LAG
A Link Aggregation Group (LAG), based on the IEEE 802.1ax standard (formerly 802.3ad), increases the bandwidth available between two network devices by grouping multiple ports to form one logical interface.
Traffic forwarded to a LAG by the router is load balanced between all active ports in the LAG. The hashing algorithm deployed by Nokia routers ensures that packet sequencing is maintained for individual sessions. Load balancing for packets is performed by the hardware, which provides line rate forwarding for all port types.
LAGs can be either statically configured or formed dynamically with Link Aggregation Control Protocol (LACP). A LAG can consist of same-speed ports or mixed-speed ports.
All ports within a LAG must be of the same Ethernet type (access, network, or hybrid) and have the same encapsulation type (dot1q, QinQ, or null).
The following is an example of static LAG configuration using dot1q access ports.
MD-CLI
[ex:/configure lag "lag-1"]
A:admin@node-2# info
admin-state enable
encap-type dot1q
mode access
port 1/1/1 {
}
port 1/1/2 {
}classic CLI
A:node-2>config>lag# info
----------------------------------------------
mode access
encap-type dot1q
port 1/1/1
port 1/1/2
no shutdown
----------------------------------------------LACP
The LACP control protocol, defined by the IEEE 802.3ad standard, specifies the method by which two devices establish and maintain LAGs. When LACP is enabled, SR OS automatically associates LACP-compatible ports into a LAG.
The following is an example of LACP LAG configuration using network ports and a default null encapsulation type.
MD-CLI
[ex:/configure lag "lag-2"]
A:admin@node-2# info
admin-state enable
mode network
lacp {
mode active
administrative-key 32768
}
port 1/1/3 {
}
port 1/1/4 {
}classic CLI
A:node-2>config>lag# info
----------------------------------------------
mode network
port 1/1/3
port 1/1/4
lacp active administrative-key 32768
no shutdown
----------------------------------------------
LACP multiplexing
The router supports two modes of multiplexing RX/TX control for LACP: coupled and independent.
In coupled mode (default), both RX and TX are enabled or disabled at the same time whenever a port is added or removed from a LAG group.
In independent mode, RX is first enabled when a link state is UP. LACP sends an indication to the far-end that it is ready to receive traffic. Upon the reception of this indication, the far-end system can enable TX. Therefore, in independent RX/TX control, LACP adds a link into a LAG only when it detects that the other end is ready to receive traffic. This minimizes traffic loss that may occur in coupled mode if a port is added into a LAG before notifying the far-end system or before the far-end system is ready to receive traffic. Similarly, on link removals from LAG, LACP turns off the distributing and collecting bit and informs the far-end about the state change. This allows the far-end side to stop sending traffic as soon as possible.
Independent control provides for lossless operation for unicast traffic in most scenarios when adding new members to a LAG or when removing members from a LAG. It also reduces loss for multicast and broadcast traffic.
Note that independent and coupled mode are interoperable (connected systems can have either mode set).
Independent and coupled modes are supported when using PXC ports, however, independent mode is recommended as it provides significant performance improvements.
LACP tunneling
LACP tunneling is supported on Epipe and VPLS services. In a VPLS, the Layer 2 control frames are sent out of all the SAPs configured in the VPLS. This feature should only be used when a VPLS emulates an end-to-end Epipe service (an Epipe configured using a three-point VPLS, with one access SAP and two access-uplink SAP/SDPs for redundant connectivity). The use of LACP tunneling is not recommended if the VPLS is used for multipoint connectivity. When a Layer 2 control frame is forwarded out of a dot1q SAP or a QinQ SAP, the SAP tags of the egress SAP are added to the packet.
The following SAPs can be configured for tunneling the untagged LACP frames (the corresponding protocol tunneling needs to be enabled on the port).
If the port encapsulation is null, a null SAP can be configured on a port to tunnel these packets.
If the port encapsulation is dot1q, either a dot1q explicit null SAP (for example, 1/1/10:0) or a dot1q default SAP (for example, 1/1/11:*) can be used to tunnel these packets.
If the port encapsulation is QinQ, a 0.* SAP (for example, 1/1/10:0.*) can be used to tunnel these packets.
LAG port states may be impacted if LACP frames are lost because of incorrect prioritization and congestion in the network carrying the tunnel.
LAG sub-group
LAG can provide active/standby redundancy by logically dividing LAG into sub-groups. The LAG is divided into sub-groups by either assigning each LAG’s ports to an explicit sub-group (1 by default), or by automatically grouping all LAG’s ports residing on the same line card into a unique sub-group (auto-iom) or by automatically grouping all LAG’s ports residing on the same MDA into a unique sub-group (auto-mda).
When a LAG is divided into sub-groups, only a single sub-group is elected as active. Which sub-group is selected depends on the LAG selection criteria.
The standby state of a port in the LAG is communicated to the remote end using the LAG standby signaling, which can be either lacp for LACP LAG or best-port for static LAG. The following applies for standby state communication:
-
lacp
The standby state of a port is communicated to the remote system using the LACP protocol.
-
best-port
The standby state of a port is communicated by switching the transmit laser off. This requires the LAG to be configured using selection-criteria best-port and standby-signaling power-off.
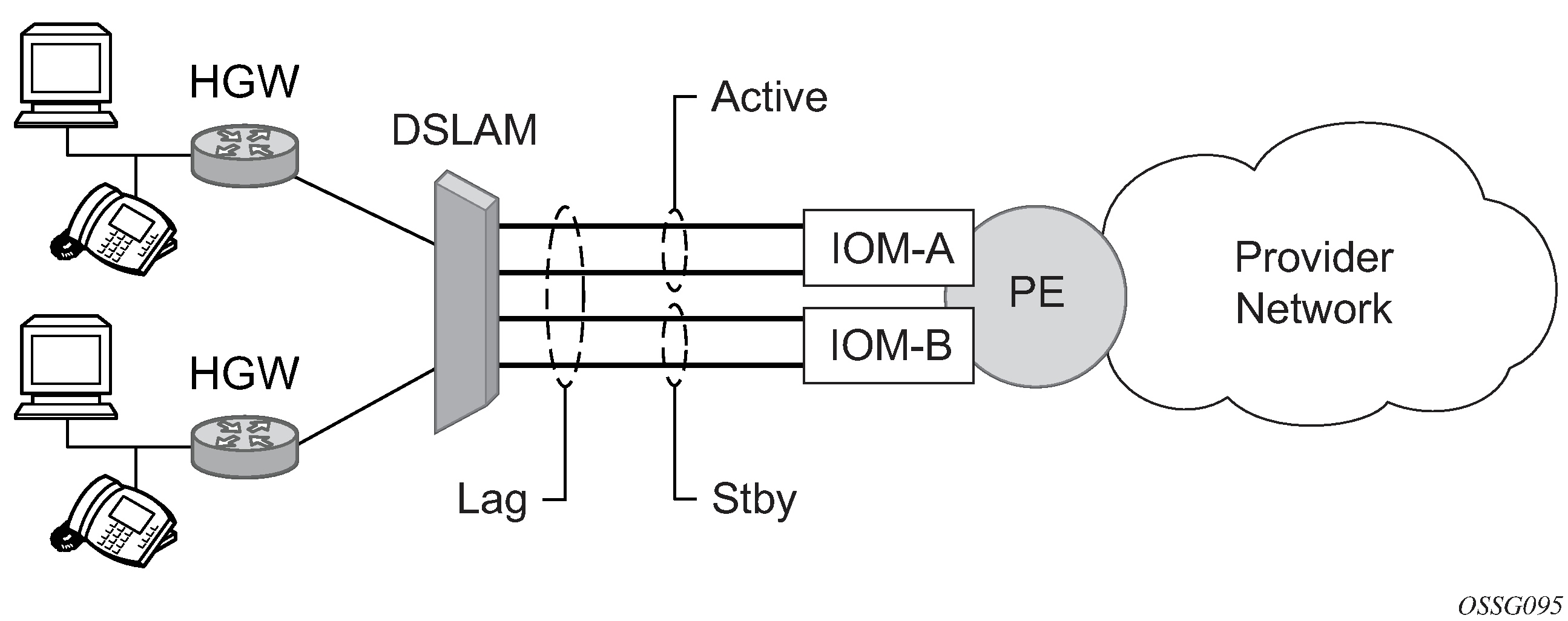
Active-standby LAG operation deployment examples shows how LAG in active/standby mode can be deployed toward a DSLAM access using sub-groups with auto-iom sub-group selection. LAG links are divided into two sub-groups (one per line card).
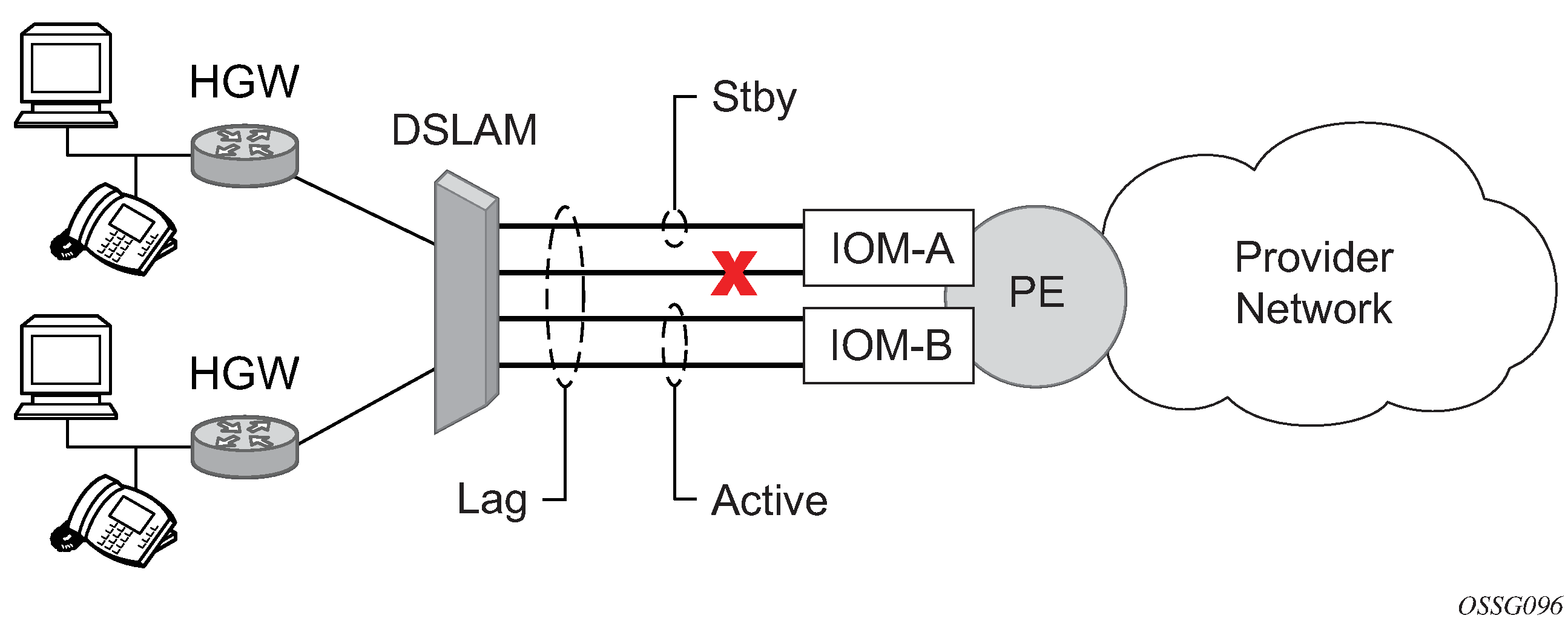
In case of a link failure, as shown in LAG on access interconnection and LAG on access failure switchover, the switch over behavior ensures that all LAG-members connected to the same IOM as failing link become standby and LAG-members connected to other IOM become active. This way, QoS enforcement constraints are respected, while the maximum of available links is used.
Traffic load balancing options
When a requirement exists to increase the available bandwidth for a logical link that exceeds the physical bandwidth or add redundancy for a physical link, typically one of two methods is applied: equal cost multi-path (ECMP) or Link Aggregation (LAG). A system can deploy both at the same time using ECMP of two or more Link Aggregation Groups (LAG) or single links, or both.
Different types of hashing algorithms can be employed to achieve one of the following objectives:
ECMP and LAG load balancing should be influenced solely by the offered flow packet. This is referred to as per-flow hashing.
ECMP and LAG load balancing should maintain consistent forwarding within a specific service. This is achieved using consistent per-service hashing.
LAG load balancing should maintain consistent forwarding on egress over a single LAG port for a specific network interface, SAP, and so on. This is referred as per link hashing (including explicit per-link hashing with LAG link map profiles). Note that if multiple ECMP paths use a LAG with per-link hashing, the ECMP load balancing is done using either per flow or consistent per service hashing.
These hashing methods are described in the following subsections. Although multiple hashing options may be configured for a specific flow at the same time, only one method is selected to hash the traffic based on the following decreasing priority order:
For ECMP load balancing:
Consistent per-service hashing
Per-flow hashing
For LAG load balancing:
LAG link map profile
Per-link hash
Consistent per-service hashing
Per-flow hashing
Per-flow hashing
Per-flow hashing uses information in a packet as an input to the hash function ensuring that any specific flow maps to the same egress LAG port/ECMP path. Note that because the hash uses information in the packet, traffic for the same SAP/interface may be sprayed across different ports of a LAG or different ECMP paths. If this is not wanted, other hashing methods described in this section can be used to change that behavior. Depending on the type of traffic that needs to be distributed into an ECMP or LAG, or both, different variables are used as input to the hashing algorithm that determines the next hop selection. The following describes default per-flow hashing behavior for those different types of traffic:
VPLS known unicast traffic is hashed based on the IP source and destination addresses for IP traffic, or the MAC source and destination addresses for non-IP traffic. The MAC SA/DA are hashed and then, if the Ethertype is IPv4 or IPv6, the hash is replaced with one based on the IP source address/destination address.
VPLS multicast, broadcast and unknown unicast traffic.
Traffic transmitted on SAPs is not sprayed on a per-frame basis, but instead, the service ID selects ECMP and LAG paths statically.
Traffic transmitted on SDPs is hashed on a per packet basis in the same way as VPLS unicast traffic. However, per packet hashing is applicable only to the distribution of traffic over LAG ports, as the ECMP path is still chosen statically based on the service ID.
Data is hashed twice to get the ECMP path. If LAG and ECMP are performed on the same frame, the data is hashed again to get the LAG port (three hashes for LAG). However, if only LAG is performed, then hashing is only performed twice to get the LAG port.
Multicast traffic transmitted on SAPs with IGMP snooping enabled is load-balanced based on the internal multicast ID, which is unique for every (s,g) record. This way, multicast traffic pertaining to different streams is distributed across different LAG member ports.
The hashing procedure that used to be applied for all VPLS BUM traffic would result in PBB BUM traffic being sent out on BVPLS SAP to follow only a single link when MMRP was not used. Therefore, traffic flooded out on egress BVPLS SAPs is now load spread using the algorithm described above for VPLS known unicast.
Unicast IP traffic routed by a router is hashed using the IP SA/DA in the packet.
MPLS packet hashing at an LSR is based on the whole label stack, along with the incoming port and system IP address. Note that the EXP/TTL information in each label is not included in the hash algorithm. This method is referred to as Label-Only Hash option and is enabled by default, or can be re-instated in CLI by entering the lbl-only option. A few options to further hash on the headers in the payload of the MPLS packet are also provided.
VLL traffic from a service access point is not sprayed on a per-packet basis, but as for VPLS flooded traffic, the service ID selects one of the ECMP/LAG paths. The exception to this is when shared-queuing is configured on an Epipe SAP, or Ipipe SAP, or when H-POL is configured on an Epipe SAP. In those cases, traffic spraying is the same as for VPLS known unicast traffic. Packets of the above VLL services received on a spoke SDP are sprayed the same as for VPLS known unicast traffic.
Note that Cpipe VLL packets are always sprayed based on the service-id in both directions.
Multicast IP traffic is hashed based on an internal multicast ID, which is unique for every record similar to VPLS multicast traffic with IGMP snooping enabled.
If the ECMP index results in the selection of a LAG as the next hop, then the hash result is hashed again and the result of the second hash is input to the modulo like operation to determine the LAG port selection.
When the ECMP set includes an IP interface configured on a spoke SDP (IES/VPRN spoke interface), or a Routed VPLS spoke SDP interface, the unicast IP packets—which is sprayed over this interface—is not further sprayed over multiple RSVP LSPs/LDP FEC (part of the same SDP), or GRE SDP ECMP paths. In this case, a single RSVP LSP, LDP FEC next-hop or GRE SDP ECMP path is selected based on a modulo operation of the service ID. In case the ECMP path selected is a LAG, the second round of the hash, hashes traffic based on the system, port or interface load-balancing settings.
In addition to the above described per-flow hashing inputs, the system supports multiple options to modify default hash inputs.
LSR hashing
By default, the LSR hash routine operates on the label stack only. However, the system also offers the ability to hash on the IP header fields of the packet for the purpose of spraying labeled IP packets over ECMP paths in an LSP or over multiple links of a LAG group.
The LSR hashing options can be selected using the following system-wide command.
configure system load-balancing lsr-load-balancingLSR label-only hash
The system hashes the packet using the labels in the MPLS stack and the incoming port (port-id). In the presence of entropy label, the system uses only the entropy label and does not use the incoming port (port-id) for the hash calculation.
The net result is used to select which LSP next-hop to send the packet to using a modulo operation of the hash result with the number of next-hops.
This same result feeds to a second round of hashing if there is LAG on the egress port where the selected LSP has its NHLFE programmed.
Use the following command to enable the label-only hash option.
configure system load-balancing lsr-load-balancing lbl-onlyLSR label-IP hash
In the first hash round for ECMP, the algorithm parses down the label stack and after it reaches the bottom, it checks the next nibble. If the nibble value is 4, it assumes it is an IPv4 packet. If the nibble value is 6, it assumes it is an IPv6 packet. In both cases, the result of the label hash is fed into another hash along with source and destination address fields in the IP packet header. Otherwise, it uses the label stack hash already calculated for the ECMP path selection.
The second round of hashing for LAG re-uses the net result of the first round of hashing.
Use the following command to enable the label-IP hash option.
configure system load-balancing lsr-load-balancing lbl-ipLSR IP-only hash
This option behaves like the label-IP hash option, except that when the algorithm reaches the bottom of the label stack in the ECMP round and finds an IP packet, it throws the outcome of the label hash and only uses the source and destination address fields in the IP packet header.
Use the following command to enable the IP-only hash option.
configure system load-balancing lsr-load-balancing ip-onlyLSR Ethernet encapsulated IP hash
This option behaves like LSR IP-only hash, except for how the IP SA/DA information is found.
After the bottom of the MPLS stack is reached, the hash algorithm verifies that what follows is an Ethernet II untagged or tagged frame. For untagged frames, the system determines the value of Ethertype at the expected packet location and checks whether it contains an Ethernet-encapsulated IPv4 (0x0800) or IPv6 (0x86DD) value. The system also supports Ethernet II tagged frames with up to two 802.1Q tags, provided that the Ethertype value for the tags is 0x8100.
When the Ethertype verification passes, the first nibble of the expected IP packet location is then verified to be 4 (IPv4) or 6 (IPv6).
Use the following command to enable the LSR Ethernet encapsulated IP hash option.
configure system load-balancing lsr-load-balancing eth-encap-ipLSR label, IP, L4, TEID hash
This option hashes the packet based on the MPLS labels and IP header fields IP source and destination address, TCP/UDP source and destination ports, and GTP TEID if the packet is IPv4 or IPv6 by checking the next nibble after the bottom of the label stack.
Use the following command to enable the LSR label, IP, L4, TEID hash option.
configure system load-balancing lsr-load-balancing lbl-ip-l4-teidLSR hashing of MPLS-over-GRE encapsulated packet
When the router removes the GRE encapsulation, pops one or more labels and then swaps a label, it acts as an LSR. The LSR hashing for packets of a MPLS-over-GRE SDP or tunnel follows a different procedure, which is enabled automatically and overrides the LSR hashing option enabled on the incoming network IP interface.
On a packet-by-packet basis, the new hash routine parses through the label stack and the new hash routine hashes on the SA/DA fields and the Layer 4 SRC/DST Port fields of the inner IPv4/IPv6 header.
-
If the GRE header and label stack sizes are such that the Layer4 SRC/DST Port fields are not read, it hashes on the SA/DA fields of the inner IPv4/IPv6 header.
-
If the GRE header and label stack sizes are such that the SA/DA fields of the inner IPv4/IPv6 header are not read, it hashes on the SA/DA fields of the outer IPv4/IPv6 header.
LSR hashing when an Entropy Label is present in the packet's label stack
The LSR hashing procedures are modified as follows:
-
If the lbl-only hashing command option is enabled, or if one of the other LSR hashing options are enabled but an IPv4 or IPv6 header is not detected below the bottom of the label stack, the LSR hashes on the Entropy Label (EL) only.
-
If the lbl-ip hashing command option is enabled, the LSR hashes on the EL and the IP headers.
-
If the ip-only or eth-encap-ip hashing command option is enabled, the LSR hashes on the IP headers only.
Layer 4 load balancing
Users can enable Layer 4 load balancing to include TCP/UDP source/destination port numbers in addition to source/destination IP addresses in per-flow hashing of IP packets. By including the Layer 4 information, a SA/DA default hash flow can be sub-divided into multiple finer-granularity flows if the ports used between a specific SA/DA vary.
Layer 4 load balancing can be enabled or disabled at the system or interface level to improve load balancing distribution by including the TCP or UDP source and destination port of the packet to the hash function.
Use the following command to enable layer 4 load balancing at the system level.
configure system load-balancing l4-load-balancingThis setting applies to unicast traffic, to apply to multicast traffic the following command also needs to be enabled.
configure system load-balancing mc-enh-load-balancingSystem IP load balancing
This option, when enabled, enhances all per-flow load balancing by adding the system IP address to the hash calculation. This capability avoids polarization of flows when a packet is forwarded through multiple routers with a similar number of ECMP/LAG paths.
Use the following command to enable system IP address load balancing.
configure system load-balancing system-ip-load-balancingTEID hash for GTP-encapsulated traffic
This options enables TEID hashing on Layer 3 interfaces. The hash algorithm identifies GTP-C or GTP-U by looking at the UDP destination port (2123 or 2152) of an IP packet to be hashed. If the value of the port matches, the packet is assumed to be GTP-U/C. For GTPv1 packets TEID value from the expected header location is then included in hash. For GTPv2 packets the TEID flag value in the expected header is additionally checked to verify whether TEID is present. If TEID is present, it is included in hash algorithm inputs. TEID is used in addition to GTP tunnel IP hash inputs: SA/DA and SPort/DPort (if Layer 4 load balancing is enabled). If a non-GTP packet is received on the GTP UDP ports above, the packets are hashed as GTP.
Source-only/destination-only hash inputs
This option allows an operator to only include source parameters or only include destination parameters in the hash for inputs that have source/destination context (such as IP address and Layer 4 port). Parameters that do not have source/destination context (such as TEID or System IP for example) are also included in hash as per applicable hash configuration. The functionality allows, among others, to ensure that both upstream and downstream traffic hash to the same ECMP path/LAG port on system egress when traffic is sent to a hair-pinned appliance (by configuring source-only hash for incoming traffic on upstream interfaces and destination-only hash for incoming traffic on downstream interfaces).
Enhanced multicast load balancing
Enhanced multicast load balancing allows users to replace the default multicast per-flow hash input (internal multicast ID) with information from the packet. When enabled, multicast traffic for Layer 3 services (such as IES, VPRN, r-VPLS) and ng-MVPN (multicast inside RSVP-TE, LDP LSPs) are hashed using information from the packet. Which inputs are chosen depends on which per-flow hash inputs options are enabled based on the following:
IP replication
The hash algorithm for multicast mimics unicast hash algorithm using SA/DA by default and optionally TCP/UDP ports (Layer 4 load balancing enabled) and/or system IP (System IP load balancing enabled) and/or source/destination parameters only (Source-only/Destination-only hash inputs).
MPLS replication
The hash algorithm for multicast mimics unicast hash algorithm is described in the LSR hashing section.
Note: Enhanced multicast load balancing is not supported with Layer 2 and ESM services. It is supported on all platforms except for the 7450 ESS in standard mode.
SPI load balancing
IPsec tunneled traffic transported over LAG typically falls back to IP header hashing only. For example, in LTE deployments, TEID hashing cannot be performed because of encryption, and the system performs IP-only tunnel-level hashing. Because each SPI in the IPsec header identifies a unique SA, and therefore flow, these flows can be hashed individually without impacting packet ordering. In this way, SPI load balancing provides a mechanism to improve the hashing performance of IPsec encrypted traffic.
The system allows enabling SPI hashing per Layer 3 interface (this is the incoming interface for hash on system egress)/Layer 2 VPLS service. When enabled, an SPI value from ESP/AH header is used in addition to any other IP hash input based on per-flow hash configuration: source/destination IPv6 addresses, Layer 4 source/dest ports in case NAT traversal is required (Layer 4 load balancing is enabled). If the ESP/AH header is not present in a packet received on a specific interface, the SPI is not part of the hash inputs, and the packet is hashed as per other hashing configurations. SPI hashing is not used for fragmented traffic to ensure first and subsequent fragments use the same hash inputs.
SPI hashing is supported for IPv4 and IPv6 tunnel unicast traffic and for multicast traffic (mc-enh-load-balancing must be enabled) on all platforms and requires Layer 3 interfaces or VPLS service interfaces with SPI hashing enabled to reside on IOM3-XP or newer line-cards.
LAG port hash-weight
The operator can use the LAG port hash-weight to control traffic distribution between LAG ports by adjusting the weight of each port independently.
This capability can be especially useful when the links used by the LAG are rate limited by a 3rd-party operator, as shown in Same speed LAG with ports of different hash-weight:
-
LAG links 1/1/1 and 1/1/2 are GE.
-
LAG link 1/1/1 is rate limited to 300 Mb/s by a 3rd party transport operator.
-
LAG Link 1/1/2 is rate limited to 500 Mb/s by a 3rd party transport operator.
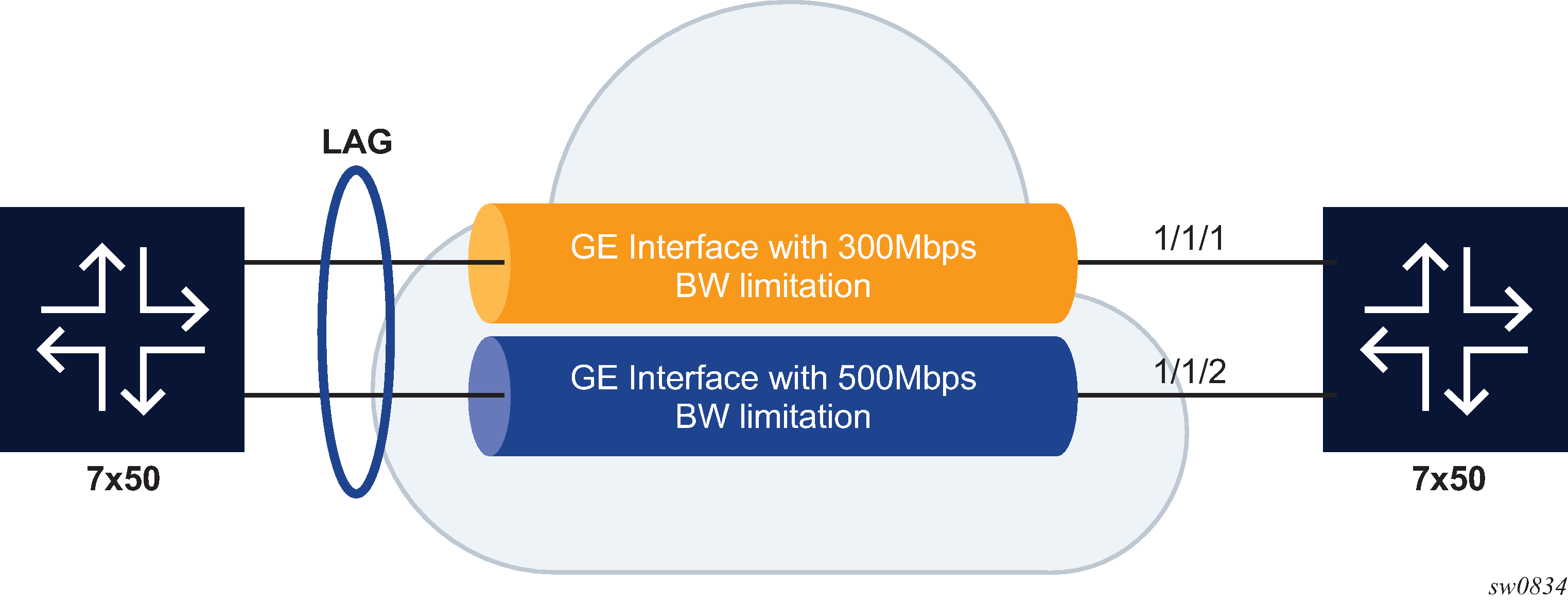
In this context, the user can configure the LAG using customized hash-weight values to adapt the flow distribution between LAG ports according to the bandwidth restrictions on each port. The following example shows the hash-weight configuration.
MD-CLI
[ex:/configure lag "lag-5"]
A:admin@node-2# info
admin-state enable
port 1/1/1 {
hash-weight 300
}
port 1/1/2 {
hash-weight 500
}
classic CLI
A:node-2>config>lag# info
----------------------------------------------
port 1/1/1 hash-weight 300
port 1/1/2 hash-weight 500
no shutdown
----------------------------------------------
Use the following command to display the resulting flow-distribution between active LAG ports.
show lag 3 flow-distribution===============================================================================
Distribution of allocated flows
===============================================================================
Port Bandwidth (Gbps) Hash-weight Flow-share (%)
-------------------------------------------------------------------------------
1/1/1 10.000 300 37.50
1/1/2 10.000 500 62.50
-------------------------------------------------------------------------------
Total operational bandwidth: 20.000
===============================================================================
The following are common rules for configuring hash weights for LAG ports:
-
The configured hash-weight value per port is ignored until all the ports in the LAG have a hash-weight configured.
-
You can set the hash-weight value to port-speed or an integer value from 1 to 100000:
-
port-speed
This assigns an implicit hash-weight value based on the physical port speed.
-
1 to 100000
This value range allows for control of flow hashing distribution between LAG ports.
-
-
The LAG port hash-weight value is normalized internally to distribute flows between LAG ports. The minimum value returned by this normalization is 1.
-
The LAG port hash-weight defaults to the port-speed value when unconfigured.
The following table lists the hash-weight values using port-speed per physical port types.
| Port type | Port speed |
|---|---|
| FE port | port-speed value 1 |
| 1GE port | port-speed value 1 |
| 10GE port | port-speed value 10 |
| 25GE port | port-speed value 25 |
| 40GE port | port-speed value 40 |
| 50GE port | port-speed value 50 |
| 100GE port | port-speed value 100 |
| 400GE port | port-speed value 400 |
| 800GE port | port-speed value 800 |
| Other ports | port-speed value 1 |
The LAG port hash-weight capability is supported for both same-speed and mixed-speed LAGs.
-
If all ports have a hash-weight configured, other than port-speed, the configured value is used and normalized to modify the hashing between LAG ports.
-
If the LAG ports are all configured to port-speed, or if only some of the ports have a customized hash-weight value, the system uses a hash weight of 1 for every port. For mixed-speed LAGs, the system uses the port-speed value.
Mixed-speed LAGs
Combining ports of different speeds in the same LAG is supported, in service, by adding or removing ports of different speeds.
The different combinations of physical port speeds supported in the same LAG are as follows:
-
1GE and 10GE
-
10GE, 25GE, 40GE, 50GE and 100GE
-
100GE and 400GE
The following applies to mixed-speed LAGs:
-
Traffic is load balanced proportionally to the hash-weight value.
-
Both LACP and non-LACP configurations are supported. With LACP enabled, LACP is unaware of physical port speed differences.
-
QoS is distributed according to the following command.
By default, the hash-weight value is taken into account.configure qos adv-config-policy child-control bandwidth-distribution internal-scheduler-weight-mode -
When sub-groups are used, consider the following behavior for selection criteria:
-
highest-count
The highest-count criteria continues to operate on physical link counts. Therefore, a sub-group with lower speed links is selected even if its total bandwidth is lower. For example, a 4 * 10GE sub-group is selected over a 100GE + 10 GE sub-group.
-
highest-weight
The highest-weight criteria continues to operate on user-configured priorities. Therefore, it is expected that configured weights take into account the proportional bandwidth difference between member ports to achieve the wanted behavior. For example, to favor sub-groups with higher bandwidth capacity but lower link count in a 10GE/100GE LAG, set the priority for 100GE ports to a value that is at least 10 times that of the 10GE ports priority value.
-
best-port
The best-port criteria continues to operate on user-configured priorities. Therefore, it is expected that the configured weights take into account proportional bandwidth difference between member ports to achieve the intended behavior.
-
The following are feature limitations for mixed-speed LAGs:
- The PIM lag-usage-optimization command is not supported and must not be configured.
-
LAG member links require the default configuration for egress or ingress rates. Use the following commands to configure the rates:
- MD-CLI
configure port ethernet egress rate configure port ethernet ingress rate - classic
CLI
configure port ethernet egress-rate configure port ethernet ingress-rate
- MD-CLI
-
ESM is not supported.
-
The following applies to LAN and WAN port combinations in the same LAG:
-
100GE LAN with 10GE WAN is supported.
-
100GE LAN with both 10GE LAN and 10GE WAN is supported.
-
Mixed 10GE LAN and 10GE WAN is supported.
-
The following ports do not support a customized LAG port hash-weight value other than port-speed and are not supported in a mixed-speed LAG:
-
VSM ports
-
10/100 FE ports
-
ESAT ports
-
PXC ports
Adaptive load balancing
Adaptive load balancing can be enabled per LAG to resolve traffic imbalance dynamically between LAG member ports. The following can cause traffic distribution imbalance between LAG ports:
-
hashing limitations in the presence of large flows
-
flow bias or service imbalance leading to more traffic over specific ports
Adaptive load balancing actively monitors the traffic rate of each LAG member port and identifies if an optimization can be made to distribute traffic more evenly between LAG ports. The traffic distribution remains flow based with packets of the same flow egressing a single port of the LAG. The traffic rate of each LAG port is polled at regular intervals and an optimization is only executed if the adaptive load balancing tolerance threshold is reached and the minimum bandwidth of the most loaded link in the LAG exceeds the defined bandwidth threshold.
The interval for polling LAG statistics from the line cards is configurable in seconds. The system optimizes traffic distribution after two polling intervals.
The tolerance is a configurable percentage value corresponding to the difference between the most and least loaded ports in the LAG. The following formula is used to calculate the tolerance:
Using a LAG of two ports as an example, where port A = 10 Gb/s and port B = 8 Gb/s, the difference between the most and least loaded ports in the LAG is equal to the following: (10 - 8) / 10 * 100 = 20%.
The bandwidth threshold defines the minimum bandwidth threshold, expressed in percentage, of the most loaded LAG port egress before adaptive load balancing optimization is performed.
- The bandwidth threshold default value is 10% for PXC LAG and 30% for other LAG.
-
Adaptive load balancing is not supported in combination with per-link hash, mixed-speed LAG, customized hash-weight values, per-fp-egr-queuing, per-fp-sap-instance, MC-LAG, or ESM.
- When using port cross-connect or satellite ports, adaptive load balancing rates and the tolerance threshold do not consider egress BUM traffic of the LAG and the adaptive load balance algorithm does not take into account link-map-profile traffic.
-
Contact your Nokia representative for more information about scaling when:
- More than 16 ports per LAG are used in combination with LAG ID 1 to 64 in classic CLI or max-ports 64 in MD-CLI.
- More than 8 ports per LAG are used in combination with LAG ID 65 to 800 in classic CLI or max-ports 32 in MD-CLI.
The following example shows an adaptive load balancing configuration:
MD-CLI
[ex:/configure lag "lag-1"]
A:admin@node-2# info
encap-type dot1q
mode access
adaptive-load-balancing {
tolerance 20
}
port 1/1/1 {
}
port 1/1/2 {
}classic CLI
A:node-2>config>lag# info
----------------------------------------------
mode access
encap-type dot1q
port 1/1/1
port 1/1/2
adaptive-load-balancing tolerance 20
no shutdown
----------------------------------------------
Per-link hashing
The hashing feature described in this section applies to traffic going over LAG and MC-LAG. Per-link hashing ensures all data traffic on a SAP or network interface uses a single LAG port on egress. Because all traffic for a specific SAP/network interface egresses over a single port, QoS SLA enforcement for that SAP, network interface is no longer impacted by the property of LAG (distributing traffic over multiple links). Internally-generated, unique IDs are used to distribute SAPs/network interface over all active LAG ports. As ports go UP and DOWN, each SAP and network interface is automatically rehashed so all active LAG ports are always used.
The feature is best suited for deployments when SAPs/network interfaces on a LAG have statistically similar BW requirements (because per SAP/network interface hash is used). If more control is required over which LAG ports SAPs/network interfaces egress on, a LAG link map profile feature described later in this guide may be used.
Per-link hashing, can be enabled on a LAG as long as the following conditions are met:
-
LAG port-type must be standard.
configure lag port-type -
LAG access adapt-qos must be link or port-fair (for LAGs in mode access or hybrid).
configure lag access adapt-qos -
LAG mode is access or hybrid and the access adapt-qos mode is distribute include-egr-hash-cfg
configure lag mode
Weighted per-link-hash
Weighted per-link-hash allows higher control in distribution of SAPs/interfaces/subscribers across LAG links when significant differences in SAPs/interfaces/subscribers bandwidth requirements could lead to an unbalanced distribution bandwidth utilization over LAG egress. The feature allows operators to configure for each SAPs/interfaces/subscribers on a LAG one of three unique classes and a weight value to be used to when hashing this service/subscriber across the LAG links. SAPs/interfaces/subscribers are hashed to LAG links, such that within each class the total weight of all SAPs/interfaces/subscribers on each LAG link is as close as possible to each other.
Multiple classes allow grouping of SAPs/interfaces/subscribers by similar bandwidth class/type. For example a class can represent: voice – negligible bandwidth, Broadband – 10 to 100 Mb/s, Extreme Broadband – 300 Mb/s and above types of service. If a class and weight are not specified for a specific service or subscriber, values of 1 and 1 are used respectively.
The following algorithm hashes SAPs, interfaces, and subscribers to LAG egress links:
-
TPSDA subscribers are hashed to a LAG link when subscribers are active, MSE SAPs/interfaces are hashed to a LAG link when configured
-
For a new SAP/interface/subscriber to be hashed to an egress LAG link, select the active link with the smallest current weight for the SAP/network/subscriber class.
-
On a LAG link failure:
-
Only SAPs/interfaces/subscribers on a failed link are rehashed over the remaining active links
-
Processing order: per class from lowest numerical, within each class per weight from highest numerical value
-
-
LAG link recovery/new link added to a LAG:
-
auto-rebalance disabled: existing SAPs/interfaces/subscribers remain on the currently active links, new SAPs/interfaces/subscribers naturally prefer the new link until balance reached.
-
auto-rebalance is enabled: when a new port is added to a LAG a non-configurable 5 second rebalance timer is started. Upon timer expiry, all existing SAPs/interfaces/subscribers are rebalanced across all active LAG links minimizing the number of SAPs/interfaces/subscribers moved to achieve rebalance. The rebalance timer is restarted if a new link is added while the timer is running. If a port bounces 5 times within a 5 second interval, the port is quarantined for10 seconds. This behavior is not configurable.
-
On a LAG startup, the rebalance timer is always started irrespective of auto-rebalance configuration to avoid hashing SAPs/interfaces/subscribers to a LAG before ports have a chance to come UP.
-
-
Weights for network interfaces are separated from weights for access SAPs/interfaces/subscribers.
-
On a mixed-speed LAG, link selection is made with link speeds factoring into the overall weight for the same class of traffic. This means that higher-speed links are preferred over lower-speed links.
tools perform lag load-balanceAlong with the restrictions for standard per-link hashing, the following restrictions exist:
-
When weighted per-link-hash is deployed on a LAG, no other methods of hash for subscribers/SAPs/interfaces on that LAG (like service hash or LAG link map profile) should be deployed, because the weighted hash is not able to account for loads placed on LAG links by subscriber/SAPs/interfaces using the other hash methods.
-
For the TPSDA model only the 1:1 (subscriber to SAP) model is supported.
This feature does not operate properly if the above conditions are not met.
Explicit per-link hash using LAG link mapping profiles
The hashing feature described in this section applies to traffic going over LAG and MC-LAG. LAG link mapping profile feature gives users full control of which links SAPs/network interface use on a LAG egress and how the traffic is rehashed on a LAG link failure. Some benefits that such functionality provides include:
-
Ability to perform management level admission control onto LAG ports therefore increasing overall LAG BW utilization and controlling LAG behavior on a port failure.
-
Ability to strictly enforce QoS contract on egress for a SAP or network interface or a group of SAPs or network interfaces by forcing egress over a single port and using one of the following commands:
- MD-CLI
configure lag access adapt-qos mode link configure lag access adapt-qos mode port-fair - classic
CLI
configure lag access adapt-qos link configure lag access adapt-qos port-fair
- MD-CLI
To enable LAG Link Mapping Profile Feature on a LAG, users configure one or more of the available LAG link mapping profiles on the LAG and then assign that profiles to all or a subset of SAPs and network interfaces as needed. Enabling per LAG link Mapping Profile is allowed on a LAG with services configured, a small outage may take place as result of re-hashing SAP/network interface when a lag profile is assigned to it.
Use the following command to configure a LAG Link Mapping Profile Feature on a LAG.
- MD-CLI
configure lag link-map-profile link port-type - classic
CLI
configure lag link-map-profile link
Each LAG link mapping profile allows users to configure:
- primary link
- a port of the LAG to be used by a SAP or network interface when the port is UP. Note that a port cannot be removed from a LAG if it is part of any LAG link profile.
- secondary link
- a port of the LAG to be used by a SAP or network interface as a backup when the primary link is not available (not configured or down) and the secondary link is UP
When neither primary, nor secondary links are available (not configured or down), use the following command to configure a failure mode of operation.
configure lag link-map-profile failure-modeThe failure mode of operation command options include:
-
discard
Traffic for a specific SAP or network interface is dropped to protect other SAPs/network interfaces from being impacted by re-hashing these SAPs or network interfaces over remaining active LAG ports.
Note: SAP or network interface status is not affected when primary and secondary links are unavailable, unless an OAM mechanism that follows the datapath hashing on egress is used and causes a SAP or network interface to go down. -
per-link-hash
Traffic for a specific SAP or network interface is re-hashed over remaining active ports of a LAG links using per-link-hashing algorithm. This behavior ensures that SAPs or network interfaces using this profile are provided available resources of other active LAG ports even if it impacts other SAPs or network interfaces on the LAG. The system uses the QoS configuration to provide fairness and priority if congestion is caused by the default-hash recovery.
LAG link mapping profiles, can be enabled on a LAG as long as the following conditions are met:
-
LAG port-type must be standard.
-
LAG access adapt-qos must be link or port-fair (for LAGs in mode access or hybrid)
-
All ports of a LAG on a router must belong to a single sub-group.
-
Access adapt-qos mode is distribute include-egr-hash-cfg.
LAG link mapping profile can coexist with any-other hashing used over a specific LAG (for example, per-flow hashing or per-link-hashing). SAPs/network interfaces that have no link mapping profile configured are subject to LAG hashing, while SAPs/network interfaces that have configured LAG profile assigned are subject to LAG link mapping behavior, which is described above.
Consistent per-service hashing
The hashing feature described in this section applies to traffic going over LAG, Ethernet tunnels (eth-tunnel) in load-sharing mode, or CCAG load balancing for VSM redundancy. The feature does not apply to ECMP.
Per-service-hashing was introduced to ensure consistent forwarding of packets belonging to one service. The feature can be enabled using the per-service-hashing command under the following contexts and is valid for Epipe, VPLS, PBB Epipe, IVPLS and BVPLS.
configure service epipe load-balancing
configure service vpls load-balancingThe following behavior applies to the usage of the [no] per-service-hashing option.
-
The setting of the PBB Epipe/I-VPLS children dictates the hashing behavior of the traffic destined for or sourced from an Epipe/I-VPLS endpoint (PW/SAP).
-
The setting of the B-VPLS parent dictates the hashing behavior only for transit traffic through the B-VPLS instance (not destined for or sourced from a local I-VPLS/Epipe children).
The following algorithm describes the hash-key used for hashing when the new option is enabled:
-
If the packet is PBB encapsulated (contains an I-TAG Ethertype) at the ingress side and enters a B-VPLS service, use the ISID value from the I-TAG. For PBB encapsulated traffic entering other service types, use the related service ID.
-
If the packet is not PBB encapsulated at the ingress side
-
For regular (non-PBB) VPLS and Epipe services, use the related service ID
-
If the packet is originated from an ingress IVPLS or PBB Epipe SAP
-
If there is an ISID configured use the related ISID value
-
If there is no ISID configured use the related service ID
-
-
For BVPLS transit traffic use the related flood list ID
-
Transit traffic is the traffic going between BVPLS endpoints
-
An example of non-PBB transit traffic in BVPLS is the OAM traffic
-
-
-
The above rules apply to Unicast, BUM flooded without MMRP or with MMRP, IGMP snooped regardless of traffic type
Users may sometimes require the capability to query the system for the link in a LAG or Ethernet tunnel that is currently assigned to a specific service-id or ISID.
Use the following command to query the system for the link in a LAG or Ethernet tunnel that is currently assigned to a specific service-id or ISID.
tools dump map-to-phy-port lag 11 service 1ServiceId ServiceName ServiceType Hashing Physical Link
---------- ------------- -------------- ----------------------- -------------
1 i-vpls per-service(if enabled) 3/2/8
A:Dut-B# tools dump map-to-phy-port lag 11 isid 1
ISID Hashing Physical Link
-------- ----------------------- -------------
1 per-service(if enabled) 3/2/8
A:Dut-B# tools dump map-to-phy-port lag 11 isid 1 end-isid 4
ISID Hashing Physical Link
-------- ----------------------- -------------
1 per-service(if enabled) 3/2/8
2 per-service(if enabled) 3/2/7
3 per-service(if enabled) 1/2/2
4 per-service(if enabled) 1/2/3
ESM
In ESM, egress traffic can be load balanced over LAG member ports based on the following entities:
-
Per subscriber, in weighted and non-weighted mode
-
Per Vport, on non HSQ cards in weighted and non-weighted
-
Per secondary shaper on HSQ cards
-
Per destination MAC address when ESM is configured in a VPLS (Bridged CO)
ESM over LAGs with configured PW ports require additional considerations:
-
PW SAPs are not supported in VPLS services or on HSQ cards. This means that load balancing per secondary shaper or destination MAC are not supported on PW ports with a LAG configured under them.
-
Load balancing on a PW port associated with a LAG with faceplate member ports (fixed PW ports) can be performed per subscriber or Vport.
-
Load balancing on a FPE (or PXC)-based PW port is performed on two separate LAGs which can be thought of as two stages:
-
Load balancing on a PXC LAG where the subscribers are instantiated. In this first stage, the load balancing can be performed per subscriber or per Vport.
-
The second stage is the LAG over the network faceplate ports over which traffic exits the node. Load balancing is independent of ESM and must be examined in the context of Epipe or EVPN VPWS that is stitched to the PW port.
-
Load balancing per subscriber
Load balancing per subscriber supports two modes of operation.
The first mode is native non-weighted per-subscriber load balancing in which traffic is directly hashed per subscriber. Use this mode in SAP and subscriber (1:1) deployments and in SAP and service (N:1) deployments. Examples of services in SAP and services deployments are VoIP, video, or data.
In this mode of operation, the following configuration requirements must be met.
-
Any form of the per-link-hash command in a LAG under the configure lag context must be disabled. This is the default setting.
-
If QoS schedulers or Vports are used on the LAG, their bandwidth must be distributed over LAG member ports in a port-fair operation.
configure lag access adapt-qos port-fairIn this scenario, setting this parameter to in adapt-qos to mode link disables per-subscriber load balancing and enables per-Vport load balancing.
configure lag per-link-hash weighted subscriber-hash-mode sapIn this scenario where hashing is performed per SAP, as reflected in the CLI above, in terms of load balancing, per-SAP hashing produces the same results as per-subscriber hashing because SAPs and subscribers are in in a 1:1 relationship. The end result is that the traffic is load balanced per-subscribers, regardless of this indirection between hashing and load-balancing.
With the per-link-hash option enabled, the SAPs (and with this, the subscribers) are dynamically distributed over the LAG member links. This dynamic behavior can be overridden by configuring the lag-link-map-profiles command under the static SAPs or under the msap-policy. This way, each static SAP, or a group of MSAPs sharing the same msap-policy are statically and deterministically assigned to a preordained member port in a LAG.
This mode allows classes and weights to be configured for a group of subscribers with a shared subscriber profile under the following hierarchy.
- MD-CLI
configure subscriber-mgmt sub-profile egress lag-per-link-hash class configure subscriber-mgmt sub-profile egress lag-per-link-hash weight - classic
CLI
configure subscriber-mgmt sub-profile egress lag-per-link-hash class {1|2|3} weight <[1 to 1024]>
Default values for class and weight are 1. If all subscribers on a LAG are configured with the same values for class and weight, load balancing effectively becomes non-weighted.
If QoS schedulers and Vports are used on the LAG, their bandwidth should be distributed over LAG member ports in a port-fair operation.
- MD-CLI
configure lag "lag-100" access adapt-qos mode port-fair - classic
CLI
configure lag access adapt-qos port-fair
Load balancing per Vport
Load balancing per Vport applies to user bearing traffic, and not to the control traffic originated or terminated on the BNG, required to setup and maintain sessions, such as PPPoE and DHCP setup and control messages.
Per Vport load balancing supports two modes of operation.
In the first mode, non-weighted load balancing based on Vport hashing, the following LAG-related configuration is required.
The per-link-hash command must be disabled.
- MD-CLI
configure lag access adapt-qos mode link - classic
CLI
configure lag access adapt-qos link
If LAG member ports are distributed over multiple forwarding complexes, the following configuration is required.
configure subscriber-mgmt sub-profile vport-hashingThe second mode, weighted load balancing based on Vport hashing, supports class and weight parameters per Vport. To enable weighted traffic load balancing per Vport, the following configuration must be enabled.
configure lag per-link-hash weighted subscriber-hash-mode vportThe class and weight can be optionally configured under the Vport definition.
- MD-CLI
configure port ethernet access egress virtual-port lag-per-link-hash class configure port ethernet access egress virtual-port lag-per-link-hash weight - classic
CLI
configure port ethernet access egress vport lag-per-link-hash class weight
Load balancing per secondary shaper
Load balancing based on a secondary shaper is supported only on HSQ cards and only in non-weighted mode. The following LAG-related configuration is required. The per-link-hash command first must be disabled.
- MD-CLI
configure lag "lag-100" access adapt-qos mode link - classic
CLI
configure lag access adapt-qos link
Use the following command to disable per-link-hash.
- MD-CLI
configure lag delete per-link-hash - classic
CLI
configure lag no per-link-hash
Load balancing per destination MAC
This load balancing mode is supported only when ESM is enabled in VPLS in Bridged Central Office (CO) deployments. In this mode of operation, the following configuration is required. The per-link-hash command first must be disabled.
configure subscriber-mgmt msap-policy vpls-only-sap-parameters mac-da-hashing
configure service vpls sap sub-sla-mgmt mac-da-hashing IPv6 flow label load balancing
IPv6 flow label load balancing enables load balancing in ECMP and LAG based on the output of a hash performed on the triplet {SA, DA, Flow-Label} in the header of an IPv6 packet received on a IES, VPRN, R-VPLS, CsC, or network interface.
IPv6 flow label load balancing complies with the behavior described in RFC 6437. When the flow-label-load-balancing command is enabled on an interface, the router applies a hash on the triplet {SA, DA, Flow-Label} to IPv6 packets received with a non-zero value in the flow label.
If the flow label field value is zero, the router performs the hash on the packet header; using the existing behavior based on the global or interface-level commands.
When enabled, IPv6 flow label load balancing also applies hashing on the triplet {SA, DA, Flow-Label} of the outer IPv6 header of an SRv6 encapsulated packet that is received on a network interface of a SRv6 transit router.
At the ingress PE router, SRv6 supports inserting the output of the hash that is performed on the inner IPv4, IPv6, or Ethernet service packet header into the flow label field of the outer IPv6 header it pushes on the SRv6 encapsulated packet.
For more details of the hashing and spraying of packets in SRv6, see the 7750 SR and 7950 XRS Segment Routing and PCE User Guide.
The flow label field in the outer header of a received IPv6 or SRv6 encapsulated packet is never modified in the datapath.
Interaction with other load balancing features
IPv6 flow label load balancing interacts with other load balancing features as follows:
-
When the flow-label-load-balancing command is enabled on an interface and the global level l4-load-balancing command is also enabled, it applies to all IPv4 packets and to IPv6 packets with a flow label field of zero.
-
The following global load-balancing commands apply independently to the corresponding non-IPv6 packet encapsulations:
-
lsr-load-balancing
-
mc-enh-load-balancing
-
service-id-lag-hashing
-
-
When the flow-label-load-balancing command is enabled on an interface and the global load balancing l2tp-load-balancing command is enabled, it applies to the following situations:
-
packets received with L2TPv2 over UDP/IPv4 encapsulation
-
packets received with L2TPv3 over UDP/IPv4 encapsulation
-
packets received with L2TPv3 over UDP/IPv6 encapsulation if the flow label field is zero. Otherwise, flow label hashing applies.
Packets received with L2TPv3 directly over IPv6 are not hashed on the L2TPv3 session ID. Therefore, hashing of these packets is based on the other interface level hash commands if the flow label field is zero. If the flow label is not zero, flow label hashing applies.
Note: SR OS implementation of L2TPv3 supports UDP/IPv6 encapsulation only. However, third-party implementations may support L2TPv3 directly over IPv6 encapsulation. -
-
The global load-balancing command selects a different hashing algorithm and therefore applies all the time when enabled, including when the flow-label-load-balancing command is enabled on the interface: system-ip-load-balancing.
-
When the flow-label-load-balancing command is enabled on an interface and the per-interface spi-load-balancing or teid-load-balancing commands are enabled, they apply to all IPv4 packets and to IPv6 packets with a flow label field of zero.
-
The following per-interface load-balancing command applies independently to MPLS encapsulated packets: lsr-load-balancing
-
The flow-label-load-balancing command and the following command are mutually exclusive, which the CLI enforces:
- MD-CLI
configure router interface load-balancing ip-load-balancing - classic
CLI
configure router interface load-balancing egr-ip-load-balancing
- MD-CLI
-
The following per-LAG port packet spraying commands override the flow-label-load-balancing command. IPv6 packets, with a non-zero flow label value, are sprayed over LAG links according to the enabled LAG-spraying mode.
-
per-link-hash
-
link-map-profile
-
QoS consideration for access LAG
The following section describes various QoS related features applicable to LAG on access.
Adapt QoS modes
Link Aggregation is supported on the access side with access or hybrid ports. Similarly to LAG on the network side, LAG on access aggregates Ethernet ports into all active or active-standby LAG. The difference with LAG on networks lies in how the QoS or H-QoS is handled. Based on hashing configured, a SAP’s traffic can be sprayed on egress over multiple LAG ports or can always use a single port of a LAG. There are three user-selectable modes that allow the user to best adapt QoS configured to a LAG the SAPs are using:
-
distribute (default)
Use the following command to configure the distributed mode:- MD-CLI
configure lag access adapt-qos mode distribute - classic
CLI
configure lag access adapt-qos distribute
In the distribute mode, the SLA is divided among all line cards proportionate to the number of ports that exist on that line card for a specific LAG. For example, a 100 Mb/s PIR with 2 LAG links on IOM A and 3 LAG links on IOM B would result in IOM A getting 40 Mb/s PIR and IOM B getting 60 Mb/s PIR. Because of this distribution, SLA can be enforced. The disadvantage is that a single flow is limited to IOM’s share of the SLA. This mode of operation may also result in underrun because of hashing imbalance (traffic not sprayed equally over each link). This mode is best suited for services that spray traffic over all links of a LAG.
- MD-CLI
-
link
Use the following command to configure the link mode:- MD-CLI
configure lag access adapt-qos mode link - classic
CLI
configure lag access adapt-qos link
In a link mode the SLA is provided to each port of a LAG. With the example above, each port would get 100 Mb/s PIR. The advantage of this method is that a single flow can now achieve the full SLA. The disadvantage is that the overall SLA can be exceeded, if the flows span multiple ports. This mode is best suited for services that are guaranteed to hash to a single egress port.
- MD-CLI
-
port-fair
Use the following command to configure the port-fair mode:- MD-CLI
configure lag access adapt-qos mode port-fair - classic
CLI
configure lag access adapt-qos port-fair
Port-fair distributes the SLA across multiple line cards relative to the number of active LAG ports per card (in a similar way to distribute mode) with all LAG QoS objects parented to scheduler instances at the physical port level (in a similar way to link mode). This provides a fair distribution of bandwidth between cards and ports whilst ensuring that the port bandwidth is not exceeded. Optimal LAG utilization relies on an even hash spraying of traffic to maximize the use of the schedulers' and ports' bandwidth. With the example above, enabling port-fair would result in all five ports getting 20 Mb/s.
When port-fair mode is enabled, per-Vport hashing is automatically disabled for subscriber traffic such that traffic sent to the Vport no longer uses the Vport as part of the hashing algorithm. Any QoS object for subscribers, and any QoS object for SAPs with explicitly configured hashing to a single egress LAG port, are given the full bandwidth configured for each object (in a similar way to link mode). A Vport used together with an egress port scheduler is supported with a LAG in port-fair mode, whereas it is not supported with a distribute mode LAG.
- MD-CLI
-
distribute include-egr-hash-cfg
Use the following commands to configure the distributed include-egr-hash-cfg mode:- MD-CLI
configure lag access adapt-qos mode distribute configure lag access adapt-qos include-egr-hash-cfg - classic
CLI
configure lag access adapt-qos distribute include-egr-hash-cfg
This mode can be considered a mix of link and distributed mode. The mode uses the configured hashing for LAG/SAP/service to choose either link or distributed adapt-qos modes. The mode allows:
-
SLA enforcement for SAPs that through configuration are guaranteed to hash to a single egress link using full QoS per port (as per link mode)
-
SLA enforcement for SAPs that hash to all LAG links proportional distribution of QoS SLA amongst the line cards (as per distributed mode)
-
SLA enforcement for multi service sites (MSS) that contain any SAPs regardless of their hash configuration using proportional distribution of QoS SLA amongst the line cards (as per distributed mode)
- MD-CLI
The following restrictions apply to adapt-qos distributed include-egr-hash-cfg:
LAG mode must be access or hybrid.
When link-map-profiles or per-link-hash is configured, the user cannot change from include-egr-hash-cfg mode to distribute mode.
The user cannot change from link to include-egr-hash-cfg on a LAG with any configuration.
Adapt QoS bandwidth/rate distribution shows examples of rate/BW distributions based on the adapt-qos mode used.
| distribute | link | port-fair | distribute include-egr-hash-cfg | |
|---|---|---|---|---|
SAP Queues |
% # local links1 | 100% rate |
100% rate (SAP hash to one link) or %# all links2 (SAP hash to all links) |
100% rate (SAP hash to one link) or % # local linksa (SAP hash to all links) |
SAP Scheduler |
% # local linksa |
100% bandwidth |
100% rate (SAP hash to one link) or %# all linksb (SAP hash to all links) |
100% bandwidth (SAP hash to a one link) or % # local linksa (SAP hash to all links) |
SAP MSS Scheduler |
% # local linksa |
100% bandwidth |
% # local linksa |
% # local linksa |
Per-fp-ing-queuing
Per-fp-ing-queuing optimization for LAG ports provides the ability to reduce the number of hardware queues assigned on each LAG SAP on ingress when the flag at LAG level is set for per-fp-ing-queuing.
When the feature is enabled in the configure lag access context, the queue allocation for SAPs on a LAG are optimized and only one queuing set per ingress forwarding path (FP) is allocated instead of one per port.
The following rules apply for configuring the per-fp-ing-queuing at LAG level:
-
To enable per-fp-ing-queuing, the LAG must be in access mode
-
The LAG mode cannot be set to network mode when the feature is enabled
-
Per-fp-ing-queuing can only be set if no port members exists in the LAG
Per-fp-egr-queuing
Per-fp-egr-queuing optimization for LAG ports provides the ability to reduce the number of egress resources consumed by each SAP on a LAG, and by any encap groups that exist on those SAPs.
When the feature is enabled in the configure lag access context, the queue and virtual scheduler allocation are optimized. Only one queuing set and one H-QoS virtual scheduler tree per SAP/encap group is allocated per egress forwarding path (FP) instead of one set per each port of the LAG. In case of a link failure/recovery, egress traffic uses failover queues while the queues are moved over to a newly active link.
Per-fp-egr-queuing can be enabled on existing LAG with services as long as the following conditions are met.
-
The mode of the LAG must be access or hybrid.
-
The port-type of the LAGs must be standard.
-
The LAG must have either per-link-hash enabled or all SAPs on the LAG must use per-service-hashing only and be of a type: VPLS SAP, i-VPLS SAP, or e-Pipe VLL or PBB SAP.
To disable per-fp-egr-queuing, all ports must first be removed from a specific LAG.
Per-fp-sap-instance
Per-fp-sap-instance optimization for LAG ports provides the ability to reduce the number of SAP instance resources consumed by each SAP on a lag.
When the feature is enabled, in the config>lag>access context, a single SAP instance is allocated on ingress and on egress per each forwarding path instead of one per port. Thanks to an optimized resource allocation, the SAP scale on a line card increases, if a LAG has more than one port on that line card. Because SAP instances are only allocated per forwarding path complex, hardware reprogramming must take place when as result of LAG links going down or up, a SAP is moved from one LAG port on a specific line card to another port on a specific line card within the same forwarding complex. This results in an increased data outage when compared to per-fp-sap-instance feature being disabled. During the reprogramming, failover queues are used when SAP queues are reprogrammed to a new port. Any traffic using failover queues is not accounted for in SAPs statistics and is processed at best-effort priority.
The following rules apply when configuring a per-fp-sap-instance on a LAG:
Per-fp-ing-queuing and per-fp-egr-queuing must be enabled.
The functionality can be enabled/disabled on LAG with no member ports only. Services can be configured.
Other restrictions:
SAP instance optimization applies to LAG-level. Whether a LAG is sub-divided into sub-groups or not, the resources are allocated per forwarding path for all complexes LAG’s links are configured on (that is irrespective of whether a sub-group a SAP is configured on uses that complex or not).
Egress statistics continue to be returned per port when SAP instance optimization is enabled. If a LAG links are on a single forwarding complex, all ports but one have no change in statistics for the last interval – unless a SAP moved between ports during the interval.
Rollback that changes per-fp-sap-instance configuration is service impacting.
LAG hold-down timers
Users can configure multiple hold-down timers that allow control how quickly LAG responds to operational port state changes. The following timers are supported:
-
port-level hold-time up/down timer
This optional timer allows user to control delay for adding/removing a port from LAG when the port comes UP/goes DOWN. Each LAG port runs the same value of the timer, configured on the primary LAG link. See the Port Link Dampening description in Port features for more details on this timer.
-
sub-group-level hold-time timer
This optional timer allows user to control delay for a switch to a new candidate sub-group selected by LAG sub-group selection algorithm from the current, operationally UP sub-group. The timer can also be configured to never expire, which prevents a switch from operationally up sub-group to a new candidate sub-group (manual switchover is possible using tools perform force lag command). Note that, if the port link dampening is deployed, the port level timer must expire before the sub-group-selection takes place and this timer is started. Sub-group-level hold-down timer is supported with LAGs running LACP only.
-
LAG-level hold-time down timer
This optional timer allows user to control delay for declaring a LAG operationally down when the available links fall below the required port/BW minimum. The timer is recommended for LAG connecting to MC-LAG systems. The timer prevents a LAG going down when MC-LAG switchover executes break-before-make switch. Note that, if the port link dampening is deployed, the port level timer must expire before the LAG operational status is processed and this timer is started.
BFD over LAG links
The router supports the application of micro-BFD to monitor individual LAG link members to speed up the detection of link failures. When BFD is associated with an Ethernet LAG, BFD sessions are setup over each link member, and are referred to as micro-BFD sessions. A link is not operational in the associated LAG until the associated micro-BFD session is fully established. In addition, the link member is removed from the operational state in the LAG if the BFD session fails.
- MD-CLI
configure lag bfd-liveness ipv4 local-ip-address configure lag bfd-liveness ipv4 remote-ip-address configure lag bfd-liveness ipv6 local-ip-address configure lag bfd-liveness ipv6 remote-ip-address - classic
CLI
configure lag bfd family ipv4 local-ip-address configure lag bfd family ipv4 remote-ip-address configure lag bfd family ipv6 local-ip-address configure lag bfd family ipv6 remote-ip-address
-
system IP address
-
local IP address
-
static link local IPv6
Multi-chassis LAG
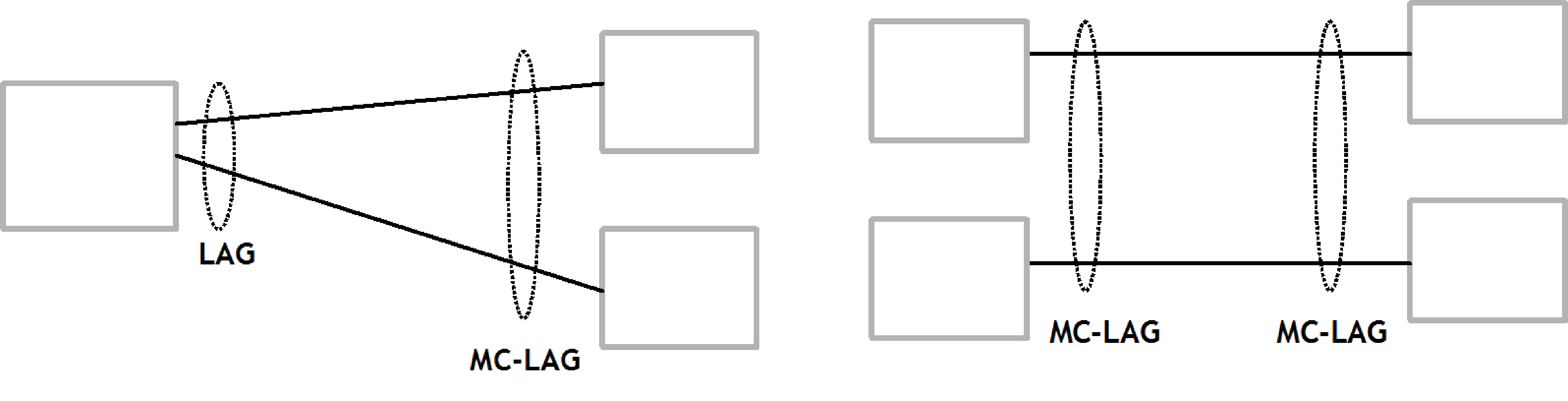
This section describes the Multi-Chassis LAG (MC-LAG) concept. MC-LAG is an extension of a LAG concept that provides node-level redundancy in addition to link-level redundancy provided by ‟regular LAG”.
Typically, MC-LAG is deployed in a network-wide scenario providing redundant connection between different end points. The whole scenario is then built by combination of different mechanisms (for example, MC-LAG and redundant pseudowire to provide e2e redundant p2p connection or dual homing of DSLAMs in Layer 2/3 TPSDA).
Overview
Multi-chassis LAG is a method of providing redundant Layer 2/3 access connectivity that extends beyond link level protection by allowing two systems to share a common LAG end point.
The multi-service access node (MSAN) node is connected with multiple links toward a redundant pair of Layer 2/3 aggregation nodes such that both link and node level redundancy, are provided. By using a multi-chassis LAG protocol, the paired Layer 2/3 aggregation nodes (referred to as redundant-pair) appears to be a single node utilizing LACP toward the access node. The multi-chassis LAG protocol between a redundant-pair ensures a synchronized forwarding plane to and from the access node and synchronizes the link state information between the redundant-pair nodes such that correct LACP messaging is provided to the access node from both redundant-pair nodes.
To ensure SLAs and deterministic forwarding characteristics between the access and the redundant-pair node, the multi-chassis LAG function provides an active/standby operation to and from the access node. LACP is used to manage the available LAG links into active and standby states such that only links from 1 aggregation node are active at a time to/from the access node.
configure lag standby-signaling power-off-
Selection of the common system ID, system-priority and administrative-key are used in LACP messages so partner systems consider all links as the part of the same LAG.
-
Extension of selection algorithm to allow selection of active sub-group.
-
The sub-group definition in LAG context is still local to the single box, meaning that even if sub-groups configured on two different systems have the same sub-group-id they are still considered as two separate sub-groups within a specified LAG.
-
Multiple sub-groups per PE in an MC-LAG is supported.
-
In case there is a tie in the selection algorithm, for example, two sub-groups with identical aggregate weight (or number of active links) the group which is local to the system with lower system LACP priority and LAG system ID is taken.
-
-
Providing inter-chassis communication channel allows inter-chassis communication to support LACP on both system. This communication channel enables the following:
-
Supports connections at the IP level which do not require a direct link between two nodes. The IP address configured at the neighbor system is one of the addresses of the system (interface or loop-back IP address).
-
The communication protocol provides heartbeat mechanism to enhance robustness of the MC-LAG operation and detecting node failures.
-
Support for operator actions on any node that force an operational change.
-
The LAG group-ids do not have to match between neighbor systems. At the same time, there can be multiple LAG groups between the same pair of neighbors.
-
Verification that the physical characteristics, such as speed and auto-negotiation is configured and initiates operator notifications (traps) if errors exist. Consistency of MC-LAG configuration (system-id, administrative-key and system-priority) is provided. Similarly, load-balancing mode of operation must be consistently configured on both nodes.
-
Traffic over the signaling link is encrypted using a user configurable message digest key.
-
-
MC-LAG function provides active/stand-by status to other software applications to build a reliable solution.
MC-LAG Layer 2 dual homing to remote PE pairs and MC-LAG Layer 2 dual homing to local PE pairs show the different combinations of MC-LAG attachments that are supported. The supported configurations can be sub-divided into following sub-groups:
-
Dual-homing to remote PE pairs
-
both end-points attached with MC-LAG
-
one end-point attached
-
-
Dual-homing to local PE pair
-
both end-points attached with MC-LAG
-
one end-point attached with MC-LAG
-
both end-points attached with MC-LAG to two overlapping pairs
-
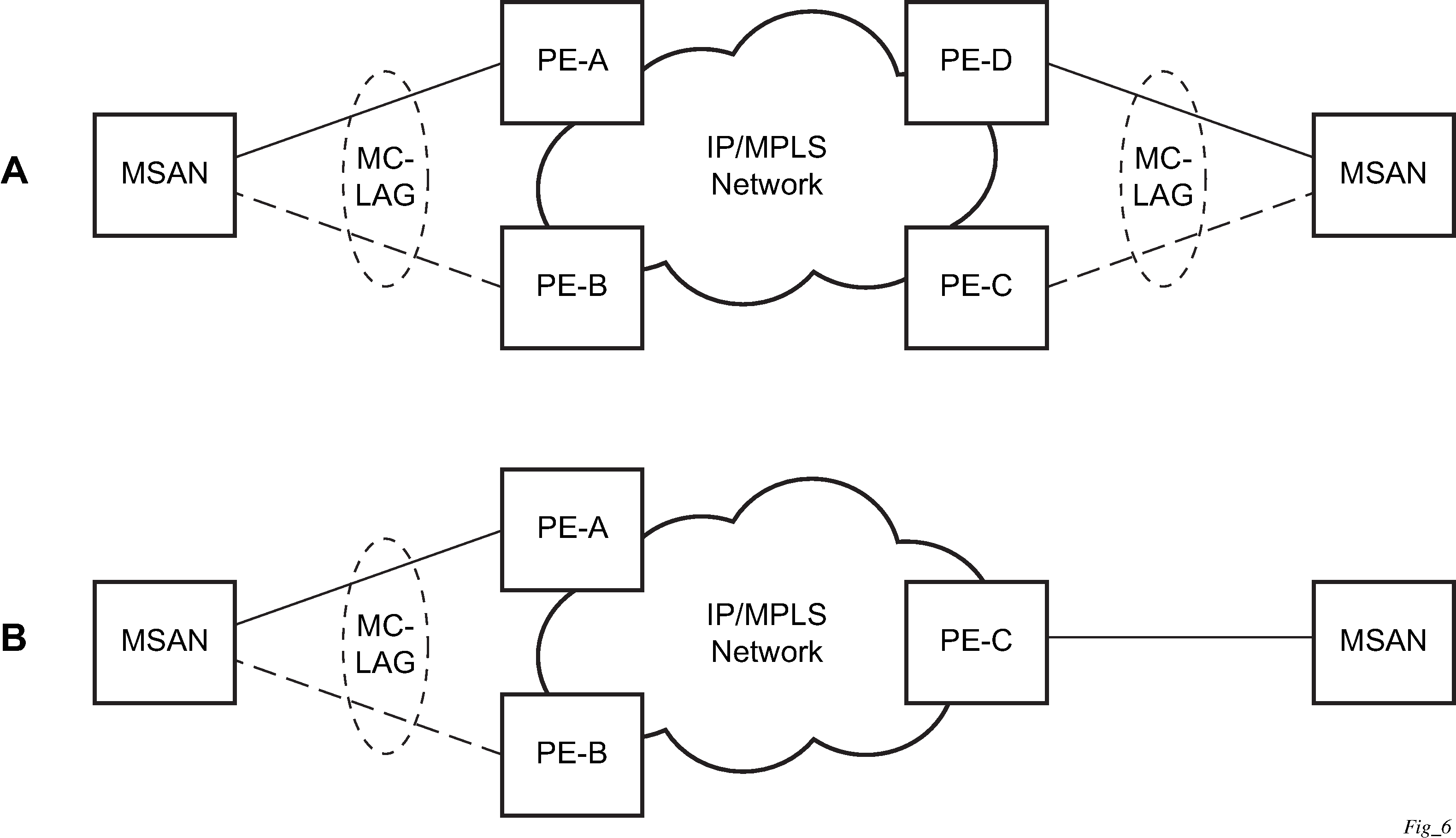
The forwarding behavior of the nodes abide by the following principles. Note that logical destination (actual forwarding decision) is primarily determined by the service (VPLS or VLL) and the principle below applies only if destination or source is based on MC-LAG:
-
Packets received from the network are forwarded to all local active links of the specific destination-sap based on conversation hashing. In case there are no local active links, the packets are cross-connected to inter-chassis pseudowire.
-
Packets received from the MC-LAG sap are forwarded to active destination pseudowire or active local links of destination-sap. In case there are no such objects available at the local node, the packets are cross-connected to inter-chassis pseudowire.
MC-LAG and SRRP
MC-LAG and Subscriber Routed Redundancy Protocol (SRRP) enable dual-homed links from any IEEE 802.1ax (formerly 802.3ad) standards-based access device (for example, a IP DSLAM, Ethernet switch or a Video on Demand server) to multiple Layer 2/3 or Layer 3 aggregation nodes. In contrast with slow recovery mechanisms such as Spanning Tree, multi-chassis LAG provides synchronized and stateful redundancy for VPN services or triple play subscribers in the event of the access link or aggregation node failing, with zero impact to end users and their services.
See the 7450 ESS, 7750 SR, and VSR Triple Play Service Delivery Architecture Guide for information about SRRP.
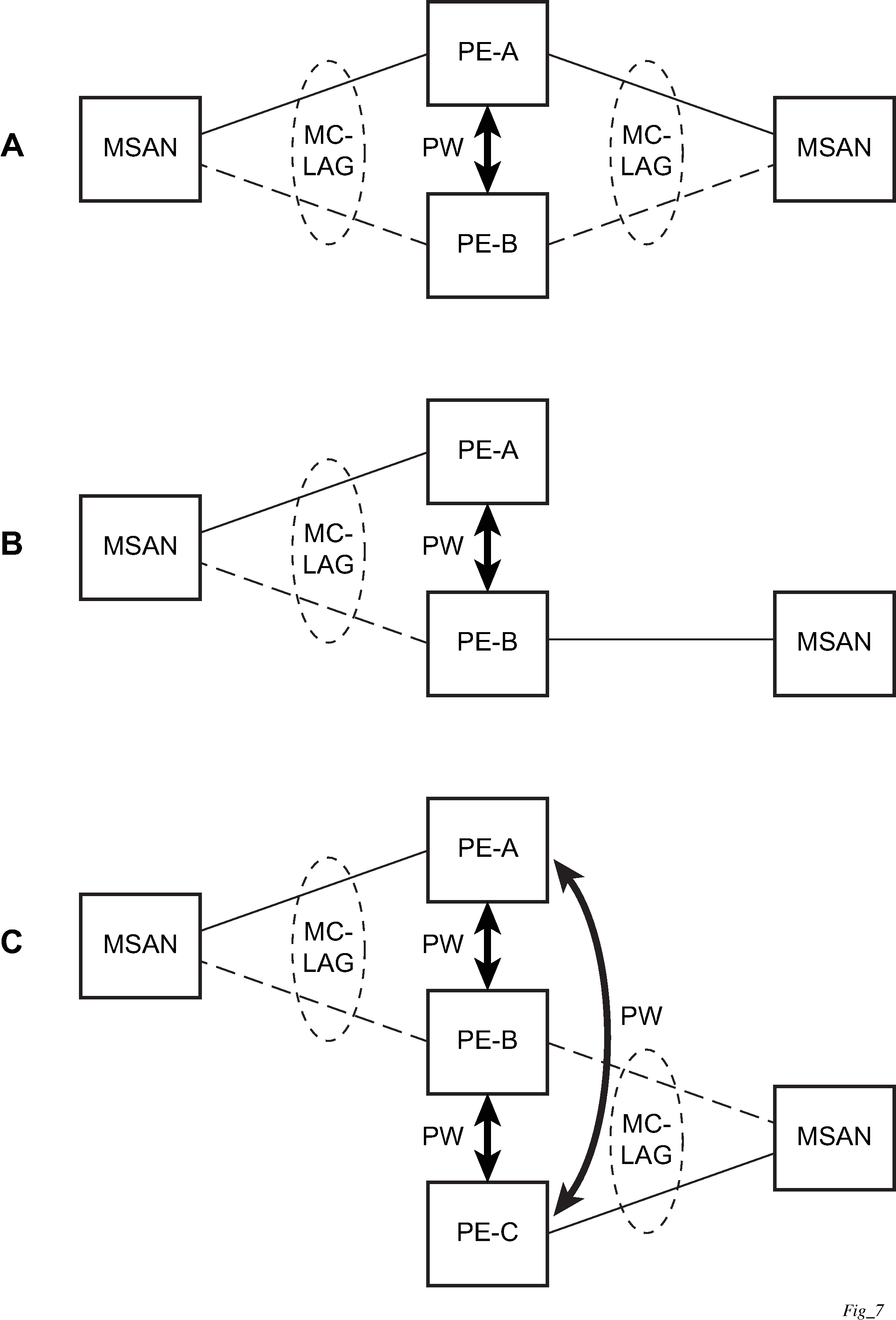
P2P redundant connection across Layer 2/3 VPN network
Point-to-Point (P2P) redundant connection through a Layer 2 VPN network shows the connection between two multi-service access nodes (MSANs) across a network based on Layer 2/3 VPN pseudowires. The connection between MSAN and a pair of PE routers is realized by MC-LAG. From an MSAN perspective, a redundant pair of PE routers acts as a single partner in LACP negotiation. At any time, only one of the routers has an active link in a specified LAG. The status of LAG links is reflected in status signaling of pseudowires set between all participating PEs. The combination of active and stand-by states across LAG links as well as pseudowires gives only one unique path between a pair of MSANs.
Note that the configuration in Point-to-Point (P2P) redundant connection through a Layer 2 VPN network shows one particular configuration of VLL connections based on MC-LAG, particularly the VLL connection where two ends (SAPs) are on two different redundant-pairs. In addition to this, other configurations are possible, such as:
Both ends of the same VLL connections are local to the same redundant-pair.
One end VLL endpoint is on a redundant-pair the other on single (local or remote) node.
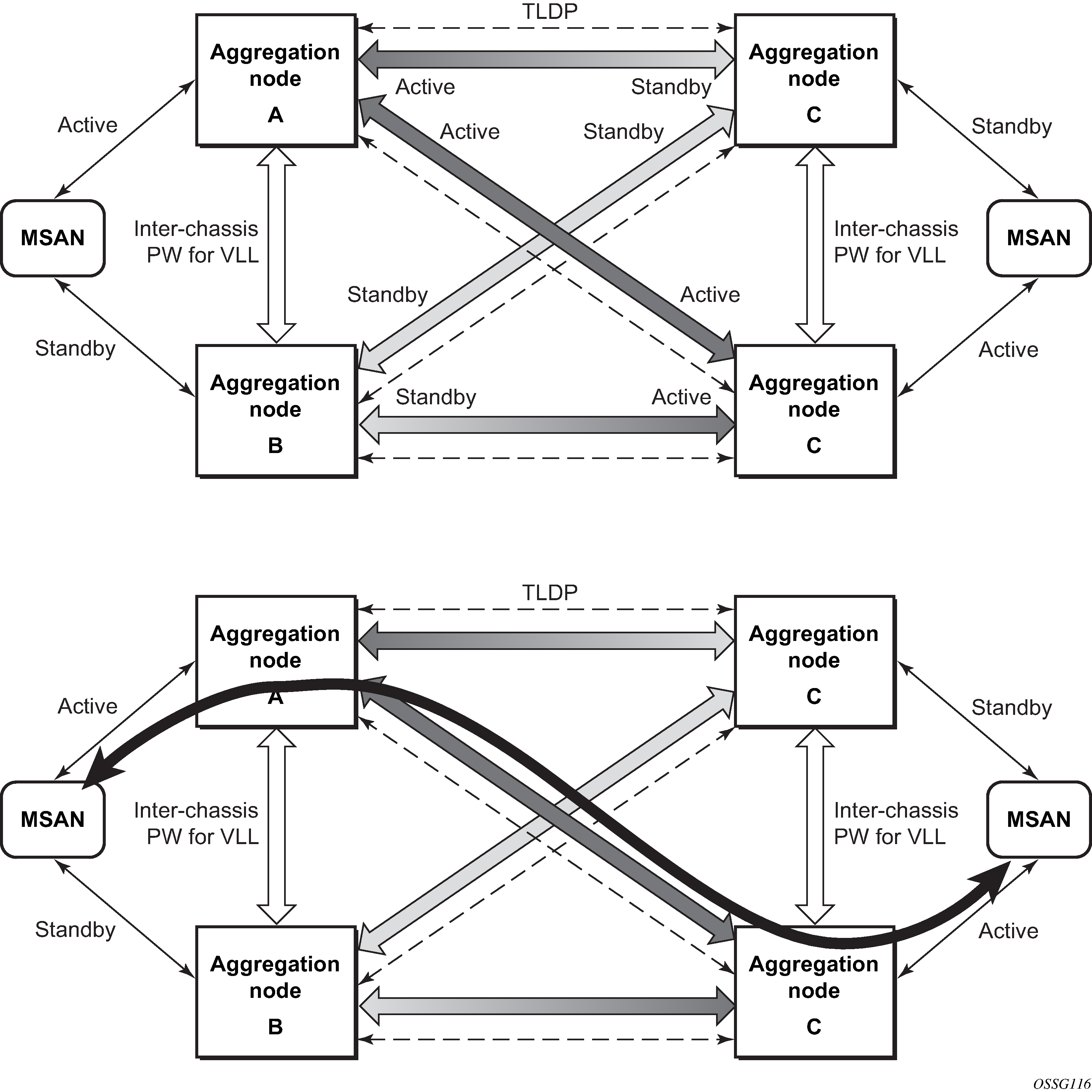
DSLAM dual homing in Layer 2/3 TPSDA model
DSLAM dual-homing using MC-LAG shows a network configuration where DSLAM is dual homed to pair of redundant PEs by using MC-LAG. Inside the aggregation network redundant-pair of PEs is connecting to VPLS service which provides reliable connection to single or pair of Broadband Service Routers (BSRs).
MC-LAG and pseudowire connectivity, PE-A and PE-B implement enhanced subscriber management features based on DHCP-snooping and creating dynamic states for every subscriber-host. As in any point of time there is only one PE active, it is necessary to provide the mechanism for synchronizing subscriber-host state-information between active PE (where the state is learned) and stand-by PE. In addition, VPLS core must be aware of active PE to forward all subscriber traffic to a PE with an active LAG link. The mechanism for this synchronization is outside of the scope of this document.
LAG IGP cost
When using a LAG, it is possible to take an operational link degradation into consideration by setting a configurable degradation threshold. The following alternative settings are available through configuration:
configure lag port-threshold
configure lag hash-weight-thresholdWhen the LAG operates under normal circumstances and is included in an IS-IS or OSPF routing instance, the LAG must be associated with an IGP link cost. This LAG cost can either be statically configured in the IGP context or set dynamically by the LAG based upon the combination of the interface speed and reference bandwidth.
Under operational LAG degradation however, it is possible for the LAG to set a new updated dynamic or static threshold cost taking the gravity of the degradation into consideration.
As a consequence, there are some IGP link cost alternatives available, for which the most appropriate must be selected. The IGP uses the following priority rules to select the most appropriate IGP link cost:
-
Static LAG cost (from the LAG threshold action during degradation)
-
Explicit configured IGP cost (from the configuration under the IGP routing protocol context)
-
Dynamic link cost (from the LAG threshold action during degradation)
-
Default metric (no cost is set anywhere)
For example:
-
Static LAG cost overrules the configured metric.
-
Dynamic cost does not overrule configured metric or static LAG cost.