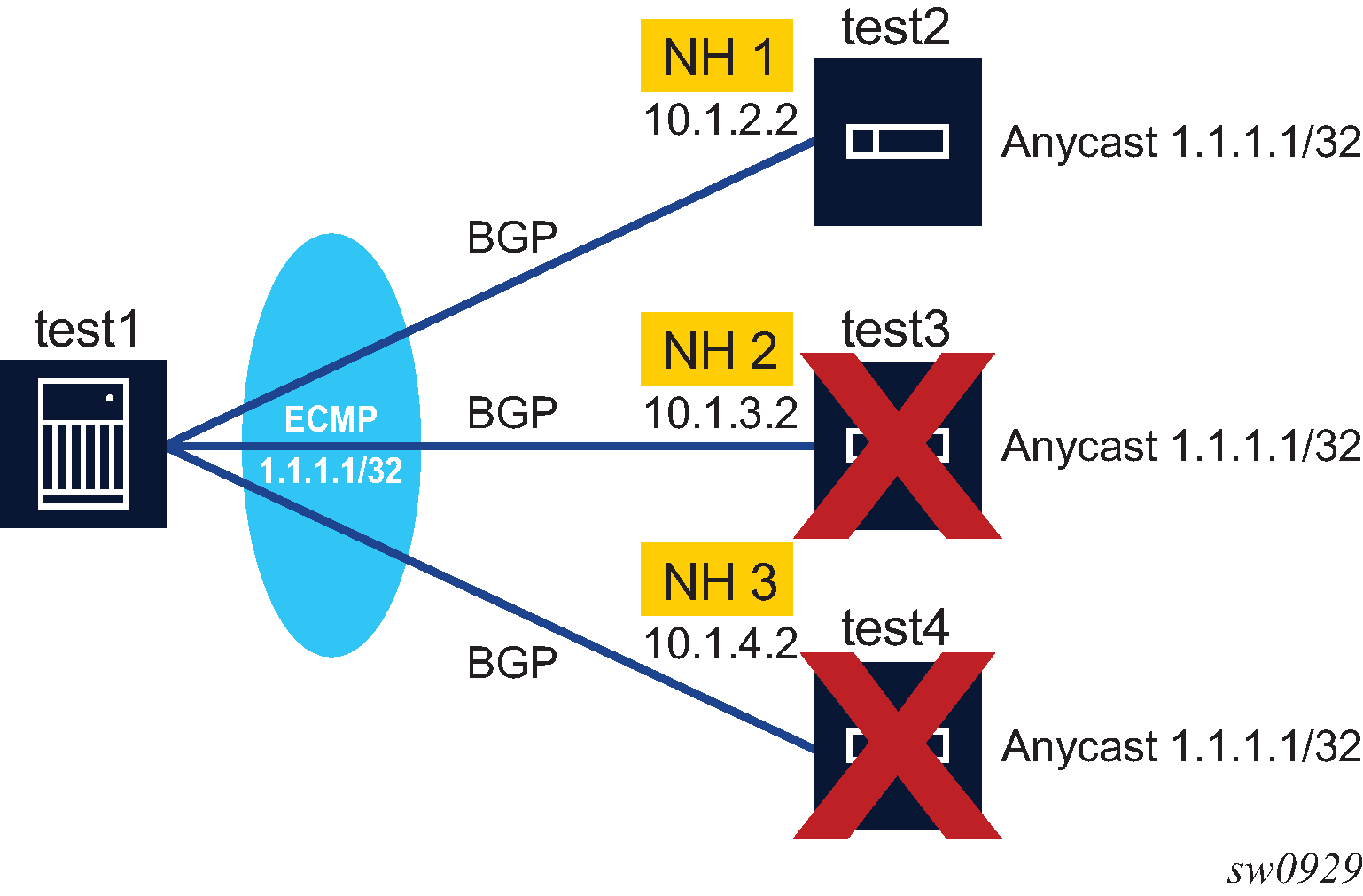
Sticky ECMP flow distribution as next hops are removed for 1.1.1.1/32 lists the sticky ECMP flow distribution as next hops are removed for 1.1.1.1/32.
| Initial sticky ECMP distribution for 1.1.1.1/32 in Sticky ECMP flow distribution as next hops are removed part 1 | ECMP distribution for 1.1.1.1/32 if next hop 3 fails in Sticky ECMP flow distribution as next hops are removed part 2 | ECMP distribution for 1.1.1.1/32 if next hop 2 subsequently fails in Sticky ECMP flow distribution as next hops are removed part 3 | |||
|---|---|---|---|---|---|
| Bucket | NH | Bucket | NH | Bucket | NH |
|
00 |
1 |
00 |
1 |
00 |
1 |
|
01 |
2 |
01 |
2 |
01 |
1 |
|
02 |
3 |
02 |
1 |
02 |
1 |
|
03 |
1 |
03 |
1 |
03 |
1 |
|
04 |
2 |
04 |
2 |
04 |
1 |
|
05 |
3 |
05 |
2 |
05 |
1 |
|
06 |
1 |
06 |
1 |
06 |
1 |
|
07 |
2 |
07 |
2 |
07 |
1 |
|
08 |
3 |
08 |
1 |
08 |
1 |
|
09 |
1 |
09 |
1 |
09 |
1 |
|
10 |
2 |
10 |
2 |
10 |
1 |
|
11 |
3 |
11 |
2 |
11 |
1 |
|
12 |
1 |
12 |
1 |
12 |
1 |
|
13 |
2 |
13 |
2 |
13 |
1 |
|
14 |
3 |
14 |
1 |
14 |
1 |
|
15 |
1 |
15 |
1 |
15 |
1 |
|
16 |
2 |
16 |
2 |
16 |
1 |
|
17 |
3 |
17 |
2 |
17 |
1 |
|
18 |
1 |
18 |
1 |
18 |
1 |
|
19 |
2 |
19 |
2 |
19 |
1 |
|
20 |
3 |
20 |
1 |
20 |
1 |
|
21 |
1 |
21 |
1 |
21 |
1 |
|
22 |
2 |
22 |
2 |
22 |
1 |
|
23 |
3 |
23 |
2 |
23 |
1 |
|
24 |
1 |
24 |
1 |
24 |
1 |
|
25 |
2 |
25 |
2 |
25 |
1 |
|
26 |
3 |
26 |
1 |
26 |
1 |
|
27 |
1 |
27 |
1 |
27 |
1 |
|
28 |
2 |
28 |
2 |
28 |
1 |
|
29 |
3 |
29 |
2 |
29 |
1 |
|
30 |
1 |
30 |
1 |
30 |
1 |
|
31 |
2 |
31 |
2 |
31 |
1 |
|
32 |
3 |
32 |
1 |
32 |
1 |
|
33 |
1 |
33 |
1 |
33 |
1 |
|
34 |
2 |
34 |
2 |
34 |
1 |
|
35 |
3 |
35 |
2 |
35 |
1 |
|
36 |
1 |
36 |
1 |
36 |
1 |
|
37 |
2 |
37 |
2 |
37 |
1 |
|
38 |
3 |
38 |
1 |
38 |
1 |
|
39 |
1 |
39 |
1 |
39 |
1 |
|
40 |
2 |
40 |
2 |
40 |
1 |
|
41 |
3 |
41 |
2 |
41 |
1 |
|
42 |
1 |
42 |
1 |
42 |
1 |
|
43 |
2 |
43 |
2 |
43 |
1 |
|
44 |
3 |
44 |
1 |
44 |
1 |
|
45 |
1 |
45 |
1 |
45 |
1 |
|
46 |
2 |
46 |
2 |
46 |
1 |
|
47 |
3 |
47 |
2 |
47 |
1 |
|
48 |
1 |
48 |
1 |
48 |
1 |
|
49 |
2 |
49 |
2 |
49 |
1 |
|
50 |
3 |
50 |
1 |
50 |
1 |
|
51 |
1 |
51 |
1 |
51 |
1 |
|
52 |
2 |
52 |
2 |
52 |
1 |
|
53 |
3 |
53 |
2 |
53 |
1 |
|
54 |
1 |
54 |
1 |
54 |
1 |
|
55 |
2 |
55 |
2 |
55 |
1 |
|
56 |
3 |
56 |
1 |
56 |
1 |
|
57 |
1 |
57 |
1 |
57 |
1 |
|
58 |
2 |
58 |
2 |
58 |
1 |
|
59 |
3 |
59 |
2 |
59 |
1 |
|
60 |
1 |
60 |
1 |
60 |
1 |
|
61 |
2 |
61 |
2 |
61 |
1 |
|
62 |
3 |
62 |
1 |
62 |
1 |
|
63 |
1 |
63 |
1 |
63 |
1 |
Sticky ECMP flow distribution as next hops are added part 1, Sticky ECMP flow distribution as next hops are added part 2, and Sticky ECMP flow distribution as next hops are added part 3 provide an example of the distribution of flows over multiple BGP next hops as next hops are added.
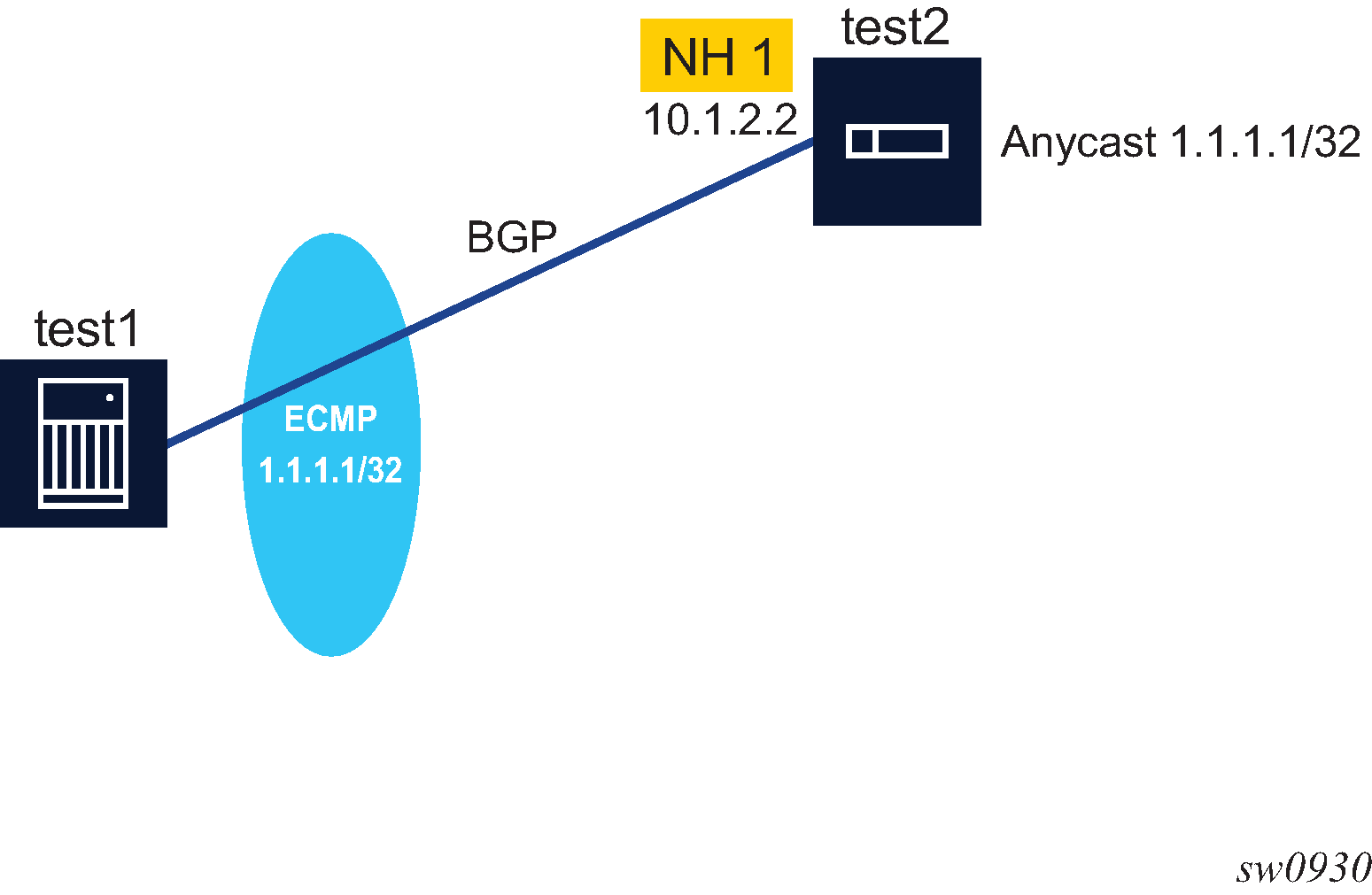
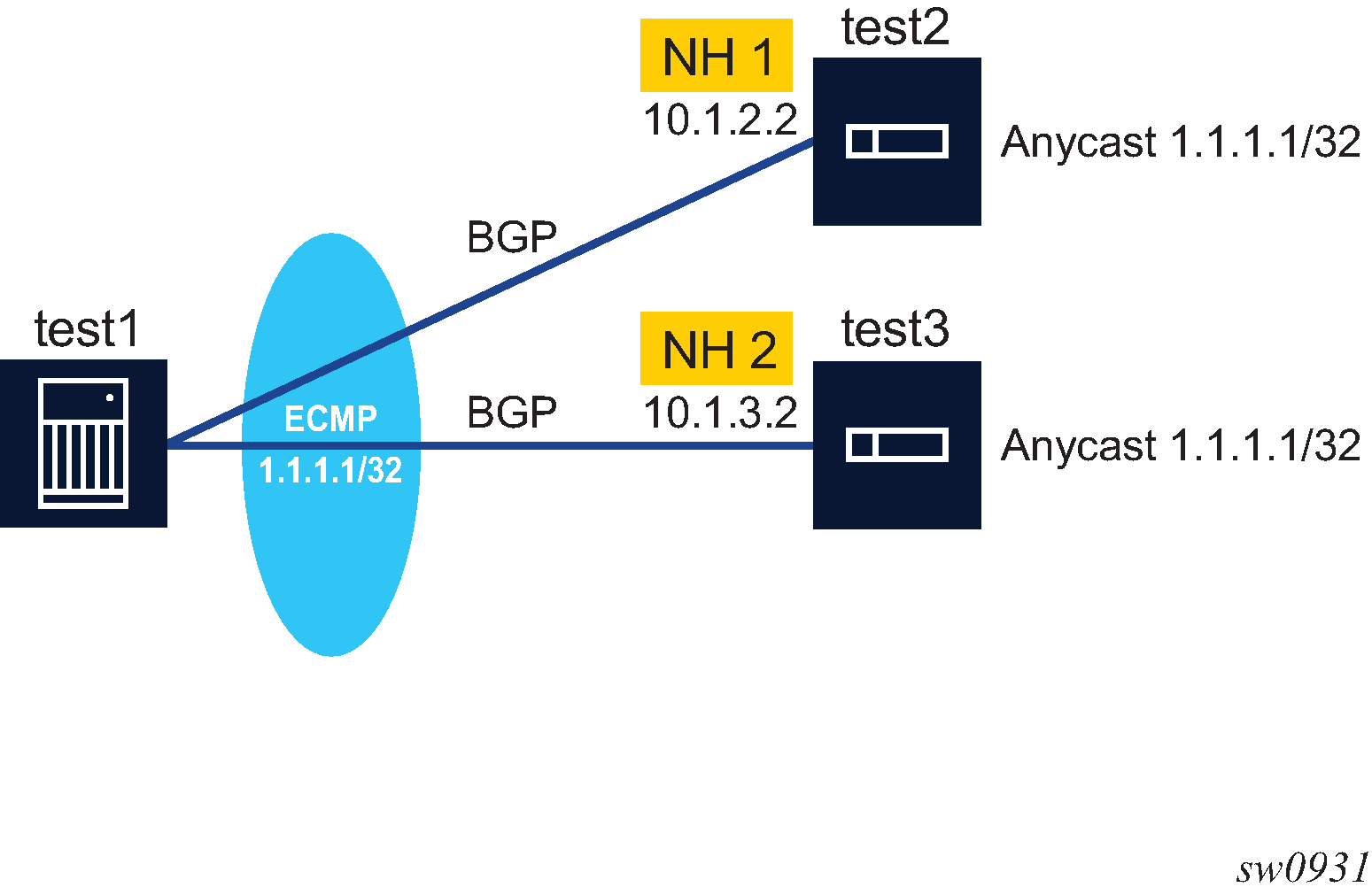
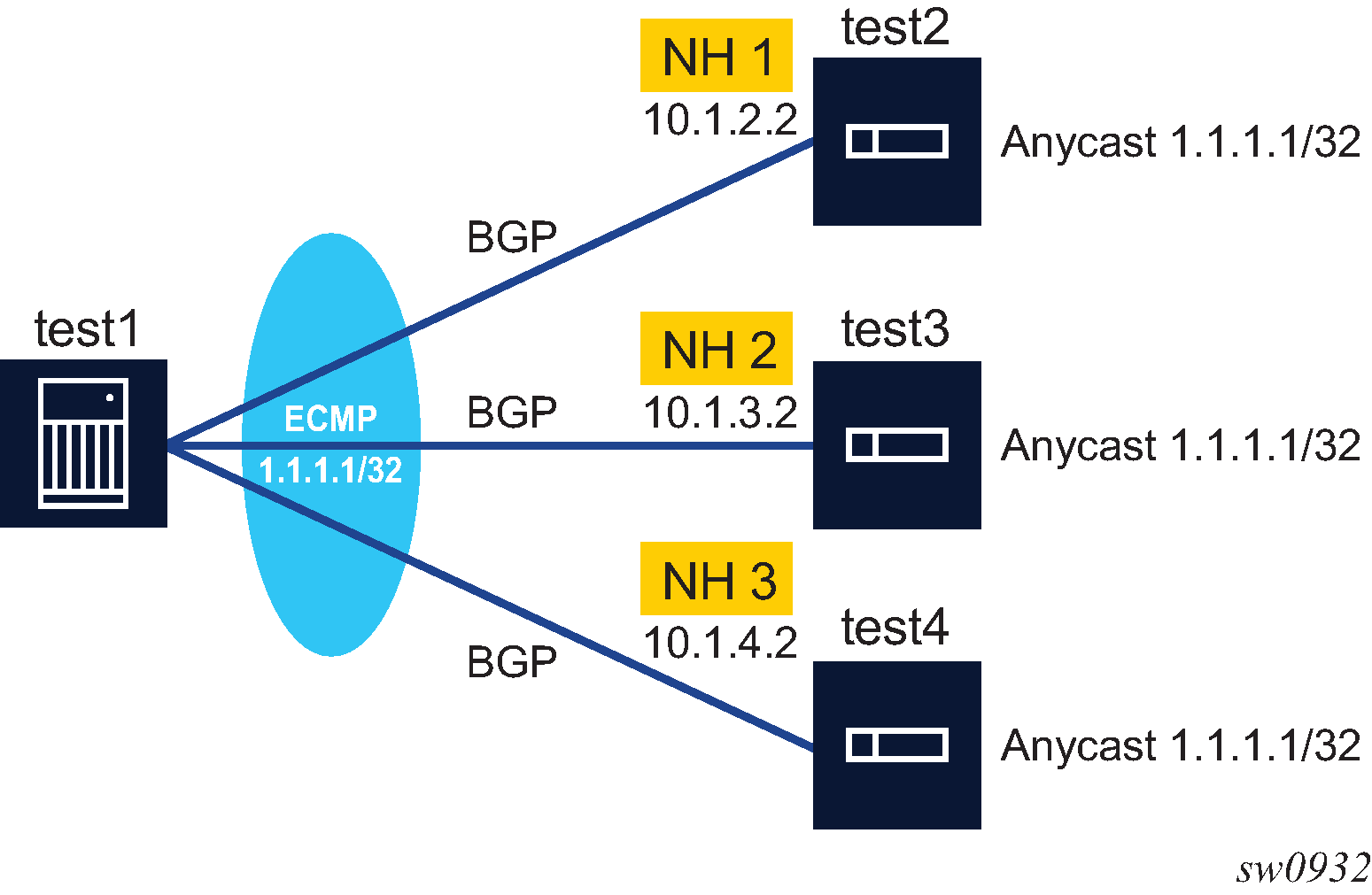
The following table lists the sticky ECMP flow distribution as next hops are added for 1.1.1.1/32:
| Initial sticky ECMP distribution for 1.1.1.1/32 in Sticky ECMP flow distribution as next hops are added part 1 | ECMP distribution for 1.1.1.1/32 if next hop 2 becomes available in Sticky ECMP flow distribution as next hops are added part 2 | ECMP distribution for 1.1.1.1/32 if next hop 3 additionally becomes available in Sticky ECMP flow distribution as next hops are added part 3 | |||
|---|---|---|---|---|---|
| Bucket | NH | Bucket | NH | Bucket | NH |
|
00 |
1 |
00 |
1 |
00 |
1 |
|
01 |
1 |
01 |
2 |
01 |
2 |
|
02 |
1 |
02 |
1 |
02 |
3 |
|
03 |
1 |
03 |
2 |
03 |
2 |
|
04 |
1 |
04 |
1 |
04 |
1 |
|
05 |
1 |
05 |
2 |
05 |
3 |
|
06 |
1 |
06 |
1 |
06 |
1 |
|
07 |
1 |
07 |
2 |
07 |
2 |
|
08 |
1 |
08 |
1 |
08 |
3 |
|
09 |
1 |
09 |
2 |
09 |
2 |
|
10 |
1 |
10 |
1 |
10 |
1 |
|
11 |
1 |
11 |
2 |
11 |
3 |
|
12 |
1 |
12 |
1 |
12 |
1 |
|
13 |
1 |
13 |
2 |
13 |
2 |
|
14 |
1 |
14 |
1 |
14 |
3 |
|
15 |
1 |
15 |
2 |
15 |
2 |
|
16 |
1 |
16 |
1 |
16 |
1 |
|
17 |
1 |
17 |
2 |
17 |
3 |
|
18 |
1 |
18 |
1 |
18 |
1 |
|
19 |
1 |
19 |
2 |
19 |
2 |
|
20 |
1 |
20 |
1 |
20 |
3 |
|
21 |
1 |
21 |
2 |
21 |
2 |
|
22 |
1 |
22 |
1 |
22 |
1 |
|
23 |
1 |
23 |
2 |
23 |
3 |
|
24 |
1 |
24 |
1 |
24 |
1 |
|
25 |
1 |
25 |
2 |
25 |
2 |
|
26 |
1 |
26 |
1 |
26 |
3 |
|
27 |
1 |
27 |
2 |
27 |
2 |
|
28 |
1 |
28 |
1 |
28 |
1 |
|
29 |
1 |
29 |
2 |
29 |
3 |
|
30 |
1 |
30 |
1 |
30 |
1 |
|
31 |
1 |
31 |
2 |
31 |
2 |
|
32 |
1 |
32 |
1 |
32 |
3 |
|
33 |
1 |
33 |
2 |
33 |
2 |
|
34 |
1 |
34 |
1 |
34 |
1 |
|
35 |
1 |
35 |
2 |
35 |
3 |
|
36 |
1 |
36 |
1 |
36 |
1 |
|
37 |
1 |
37 |
2 |
37 |
2 |
|
38 |
1 |
38 |
1 |
38 |
3 |
|
39 |
1 |
39 |
2 |
39 |
2 |
|
40 |
1 |
40 |
1 |
40 |
1 |
|
41 |
1 |
41 |
2 |
41 |
3 |
|
42 |
1 |
42 |
1 |
42 |
1 |
|
43 |
1 |
43 |
2 |
43 |
2 |
|
44 |
1 |
44 |
1 |
44 |
3 |
|
45 |
1 |
45 |
2 |
45 |
2 |
|
46 |
1 |
46 |
1 |
46 |
1 |
|
47 |
1 |
47 |
2 |
47 |
3 |
|
48 |
1 |
48 |
1 |
48 |
1 |
|
49 |
1 |
49 |
2 |
49 |
2 |
|
50 |
1 |
50 |
1 |
50 |
3 |
|
51 |
1 |
51 |
2 |
51 |
2 |
|
52 |
1 |
52 |
1 |
52 |
1 |
|
53 |
1 |
53 |
2 |
53 |
3 |
|
54 |
1 |
54 |
1 |
54 |
1 |
|
55 |
1 |
55 |
2 |
55 |
2 |
|
56 |
1 |
56 |
1 |
56 |
3 |
|
57 |
1 |
57 |
2 |
57 |
2 |
|
58 |
1 |
58 |
1 |
58 |
1 |
|
59 |
1 |
59 |
2 |
59 |
3 |
|
60 |
1 |
60 |
1 |
60 |
1 |
|
61 |
1 |
61 |
2 |
61 |
2 |
|
62 |
1 |
62 |
1 |
62 |
3 |
|
63 |
1 |
63 |
2 |
63 |
2 |
Weighted ECMP for BGP routes
In some cases, the ECMP BGP next-hops of an IP route correspond to paths with very different bandwidths and it makes sense for the ECMP load-balancing algorithm to distribute traffic across the BGP next-hops in proportion to their relative bandwidths. The bandwidth associated with a path can be signaled to other BGP routers by including a link-bandwidth extended community in the BGP route. The link-bandwidth extended community is optional and non-transitive and encodes an autonomous system (AS) number and a bandwidth.
The SR OS implementation supports the link-bandwidth extended community in routes associated with the following address families: IPv4, IPv6, label-IPv4, label-IPv6, VPN-IPv4, and VPN-IPv6. The router automatically performs weighted ECMP for an IP BGP route when all of the ECMP BGP next-hops of the route include a link-bandwidth extended community. The relative weight of traffic sent to each BGP next-hop is visible in the output of the show router route-table extensive and show router fib extensive commands.
A route with a link-bandwidth extended community can be received from any IBGP peer. If such a route is received from an EBGP peer, the link-bandwidth extended community is stripped from the route unless an accept-from-ebgp command applies to that EBGP peer. However, a link-bandwidth extended community can be added to routes received from a directly connected (single hop) EBGP peer, potentially replacing the received Extended Community. This is accomplished using the add-to-received-ebgp command, which is available in group and neighbor configuration contexts.
When a route with a link-bandwidth extended community is advertised to an EBGP peer, the link-bandwidth extended community is removed by default. However, transitivity across an AS boundary can be allowed by configuring the send-to-ebgp command.
When a route with a link-bandwidth extended community is advertised to a peer using next-hop-self, the Extended Community is usually removed if it was not added locally (that is, by policy or add-to-received-ebgp command). However, in the special case that a route is readvertised (with next-hop-self) toward a peer covered by the scope of an aggregate-used-paths command, and the re-advertising router has installed multiple ECMP paths toward the destination each associated with a link-bandwidth extended community, the route is readvertised with a link-bandwidth extended community encoding the total bandwidth of all the used multi-paths.
The link-bandwidth extended community associated with a BGP route can be displayed using the show router bgp routes command. For the bandwidth value, the system automatically converts the binary value in the extended community to a decimal number in units of Mb/s (1 000 000 b/s).
Weighted ECMP across the BGP next-hops of an IP BGP route is supported in combination with ECMP at the level of the route or tunnel that resolves one or more of the ECMP BGP next-hops. This ECMP at the resolving level can also be weighted ECMP when the following conditions all apply:
the BGP next-hop is resolved by an IP route (OSPF, IS-IS, or static) with MPLS LSP ECMP next-hops
ibgp-multipath is configured under BGP
config>router>weighted-ecmp is configured
BGP route installation in the tunnel table
Received label-unicast routes can be installed by BGP as tunnels in the tunnel table. In SR OS, the tunnel table is used to resolve a BGP next-hop to a tunnel when required by the configuration or the type of route (see Next-hop resolution). BGP tunnels play a key role in the following solutions:
inter-AS model C
carrier supporting carrier (CSC)
seamless MPLS
BGP tunnels have a preference of 10 in the tunnel table, compared to 9 for LDP tunnels and 7 for RSVP tunnels. If the router configuration allows all types of tunnels to resolve a BGP next-hop, an RSVP LSP is preferred over an LDP tunnel, and an LDP tunnel is preferred over a BGP tunnel.
Further details about BGP-LU tunnels depending on the address family, are described below.
Label-IPv4 tunnels
A label-IPv4 is automatically added as a BGP tunnel entry to the tunnel table if all of the following conditions are met.
The label-IPv4 route is the best BGP path for the /32 IPv4 prefix.
The label-IPv4 route has the numerically lowest preference value among all routes (regardless of the protocol) for the /32 IPv4 prefix.
The disable-route-table-install command does not apply to the route.
The selective-label-ipv4-install command does not prevent the installation of the route.
If multipath and ECMP are configured so that they apply to label IPv4 routes, then a BGP tunnel can be installed in the tunnel table with multiple ECMP next-hops, each one corresponding to a path through a different BGP next-hop. The multipath selection process described in BGP route installation in the route table also applies to this case.
Label-IPv6 tunnels
A label-IPv6 is automatically added as a BGP tunnel entry to the tunnel table if all of the following conditions are met.
The label-IPv6 route is the best BGP path for a /128 IPv6 prefix is a label-IPv6 route (AFI 2, SAFI 4).
The label-IPv6 route has the numerically lowest preference value among all routes (regardless of protocol) for the /128 IPv6 prefix.
The disable-route-table-install command does not apply to the route.
The disable-explicit-null command is configured.
If multipath and ECMP are configured so that they apply to label IPv6 routes, a BGP tunnel can be installed in the tunnel table with multiple ECMP next-hops, each one corresponding to a path through a different BGP next-hop. However, when disable-explicit-null is configured, the label-IPv6 routes used for ECMP toward an IPv6 destination cannot be a mix of routes with regular label values and routes with special (IPv6 explicit null) label values.
Selective download of labeled unicast routes on next-hop-self routers
When a router is configured to perform next-hop-self for labeled unicast routes, the router must swap and advertise learned labeled unicast routes to downstream routers because there is no way for next-hop-self routers to know which BGP-LU routes are in use by downstream routers at a specific time. Additionally, a new service may resolve to a new labeled unicast route on a downstream router at any time. A next-hop-self router is required to readvertise all learned labeled routes downstream after best route selection.
A next-hop-self router may have local services that resolve to a subset of learned labeled unicast routes. In this case, it is possible to enable selective download of labeled unicast routes to datapath tables. Only the labeled unicast routes used by local services can be downloaded to the datapath.
Use the following command to install labeled unicast routes in local datapath tables that are used for NHLFE resolution by local services.
configure router bgp selective-label-ip no-installThis process is dynamic. When additional labeled unicast routes are called by services, they are automatically downloaded to the datapath tables. After a labeled unicast route is downloaded to a datapath, the route can also be used by IP shortcuts for next-hop resolution.
Use the following command to install labeled unicast routes to the RTM for NHLFE resolution by IP shortcuts and continue with selective install for local services. This option is used to extend the no-install mode via downloading all the labeled unicast routes to the RTM for IP next-hop resolution. The RTM is fully populated by labeled unicast routes, and services continue to trigger the download of only the required labeled unicast routes to the LTN.
configure router bgp selective-label-ip route-table-install-onlyLabeled unicast routes required for NHLFE resolution are handled selectively. That is, local services that require resolution to a labeled unicast route trigger the download.
The selective-label-ip command does not impact how labeled unicast routes are readvertised downstream.
In the following figure, the 7750 SR performs next-hop-self for labeled unicast routes and readvertises all learned labeled unicast routes to access the network (such as ACC routers, including the 7250 IXR-e).
The following figure shows the logical view of the BGP-LU NHS component from the example in the preceding figure.
Enabling selective-label-ip install saves datapath table space that can be used by other applications.
BGP fast reroute
BGP fast reroute is a feature that brings together indirection techniques in the forwarding plane and pre-computation of BGP backup paths in the control plane to support fast reroute of BGP traffic around unreachable/failed BGP next-hops. BGP fast reroute is supported with IPv4, label-IPv4, IPv6, label-IPv6, VPN-IPv4 and VPN-IPv6 routes. The scenarios supported by the base router BGP context are described in BGP fast reroute scenarios (base context).
See the VPRN section of the 7450 ESS, 7750 SR, 7950 XRS, and VSR Layer 3 Services Guide: IES and VPRN for more information about BGP fast reroute information specific to IP VPNs.
| Ingress packet | Primary route | Backup route | Prefix independent convergence |
|---|---|---|---|
IPv4 |
IPv4 route with next-hop A resolved by an IPv4 route or any shortcut tunnel |
IPv4 route with next-hop B resolved by an IPv4 route or any shortcut tunnel |
Yes |
IPv4 |
Label-IPv4 route with next-hop A resolved by any transport tunnel |
Label-IPv4 route with next-hop B resolved by any transport tunnel |
Yes |
IPv4 |
Label-IPv4 route with next-hop A resolved by a local route |
Label-IPv4 route with next-hop B resolved by a local route |
Yes |
IPv4 |
Label-IPv4 route with next-hop A resolved by a static route |
Label-IPv4 route with next-hop B resolved by a static route |
Yes |
IPv6 |
IPv6 route with next-hop A resolved by an IPv6 route |
IPv6 route with next-hop B resolved by an IPv6 route |
Yes |
IPv6 |
Label-IPv6 route with next-hop A resolved by any transport tunnel |
Label-IPv6 route with next-hop B resolved by any transport tunnel |
Yes |
IPv6 |
Label-IPv6 route with next-hop A resolved by a local route |
Label-IPv6 route with next-hop B resolved by a local route |
Yes |
IPv6 |
Label-IPv6 route with next-hop A resolved by a static route |
Label-IPv6 route with next-hop B resolved by a static route |
Yes |
Calculating backup paths
In SR OS, fast reroute is optional and must be enabled by using either the BGP backup-path command or the route-policy install-backup-path command. Typically, only one approach is used.
The backup-path command in the base router context is used to control fast reroute on a per-RIB basis (IPv4, label-IPv4, IPv6, and label-IPv6). When the command specifies a particular family, BGP attempts to find a backup path for every prefix learned by the associated BGP RIB.
The install-backup-path command, available in route-policy-action contexts, marks a BGP route as requesting a backup path. It only takes effect in BGP import and VRF import policies. If only some prefixes should have backup paths, then the backup-path command should not be used, and instead the install-backup-path command should be used to mark only those prefixes that require extra protection.
In general, a prefix supports ECMP paths or a backup path, but not both. The backup path is the best path after the primary path and any paths with the same BGP next-hop as the primary path have been removed.
Failure detection and switchover to the backup path
When BGP fast reroute is enabled the IOM reroutes traffic onto a backup path based on input from BGP. When BGP decides that a primary path is no longer usable it notifies the IOM and affected traffic is immediately switched to the backup path.
The following events trigger failure notifications to the IOM and reroute of traffic to backup paths.
The peer IP address is unreachable and the peer-tracking is enabled.
The BFD session associated with BGP peer goes down.
The BGP session terminated with peer (for example, send/receive NOTIFICATION).
There is no longer any route (allowed by the next-hop resolution policy, if configured) that can resolve the BGP next-hop address.
The LDP tunnel that resolves the next-hop goes down. This could happen because there is no longer any IP route that can resolve the FEC, or the LDP session goes down, or the LDP peer withdraws its label mapping.
The RSVP tunnel that resolves the next-hop goes down. This could happen because a ResvTear message is received, or the RESV state times out, or the outgoing interface fails and is not protected by FRR or a secondary path.
The BGP tunnel that resolves the next-hop goes down. This could happen because the BGP label-IPv4 route is withdrawn by the peer or else becomes invalid because of an unresolved next-hop.
QoS policy propagation through BGP
The QoS Policy Propagation through BGP (QPPB) is a feature that allows a QoS treatment (forwarding class and optionally priority) to be associated with a BGP IPv4, label-IPv4, IPv6, or label-IPv6 route that is installed in the routing table. This is done so that when traffic arrives on a QPPB-enabled IP interface and its source or destination IP address matches a BGP route with QoS information, the packet is handled according to the QoS of the matching route. SR OS supports QPPB on the following types of interfaces:
base router network interfaces
IES and VPRN SAP interfaces
IES and VPRN spoke SDP interfaces
IES and VPRN subscriber interfaces
QPPB is enabled on an interface using the qos-route-lookup command. There are separate commands for IPv4 and IPv6 so QPPB can be enabled in one mode, source, destination, or none, for IPv4 packets arriving on the interface, and a different mode source, destination, or none, for IPv6 packets arriving on the interface.
Different BGP routes for the same IP prefix can be associated with different QPPB information. If these BGP routes are combined in support of ECMP or BGP fast reroute then the QPPB information becomes next-hop specific. If these LOC-RIB routes are combined in support of ECMP or BGP fast reroute then the QPPB information becomes next-hop specific. This means that in destination QPPB mode the QoS assigned to a packet depends on the BGP next-hop that is selected for that particular packet by the ECMP hash or fast reroute algorithm. In source QPPB mode the QoS assigned to a packet comes from the first BGP next-hop of the IP route matching the source address.
BGP policy accounting and policing
Policy accounting is a feature that allows ‟classes” to be associated with specific IPv4 or IPv6 routes, static or BGP learned, when they are installed in the routing table. This is done for the following reasons.
To collect ‟per-interface, per-class” traffic statistics on policy accounting-enabled interfaces of the router. This is supported by all FP2 and later generation cards and systems.
To implement ‟per-interface, per-FP, per-class” traffic policing on policy accounting-enabled interfaces of the router. This is only supported for destination classes and only by FP4 cards and systems. The rate limit is applied per-interface, per-FP, per-class, when the IP interface is a distributed interface such as R-VPLS, LAG, or spoke SDP, that spans multiple complexes. Otherwise, for a simple interface, the rate limit is applied per-interface per-class.
For both applications the following IP interface types are supported:
base router network interfaces
IES and VPRN SAP interfaces
IES and VPRN spoke SDP interfaces
IES and VPRN subscriber interfaces (with some limitations)
IES and VPRN R-VPLE interfaces
Policy accounting, and policing (if needed and supported), is enabled on an interface using the policy-accounting command. The name of a policy accounting template must be specified as an argument of this command. SR OS supports up to 1024 different templates. Each policy accounting template can have a list of source classes (up to 255), a list of destination classes (up to 255), and a list of policers (up to 63). Each source class, destination class, and policer, in their respective list, has an index number. Source class indexes and destination class indexes have a global meaning. In other words, destination-class index 5 in one template refers to the same set of routes as destination-class index 5 in another policy accounting template. Policer indexes have a local scope to the enclosing template. In one template, destination-class index 5 could use policer index 2 and in another template destination-class index 5 could use policer index 62. If a destination class has an associated policer then incoming traffic on each IP interface on which the template is applied is rate-limited based on that policer if the destination IP address matches a route with that destination class.
Policy accounting templates containing one or more source class identifiers cannot be applied to subscriber interfaces.
The policy accounting template tells the IOM the number of statistics and policer resources to use for each interface. These resources are derived from two pools that are sized per-FP. The first pool consists of policer statistics indexes. Every policy-accounting interface on a card or FP uses one of these resources for every source and destination class index listed in the template referenced by the interface. These are basic resources needed for statistics collection. The total reservation at the FP level is set using the configure card slot-number fp fp-number policy-accounting command.
The second pool (FP4 cards only) consists of policer index resources. Every policy-accounting interface on a complex uses one of these resources for every destination class associated with a policer in the template referenced by the interface. The total reservation of this second resource at the FP level is set using the configure card slot-number fp fp-number ingress policy-accounting policers command.
The total number of the above two resources, per FP, must be less than or equal to 128000. In addition, the second resource pool size must be less than or equal to the size of the first resource pool.
It is possible to increase or decrease the size of either resource sub-pool at any time. A decrease can cause some interfaces (randomly selected) to immediately lose their resources and stop counting or policing some traffic that was previously being counted or policed.
If the policy accounting is enabled on a spoke SDP or R-VPLS interface, all FPs in the system should have a reservation for each of the above resources, otherwise the show router interface policy-accounting command output reports that the statistics are possibly incomplete.
Through route policy or configuration mechanisms, a BGP or static route for an IP prefix can have a source class index (1 to 255), a destination class index (1 to 255) or both. When an ingress packet on a policy accounting-enabled interface [I1] is forwarded by the IOM and its destination address matches a BGP or static route with a destination class index [D], and [D] is listed in the relevant policy accounting template, then the packets-forwarded and IP-bytes-forwarded counters for [D] on interface [I1] are incremented accordingly. If [D] is also associated with a policer (FP4 only) the packet is also subjected to rate limiting as discussed above. The policer statistics displayed by the show router interface policy-accounting command include Layer 2 encapsulation and is different from the destination-class byte-level statistics.
When an ingress packet on a policy accounting-enabled interface [I2] is forwarded by the IOM and its source address matches a BGP or static route with a source class index [S], and [S] is listed in the relevant policy accounting template, the packets-forwarded and IP-bytes-forwarded counters for [S] on interface [I2] are incremented accordingly. Policing based on the source class is unsupported.
It is possible that different BGP or static routes for the same IP prefix (through different next hops) are associated with different class information. If these routes are combined in support of ECMP or fast reroute then the destination class of a packet depends on the next hop that is selected for that particular packet by the ECMP hash or fast reroute algorithm. If the source address of a packet matches a route with multiple next hops its source class is derived from the first next hop of the matching route.
Route flap damping
Route Flap Damping (RFD) is a mechanism supported by 7450, 7750, and 7950 routers, as well as other BGP routers, that was designed to help improve the stability of Internet routing by mitigating the impact of route flaps. Route flaps describe a situation where a router alternately advertises a route as reachable and then unreachable or as reachable through one path and then another path in rapid succession. Route flaps can result from hardware errors, software errors, configuration errors, unreliable links, and so on. However not all perceived route flaps represent a true problem; when a best path is withdrawn the next-best path may not be immediately known and may trigger a number of intermediate best path selections (and corresponding advertisements) before it is found. These intermediate best path selections may travel at different speeds through different routers because of the effect of the min-route-advertisement interval (MRAI) and other factors. RFD does not handle this type of situation particularly well and for this and other reasons many Internet service providers do not use RFD.
In SR OS route flap damping is configurable; by default, it is disabled. It can be enabled on EBGP and confed-EBGP sessions by including the damping command in their group or neighbor configuration. The damping command has no effect on IBGP sessions. When a route of any type (any AFI/SAFI) is received on a non-IBGP session that has damping enabled.
If the route changes from reachable to unreachable because of a withdrawal by the peer then damping history is created for the route (if it does not already exist) and in that history the Figure of Merit (FOM), an accumulated penalty value, is incremented by 1024.
If a reachable route is updated by the peer with new path attribute values then the FOM is incremented by 1024.
In SR OS the FOM has a hard upper limit of 21540 (not configurable).
The FOM value is decayed exponentially as described in RFC 2439. The half-life of the decay is 15 minutes by default, however a BGP import policy can be used to apply a non-default damping profile to the route, and the half-life in the non-default damping profile can have any value between 1 and 45 minutes.
The FOM value at the last time of update can be displayed using the show router bgp damping detail command. The time of last update can be up to 640 seconds ago; SR OS does not calculate the current FOM every time the show command is entered.
When the FOM reaches the suppress limit, which is 3000 by default, but can be changed to any value between 1 and 20000 in a non-default damping profile, the route is suppressed, meaning it is not used locally and not advertised to peers. The route remains suppressed until either the FOM exponentially decays to a value less than or equal to the reuse threshold or the max-suppress time is reached. By default, the reuse threshold is 750 and the max-suppress time is 60 minutes, but these can be changed in a non-default damping profile: reuse can have a value between 1 and 20000 and max-suppress can have a value between 1 and 720 minutes.
RIB-OUT features
SR OS implements the following features related to RIB-OUT processing:
BGP export policies
outbound route filtering (ORF)
RT constrained route distribution
configurable min-route-advertisement (MRAI)
advertise-inactive
best-external
add-path
split-horizon
These features are discussed in the following sections.
BGP export policies
The export command is used to apply one or more policies (up to 15) to a neighbor, group or to the entire BGP context. The export command that is most-specific to a peer is the one that is applied. An export policy command applied at the neighbor level takes precedence over the same command applied at the group or global level. An export policy command applied at the group level takes precedence over the same command specified on the global level. The export policies applied at different levels are not cumulative. The policies listed in an export command are evaluated in the order in which they are specified.
The most common uses for BGP export policies are as follows.
To locally originate a BGP route by exporting (or redistributing) a non-BGP route that is installed in the route table and actively used for forwarding. The non-BGP route is most frequently a direct, static or aggregate route (exporting IGP routes into BGP is generally not recommended).
To block the advertisement of specific BGP routes toward specific BGP peers. The routes may be blocked on the basis of IP prefix, communities, and so on.
To modify the attributes of BGP routes advertised to specific BGP peers. The following path attribute modifications are possible using BGP export policies.
Change the ORIGIN value.
Add a sequence of AS numbers to the start of the AS_PATH. When a route is advertised to an EBGP peer the addition of the local-AS/global-AS numbers to the AS_PATH is always the final step (done after export policy).
Replace the AS_PATH with a new AS_PATH. When a route is advertised to an EBGP peer the addition of the local-AS/global-AS numbers to the AS_PATH is always the final step (done after export policy).
Prepend an AS number multiple times to the start of the AS_PATH. When a route is advertised to an EBGP peer the addition of the local-AS/global-AS numbers to the AS_PATH is always the final step (done after export policy). The add/replace action on the AS_PATH supersedes the prepend action if both are specified in the same policy entry.
Change the NEXT_HOP to a specific IP address. When a route is advertised to an EBGP peer the next-hop cannot be changed from the local-address.
Change the NEXT_HOP to the local-address used with the peer (next-hop-self).
Add a value to the MED. If the MED attribute does not exist it is added.
Subtract a value from the MED. If the MED attribute does not exist it is added with a value of 0. If the result of the subtraction is a negative number the MED metric is set to 0.
Set the MED to a particular value.
Set the MED to the cost of the IP route (or tunnel) used to resolve the BGP next-hop.
Set LOCAL_PREF to a particular value when advertising to an IBGP peer.
Add, remove or replace standard communities.
Add, remove or replace extended communities.
Add a static value to the AIGP metric when advertising the route to an AIGP-enabled peer with a modified BGP next-hop. The static value is incremental to the automatic adjustment of the LOC-RIB AIGP metric to reflect the distance between the local router and the received BGP next-hop.
Increment the AIGP metric by a fixed amount when advertising the route to an AIGP-enabled peer with a modified BGP next-hop. The static value is a substitute for the dynamic value of the distance between the local router and the received BGP next-hop.
Outbound route filtering
Outbound Route Filtering (ORF) is a mechanism that allows one router, the ORF-sending router to signal to a peer, the ORF-receiving router, a set of route filtering rules (ORF entries) that the ORF-receiving router should apply to its route advertisements toward the ORF-sending router. The ORF entries are encoded in Route Refresh messages.
The use of ORF on a session must be negotiated — that is, both routers must advertise the ORF capability in their Open messages. The ORF capability describes the address families that support ORF, and for each address family, the ORF types that are supported and the ability to send/receive each type. 7450, 7750, and 7950 routers support ORF type 3, which is ORF based on Extended Communities. It is supported for only the following address families:
VPN-IPv4
VPN-IPv6
MVPN-IPv4
MVPN-IPv6
In SR OS the send/receive capability for ORF type 3 is configurable (with the send-orf and accept-orf commands) but the setting applies to all supported address families.
SR OS support for ORF type 3 allows a PE router that imports VPN routes with a particular set of Route Target Extended Communities to indicate to a peer (for example a route reflector) that it only wants to receive VPN routes that contain one or more of these Extended Communities. When the PE router wants to inform its peer about a new RT Extended Community it sends a Route Refresh message to the peer containing an ORF type 3 entry instructing the peer to add a permit entry for the 8-byte extended community value. When the PE router wants to inform its peer about a RT Extended Community that is no longer needed it sends a Route Refresh message to the peer containing an ORF type 3 entry instructing the peer to remove the permit entry for the 8-byte extended community value.
In SR OS the type-3 ORF entries that are sent to a peer can be generated dynamically (if no Route Target Extended Communities are specified with the send-orf command) or else specified statically. Dynamically generated ORF entries are based on the route targets that are imported by all locally-configured VPRNs.
A router that has installed ORF entries received from a peer can still apply BGP export policies to the session. If the evaluation of a BGP export policy results in a reject action for a VPN route that matches a permit ORF entry the route is not advertised (that is, the export policy has the final word).
Despite the advantages of ORF compared to manually configured BGP export policies a better technology, when it comes to dynamic filtering based on Route Target Extended Communities, is RT Constraint. RT Constraint is discussed further in the next section.
RT constrained route distribution
RT constrained route distribution, or RT-constrain for short, is a mechanism that allows a router to advertise to specific peers a special type of MP-BGP route called an RTC route; the associated AFI is 1 and the SAFI is 132. The NLRI of an RTC route encodes an Origin AS and a Route Target Extended Community with prefix-type encoding (for instance, if there is a prefix-length and ‟host” bits after the prefix-length are set to zero). A peer receiving RTC routes does not advertise VPN routes to the RTC-sending router unless they contain a Route Target Extended Community that matches one of the received RTC routes. As with any other type of BGP route RTC routes are propagated loop-free throughout and between Autonomous Systems. If there are multiple RTC routes for the same NLRI the BGP decision process selects one as the best path. The propagation of the best path installs RIB-OUT filter rules as it travels from one router to the next and this process creates an optimal VPN route distribution tree rooted at the source of the RTC route.
In SR OS the capability to exchange RTC routes is advertised when the route-target keyword is added to the relevant family command. RT-constrain is supported on EBGP and IBGP sessions of the base router instance. On any particular session either ORF or RT-constrain may be used but not both; if RT-constrain is configured the ORF capability is not announced to the peer.
When RT-constrain has been negotiated with one or more peers SR OS automatically originates and advertises to these peers one /96 RTC route (the origin AS and Route Target Extended Community are fully specified) for every route target imported by a locally-configured VPRN or BGP-based L2 VPN; this includes MVPN-specific route targets.
SR OS also supports a group/neighbor level default-route-target command that causes routers to generate and send a 0:0:0/0 default RTC route to one or more peers. Sending the default RTC route to a peer conveys a request to receive all VPN routes from that peer. The default-route-target command is typically configured on sessions that a route reflector has with its PE clients. A received default RTC route is never propagated to other routers.
The advertisement of RTC routes by a route reflector follows special rules that are described in RFC 4684. These rules are needed to ensure that RTC routes for the same NLRI that are originated by different PE routers in the same Autonomous System are properly distributed within the AS.
When a BGP session comes up, and RT-constrain is enabled on the session (both peers advertised the MP-BGP capability), routers delay sending any VPN-IPv4 and VPN-IPv6 routes until either the session has been up for 60 seconds or the End-of-RIB marker is received for the RT-constrain address family. When the VPN-IPv4 and VPN-IPv6 routes are sent they are filtered to include only those with a Route Target Extended Community that matches an RTC route from the peer. VPN-IP routes matching an RTC route originated in the local AS are advertised to any IBGP peer that advertises a valid path for the RTC NLRI. In other words, route distribution is not constrained to only the IBGP peer advertising the best path. On the other hand, VPN-IP routes matching an RTC route originated outside the local AS are only advertised to the EBGP or IBGP peer that advertises the best path.
Min route advertisement interval
According to the BGP standard (RFC 4271), a BGP router should not send updated reachability information for an NLRI to a BGP peer until a specific period of time, Min Route Advertisement Interval (MRAI), has elapsed from the last update. The RFC suggests the MRAI should be configurable per peer but does not propose a specific algorithm, and therefore, MRAI implementation details vary from one router operating system to another.
In SR OS, the MRAI is configurable, on a per-session basis, using the min-route-advertisement command. The min-route-advertisement command can be configured with any value between 1 and 255 seconds and the setting applies to all address families. The default value is 30 seconds, regardless of the session type (EBGP or IBGP). The MRAI timer is started at the configured value when the session is established and counts down continuously, resetting to the configured value whenever it reaches zero. Every time it reaches zero, all pending RIB-OUT routes are sent to the peer.
To send UPDATE messages that advertise new NLRI reachability information more frequently for some address families than others, SR OS offers a rapid-update command that overrides the remaining time on a peer's MRAI timer and immediately sends routes belonging to specified address families (and all other pending updates) to the peers receiving these routes. The address families that can be configured with rapid-update support are:
EVPN
L2-VPN
label-IPv4
label-IPv6
MCAST-VPN-IPv4
MCAST-VPN-IPv6
MDT-SAFI
MVPN-IPv4
MVPN-IPv6
VPN-IPv4
VPN-IPv6
In many cases, the default MRAI is appropriate for all address families (or at least those not included in the preceding list) when it applies to UPDATE messages that advertise reachable NLRI, but it is not the best option for UPDATE messages that advertise unreachable NLRI (route withdrawals). Fast re-convergence after some types of failures requires route withdrawals to propagate to other routers as quickly as possible so that they can calculate and start using new best paths, which would be impeded by the effect of the MRAI timer at each router hop. This is facilitated by the rapid-withdrawal configuration command.
When rapid-withdrawal is configured, UPDATE messages containing withdrawn NLRI are sent immediately to a peer without waiting for the MRAI timer to expire. UPDATE messages containing reachable NLRI continue to wait for the MRAI timer to expire, or for a rapid-update trigger, if it applies. When rapid-withdrawal is enabled, it applies to all address families.
When there is a change to a labeled-unicast route that requires reprogramming of the label operations in the data plane, these IOM updates are not made until the changed route is advertised to a peer, which depends on MRAI. Lowering the MRAI value or using rapid-update improves the speed of this operation.
Advertise-inactive
BGP does not allow a route to be advertised unless it is the best path in the RIB and an export policy allows the advertisement.
In some cases, it may be useful to advertise the best BGP path to peers despite the fact that is inactive. For example, because there are one or more preferred non-BGP routes to the same destination and one of these other routes is the active route. One way SR OS supports this flexibility is using the advertise-inactive command; other methods include best-external and add-paths.
When the BGP advertise-inactive command is configured so that it applies to a BGP session it has the following effect on the IPv4, IPv6, mcast-ipv4, mcast-ipv6, label-IPv4 and label-IPv6 routes advertised to that peer.
If the active route for the IP prefix is a BGP route then that route is advertised. If the active route for the IP prefix is a non-BGP route and there is at least one valid but inactive BGP route for the same destination then the best of the inactive and valid BGP routes is advertised unless the non-BGP active route is matched and accepted by an export policy applied to the session.
If the active route for the IP prefix is a non-BGP route and there are no (valid) BGP routes for the same destination then no route is advertised for the prefix unless the non-BGP active route is matched and accepted by an export policy applied to the session.
Best-external
Best-external is a BGP enhancement that allows a BGP speaker to advertise to its IBGP peers its best ‟external” route for a prefix/NLRI when its best overall route for the prefix/NLRI is an ‟internal” route. This is not possible in a normal BGP configuration because the base BGP specification prevents a BGP speaker from advertising a non-best route for a destination.
In specific topologies best-external can improve convergence times, reduce route oscillation and allow better loadsharing. This is achieved because routers internal to the AS have knowledge of more exit paths from the AS. Enabling add-paths on border routers of the AS can achieve a similar result but add-paths introduces NLRI format changes that must be supported by BGP peers of the border router and therefore has more interoperability constraints than best-external (which requires no messaging changes).
Best-external is supported in the base router BGP context. (A related feature is also supported in VPRNs; consult the Services Guide for more details.) It is configured using the advertise-external command, which provides IPv4, label-IPv4, IPv6, and label-IPv6 as options.
The advertisement rules when advertise-external is enabled can be summarized as follows.
If a router has advertise-external enabled and its best overall route is a route from an IBGP peer then this best route is advertised to EBGP and confed-EBGP peers, and the ‟best external” route is advertised to IBGP peers. The ‟best external” route is the one found by running the BGP path selection algorithm on all LOC-RIB paths except for those learned from the IBGP peers.
Note: A route reflector with advertise-external enabled does not include IBGP routes learned from other clusters in its definition of ‛external’.If a router has advertise-external enabled and its best overall route is a route from an EBGP peer then this best route is advertised to EBGP, confed-EBGP, and IBGP peers.
If a router has advertise-external enabled and its best overall route is a route from a confed-EBGP peer in member AS X then this best route is advertised to EBGP, IBGP peers and confed-EBGP peers in all member AS except X and the ‟best external” route is advertised to confed-EBGP peers in member AS X. In this case the ‟best external” route is the one found by running the BGP path selection algorithm on all RIB-IN paths except for those learned from member AS X.
Note: If the best-external route is not the best overall route it is not installed in the forwarding table and in some cases this can lead to a short-duration traffic loop after failure of the overall best path.
Add-paths
Add-paths is a BGP enhancement that allows a BGP router to advertise multiple distinct paths for the same prefix/NLRI. Add-Paths provides a number of potential benefits, including reduced routing churn, faster convergence, and better loadsharing.
For a router to receive multiple paths per NLRI from a peer, for a particular address family, the peer must announce the BGP capability to send multiple paths for the address family and the local router must announce the BGP capability to receive multiple paths for the address family. When the Add-Path capability has been negotiated this way, all advertisements and withdrawals of NLRI by the peer must include a path identifier. The path identifier has no significance to the receiving router. If the combination of NLRI and path identifier in an advertisement from a peer is unique (does not match an existing route in the RIB-IN from that peer) then the route is added to the RIB-IN. If the combination of NLRI and path identifier in a received advertisement is the same as an existing route in the RIB-IN from the peer then the new route replaces the existing one. If the combination of NLRI and path identifier in a received withdrawal matches an existing route in the RIB-IN from the peer, then that route is removed from the RIB-IN.
An UPDATE message carrying an IPv4 NLRI with a path identifier is shown in BGP update message with path identifier for IPv4 NLRI.
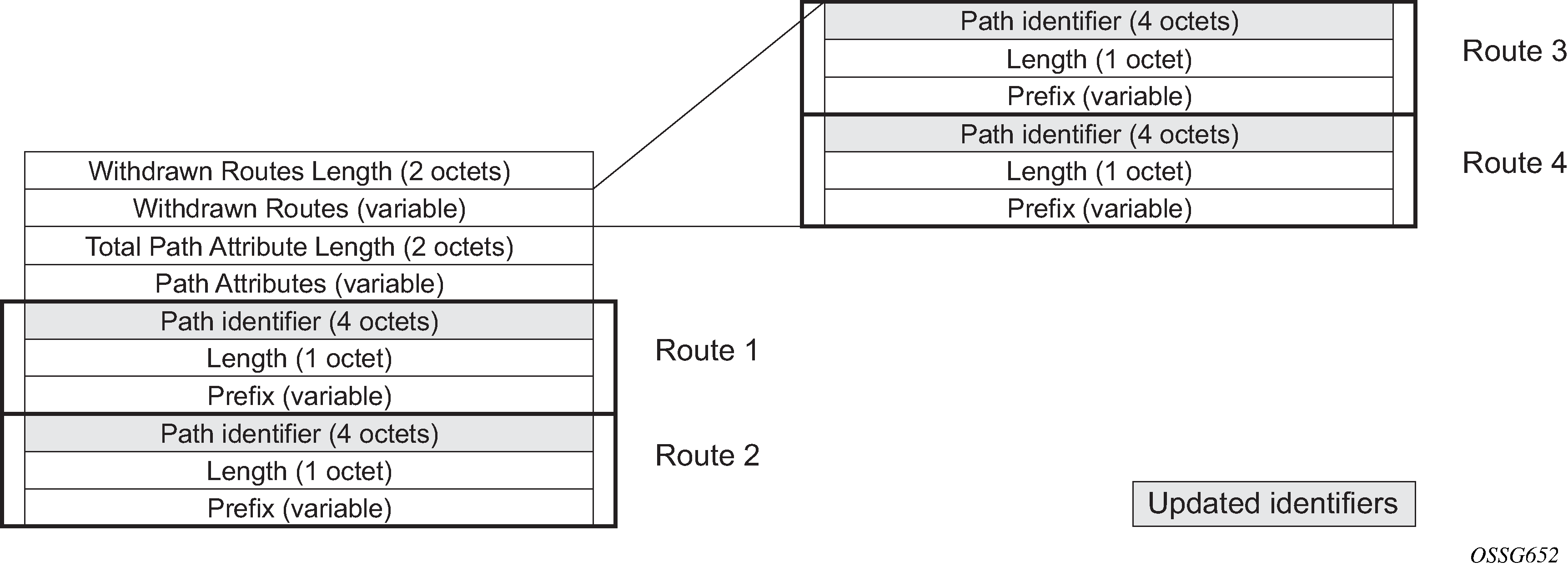
Add-paths is only supported by the base router BGP instance and the EBGP and IBGP sessions it forms with other peers capable of add-paths. The ability to send and receive multiple paths per prefix is configurable per family, and supported for the following options:
IPv4
label-IPv4
VPN-IPv4
IPv6
label-IPv6
VPN-IPv6
MCAST-VPN-IPv4
MCAST-VPN-IPv6
MVPN-IPv4
MVPN-IPv6
EVPN
Path selection with add-paths
The local RIB may have multiple paths for a prefix. The path selection mode refers to the algorithm used to decide which paths to advertise to an add-paths peer. SR OS supports a send N path selection algorithm (See draft-ietf-idr-add-paths-guidelines) and a send multipaths selection algorithm.
The send N algorithm selects the N best advertisable paths that meet the following constraints.
The BGP next-hop of the route is unique.
The BGP route is not rejected by an export policy.
The BGP route is not blocked by a split-horizon rule.
The number of advertised paths does not exceed N. N is derived from the send-limit of the best BGP RIB-IN as applied by BGP import policy action or the configuration of the add-paths command that applies to the neighbor and the address family.
The send multipaths algorithm selects the N best advertisable paths that meet the following constraints.
The BGP route is a multipath (in other words, it is tied with the best path up to and including the NH-cost comparison step of the decision process, skipping steps that do not apply).
The BGP next-hop of the route is unique.
The BGP route is not rejected by an export policy.
The BGP route is not blocked by a split-horizon rule.
Split-horizon
Split-horizon refers to the action taken by a router to avoid advertising a route back to the peer from which it was received. By default, SR OS applies split-horizon behavior only to routes received from IBGP non-client peers, and split-horizon only works for routes to non-imported routes within a RIB. This split-horizon functionality, which can never be disabled, prevents a route learned from a non-client IBGP peer to be advertised to the sending peer or any other non-client peer.
To apply split-horizon behavior to routes learned from RR clients, confed-EBGP peers or (non-confed) EBGP peers the split-horizon command must be configured in the appropriate contexts; it is supported at the global BGP, group and neighbor levels. When split-horizon is enabled on these types of sessions, it only prevents the advertisement of a route back to its originating peer; for example, SR OS does not prevent the advertisement of a route learned from one EBGP peer back to a different EBGP peer in the same neighbor AS.
BGP monitoring protocol
The BGP Monitoring Protocol (BMP) provides a monitoring station that obtains route updates and statistics from a BGP router. The BMP protocol is described in detail in RFC 7854, BGP Monitoring Protocol (BMP). A router communicates information about one or more BGP sessions to a BMP station. Specifically, BMP allows a BGP router to advertise the pre-policy or post-policy BGP RIB-In from specific BGP peers to a monitoring station. This allows the monitoring station to monitor the routing table size, identify issues, and monitor trends in the table size and update or withdraw the frequency. The BMP station is also sometimes called a BMP collector. A router sends information in BMP messages to a BMP station.
BMP is a unidirectional protocol. A BMP station never sends back any messages to a router.
BMP allows a router to report different types of information.
A router can send BMP messages with notifications when neighbors go into or out of the established mode (for example, when the peer goes up or down). These notifications are called BMP peer-up and peer-down messages.
A router can periodically send statistical information about one or more neighbors. This information consists of a number of counters, for example, the number of routes received from a particular neighbor or the number of rejected or accepted routes because of ingress policy parameters.
Other counters report the number of errors that were encountered, for example, AS-path loops, duplicate prefixes, or withdrawals received.
A router can also report the exact routes received from a particular neighbor. This action is called route monitoring. A router encapsulates a BGP route into the original BGP update message, then encapsulates that BGP update message in a BMP route monitoring message.
BMP on an SR OS router reports information about routes that were received from a neighbor. The SR OS cannot report routes that were sent to a neighbor.
When periodic statistics are enabled, the router sends all the statistics as described in RFC 7854, section 4.8, with the exception of statistic number 13, ‟Number of duplicate update messages received”. The supported statistics are listed in Supported statistics.
| Statistic | Type |
|---|---|
Number of Prefixes rejected by inbound policy |
0 |
Number of duplicate prefix advertisements received |
1 |
Number of duplicate withdraws received |
2 |
Number of invalidated prefixes because of Cluster_List loop detection |
3 |
Number of invalidated prefixes because of AS_PATH loop detection |
4 |
Number of invalidated prefixes because of Originator ID validation |
5 |
Number of invalidated prefixes because AS-Confed loop detection |
6 |
Total number of routes in adj-rib-in (all families) |
7 |
Total number of routes in Local-RIB (all families)` |
8 |
Number of routes per address-family in adj-rib-in |
9 |
Number of routes per address-family in loc-rib |
10 |
Number of updates subjected to treat-as-withdraw |
11 |
Number of prefixes subjected to treat-as-withdraw |
12 |
The values in these counters are the same values that can be seen in the output of the following commands.
show router bgp neighbor
show router bgp neighbor detailBGP applications
SR OS implements the following BGP application:
BGP FlowSpec
FlowSpec is a standardized method for using BGP to distribute traffic flow specifications (flow routes) throughout a network. A flow route carries a description of a flow in terms of packet header fields such as source IP address, destination IP address, or TCP/UDP port number and indicates (through a community attribute) an action to take on packets matching the flow. The primary application for FlowSpec is DDoS mitigation.
FlowSpec is supported for both IPv4 and IPv6. To exchange non-VPN-aware IPv4 FlowSpec routes with a BGP peer, flow-ipv4 must be enabled in the family configuration that applies to the session. To exchange non-VPN-aware IPv6 FlowSpec routes with a BGP peer, flow-ipv6 must be enabled in the relevant family configuration. The IP filter entries created from non-VPN-aware FlowSpec routes can only be used on the IP interfaces of the base or VPRN router instance that received the FlowSpec routes.
SR OS BGP also supports VPN-aware FlowSpec routes. These SAFI 134 routes carry Route Distinguisher (RD) and RT Extended Communities. To exchange VPN-aware IPv4 FlowSpec routes with an IBGP peer of the base router, flow-vpn-ipv4 must be enabled in the family configuration that applies to the session. To exchange VPN-aware IPv6 FlowSpec routes with an IBGP peer of the base router, flow-vpn-ipv6 must be enabled in the relevant family configuration. IP filter entries are created from a VPN-aware FlowSpec route when the route is imported into a locally configured VPRN. This is done by appropriately configuring a VRF import or VRF target policy for the VPRN. There must also be an IP filter policy applied to the IP interfaces of the VPRN that embeds FlowSpec routes.
The NLRI of a FlowSpec IPv4 or FlowSpec-VPN IPv4 route can contain one or more of the subcomponents shown in Subcomponents of FlowSpec IPv4 and FlowSpec-VPN IPv4 NLRI.
| Subcomponent name [type] | Value encoding | SR OS support |
|---|---|---|
|
Destination IPv4 prefix [1] |
Prefix length, prefix |
Yes |
|
Source IPv4 prefix [2] |
Prefix length, prefix |
Yes |
|
IP protocol [3] |
One or more (operator, value) pairs |
Partial. No support for multiple values other than ‟TCP or UDP”. |
|
Port [4]1 |
One or more (operator, value) pairs |
Yes. Support single port, port-range. |
|
Destination port [5] |
One or more (operator, value) pairs |
Yes. Support single port, port-range. |
|
Source port [6] |
One or more (operator, value) pairs |
Yes. Support single port, port-range. |
|
ICMP type [7] |
One or more (operator, value) pairs |
Partial. Only a single value is supported. |
|
ICMP code [8] |
One or more (operator, value) pairs |
Partial. Only a single value is supported. |
|
TCP flags [9] |
The following restrictions apply:
|
Yes |
|
Packet length [10] |
One or more (operator, value) pairs |
Yes. Support single packet-length or range. |
|
DSCP [11] |
One or more (operator, value) pairs |
Partial. Only a single value is supported. |
|
Fragment [12] |
One or more (operator, bitmask) pairs |
Partial. No support for matching Last Fragment. |
The NLRI of a FlowSpec IPv6 or FlowSpec-VPN IPv6 route can contain one or more of the subcomponents shown in Subcomponents of FlowSpec IPv6 and FlowSpec-VPN IPv6 NLRI.
| Subcomponent name [type] | Value encoding | SR OS support |
|---|---|---|
|
Destination IPv6 prefix [1] |
Prefix length, prefix offset, prefix |
Partial. No support for prefix offset. |
|
Source IPv6 prefix [2] |
Prefix length, prefix offset, prefix |
Partial. No support for prefix offset. |
|
Next header [3] |
One or more (operator, value) pairs |
Partial. Only a single value supported. |
|
Port [4]1 |
One or more (operator, value) pairs |
Yes. Support single port, port-range. |
|
Destination port [5] |
One or more (operator, value) pairs |
Yes. Support single port, port-range. |
|
Source port [6] |
One or more (operator, value) pairs |
Yes. Support single port, port-range. |
|
ICMP type [7] |
One or more (operator, value) pairs |
Partial. Only a single value is supported. |
|
ICMP code [8] |
One or more (operator, value) pairs |
Partial. Only a single value is supported. |
|
TCP flags [9] |
The following restrictions apply:
|
Yes |
|
Packet length [10] |
One or more (operator, value) pairs |
Yes. Support single packet-length or range. |
|
Traffic class [11] |
One or more (operator, value) pairs |
Partial. Only a single value is supported. |
|
Fragment [11] |
One or more (operator, bitmask) pairs |
Partial. No support for matching Last Fragment. |
|
Flow label [13] |
One or more (operator, value) pairs |
Partial. Only a single value is supported. |
IPv4 FlowSpec actions summarizes the actions that may be associated with FlowSpec IPv4 and FlowSpec-VPN IPv4 routes. IPv6 FlowSpec actions summarizes the actions that may be associated with FlowSpec IPv6 and FlowSpec-VPN IPv6 routes.
| Action | Encoding | SR OS support |
|---|---|---|
Rate limit |
Extended community type 0x8006 |
Yes |
Sample/log |
Extended community type 0x8007 S-bit |
Yes |
Next entry |
Extended community type 0x8007 T-bit |
— |
Redirect to VRF |
Extended community type 0x8008 |
Yes |
Mark traffic class |
Extended community type 0x8009 |
Yes |
Redirect to IPv4 |
Extended community type 0x010c |
Yes |
Redirect to IPv6 |
Extended community type 0x000c |
— |
Redirect to LSP |
Extended community type 0x0900 |
Partial, only support for ID-type 0x00 (localized ID) |
| Action | Encoding | SR OS support |
|---|---|---|
rate limit |
Extended community type 0x8006 |
Yes |
sample/log |
Extended community type 0x8007 S-bit |
Yes |
next entry |
Extended community type 0x8007 T-bit |
— |
Redirect to VRF |
Extended community type 0x8008 |
Yes |
Mark traffic class |
Extended community type 0x8009 |
Yes |
Redirect to IPv4 |
Extended community type 0x010c |
— |
Redirect to IPv6 |
Extended community type 0x000c |
Yes |
Redirect to LSP |
Extended community type 0x0900 |
Partial, only support for ID-type 0x00 (localized ID) |
Validating received FlowSpec routes
Received non-VPN-aware FlowSpec routes are validated following the procedures described in RFC 5575 and draft-ietf-idr-bgp-flowspec-oid-03, Revised Validation Procedure for BGP Flow Specifications. Configure the validate-dest-prefix command in a routing instance to enable validation checks based on the destination prefix. By default, this check is not performed. When the command is enabled, BGP determines whether a non-VPN-aware FlowSpec route is valid or invalid based on the following logic:
If the FlowSpec route was originated in the same Autonomous System (AS) as the receiving BGP router, it is automatically valid.
If rule 1 does not apply, the FlowSpec route was originated in an external AS, and it does not contain a destination prefix subcomponent, it is considered valid.
If rule 1 does not apply, the FlowSpec route was originated in an external AS, and it does contain a destination prefix subcomponent, it is considered valid if all of the following are true:
The neighbor AS (last non-confed AS in the AS_PATH) of the FlowSpec route matches the neighbor AS of the unicast IP route that is the best match of the destination prefix. The best match unicast IP route must be a BGP route (that is, not static, IGP, or other routes).
The neighbor AS of the FlowSpec route matches the neighbor AS of all unicast IP routes that are longer matches of the destination prefix. All longer match unicast IP routes must be BGP routes (that is, not static, IGP, or other routes).
Non-VPN-aware FlowSpec routes that are received with a redirect-to-IPv4 extended community action are also subject to an additional set of validation checks. If the validate-redirect-ip command is enabled in the receiving BGP instance, a non-VPN-aware FlowSpec route is considered invalid, if it is deemed to have originated in a different AS than the IP route that resolves the redirection IPv4 address. The originating AS of a FlowSpec route is determined from its AS paths.
A FlowSpec route that is determined to be invalid by any of the validation rules described earlier is retained in the BGP RIB, but not used for traffic filtering and not propagated to other BGP speakers.
Using flow routes to create dynamic filter entries
When the base router BGP instance receives a non-VPN-aware flow IPv4 or IPv6 route that is considered valid and best, the system attempts to construct an IPv4 or IPv6 filter entry from the NLRI contents and actions encoded in the UPDATE message. If successful, the filter entry is added to the system-created ‟fSpec-0” IPv4 embedded filter or to the ‟fSpec-0” IPv6 embedded filter. These embedded filters can be inserted into configured IPv4 and IPv6 filter policies that are applied to ingress traffic on a selected set of the base router IP interfaces. These interfaces can include network interfaces, IES SAP interfaces, and IES spoke SDP interfaces.
When the VPRN BGP instance receives a non-VPN-aware flow IPv4 or IPv6 route from a BGP peer of the VPRN or imports a VPN-aware FlowSpec-VPN IPv4 or IPv6 route that was received in the base router BGP instance and considered to be valid and best, the system attempts to construct an IPv4 or IPv6 filter entry from the NLRI contents and actions encoded in the UPDATE message. If successful, the filter entry is added to the system-created "fSpec-$vprnid" IPv4 embedded filter or to the "fSpec-$vprnid" IPv6 embedded filter. $vprnid represents a parameter value that is unique to each VPRN. These embedded filters can be inserted into configured IPv4 and IPv6 filter policies that are applied to ingress traffic on one or more of the IP interfaces on the VPRN.
When FlowSpec rules are embedded into a user-defined filter policy, configure the insertion point of the rules using the following commands:
-
MD-CLI
configure filter ip-filter embed flowspec offset configure filter ipv6-filter embed flowspec offset -
classic CLI
configure filter ip-filter embed-filter flowspec offset configure filter ipv6-filter embed-filter flowspec offset
The sum of the configured maximum number of FlowSpec routes and offset must not exceed the maximum filter entry ID range.
BGP FlowSpec steering toward the SRv6 policy
BGP FlowSpec is enhanced to facilitate IPv6 traffic steering toward a remote IPv6 address in an SRv6 policy. This enhancement adds supplementary information, such as the redirect IPv6 next-hop, color, and SRv6 service SID. The system uses this information to guide specific traffic that matches the FlowSpec filter Network Layer Reachability Information (NLRI) toward the designated SRv6 policy.
FlowSpec refers to the use of BGP to distribute traffic flow specifications (flow routes) throughout a network. A flow route carries a description of a flow in the packet header fields such as source IP address, destination IP address, and TCP/UDP port number, and indicates (using BGP communities) an action to take on packets matching the flow.
The draft-ietf-idr-ts-flowspec-srv6-policy-03 document defines the use of BGP FlowSpec to direct traffic toward an SRv6 policy. This process involves leveraging existing FlowSpec and localized Policy-Based Routing (PBR) capabilities, with no novel BGP attributes.
The ietf-idr-FlowSpec-redirect-ip-02 document defines the framework for redirecting traffic to both IPv4 and IPv6 next-hop addresses. The FlowSpec steering to the SRv6 policy uses the IPv6 extended community as a destination point for the SRv6 policy.
After reaching the SRv6 policy tail-end device, specific identifiers determine the processing steps for the flows. The BGP prefix-SID, as defined in RFC 8669, plays a role in enabling SRv6 VPN services (defined in RFC 9252).The SRv6 service TLVs of the BGP prefix-SID attribute indicate endpoint functions that serve as service SIDs to guide the processing of incoming packets at the policy endpoint. The BGP-encoded SRv6 TLV must be an SRv6 L3 Service TLV to extract a valid SRv6 Service SID.
The draft-ietf-idr-ts-flowspec-srv6-policy-03 document introduces the color extended community within a FlowSpec NLRI context, as defined in RFC 8955 and RFC 8956. This feature serves to select the appropriate SRv6 SR policy.
Conditions
The following FlowSpec validation conditions apply for steering to an SRv6 policy:
- When the FlowSpec IPv6 extended community exists but either the color extended community or BGP prefix-SID is missing, the FlowSpec steering falls back to the redirect-IP action.
- If the FlowSpec NLRI is missing the IPv6 extended community but has the color extended community, or the BGP prefix-SID, then no steering to redirect-IP or SR-policy happens and no other FlowSpec action is considered.
Restrictions
The following restrictions apply:
- The feature only supports combining one color extended community with one BGP prefix-SID attribute.
- The SRv6 Service TLV in the SRv6 policy must be the L3 Service TLV.
- The feature does not support combining redirect-to-VRF and redirect-to-IP extended communities for a single FlowSpec NLRI.
- The feature does not support a received redirect-to-IP extended community with C=1 set in the local administrator field of the redirect-to-IP extended community.
- An unsupported FlowSpec entry is handled as an exception and the system generates a log for unsupported actions and creates no filter entry. However, the entry is propagated as if the BGP route was used.
Configuration of TTL propagation for BGP label routes
This feature allows the separate configuration of TTL propagation for in transit and CPM generated IP packets at the ingress LER within a BGP label route context.
TTL propagation for RFC 8277 label route at ingress LER
For IPv4 and IPv6 packets forwarded using a RFC 8277 label route in the global routing instance, including label-IPv6, the following command specified with the all value enables TTL propagation from the IP header into all labels in the transport label stack:
config router ttl-propagate label-route-local [none | all]
config router ttl-propagate label-route-transit [none | all]
The none value reverts to the default mode which disables TTL propagation from the IP header to the labels in the transport label stack.
These commands do not have a no version.
The TTL of the IP packet is always propagated into the RFC 8277 label itself. The commands only control the propagation into the transport labels, for example, the labels of the RSVP or LDP LSP which the BGP label route resolves to and which are pushed on top of the BGP label.
If the BGP peer advertised the implicit-null label value for the BGP label route, the TTL propagation does not follow the configuration described, but follows the configuration to which the BGP label route resolves:
RSVP LSP shortcut:
configure router mpls shortcut-transit-ttl-propagate
configure router mpls shortcut-local-ttl-propagate
LDP LSP shortcut:
configure router ldp shortcut-transit-ttl-propagate
configure router ldp shortcut-local-ttl-propagate
This feature does not impact packets forwarded over BGP shortcuts. The ingress LER operates in uniform mode by default and can be changed into pipe mode using the configuration of TTL propagation for RSVP or LDP LSP shortcut.
TTL propagation for RFC 8277 label routes at LSR
This feature configures the TTL propagation for transit packets at a router acting as an LSR for a BGP label route.
When an LSR swaps the BGP label for a IPv4 prefix packet, therefore acting as a ABR, ASBR, or data-path Route-Reflector (RR) in the base routing instance, or swaps the BGP label for a vpn-IPv4 or vpn-IPv6 prefix packet, therefore acting as an inter-AS Option B VPRN ASBR or VPRN data path Route-Reflector (RR), the all value of the following command enables TTL propagation of the decremented TTL of the swapped BGP label into all LDP or RSVP transport labels.
configure router ttl-propagate lsr-label-route [none | all]
When an LSR swaps a label or stitches a label, it always writes the decremented TTL value into the outgoing swapped or stitched label. What the above CLI controls is whether this decremented TTL value is also propagated to the transport label stack pushed on top of the swapped or stitched label.
The none value reverts to the default mode which disables TTL propagation. This changes the existing default behavior which propagates the TTL to the transport label stack. When a customer upgrades, the new default becomes in effect. The above commands do not have a no version.
The following describes the behavior of LSR TTL propagation in a number of other use cases and indicates if the above CLI command applies or not.
When an LSR stitches an LDP label to a BGP label, the decremented TTL of the stitched label is propagated or not to the LDP or RSVP transport labels as per the above configuration.
When an LSR stitches a BGP label to an LDP label, the decremented TTL of the stitched label is automatically propagated into the RSVP label if the outgoing LDP LSP is tunneled over RSVP. This behavior is not controlled by the above CLI.
When an LSR pops a BGP label and forwards the packet using an IGP route (IGP route to destination of prefix wins over the BGP label route), it pushes an LDP label on the packet and the TTL behavior is as described in the previous bullet when stitching from a BGP label to an LDP label.
When an ingress Carrier Supporting Carrier (CsC) PE swaps the incoming EBGP label into a VPN-IPv4 label. The reverse operation is performed by the egress CsC PE. In both cases, the decremented TTL of the swapped label is or is not passed on to the LDP or RSVP transport labels as per the above configuration.
BGP prefix origin validation
BGP prefix origin validation is a solution developed by the IETF SIDR working group for reducing the vulnerability of BGP networks to prefix mis-announcements and specific man-in-the-middle attacks. BGP has traditionally relied on a trust model where it is assumed that when an AS originates a route it has the right to announce the associated prefix. BGP prefix origin validation takes extra steps to ensure that the origin AS of a route is valid for the advertised prefix.
7450, 7750, and 7950 routers support BGP prefix origin validation for IPv4 and IPv6 routes received from selected peers. When prefix origin validation is enabled on a base router BGP or VPRN BGP session using the enable-origin-validation command, every received IPv4, IPv6, or both route received from the peer is checked to determine whether the origin AS is valid for the received prefix. The origin AS is the first AS that was added to the AS_PATH attribute and indicates the autonomous system that originated the route.
For purposes of determining the origin validation state of received BGP routes, the router maintains an Origin Validation database consisting of static and dynamic entries. Each entry is called a VRP (Validated ROA Payload) and associates a prefix (range) with an origin AS.
Static VRP entries are configured using the static-entry command in the configure router origin-validation context of the base router. In SR OS, a static entry can express that a specific prefix and origin AS combination is either valid or invalid.
Dynamic VRP entries are learned from RPKI local cache servers and express valid origin AS and prefix combinations. The router communicates with RPKI local cache servers using the RPKI-RTR protocol. SR OS supports the RPKI-RTR protocol over TCP/IPv4 or TCP/IPv6 transport; TCP-MD5 and other forms of session security are not supported. 7450, 7750, and 7950 routers can set up an RPKI-RTR session using the base routing table (in-band) or the management router (out-of-band). Dynamic VRP entries are configured and displayed using the RPKI commands in the configure router origin-validation and show router origin-validation contexts. For command information, see the following:
-
MD-CLI
7450 ESS, 7750 SR, 7950 XRS, and VSR MD-CLI Command Reference Guide
7450 ESS, 7750 SR, 7950 XRS, and VSR Clear, Monitor, Show, and Tools Command Reference Guide
-
classic CLI
7450 ESS, 7750 SR, 7950 XRS, and VSR Classic CLI Command Reference Guide
7450 ESS, 7750 SR, 7950 XRS, and VSR Clear, Monitor, Show, and Tools Command Reference Guide
An RPKI local cache server is one element of the larger RPKI system. The RPKI is a distributed database containing cryptographic objects relating to Internet Number resources. Local cache servers are deployed in the service provider network and retrieve digitally signed Route Origin Authorization (ROA) objects from Global RPKI servers. The local cache servers cryptographically validate the ROAs before passing the information along to the routers.
The algorithm used to determine the origin validation states of routes received over a session with enable-origin-validation configured uses the following definitions:
A route is matched by a VRP entry if all of the following occurs:
the prefix bits in the route match the prefix bits in the VRP entry (up to its min prefix length
the route prefix length is greater than or equal to the VRP entry min prefix length
the route prefix length is less than or equal to the VRP entry max prefix length
the origin AS of the route matches the origin AS of the VRP entry
A route is covered by a VRP entry if all of the follow occurs:
the prefix bits in the route match the prefix bits in the VRP entry (up to its min prefix length)
the route prefix length is greater than or equal to the VRP entry min prefix length
the VRP entry type is static-valid or dynamic
Using the above definitions, the origin validation state of a route is based on the following rules.
If a route is matched by at least one VRP entry, and the most specific of these matching entries includes a static-invalid entry then the origin validation state is Invalid (2).
If a route is matched by at least one VRP entry, and the most specific of these matching entries does not include a static-invalid entry then the origin validation state is Valid (0).
If a route is not matched by any VRP entry, but it is covered by at least one VRP entry then the origin validation state is Invalid (2).
If a route is not covered by any VRP entry then the origin validation state is Not-Found (1).
Consider the following example. Suppose the Origin Validation database has the following entries:
10.1.0.0/16-32, origin AS=5, dynamic
10.1.1.0/24-32, origin AS=4, dynamic
10.0.0.0/8-32, origin AS=5, static invalid
10.1.1.0/24-32, origin AS=4, static invalid
In this case, the origin validation state of the following routes are as indicated:
10.1.0.0/16 with AS_PATH {…5}: Valid
10.1.1.0/24 with AS_PATH {…4}: Invalid
10.2.0.0/16 with AS_PATH {…5}: Invalid
10.2.0.0/16 with AS_PATH {…6}: Not-Found
The origin validation state of a route can affect its ranking in the BGP decision process. When origin-invalid-unusable is configured, all routes that have an origin validation state of ‛Invalid’ are considered unusable by the best path selection algorithm, that is, they cannot be used for forwarding and cannot be advertised to peers.
If origin-invalid-unusable is not configured then routes with an origin validation state of ‛Invalid’ are compared to other ‟usable” routes for the same prefix according to the BGP decision process.
When compare-origin-validation-state is configured a new step is added to the BGP decision process after removal of invalid routes and before the comparison of local preference. The new step compares the origin validation state, so that a route with a ‛Valid’ state is preferred over a route with a ‛Not-Found’ state, and a route with a ‛Not-Found’ state is preferred over a route with an ‛Invalid’ state assuming that these routes are considered ‛usable’. The new step is skipped if the compare-origin-validation-state command is not configured.
Route policies can be used to attach an Origin Validation State extended community to a route received from an EBGP peer to convey its origin validation state to IBGP peers and save them the effort of repeating the Origin Validation database lookup. To add an Origin Validation State extended community encoding the ‛Valid’ result, the route policy should add a community list that contains a member in the format ext:4300:0. To add an Origin Validation State extended community encoding the ‛Not-Found’ result, the route policy should add a community list that contains a member in the format ext:4300:1. To add an Origin Validation State extended community encoding the ‛Invalid’ result, the route policy should add a community list that contains a member in the format ext:4300:2.
BGP route leaking
It is possible to leak a copy of a BGP route (including all its path attributes) from one routing instance RIB to another routing instance RIB of the same type (labeled or unlabeled) in the same router. Leaking is supported from the GRT to a VPRN, from one VPRN to another VPRN, and from a VPRN to the GRT. Any valid BGP route for an IPv4, IPv6, label-IPv4, or label-IPv6 prefix can be leaked. A BGP route does not have to be the best path or used for forwarding in the source instance to be leaked.
An IPv4, IPv6, label-IPv4, or label-IPv6 BGP route becomes a candidate for leaking to another instance when it is specially marked by a BGP import policy. The operator can achieve this special marking by accepting the route with a bgp-leak action in the route policy. Routes that are candidates for leaking to other instances show a leakable flag in the output of various show router BGP commands. To copy a leakable BGP route received in a specific source instance into the BGP RIB of a specific target instance, the operator must configure the target instance with a leak-import policy that matches and accepts the leakable route. The operator can specify different leak-import policies for each of the following RIBs: IPv4, label-IPv4, IPv6, and label-IPv6. Up to 15 leak-import policies can be chained together for more complex use cases. The leak-import policies are configured in various config>router>bgp>rib-management contexts.
In the target instance, leaked BGP routes are compared to other (leaked and non-leaked) BGP routes for the same prefix based on the complete BGP decision process. Leaked routes do not have information about the router ID and peer IP address of the original peer and use all-zero values for these properties.
BGP always tries to resolve the BGP next hop of a leaked route using the route and tunnel table of the original (source) routing instance and this resolution information is carried with the leaked route, avoiding the need to leak the resolving routes as well. If BGP cannot resolve the route or tunnel in the source instance, the unresolved route cannot be leaked unless allow-unresolved-leaking is configured and the source routing instance is the GRT. In this case, the importing VPRN tries to resolve the BGP next hop of the leaked route by using its own route table (and according to its own BGP next-hop-resolution configuration options).
If a target instance has BGP multipath and ECMP enabled and some of the equal-cost best paths for a prefix are leaked routes, they can be used along with non-leaked best paths as ECMP next hops of the route.
When BGP fast reroute is enabled in a target instance (for a particular IP prefix), BGP attempts to find a qualifying backup path by considering both leaked and non-leaked BGP routes. The backup path criteria are unchanged by this feature, that is, the backup path is the best remaining path after the primary paths and all paths with the same BGP next hops as the primary paths have been removed.
A leaked BGP route can be advertised to direct BGP neighbors of the target routing instance.
The BGP next hop of a leaked route is automatically reset to itself whenever it is advertised to a peer of the target instance. Normal route advertisement rules apply, meaning that by default, the leaked route is advertised only if (in the target instance) it is the overall best path and is used as the active route to the destination and is not blocked by the IBGP-to-IBGP split-horizon rule.
A BGP route resolved in the source routing instance and leaked into a VPRN can be exported from the VPRN as a VPN-IPv4 or VPN-IPv6 route if it matches the VRF export policy. In this case, normal VPN export rules apply, meaning that by default, the leaked route is exported only if (in the VPRN) it is the overall best path and is used as the active route to the destination.
A BGP route that is unresolved in the GRT, leaked into a VPRN, and resolved by a BGP-VPN route in the VPRN cannot be exported from the VPRN as a VPN-IPv4 or VPN-IPv6 route unless it matches the VRF export policy and the VPRN is configured with the allow-bgp-vpn-export command.
BGP optimal route reflection
BGP Route Reflectors (RRs) are used in networks to improve network scalability by eliminating or reducing the need for a full-mesh of IBGP sessions. When a BGP RR receives multiple paths for the same IP prefix, it typically selects a single best path to send to all clients. If the RR has multiple nearly-equal best paths and the tie-break is determined by the next-hop cost, the RR advertises the path based on its view of next-hop costs. The advertised route may differ from the path that a client would select if it had visibility of the same set of candidate paths and used its own view of next-hop costs.
Non-optimal advertisements by the RR can be a problem in hot-potato routing designs. Hot-potato routing aims to hand off traffic to the next AS using the closest possible exit point from the local AS. In this context, the closest exit point implies minimum IGP cost to reach the BGP next-hop. SR OS implements the hot-potato routing solution described in draft-ietf-idr-bgp-optimal-route-reflection.
Optimal Route Reflection (ORR) is supported in the base router BGP instance only. It applies to routes in the following address families: IPv4 unicast, label-IPv4, label-IPv6 (6PE), VPN-IPv4, and VPN-IPv6.
ORR locations are created when config>router>bgp>orr>location is configured. The RR can maintain information for a maximum of 255 ORR locations. A primary IPv4 or primary IPv6 address is required for each location; optionally, specify a secondary and tertiary IPv4 and IPv6 addresses for the location. The IP addresses are used to find a node in the network topology that can serve as the root for SPF calculations. The IP addresses must correspond to loopback or system IP addresses of routers that participate in IGP protocols. The secondary and tertiary IP address parameters provide redundancy in case the node selected to be root for the SPF calculations disappears.
The route reflector's TE database, populated with information from local IGP instances or BGP-LS NLRI, is used to compute the SPF cost from each ORR location to IPv4 and IPv6 BGP next-hops in the candidate set of best paths. The use of BGP-LS allows the route reflector to learn IGP topology information for OSPF areas, IS-IS levels, and others in which the route reflector is not a direct participant.
To configure an ORR client, configure the cluster command for the BGP session to reference one of the defined ORR locations. The association of a client with an ORR location is not automatic. Choose an ORR location as close as possible to the client that is being configured. The allow-local-fallback option of the cluster command affects RR behavior when no BGP routes are reachable from the ORR location of the client. When allow-local-fallback is configured, the RR is allowed, in this circumstance only, to advertise the best reachable BGP path from its own topology location. If allow-local-fallback is not configured and this situation applies, then no route is advertised to the client.
LSP tagging for BGP next-hops or prefixes and BGP-LU
The tunnels used by the system for resolution of BGP next-hops or prefixes and BGP labeled unicast routes can be constrained using LSP administrative tags. For more information, see the 7450 ESS, 7750 SR, 7950 XRS, and VSR MPLS Guide, 'LSP Tagging and Auto-Bind Using Tag Information'.
BGP-LS
BGP-LS is a new BGP address family that is intended to distribute IGP topology information to external servers such as Application Later Traffic Optimization (ALTO) or Path Computation Engines (PCE) servers. These external traffic engineering databases can then use this information when calculating optimal paths.
BGP-LS provides external ALTO and PCE servers with topology information for a multi-area or multi-level network. Through the use of one or two BGP-LS speakers per area or level, the external ALTO or PCE servers can receive full topology information for the entire network. The BGP-LS information can also be distributed through route reflectors supporting the BGP-LS to minimize the peering requirements.
Example BGP-LS network shows an example BGP-LS network.
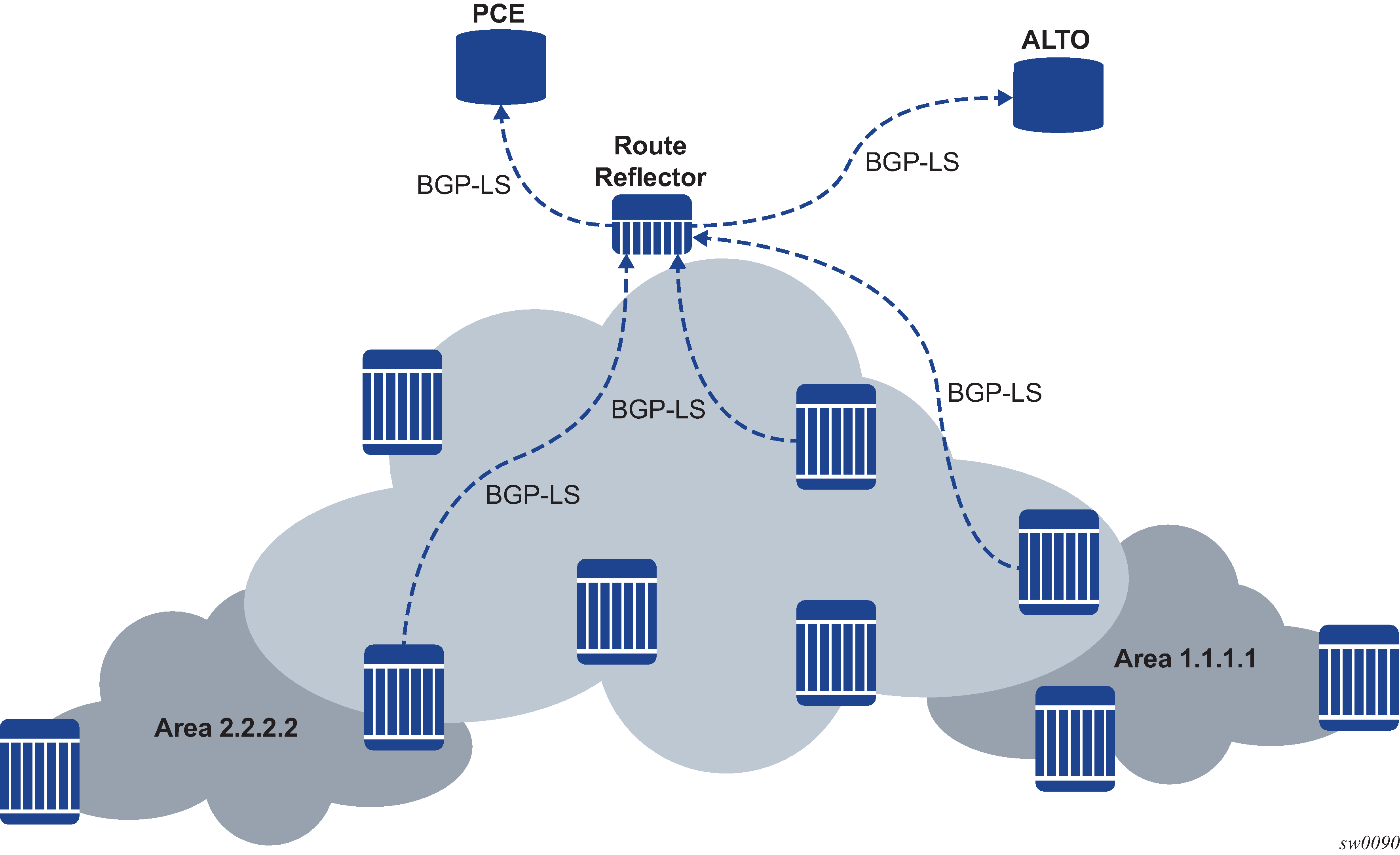
Supported BGP-LS components
The following BGP-LS components are currently supported.
Protocol-ID
-
IS-IS level 1
-
IS-IS level 2
-
OSPFv2
-
BGP
NLRI Types
-
Node NLRI
-
Link NLRI
-
IPv4 Topology Prefix NLRI
-
IPv6 Topology Prefix NLRI
-
SRv6 SID
Node Descriptor TLVs
-
512 — Autonomous System
-
513 — BGP-LS Identifier
-
514 — OSPF Area-ID
-
515 — IGP Router-ID
Node Attribute TLVs
-
263 — Multi-Topology ID (IS-IS only)
-
266 — Node MSD
-
1024 — Node Flag Bits (O and B bits supported)
-
1026 — Node Name
-
1027 — IS-IS Area Identifier
-
1028 — IPv4 Router ID of Local Node (Only supported for IS-IS; Only when received from remote router. Not supported for local links.)
-
1029 — IPv6 Router-ID of Local Node (only supported for IS-IS)
-
1032 — S-BFD Discriminators
-
Segment Routing
-
1034 — SR Capabilities
-
1035 — SR Algorithm
-
1038 — SRv6 Capabilities
-
1039 — Flexible Algorithm Definition
-
1040 — Flexible Algorithm Exclude-Any Affinity
-
1041 — Flexible Algorithm Include-Any Affinity
-
1042 — Flexible Algorithm Include-All Affinity
-
1043 — Flexible Algorithm Definition Flags
-
1045 — Flexible Algorithm Exclude SRLG
-
Link Descriptors TLVs
-
258 — Link Local/Remote Identifiers
-
259 — IPv4 interface address
-
260 — IPv4 neighbor address
-
261 — IPv6 interface address (only supported for IS-IS)
-
262 — IPv6 neighbor address (only supported for IS-IS)
-
263 — Multi-Topology ID (only supported for IS-IS)
Link Attributes TLVs
-
267 — Link MSD (Only when received from remote router. Not supported for local links.)
-
1088 — Administrative group (color)
-
1089 — Maximum link bandwidth
-
1090 — Max. reservable link bandwidth
-
1091 — Unreserved bandwidth
-
1092 — TE Default Metric
-
1095 — IGP Metric
-
1096 — Shared Risk Link Group
-
1114 — Unidirectional Link Delay (Only when received from remote router. Not supported for local links.)
-
1115 — Min/Max Unidirectional Link Delay
-
1116 — Unidirectional Delay Variation (Only when received from remote router. Not supported for local links.)
-
1117 — Unidirectional Link Loss (Only when received from remote router. Not supported for local links.)
-
1118 — Unidirectional Residual Bandwidth (Only when received from remote router. Not supported for local links.)
-
1119 — Unidirectional Available Bandwidth (Only when received from remote router. Not supported for local links)
-
1120 — Unidirectional Utilized Bandwidth (Only when received from remote router. Not supported for local links)
-
1122 — Application Specific Link Attributes
-
1173 — Extended Administrative Group
-
Segment Routing
-
1099 — Adjacency Segment Identifier
-
1100 — LAN Adjacency Segment Identifier
-
1106 — SRv6 End.X SID (only supported for IS-IS)
-
1107 — IS-IS SRv6 LAN End.X SID (only supported for IS-IS)
-
Prefix Descriptors TLVs
-
263 — Multi-Topology ID (only supported for IS-IS)
-
264 — OSPF Route Type (only Intra-Area and Inter-Area)
-
265 — IP Reachability Information
Prefix Attributes TLVs
-
1044 — Flexible Algorithm Prefix Metric
-
1152 — IGP Flags (only D flag supported [only supported for IS-IS])
-
1155 — Prefix Metric
-
Segment Routing
-
1158 — Prefix SID
-
1159 — Range (prefix-SID and sub-TLV only)
-
1162 — SRv6 Locator (only supported for IS-IS)
-
1170 — IGP Prefix Attributes
-
SRv6 SID
-
SRv6 SID Descriptor TLVs
-
263 — Multi-Topology ID (only supported for IS-IS)
- 518 — SRv6 SID Information (only supported for IS-IS)
-
-
SRv6 SID Attribute TLVs
- 1250 — SRv6 Endpoint Behavior (only supported for IS-IS)
- 1152 — SRv6 SID Structure (only supported for IS-IS)
BGP-LU traffic statistics
SR OS can collect BGP-LU traffic statistics.
Traffic statistics can be collected on egress data paths. This requires the use of egress-statistics keyword when creating an import policy and that the BGP tunnel exists for the corresponding prefix. If multiple paths exist (for example, ECMP), a single statistical index is allocated and reflects the traffic sent over all paths.
Traffic statistics can also be collected on ingress data paths if the label is assigned and effectively advertised per prefix. This typically requires the use of advertise-label per-prefix when creating the import policy and applies whether the sr-label-index keyword is in use or not. However, there are cases where this may not result in a per-prefix label advertisement. When a non-BGP route (for example, static route) is requested to be advertised (advertise-inactive) with a Label Per Prefix (LPP) policy but it exists as an active RTM route and as inactive BGP route, the system does not use the LPP but instead uses the LPNH policy. Statistics are not counted for this prefix. An imported (local loopback) SR label route can also be configured to use the ingress-statistics keyword by using a route table import policy under rib-management (either label-ipv4 or label-ipv6).
Overall, BGP-LU statistics apply at the:
PE and forwarding RR on egress
ASBR on both ingress and egress
Only host prefixes (/32 and /128) are supported on egress statistics.
Host and non-host prefixes are supported on ingress statistics.
Control messages sent over the BGP-LU tunnel are accounted for in traffic statistics.
BGP-LU statistics are not supported for imported LDP routes (ldp-bgp stitching) or for VPN labels (for example, inter-AS B or C).
BGP Egress Peer Engineering using BGP Link State
BGP Egress Peer Engineering (BGP EPE) extends segment routing (SR) capabilities beyond the AS boundary toward directly attached EBGP peers. Operators can use a central controller to enforce more programmatic control of traffic distribution across these BGP peering links.
An SR SID can be allocated to a BGP peering segment and advertised in BGP Link State (BGP-LS) toward a controller, such as the Nokia NSP. The instantiation of the following BGP peering segments is supported:
-
an eBGP or iBGP peer (peer node SIDs as defined in RFC 8402, Segment Routing Architecture)
-
a link to such a peer (peer adjacency SIDs as defined in RFC 8402, Segment Routing Architecture)
The controller includes the specific SID in the path for an SR-TE LSP or SR policy, which it programs at the head-end LER. EPE enables a head-end router to steer traffic across a downstream peering link to a node, for traffic optimization, resiliency, or load-balancing purposes.
EPE example use case shows an example use case for BGP EPE.
In this example, there are two IGP domains with eBGP running between R5 and R6, and between R5 and R8. These adjacencies are not visible to R1, which is external to the IGP domain. At R5, separate peer node SIDs are allocated for R6 and R8. The peer node SIDs are advertised to the Nokia NSP in BGP-LS. This allows the NSP to compute a path across either the R5-R6 adjacency or the R5-R8 adjacency by including the appropriate peer node SID in the path. In the preceding use case, the R5-R6 adjacency is preferable. This peer node SID can be included in either the SR-ERO of an SR-TE LSP that is computed by PCEP or the segment list of BGP SR policy that is programmed at R1. Traffic on this LSP or SR policy is, therefore, steered across the required peering.
EPE is supported for BGP neighbors with either eBGP or iBGP sessions. SR peer node SIDs and peer adjacency SIDs are supported. The SID labels are dynamically allocated from the local label space on the node and advertised in BGP-LS using the encoding specified in section 4 of draft-ietf-idr-bgpls-segment-routing-epe-19.
The peering node can behave as both an LSR and an LER for steering traffic toward the peering segment. Both ILM and LTN entries are programmed for peer node SIDs and peer adjacency SIDs, with a label swap to or push of an implicit null label.
-
BGP EPE only supports neighbor nodes that are directly connected to the egress router (for example, not indirectly through tunnels).
-
BGP EPE SIDs cannot be used as the top SIDs on a tunnel originating at the ingress node to the peering segment. Only IS-IS or OSPF SIDs can be used as the transport SID.
ECMP is supported by default if there are multiple peer adjacency SIDs. BGP only allocates peer adjacency SIDs to the ECMP set of next hops toward the peer node. For non-ECMP next hops, only a peer adjacency SID is allocated and it is advertised if all ECMP sets go down.
LSP ping and LSP trace echo requests are supported by including a label representing a peer node SID or peer adjacency SID in a NIL FEC of the target FEC stack. An EPE router can validate and respond to an LSP ping or trace echo request containing this FEC.
Configuring BGP EPE
In addition to enabling the BGP-LS route family for a BGP neighbor, the following CLI is required to send the Egress Peering Segments described in BGP Egress Peer Engineering using BGP Link State using the NLRI Type 2 with protocol ID set to BGP-EPE.
CLI syntax
configure>router>bgp
egress-peer-engineering {
admin-state {enable | disable}
}When egress-peer-engineering is administratively enabled, BGP registers with SR and the router starts advertising any peer node and peer adjacency SIDs in BGP-LS.
To allocate peer node and peer adjacency SIDs, use the following syntax to configure the egress-engineering command and enable BGP-EPE for a BGP neighbor or group.
CLI syntax
configure>router>bgp
group
neighbor <a.b.c.d> {
egress-engineering {
admin-state {enable | disable}
}
configure>router>bgp
group
egress-engineering {
admin-state {enable | disable}
}The BGP egress-engineering at the neighbor level overrides the group level configuration. When a neighbor does not have an egress-engineering configuration context, the group configuration is inherited in the following cases.
If the group does not have an egress-engineering configuration, egress-engineering is disabled for the neighbor.
If the group has an egress-engineering configuration in the default disabled state, egress-engineering is disabled for the neighbor.
If the group has an enabled egress-engineering configuration, egress-engineering is enabled for the neighbor.
When a neighbor has egress-engineering configured and in the default disabled state, egress-engineering is disabled for the neighbor, irrespective of the disabled, enabled, or no-context configuration at the group level. When a neighbor has egress-engineering configured and enabled, egress-engineering is enabled for the neighbor, irrespective of the disabled, enabled, or no-context configuration at the group level.
By default, enabling egress-engineering at the peer or group level causes SID values (MPLS labels) to be dynamically allocated for the peer node segment and the peer adjacency segments. Although the labels are assigned when the neighbor or group is configured, they are not programmed until the adjacency comes up. Peer node segments are derived from the BGP next hops used to reach a specific peer. If the node reboots, these dynamically allocated label values may change and are re-announced in BGP-LS.
If a BGP neighbor goes down, the router advertises a delete for all SIDs associated with the neighbor and deprograms them from the IOM. However, the label values for the SIDs are not released and the router re-advertises the same values when the BGP neighbor comes back up.
If a BGP neighbor is deleted from the configuration or is shut down, or egress-engineering is disabled, the router advertises a delete for all SIDs associated with the neighbor and deprograms them from the IOM. The router also releases the label values for the SIDs.
BGP Egress Peer Engineering using Labeled Unicast
Egress Peer Engineering (EPE) allows an ingress PE or source host in an Autonomous System (AS) to use a specific egress peering router and a specific external interface or neighbor of that peering router to reach IP destinations external to the AS.
- Use segment routing and BGP-LS to signal peer node SIDs and peer adjacency SIDs to a PCE or controller that computes and programs the steering instructions that make use of these SIDs. For more information, see BGP Egress Peer Engineering using BGP Link State.
- Use a distributed EPE solution relying on BGP Labeled Unicast (LU) routes and recursive BGP route resolution. BGP EPE using LU does not depend on segment routing, BGP-LS, or a controller. It only depends on the appropriate configuration in the EPE border routers and ingress PE routers. This is the simpler solution and is described in what follows.
To enable an egress border router (with EPE peers) to support BGP-LU based EPE, use the egress-peer-engineering-label-unicast command for the base router BGP groups and neighbors in the configure router bgp group and configure router bgp group neighbor contexts so that all potential EPE peers are covered. When this command is applied, BGP generates a labeled unicast route for the /32 or /128 prefix that corresponds to each EPE peer. These routes can be advertised to other routers to recursively resolve unlabeled BGP routes for AS external destinations. The BGP-LU EPE routes can resolve unlabeled BGP routes only when the unlabeled BGP routes are advertised in the local AS with the next-hop unchanged. In general, the unlabeled routes should be advertised in the local AS using add-paths or best-external so that multiple exit paths are available to the route selection process in ingress PE routers.
-
The peer address is not an IPv6 link-local address.
-
The peer session is up.
-
The detected peer type is EBGP (and not IBGP or confederation-EBGP).
-
The peer address is resolved by a direct interface route (that is, the peer is a single-hop connected peer).
The system withdraws an EPE route if any of these conditions is no longer met; for example, the peer session goes down. After the withdrawal reaches the ingress PE routers, the BGP route selection process must select a different EPE exit point.
-
If the interface is up, the system forwards a packet received with the EPE label as a bottom-of-stack label without IP header lookup (and with the EPE label removed) to the EPE peer.
-
If the interface is down, the system forwards a packet received with the EPE label as a bottom-of-stack label as an IP packet (with the EPE label removed, based on the IP FIB lookup).
These datapath optimizations enable fast reroute behavior (BGP FRR) when the interface toward an EPE peer goes down. The BGP FRR behavior is only available with FP3 or later FP technology.
BGP configuration process overview
BGP configuration and implementation flow displays the process to provision basic BGP parameters.
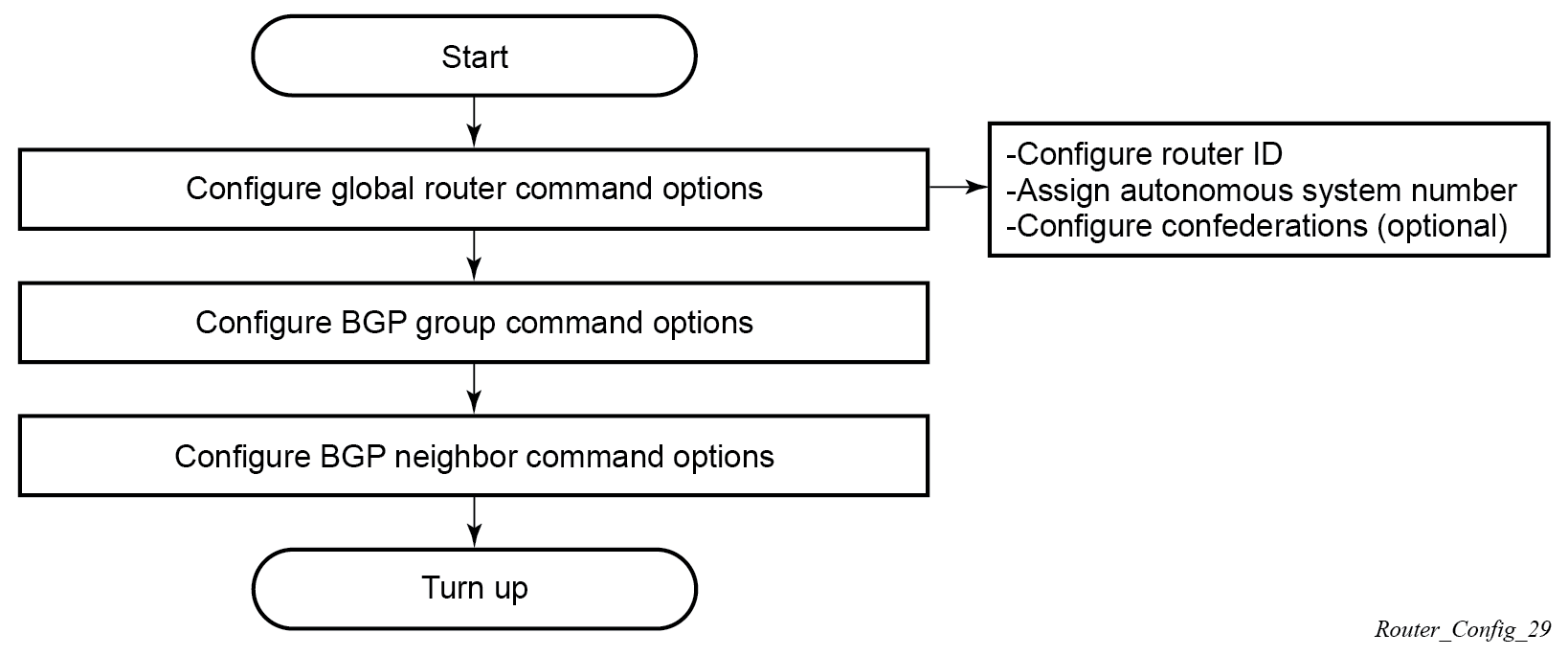
Configuration notes
This section describes BGP configuration restrictions.
General
Before BGP can be configured, the router ID and autonomous system should be configured.
BGP must be added to the router configuration. There are no default BGP instances on a router.
BGP defaults
The following list summarizes the BGP configuration defaults.
By default, the router is not assigned to an AS.
A BGP instance is created in the administratively enabled state.
A BGP group is created in the administratively enabled state.
A BGP neighbor is created in the administratively enabled state.
No BGP router ID is specified. If no BGP router ID is specified, BGP uses the router system interface address.
The router BGP timer defaults are generally the values recommended in IETF drafts and RFCs (see BGP MIB notes)
If no import route policy statements are specified, then all BGP routes are rejected.
If no export route policy statements are specified, then no routes are advertised.
BGP MIB notes
The router implementation of the RFC 1657 MIB variables listed in SR OS and IETF MIB variations differs from the IETF MIB specification.
| MIB variable | Description | RFC 1657 allowed values | SR OS allowed Values |
|---|---|---|---|
bgpPeerMinRouteAdvertisementInterval |
Time interval in seconds for the MinRouteAdvertisementInterval timer. The suggested value for this timer is 30. |
1 to 65535 |
1 to 255 A value of 0 is supported when the rapid-update command is applied to an address family that supports it. |
If SNMP is used to set a value of X to the MIB variable in SR OS and IETF MIB variations , there are three possible results:
| Condition | Result |
|---|---|
X is within IETF MIB values and X is within SR OS values |
SNMP set operation does not return an error MIB variable set to X |
X is within IETF MIB values and X is outside SR OS values |
SNMP set operation does not return an error MIB variable set to ‟nearest” SR OS supported value (for example, SR OS range is 2 - 255 and X = 65535, MIB variable is set to 255) Log message generated |
X is outside IETF MIB values and X is outside SR OS values |
SNMP set operation returns an error |
When the value set using SNMP is within the IETF allowed values and outside the SR OS values as specified in SR OS and IETF MIB variations and MIB variable with SNMP , a log message is generated.
The log messages that display are similar to the following log messages:
Sample Log Message for setting bgpPeerMinRouteAdvertisementInterval to 256
535 2006/11/12 19:40:53 [Snmpd] BGP-4-bgpVariableRangeViolation: Trying to set
bgpPeerMinRouteAdvInt to 256 - valid range is [2-255] - setting to 255
Sample Log Message for setting bgpPeerMinRouteAdvertisementInterval to 1
566 2006/11/12 19:44:41 [Snmpd] BGP-4-bgpVariableRangeViolation: Trying to set
bgpPeerMinRouteAdvInt to 1 - valid range is [2-255] - setting to 2
Configuring BGP with CLI
This section provides information to configure BGP using the command line interface.
Configuration overview
Preconfiguration requirements
Before BGP can be implemented, the following entities must be configured:
The autonomous system (AS) number for the router
An AS number is a globally unique value which associates a router to a specific autonomous system. This number is used to exchange exterior routing information with neighboring ASs and as an identifier of the AS itself. Each router participating in BGP must have an AS number specified.
To implement BGP, the AS number must be specified in the config>router context.
Router ID
The router ID is the IP address of the local router. The router ID identifies a packet’s origin. The router ID must be a valid host address.
BGP hierarchy
BGP is configured in the config>router>bgp context. Three hierarchical levels are included in BGP configurations:
global level
group level
neighbor level
Commands and parameters configured on the global level are inherited to the group and neighbor levels although parameters configured on the group and neighbor levels take precedence over global configurations.
Internal and external BGP configuration
A BGP system comprises of ASs which share network reachability information. Network reachability information is shared with adjacent BGP peers. BGP supports two types of routing information exchanges.
External BGP (EBGP) is used between ASs
EBGP speakers peer to different ASs and typically share a subnet. In an external group, the next hop is dependent upon the interface shared between the external peer and the specific neighbor. The multihop command must be specified if an EBGP peer is more than one hop away from the local router.
Internal BGP (IBGP) is used within an AS
IBGP peers belong to the same AS and typically does not share a subnet. Neighbors do not have to be directly connected to each other. Because IBGP peers are not required to be directly connected, IBGP uses the IGP path (the IP next-hop learned from the IGP) to reach an IBGP peer for its peering connection.
Default external BGP route propagation behavior without policies
A newly created or existing BGP instance, group, or EBGP neighbor in a classic interface (the classic CLI and SNMP) maintains backwards compatibility with the insecure default to advertise and receive all routes. It is not compliant with RFC 8212. The secure default behavior must be enabled using the ebgp-default-reject-policy command in these cases.
A newly created BGP instance, group, or EBGP neighbor in a model-driven interface (the MD-CLI, NETCONF, or gRPC) applies the secure default behavior to reject all routes. It is compliant with RFC 8212. The secure behavior can be disabled using the ebgp-default-reject-policy command. However, Nokia recommends configuring import and export policies that express the intended routing instead of using the insecure default behavior. Defining an empty policy does not match any routes, an accept must match the route through an action accept or default-action accept statement.
The default behavior is inherited from the BGP instance to the group to an EBGP neighbor.
The import and export policies that are applied can be displayed using info detail or the show router bgp neighbor commands.
Default EBGP route propagation behavior shows the default EBGP route propagation behavior according to how the neighbor was configured.
| Management-interface configuration-mode | Classic | Mixed | Model-driven | |
|---|---|---|---|---|
| BGP instance, group, or EBGP neighbor | Configured in a classic interface | Configured in a classic interface | Configured in a model-driven interface | Configured in a model-driven interface |
Configured before Release 19.5.R1 |
Default accept |
Default accept |
Default accept |
Default accept |
Configured in Release 19.5.R1 or higher |
Default accept |
Default accept |
Default reject2 |
Default reject2 |
ISSU to Release 19.5.R1 or higher |
Default accept |
Default accept |
According to rows 1 and 22 |
According to rows 1 and 22 |
Reboot with Release 19.5.R1 or higher |
Default accept |
Default accept |
According to rows 1 and 22 |
Default reject2 |
Basic BGP configuration
This section provides information to configure BGP and configuration examples of common configuration tasks. The minimal BGP parameters that need to be configured are shown below.
An autonomous system number for the router.
A router ID. If a new or different router ID value is entered in the BGP context, then the new value takes precedence and overwrites the router-level router ID.
A BGP peer group.
A BGP neighbor with which to peer.
A BGP peer-AS that is associated with the above peer.
The BGP configuration commands have three primary configuration levels: bgp for global configurations, group name for BGP group configuration, and neighbor ip-address for BGP neighbor configuration. Within the different levels, many of the configuration commands are repeated. For the repeated commands, the command that is most specific to the neighboring router is in effect, that is, neighbor settings have precedence over group settings which have precedence over BGP global settings.
Following is an example configuration that includes the above parameters. The other parameters shown below are optional:
info
#--------------------------------------------------
echo "IP Configuration"
#--------------------------------------------------
...
autonomous-system 200
confederation 300 members 200 400 500 600
router-id 10.10.10.103
#--------------------------------------------------
...
#--------------------------------------------------
echo "BGP Configuration"
#--------------------------------------------------
bgp
graceful-restart
exit
cluster 0.0.0.100
export "direct2bgp"
router-id 10.0.0.12
group "To_AS_10000"
connect-retry 20
hold-time 90
keepalive 30
local-preference 100
remove-private
peer-as 10000
neighbor 10.0.0.8
description "To_Router B - EBGP Peer"
connect-retry 20
hold-time 90
keepalive 30
local-address 10.0.0.12
passive
preference 99
peer-as 10000
exit
exit
group "To_AS_30000"
connect-retry 20
hold-time 90
keepalive 30
local-preference 100
remove-private
peer-as 30000
neighbor 10.0.3.10
description "To_Router C - EBGP Peer"
connect-retry 20
hold-time 90
keepalive 30
peer-as 30000
exit
exit
group "To_AS_40000"
connect-retry 20
hold-time 30
keepalive 30
local-preference 100
peer-as 65206
neighbor 10.0.0.15
description "To_Router E - Sub Confederation AS 65205"
connect-retry 20
hold-time 90
keepalive 30
local-address 10.0.0.12
peer-as 65205
exit
exit
exit
#--------------------------------------------------
....
A:ALA-48>config>router#
Common configuration tasks
This task provides a brief overview of the tasks that must be performed to configure BGP and provides the CLI commands. To enable BGP, one AS must be configured and at least one group must be configured which includes neighbor (system or IP address) and peering information (AS number).
All BGP instances must be explicitly created on each router. After the instances are created, BGP is administratively enabled.
Configuration planning is essential to organize ASs and the SRs within the ASs, and determine the internal and external BGP peering.
To configure a basic autonomous system, perform the following steps.
- Prepare a plan detailing the autonomous systems, the router belonging to each group, group names, and peering connections.
- Associate each router with an autonomous system number.
- Configure each router with a router ID.
- Associate each router with a peer group name.
- Specify the local IP address that is used by the group or neighbor when communicating with BGP peers.
- Specify neighbors.
- Specify the autonomous system number associated with each neighbor.
Creating an autonomous system
Before BGP can be configured, the autonomous system must be configured first. In BGP, routing reachability information is exchanged between autonomous systems (ASs). An AS is a group of networks that share routing information. The autonomous-system command associates an autonomous system number to the router being configured. The autonomous-system command is configured in the config>router context.
Use the following CLI syntax to associate a router to an autonomous system.
CLI syntax
config>router# autonomous-system autonomous-systemThe router series supports 4 bytes AS numbers by default. This means autonomous-system can have any value from 1 to 4294967295. The following example displays autonomous system configuration command usage.
Example
config>router# autonomous-system 100The following example displays the autonomous system configuration:
ALA-B>config>router# info
#------------------------------------------
# IP Configuration
#------------------------------------------
interface "system"
address 10.10.10.104/32
exit
interface "to-103"
address 10.0.0.104/24
port 1/1/1
exit
autonomous-system 100
#------------------------------------------
ALA-B>config>router#
Configuring a router ID
In BGP, routing information is exchanged between autonomous systems. The BGP router ID, expressed like an IPv4 address, uniquely identifies the router. It can be set to be the same as the system interface address.
It is possible to configure an SR OS to operate with an IPv6 only BOF and no IPv4 system interface address. When configured in this manner, the operator must explicitly define IPv4 router IDs for protocols such as OSPF and BGP as there is no mechanism to derive the router ID from an IPv6 system interface address.
If a new or different router ID value is entered in the BGP context, then the new router ID value is used instead of the router ID configured on the router level, system interface level, or inherited from the MAC address. The router-level router ID value remains intact. The router ID used by BGP is selected in the following order:
the router-id configured under config>router>bgp
the router-id configured under config>router
the system interface IPv4 address
the last 4 bytes of the system MAC address
When configuring a new router ID outside of the config>router>bgp context, BGP is not automatically restarted with the new router ID; the next time BGP is (re) initialized the new router ID is used. An interim period of time can occur when different protocols use different router IDs. To force the new router ID, issue the shutdown and no shutdown commands for BGP or restart the entire router. Use the following CLI syntax to configure the router ID for multiple protocols.
CLI syntax
config>router# router-id router-idThe following example displays router ID configuration command usage.
Example
config>router# router-id 10.10.10.104The following example displays the router ID configuration:
ALA-B>config>router# info
----------------------------------------------
# IP Configuration
#------------------------------------------
interface "system"
address 10.10.10.104/32
exit
interface "to-103"
address 10.0.0.104/24
port 1/1/1
exit
autonomous-system 100
router-id 10.10.10.104
#------------------------------------------
...
ALA-B>config>router#
BGP confederations
- Configure the autonomous system number of the confederation using the confederation command in the config>router context.
- Configure the BGP confederation members using the confederation command in the config>router context.
- Configure IBGP peering within the (local) sub-confederation.
-
Configure one or more confed-EBGP peerings to peers in other neighboring
sub-confederations.
Confederation network diagram example shows a confederation network diagram example.
Figure 16. Confederation network diagram example 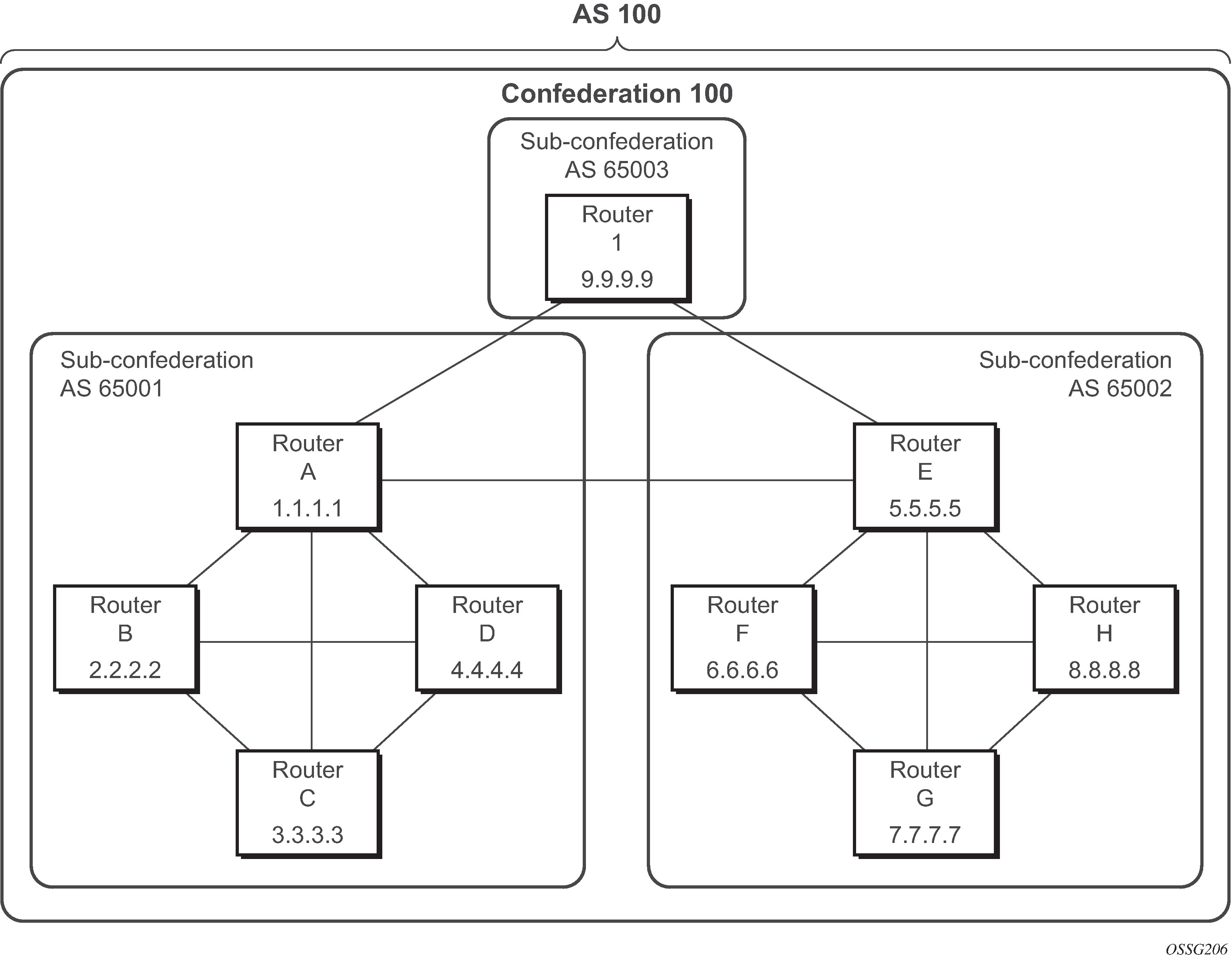
The following configuration displays the minimum BGP configuration for routers in sub-confederation AS 65001 described in Confederation network diagram example.
ALA-A config router autonomous-system 65001 confederation 100 members 65001 65002 65003 bgp group confed1 peer-as 65001 neighbor 2.2.2.2 exit neighbor 3.3.3.3 exit neighbor 4.4.4.4 exit exit group external_confed neighbor 5.5.5.5 peer-as 65002 exit neighbor 9.9.9.9 peer-as 65003 exit exit exit exit ALA-D config router autonomous-system 65001 confederation 100 members 65001 65002 65003 bgp group confed1 peer-as 65001 neighbor 1.1.1.1 exit neighbor 2.2.2.2 exit neighbor 3.3.3.3 exit exit exit exit ROUTER 1 config router autonomous-system 65003 confederation 100 members 65001 65002 65003 bgp group confed1 peer-as 65001 neighbor 1.1.1.1 exit neighbor 5.5.5.5 peer-as 65002 exit exit exit exit
BGP router reflectors
In a standard BGP configuration, all BGP speakers within an AS must have a full BGP mesh to ensure that all externally learned routes are redistributed through the entire AS. IBGP speakers do not re-advertise routes learned from one IBGP peer to another IBGP peer. If a network grows, scaling issues could emerge because of the full mesh configuration requirement. Route reflection circumvents the full mesh requirement but still maintains the full distribution of external routing information within an AS.
Autonomous systems using route reflection arrange BGP routers into groups called clusters. Each cluster contains at least one route reflector which is responsible for redistributing route updates to all clients. Route reflector clients do not need to maintain a full peering mesh between each other. They only require a peering to the route reflectors in their cluster. The route reflectors must maintain a full peering mesh between all non-clients within the AS.
Each route reflector must be assigned a cluster ID and specify which neighbors are clients and which are non-clients to determine which neighbors should receive reflected routes and which should be treated as a standard IBGP peer. Additional configuration is not required for the route reflector besides the typical BGP neighbor parameters.
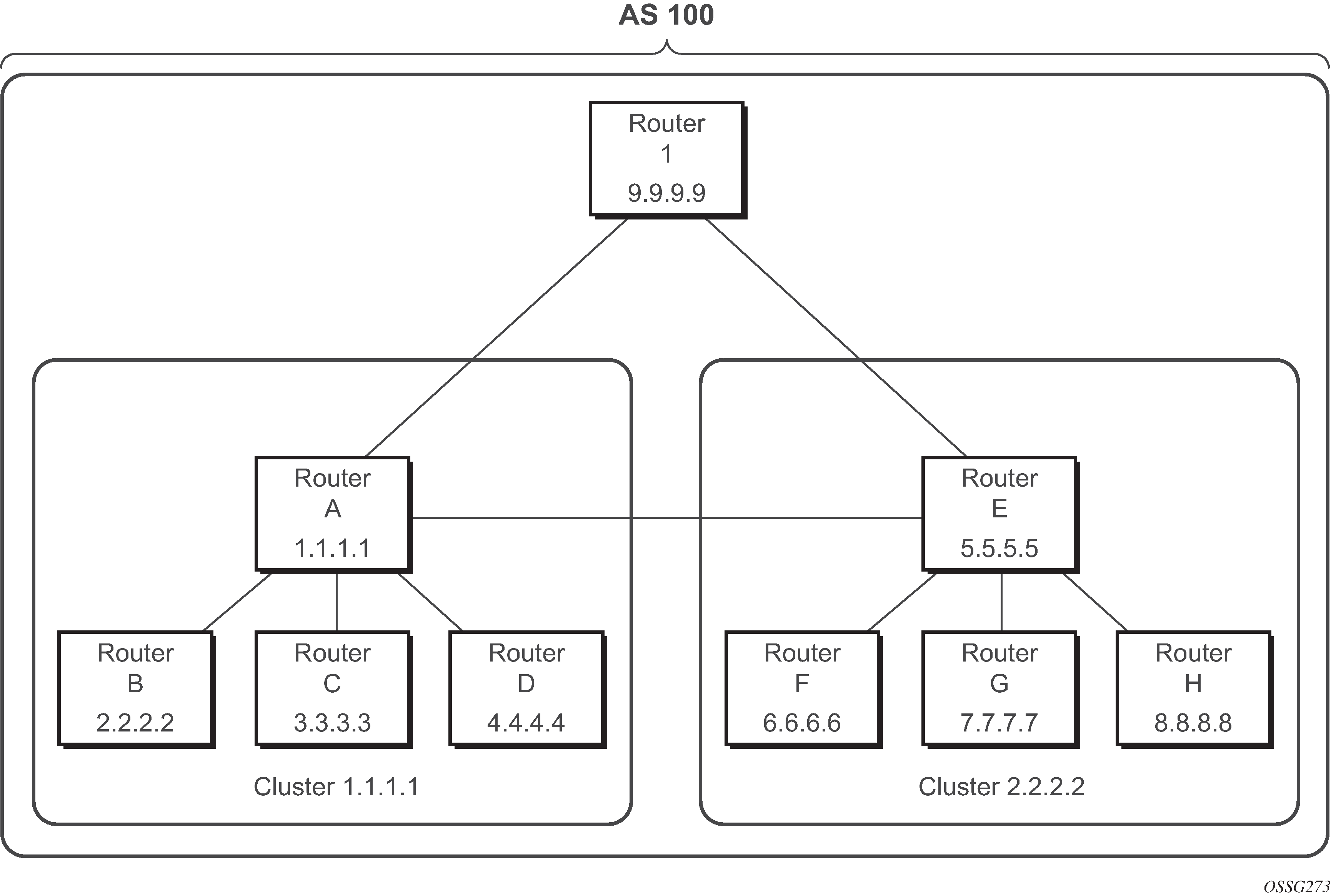
The following configuration displays the minimum BGP configuration for routers in Cluster 1.1.1.1 described in Route reflection network diagram example.
MD-CLI
[ex:/configure router "Base" bgp]
A:admin@node-2A# info
...
group "RRs" {
peer-as 100
}
group "cluster1" {
peer-as 100
cluster {
cluster-id 1.1.1.1
}
}
neighbor "2.2.2.2" {
group "cluster1"
}
neighbor "3.3.3.3" {
group "cluster1"
}
neighbor "4.4.4.4" {
group "cluster1"
}
neighbor "5.5.5.5" {
group "RRs"
}
neighbor "9.9.9.9" {
group "RRs"
}
[ex:/configure router "Base" bgp]
A:admin@node-2B# info
group "cluster1" {
peer-as 100
cluster {
cluster-id 1.1.1.1
}
}
[ex:/configure router "Base" bgp]
A:admin@node-2C# info
group "cluster1" {
peer-as 100
cluster {
cluster-id 1.1.1.1
}
}
[ex:/configure router "Base" bgp]
A:admin@node-2D# info
group "cluster1" {
peer-as 100
cluster {
cluster-id 1.1.1.1
}
}classic CLI
A:node-2A>config>router>bgp# info
group cluster1
peer-as 100
cluster 1.1.1.1
neighbor 2.2.2.2
exit
neighbor 3.3.3.3
exit
neighbor 4.4.4.4
exit
exit
group RRs
peer-as 100
neighbor 5.5.5.5
exit
neighbor 9.9.9.9
exit
exit
exit
A:node-2B>config>router>bgp# info
group cluster1
peer-as 100
neighbor 1.1.1.1
exit
exit
exit
A:node-2C>config>router>bgp# info
group cluster1
peer-as 100
neighbor 1.1.1.1
exit
exit
exit
A:node-2D>config>router>bgp# info
group cluster1
peer-as 100
neighbor 1.1.1.1
exit
exit
exit
BGP components
Use the CLI syntax displayed in the following subsections to configure BGP attributes.
Configuring group attributes
A group is a collection of related BGP peers. The group name should be a descriptive name for the group. Follow your group, name, and ID naming conventions for consistency and to help when troubleshooting faults.
All parameters configured for a peer group are applied to the group and are inherited by each peer (neighbor), but a group parameter can be overridden on a specific neighbor-level basis.
The following example displays the BGP group configuration:
ALA-B>config>router>bgp# info
----------------------------------------------
...
group "headquarters1"
description "HQ execs"
local-address 10.0.0.104
disable-communities standard extended
ttl-security 255
exit
exit
...
----------------------------------------------
ALA-B>config>router>bgp#
Configuring neighbor attributes
After you create a group name and assign options, add neighbors within the same autonomous system to create IBGP connections and/or neighbors in different autonomous systems to create EBGP peers. All parameters configured for the peer group level are applied to each neighbor, but a group parameter can be overridden on a specific neighbor basis.
The following example displays neighbors configured in group ‟headquarters1”.
ALA-B>config>router>bgp# info
----------------------------------------------
...
group "headquarters1"
description "HQ execs"
local-address 10.0.0.104
disable-communities standard extended
ttl-security 255
neighbor 10.0.0.5
passive
peer-as 300
exit
neighbor 10.0.0.106
peer-as 100
exit
neighbor 172.5.0.2
hold-time 90
keepalive 30
local-preference 170
peer-as 10701
exit
neighbor 172.5.1.2
hold-time 90
keepalive 30
local-preference 100
min-route-advertisement 30
preference 170
peer-as 10702
exit
exit
...
----------------------------------------------
ALA-B>config>router>bgp#
Configuring route reflection
Route reflection can be implemented in autonomous systems with a large internal BGP mesh to reduce the number of IBGP sessions required. One or more routers can be selected to act as focal points for internal BGP sessions. Several BGP speaking routers can peer with a route reflector. A route reflector forms peer connections to other route reflectors. A router assumes the role as a route reflector by configuring the cluster cluster-id command. No other command is required unless you want to disable reflection to specific peers.
If you configure the cluster command at the global level, then all subordinate groups and neighbors are members of the cluster. The route reflector cluster ID is expressed in dotted-decimal notation. The ID should be a significant topology-specific value. No other command is required unless you want to disable reflection to specific peers.
If a route reflector client is fully meshed, the disable-client-reflect command can be enabled to stop the route reflector from reflecting redundant route updates to a client.
The following example displays a route reflection configuration:
MD-CLI
[ex:/configure router "Base" bgp]
A:admin@node-2# info
cluster {
cluster-id 0.0.0.100
}
group "Santa Clara" {
local-address 10.0.0.103
}
neighbor "10.0.0.91" {
group "Santa Clara"
peer-as 100
}
neighbor "10.0.0.92" {
group "Santa Clara"
peer-as 100
}
neighbor "10.0.0.93" {
group "Santa Clara"
client-reflect false
peer-as 100
}classic CLI
A:node-2>config>router>bgp# info
---------------------------------------------
cluster 0.0.0.100
group "Santa Clara"
local-address 10.0.0.103
neighbor 10.0.0.91
peer-as 100
exit
neighbor 10.0.0.92
peer-as 100
exit
neighbor 10.0.0.93
disable-client-reflect
peer-as 100
exit
exit
---------------------------------------------Configuring a confederation
Reducing a complicated IBGP mesh can be accomplished by dividing a large autonomous system into smaller autonomous systems. The smaller ASs can be grouped into a confederation. A confederation looks like a single AS to routers outside the confederation. Each confederation is identified by its own (confederation) AS number.
To configure a BGP confederation, you must specify a confederation identifier, an AS number expressed as a decimal integer. The collection of autonomous systems appears as a single autonomous system with the confederation number acting as the ‟all-inclusive” autonomous system number. Up to 15 members (ASs) can be added to a confederation.
The confederation command is configured in the config>router context.
Use the following CLI syntax to configure a confederation.
CLI syntax
config>router# confederation confed-as-num members
member-as-numWhen 4-byte AS number support is not disabled on router, the confederation and any of its members can be assigned an AS number in the range from 1 to 4294967295. The following example displays a confederation configuration command usage.
Example
config>router># confederation 1000 members 100 200 300The following example displays the confederation configuration:
ALA-B>config>router# info
#------------------------------------------
# IP Configuration
#------------------------------------------
interface "system"
address 10.10.10.103/32
exit
interface "to-104"
shutdown
address 10.0.0.103/24
port 1/1/1
exit
autonomous-system 100
confederation 1000 members 100 200 300
router-id 10.10.10.103
#------------------------------------------
ALA-B>config>router#
Configuring BMP
See the BGP monitoring protocol for more information about the protocol. To enable BMP, follow these steps.
Configure a BMP station where BMP information is sent.
Configure one or more neighbors to be monitored by that station.
Configuring BMP shows a BMP configuration example.
Configuring a BMP station
BMP stations are configured at a top-level configuration context (config>bmp). A BMP station can then monitor BGP in the base router, or in one or more virtual routers for VPRN services. For each instance of BGP, a separate BMP TCP session is set up between the router and that BMP station. A total of eight different BMP stations can be configured on an SR OS router.
The following command creates a BMP station:
config>bmp>station station-name [create]
config>bmp>station antwerp [create]This creates a BMP station named antwerp. The station name must be used when configuring BGP peers to be monitored by this station. The name can also be used in the show>router>bmp CLI commands to display associated information.
The next step is to configure how this station can be reached. To do this, the IP address of the Linux station, or container, on which the BMP collector is run is required. Also, the TCP port number on which the BMP station is listening is needed. BMP does not use a well-known port number.
A network operator can pick any appropriate TCP port number.
BMP sessions from an SR OS router can run over either TCP/IPv4 or TCP/IPv6.
The following is an IP address and port number configuration for a BMP station:
configure bmp
station antwerp create
connection
station-address 1.2.3.4 port 5000
exit
exit
exit
This creates a BMP station that can monitor one or more BGP peers.
Next, assign the BGP peers to be monitored.
In BGP configuration mode, navigate to the monitor command, config>router>bgp>monitor. The monitor command can be used at the BGP-instance level the group or neighbor levels.
Configure up to eight station names that monitor these peers, config>router>bgp>monitor>station name.
Enable monitoring, config>router>bgp>monitor>no shutdown. On SR OS routers, both the BMP protocol and each individual station are in a shutdown state by default. To allow BMP to start BMP sessions, BMP and the station must be administratively enabled.
configure router bgp
monitor
station antwerp
no shutdown
exit
exit
All peers in the BGP instance of the base router are now monitored by station antwerp. The router only sends BMP peer-up and peer-down messages to the BMP station. Sending periodic statistics messages, or reporting incoming BGP routes must be explicitly configured.
BGP configuration management tasks
This section discusses BGP configuration management tasks.
Modifying an AS number
Modify an AS number on a router but the new AS number is not used until the BGP instance is restarted either by administratively disabling or enabling the BGP instance or by rebooting the system with the new configuration.
Because the AS number is defined in the configure router context, not in the BGP configuration context, the BGP instance is not aware of the change. Re-examine the plan detailing the autonomous systems, the SRs belonging to each group, group names, and peering connections. Changing an AS number on a router could cause configuration inconsistencies if associated peer AS values are not also modified as required. At the group and neighbor levels, BGP re-establishes the peer relationships with all peers in the group with the new AS number.
Use the configure router autonomous-system command to change an autonomous system number.
The following example displays an AS configuration.
MD-CLI
[ex:/configure router "Base"]
A:admin@node-2# info
autonomous-system 400
...
bgp
group "1" {
}
group "headquarters1" {
}
neighbor "10.10.10.103" {
group "headquarters1"
peer-as 400
}
}
classic CLI
A:node-2>config>router# info
#--------------------------------------------------
echo "IP Configuration"
#--------------------------------------------------
...
autonomous-system 400
...
#--------------------------------------------------
echo "BGP Configuration"
#--------------------------------------------------
bgp
group "1"
exit
group "headquarters1"
neighbor 10.10.10.103
peer-as 400
exit
exit
no shutdown
exit
----------------------------------------------Modifying a confederation number
Modifying a confederation number causes BGP to restart automatically. Changes immediately take effect.
Modifying the BGP router ID
Changing the router ID number in the BGP context causes the new value to overwrite the router ID configured on the router level, system interface level, or the value inherited from the MAC address. It triggers an immediate reset of all peering sessions.
The following example displays the BGP configuration with the BGP router ID specified.
MD-CLI
[ex:/configure router "Base" bgp]
A:admin@node-2# info detail
## apply-groups
## apply-groups-exclude
admin-state enable
## description
connect-retry 120
router-id 10.0.0.123
inter-as-vpn false
classic CLI
A:node-2>config>router>bgp# info detail
----------------------------------------------
no description
no family
router-id 10.0.0.123
...Modifying the router-level router ID
Changing the router ID number in the configure router context causes the new value to overwrite the router ID derive from the system interface address, or the value inherited from the MAC address.
When configuring a new router ID, protocols are not automatically restarted with the new router ID. The next time a protocol is (re) initialized the new router ID is used. An interim period of time can occur when different protocols use different router IDs. To force the new router ID, do the following or restart the entire router.
- disable the protocol
- configure the new router ID
- enable the protocol
The following commands disable and enable the BGP protocol:
- MD-CLI
configure router bgp admin-state disable configure router bgp admin-state enable - classic
CLI
configure router bgp shutdown configure router bgp no shutdown
The following example displays the router ID configuration.
MD-CLI
[ex:/configure router "Base"]
A:admin@node-2# info
autonomous-system 100
router-id 10.10.10.104
interface "system" {
ipv4 {
primary {
address 10.10.10.104
prefix-length 32
}
}
}
interface "to-103" {
port 1/1/1
ipv4 {
primary {
address 10.0.0.104
prefix-length 24
}
}
}
classic CLI
A:node-2>config>router# info
#--------------------------------------------------
echo "IP Configuration"
#--------------------------------------------------
interface "system"
address 10.10.10.104/32
no shutdown
exit
interface "to-103"
address 10.0.0.104/24
port 1/1/1
no shutdown
exit
autonomous-system 100
router-id 10.10.10.104
#--------------------------------------------------Deleting a neighbor
Use the following CLI command to delete a neighbor:
- MD-CLI
configure router bgp delete neighbor - classic
CLI
configure router bgp group shutdown configure router bgp group no neighbor
The following example displays the ‟headquarters1” configuration with the neighbor 10.0.0.103 removed.
MD-CLI
[ex:/configure router "Base" bgp]
A:admin@node-2# info
router-id 10.0.0.123
ebgp-default-reject-policy {
import false
export false
}
group "1" {
}
group "headquarters1" {
}
classic CLI
A:node-2>config>router>bgp# info
----------------------------------------------
router-id 10.0.0.123
group "1"
exit
group "headquarters1"
exit
no shutdown
----------------------------------------------Deleting groups
To delete a group, the neighbor configurations must first be administratively disabled. After each neighbor is disabled, you must administratively disable the group before removing the group.
The following example displays the administratively disabled neighbors.
MD-CLI
[ex:/configure router "Base" bgp]
A:admin@node-2# info
...
group "headquarters1" {
admin-state enable
}
neighbor "10.10.10.103" {
admin-state disable
group "headquarters1"
peer-as 400
}
neighbor "10.10.10.105" {
admin-state disable
group "headquarters1"
peer-as 400
}
classic CLI
A:node-2>config>router>bgp>group# info
----------------------------------------------
neighbor 10.10.10.103
shutdown
peer-as 400
exit
neighbor 10.10.10.105
shutdown
peer-as 400
exit
----------------------------------------------
The following example displays the administratively disabled group.
MD-CLI
[ex:/configure router "Base" bgp]
A:admin@node-2# info
...
group "headquarters1" {
admin-state disable
}
neighbor "10.10.10.103" {
admin-state disable
group "headquarters1"
peer-as 400
}
neighbor "10.10.10.105" {
admin-state disable
group "headquarters1"
peer-as 400
}
classic CLI
A:node-2>config>router>bgp# info
----------------------------------------------
...
group "headquarters1"
shutdown
neighbor 10.10.10.103
shutdown
peer-as 400
exit
neighbor 10.10.10.105
shutdown
peer-as 400
exit
exit
no shutdown
----------------------------------------------
MINOR: CLI BGP peer group must be 'shutdown' before deletion.
Use the following command to delete the group:
- MD-CLI
[ex:/configure router "Base" bgp] A:admin@node-2# delete group headquarters1 - classic
CLI
configure router bgp no group