Network-instances
On the SR Linux device, you can configure one or more virtual routing instances, known as ‟network-instances”. Each network-instance has its own interfaces, its own protocol instances, its own route table, and its own FIB.
When a packet arrives on a subinterface associated with a network-instance, it is forwarded according to the FIB of that network-instance. Transit packets are typically forwarded out another subinterface of the network-instance.
The SR Linux supports three types of network-instances: default, ip-vrf, and mac-vrf. Type default is the default network-instance and only one of this type is supported. Type ip-vrf is the regular network-instance; you can create multiple network-instances of this type.
Type mac-vrf functions as a broadcast domain and is associated with an ip-vrf network-instance via an Integrated Routing and Bridging (IRB) to support tunneling of Layer 2 traffic across an IP network. See The mac-vrf network-instance.
Initially, the SR Linux has a default network-instance and no ip-vrf or mac-vrf network-instances.
A management network-instance, which isolates management network traffic from other
network-instances configured on the device, is created by default, with the
mgmt0 port automatically added to it. See Configuring the management network-instance and the SR Linux
Interfaces Guide.
Basic network-instance configuration
The following example creates network-instance ‟black” and associates two network subinterfaces and one loopback subinterface with it.
The configuration administratively enables the network-instance, specifies a description, and assigns it a router ID. The router ID is optional and is used as a default router identifier for protocols running within the network-instance.
The network-instance is configured to export routes and neighbors to the Linux routing table.
--{ candidate shared default }--[ ]--
# info network-instance black
network-instance black {
type ip-vrf
admin-state enable
description "Sample network instance"
router-id 192.168.2.1
ip-forwarding {
receive-ipv4-check true
}
interface ethernet-1/1.1 {
}
interface ethernet-1/2.1 {
}
interface lo0.1 {
}
protocols {
linux {
export-routes true
export-neighbors true
}
}
}In the preceding example, the receive-ipv4-check parameter is set to true; if an IPv4 packet is received on a subinterface of this network-instance, and the IPv4 operational status of the subinterface is down, then the packet is discarded. When the receive-ipv4-check parameter is set to false, IPv4 packets are received on all subinterfaces of this network-instance that are up, even if they do not have IPv4 addresses.
Path MTU discovery
Path MTU discovery is the technique for determining the MTU size on the network path between hosts. On the SR Linux, path MTU discovery is enabled by default for all network-instances and can be manually enabled or disabled per network-instance.
If path MTU discovery is disabled, the system drops the MTU for the session to the number of bytes specified by the system-level min-path-mtu parameter when an ICMP fragmentation-needed message is received; by default, the min-path-mtu setting is 552 bytes.
--{ * candidate shared default }--[ ]--
# info network-instance default
network-instance default {
mtu {
path-mtu-discovery true
}
} --{ * candidate shared default }--[ ]--
# info system mtu
system {
mtu {
min-path-mtu 552
}
}
Static routes
Within a network-instance, you can configure static routes. Each static route is associated with an IPv4 prefix or an IPv6 prefix, which represents the packet destinations matched by the static route. Each static route belongs to a specific network-instance. Different network-instances can have overlapping routes (static or otherwise) because each network-instance installs its own routes into its own set of route tables and FIBs.
Each static route must be associated with a statically configured next-hop group, which determines how matching packets are handled: either perform a blackhole discard action or a forwarding action. The next-hop group can specify a list of one or more nexthops (up to 128). SR Linux supports the following types of next-hops in a next-hop group:
-
Regular IP-numbered next-hops
Matching IP packets are forwarded, without encapsulation, towards the next-hop, with one or more resolution steps deciding the outbound interface and MAC address to use for forwarding. If the resolve flag is set to false, only a direct route can be used to resolve the IPv4 or IPv6 next-hop address; if the resolve flag is set to true, any route in the FIB can be used to resolve the IPv4 or IPv6 next-hop address.
-
MPLS next-hops (7250 IXR-6/10/6e/10e systems only)
Matching IP packets are forwarded, with an added MPLS label stack, towards the next-hop, with one resolution step deciding the outbound interface and MAC address to use for forwarding. The resolve flag must be set to false, because only a direct route can be used to resolve the IPv4 or IPv6 next-hop address.
-
GRE tunnel next-hops (7250 IXR-6/10/6e/10e systems only)
Matching IP packets are forwarded, with added IP/GRE encapsulation, towards a remote GRE tunnel endpoint. A GRE tunnel next-hop can be configured with an IPv4 or IPv6 address of the remote GRE tunnel endpoint; this is the destination address in the outer IP header of the IP/GRE packet.
A next-hop group can have up to 128 GRE tunnel next-hops; more than one next-hop implies ECMP. An ECMP hash calculation using header fields of the payload packet (before IP/GRE encapsulation) selects one of these next-hops and in so doing, selects an outer IP destination for the GRE encapsulation.
A GRE tunnel next-hop is resolved if the destination address is reachable (using any route type) in the route table. If a GRE tunnel endpoint is unresolved, it is removed from the next-hop-group ECMP set. If a next-hop group has no resolved GRE tunnel next-hops, it is not usable and all referencing static routes are removed from the route table and FIB.
Each static route has a specified metric and preference. The metric is the IGP cost to reach the destination. The preference specifies the relative degree this static route is preferred compared to other static and non-static routes available for the same IP prefix in the same network-instance.
A static route is installed in the FIB for the network-instance if the following conditions are met:
-
The route has the lowest preference value among all routes (static and non-static) for the IP prefix.
-
The route has the lowest metric value among all static routes for the IP prefix.
If BGP is running in a network-instance, all static routes of that same network-instance are automatically imported into the BGP local RIB so that they can be redistributed as BGP routes, subject to BGP export policies.
You can use Bidirectional Forwarding Detection (BFD) to monitor reachability between the router and the configured next hops for a static route, making BFD sessions between the local router and the defined next hops a condition for an associated static route and next hops to be operationally active. See Configuring failure detection for static routes.
Configuring static routes
To configure static routes, you specify route prefixes to point to next-hop groups, along with the metric and preference.
Configure IPv4 and IPv6 static routes
The following example configures IPv4 and IPv6 static route prefixes to point to next-hop groups and specifies a preference and metric for each one:
--{ * candidate shared default }--[ network-instance black ]--
# info static-routes
static-routes {
route 192.168.18.0/24 {
admin-state enable
metric 1
preference 5
next-hop-group static-ipv4-grp
}
route 2001:1::192:168:18:0/64 {
admin-state enable
metric 1
preference 6
next-hop-group static-ipv6-grp
}
}
Configure IP-numbered next-hop groups
The following example configures the next-hop groups for the static routes:
--{ * candidate shared default }--[ network-instance black ]--
# info next-hop-groups
next-hop-groups {
group static-ipv4-grp {
admin-state enable
nexthop 1 {
ip-address 192.0.2.22
}
nexthop 2 {
ip-address 192.0.2.45
resolve true
}
}
group static-ipv6-grp {
admin-state enable
blackhole {
}
}
}
}
In this example, an IPv4 next-hop group is configured with two next-hops. The resolve
true setting allows any route in the FIB to be used to resolve the IPv4
next-hop address, provided the resolution depth is not more than 2.
The IPv6 next-hop group is configured to perform a blackhole discard action for matching packets.
Configure a MPLS next-hop group
The following example specifies a MPLS next-hop for nhop_group_1. Only one MPLS next-hop is supported per next-hop group. In this example, the label for outgoing traffic to MPLS next-hop 192.35.1.5 is swapped to 1001.
--{ * candidate shared default }--[ ]--
# info network-instance default next-hop-groups group nhop_group_1
network-instance default {
next-hop-groups {
group nhop_group_1 {
nexthop 0 {
ip-address 192.35.1.5
resolve false
pushed-mpls-label-stack [
1001
]
}
}
}
}GRE tunnel next-hop group
The following example specifies a GRE tunnel next-hop group. Packets are forwarded,
with added IP/GRE encapsulation, towards a remote GRE tunnel endpoint specified by
the destination-ip.
--{ * candidate shared default }--[ ]--
# info network-instance default next-hop-groups group NHG1
network-instance default {
next-hop-groups {
group NHG1 {
nexthop 1 {
encapsulate-header gre
gre {
destination-ip 20.20.20.1
}
}
nexthop 2 {
encapsulate-header gre
gre {
destination-ip 20.20.20.2
}
}
nexthop 3 {
encapsulate-header gre
gre {
destination-ip 20.20.20.3
}
}
}
}
}You can optionally specify the source-ip for a next-hop in a GRE
next-hop group. If the source-ip is not specified, the
lowest-numbered loopback address of the associated network-instance is used.
Configure a link-local address in an IPv6 next-hop group
IPv6 next-hop addresses in a static next-hop group can be global unicast IPv6 addresses or IPv6 link local addresses. If you configure an IPv6 LLA, you specify it with a zone, as a string in the following format:
<link-local-ipv6-address>%<subinterface-name>
where <subinterface-name> has the format
<interface-name>.<subinterface-index> and corresponds to a configured
interface.subinterface object in the interface
configuration hierarchy on the SR Linux device.
The following example configures an IPv6 LLA for a subinterface and specifies it as a next-hop in a next-hop group.
--{ * candidate shared default }--[ ]--
# info interface ethernet-1/10 subinterface 1 ipv6
interface ethernet-1/10 {
subinterface 1 {
ipv6 {
admin-state enable
address fe80::24:1/64 {
type link-local-unicast
}
}
}
}--{ * candidate shared default }--[ ]--
# info network-instance default next-hop-groups group ecmp nexthop 1
network-instance default {
next-hop-groups {
group g1 {
nexthop 1 {
ip-address fe80::25:1:2%ethernet-1/10.1
resolve false
failure-detection {
enable-bfd {
local-address fe80::25:1:1
}
}
}
}
}
}Associate a static route with a tag-set
You can associate a static route with a tag-set, which is defined under routing-policy. The following example defines a tag-set, then associates it with a static route.
--{ * candidate shared default }--[ ]--
# info routing-policy
routing-policy {
tag-set ts1 {
tag-value [
2
4
]
}
}--{ * candidate shared default }--[ ]--
# info network-instance default static-routes
network-instance default {
static-routes {
route 1.1.1.1/32 {
tag-set ts1
}
}
}Configuring failure detection for static routes
You can use BFD as a failure detection mechanism for monitoring the reachability of next hops for static routes. When BFD is enabled for a static route, it makes an active BFD session between the local router and the defined next hops required as a condition for a static route to be operationally active.
You enable BFD for specific next-hop groups; as a result, BFD is enabled for any static route that refers to the next-hop group. If multiple next hops are defined within the next-hop group, a BFD session is established between the local address and each next hop in the next-hop group.
A static route is considered operationally up if at least one of the configured next-hop addresses can establish a BFD session. If the BFD session fails, the associated next hop is removed from the FIB as an active next hop.
The following example enables BFD for a static route next hop:
--{ * candidate shared default }--[ network-instance black ]--
# info next-hop-groups
next-hop-groups {
group static-ipv4-grp {
admin-state enable
nexthop 1 {
failure-detection {
enable-bfd {
local-address 192.0.2.1
}
}
}
}
}
A BFD session is established between the address configured with the local-address parameter and each next-hop address before that next-hop address is installed in the forwarding table.
All next-hop BFD sessions share the same timer settings, which are taken from the BFD configuration for the subinterface where the address in local-address parameter is configured. See "Bidirectional Forwarding Detection" in the SR Linux OAM and Diagnostics Guide.
Aggregate routes
You can specify aggregate routes for a network-instance. Each aggregate route is associated with an IPv4 prefix or an IPv6 prefix, which represents the packet destinations matched by the aggregate route. As with static routes, each aggregate route belongs to a specific network-instance, though different network-instances can have overlapping routes because each network-instance installs its own routes into its own set of route tables and FIBs.
An aggregate route can become active when it has one or more contributing routes. A route contributes to an aggregate route if all of the following conditions are met:
The prefix length of the contributing route is greater than the prefix length of the aggregate route.
The prefix bits of the contributing route match the prefix bits of the aggregate route up to the prefix length of the aggregate route.
There is no other aggregate route that has a longer prefix length that meets the previous two conditions.
The contributing route is actively used for forwarding and is not an aggregate route itself.
That is, a route can only contribute to a single aggregate route, and that aggregate route cannot recursively contribute to a less-specific aggregate route.
Aggregate routes have a fixed preference value of 130. If there is no route to the aggregate route prefix with a numerically lower preference value, then the aggregate route, when activated by a contributing route, is installed into the FIB with a blackhole next hop. It is not possible to install an aggregate route into the route-table or as a BGP route without also installing it in the FIB.
The aggregate routes are commonly advertised by BGP or another routing protocol so that the individual contributing routes no longer need to be advertised.
This process can speed up routing convergence and reduce RIB and FIB sizes throughout the network. If BGP is running in a network-instance, all active aggregate routes of that network-instance are automatically imported into the BGP local RIB so they can be redistributed as BGP routes, subject to BGP export policies.
Configuring aggregate routes
To specify an aggregate route, you configure the aggregator address setting, which identifies the aggregating router. By default, this is the configured router ID of the BGP instance, or 0 if BGP is not enabled.
--{ * candidate shared default }--[ network-instance black ]--
# info aggregate-routes
aggregate-routes {
route 192.0.2.0/24 {
aggregator {
address 192.168.0.1
}
summary-only true
generate-icmp true
}
}
When the summary-only parameter is set to true, activation of an aggregate route automatically blocks the advertisement of all of its contributing routes by BGP.
The generate-icmp true setting causes the router to generate ICMP unreachable messages for the dropped packets.
Route preferences
A route can be learned by the router from different protocols, in which case, the costs are not comparable. When a route is learned from different protocols, the preference value is used to decide which route is installed in the forwarding table if several protocols calculate routes to the same destination. The route with the lowest preference value is selected.
Different protocols must not be configured with the same preference. If protocols are configured with the same preference, the tiebreaker is per the default preference table as defined in Route preference defaults by route type. If multiple routes are learned with an identical preference using the same protocol, the lowest cost route is used.
Route Type |
Preference |
Configurable |
|---|---|---|
|
Direct attached |
0 |
No |
|
Static routes |
5 |
Yes |
|
OSPF internal |
10 |
Yes1 |
|
IS-IS level 1 internal |
15 |
Yes |
|
IS-IS level 2 internal |
18 |
Yes |
|
OSPF external |
150 |
Yes |
|
IS-IS level 1 external |
160 |
Yes |
|
IS-IS level 2 external |
165 |
Yes |
|
BGP |
170 |
Yes |
|
Aggregate routes |
130 |
No |
-
Preference for OSPF internal routes is configured with the preference command.
IP tunnel decapsulation groups
Within the default network-instance, you can configure IP tunnel decapsulation groups. In an IP tunnel decapsulation group, you specify a termination-subnet and an allowed-payload type. An IP/GRE packet received on any routed subinterface of the default network instance that matches the termination-subnet is decapsulated. If the inner header of the decapsulated packet indicates the packet is an allowed-payload type, it is forwarded according to the packet's inner header. If the decapsulated packet is not an allowed-payload type, it is dropped and not forwarded further.
A received IP/GRE packet that does not match the termination subnet in an IP tunnel decapsulation group is forwarded based on IP route lookup. If the longest matching route is a host route, then the packet is dropped unless it is explicitly allowed by a non-default CPM-filter policy.
- IP tunnel decapsulation groups are supported only on the default network instance.
- The termination-subnet lookup for a IP/GRE packet is done before IP longest prefix match lookup, so decapsulation occurs for a packet matching the termination-subnet even if the packet's outer IP address matches a local interface IP address or IP route in the FIB.
- Decapsulation occurs regardless of whether the GRE header specifies version 0 or 1.
- Decapsulation does not occur if the GRE version 0 header includes a key or sequence number. In this case, the packet is forwarded based on IP route lookup on the outer IP DA. If the longest matching route is a host route, the packet is dropped unless it is explicitly allowed by a non-default CPM-filter policy.
Configuring an IP tunnel decapsulation group
To configure an IP tunnel decapsulation group, specify a termination-subnet and an allowed-payload type.
The following example configures an IP tunnel decapsulation group in the default network instance. The termination-subnet is 192.168.1.0/24, and the allowed-payload type is MPLS. IP/GRE packets that match this subnet are decapsulated. If the payload of the decapsulated packet is MPLS, it is forwarded based on its inner header; otherwise, the decapsulated packet is dropped.
--{ * candidate shared default }--[ ]--
# info network-instance default ip-tunnel-decapsulation
network-instance default {
ip-tunnel-decapsulation {
group dcgrp1 {
allowed-payloads [
mpls
]
termination-subnet 192.168.1.0/24 {
}
}
}
}Displaying network-instance status
Use the show network-instance command to display status information about network-instances configured on the device.
Display information about all network-instances
To display information about all configured network-instances, including the router ID, description, administrative, and operational state:
--{ show }--
# show network-instance summary
+---------+---------+--------+-------+------------+--------------------------------+
| Name | Type | Admin | Oper | Router id | Description |
| | | state | state | | |
+=========+=========+========+=======+============+================================+
| default | default | enable | up | 5.5.5.5 | Sample network instance |
| mgmt | ip-vrf | enable | up | | Management network instance |
| red | ip-vrf | enable | up |55.55.55.55 | Network instance for bgp tests |
+---------+---------+--------+-------+------------+--------------------------------+
Display information about one network-instance
To limit the display to a single network-instance:
--{ show }--
# show network-instance default summary
+---------+---------+--------+-------+---------+----------------------------+
| Name | Type | Admin | Oper | Router | Description |
| | | state | state | id | |
+=========+=========+========+=======+=========+============================+
| default | default | enable | up | 5.5.5.5 | "Sample network instance" |
+---------+---------+--------+-------+---------+----------------------------+
Display information about attached interfaces
To display information about the interfaces attached to a network-instance:
--{ show }--
# show network-instance default interfaces
===================================================================
Net instance : default
Interface : ethernet-1/1.1
Oper state : up
Ip mtu : 1500
Prefix Origin Status
=================================================================
192.35.1.0/31 static
2001:192:35:1::/127 static preferred
fe80::201:5ff:feff:0/64 link-layer preferred
===================================================================
Net instance : default
Interface : lo0.1
Oper state : up
Prefix Origin Status
=================================================================
5.5.5.5/32 static
2001:5:5:5::5/128 static preferred
===================================================================
The command displays the operational state, IP MTU, and assigned IPv4/IPv6 prefix for
each interface. If the operational state for an interface is down,
the reason for the interface being down is shown.
Display interface information using an interface reference
If you configure an interface reference for an interface (see Configuring interface references) in the network-instance configuration, you can display information about the interface using the interface reference name.
The following example configures network-instance "black" to use the interface reference "red" to refer to interface ethernet-1/10, subinterface 1.
--{ + candidate shared default }--[ ]--
# info network-instance black
network-instance black {
interface red {
interface-ref {
interface ethernet-1/10
subinterface 1
}
}
}
In the context of network instance black, you can use the name red to refer to interface ethernet-1/10, subinterface 1. For example:
--{ + running }--[ network-instance black ]--
# show interfaces red
===========================================================================
Net instance : black
Interface : ethernet-1/10.1 (red)
Type : routed
Oper state : down
Oper down reason: subif-down
Ip mtu : 1500
===========================================================================The mac-vrf network-instance
The network-instance type mac-vrf is associated with a network-instance of type default or ip-vrf via an IRB interface.
The mac-vrf network-instance type functions as a broadcast domain. Each mac-vrf network-instance builds a bridge table composed of MAC addresses that can be learned via the data path on network-instance interfaces or via static configuration. You can configure the size of the bridge table for each mac-vrf network instance, as well as the aging for dynamically learned MAC addresses and other parameters related to the bridge table.
The mac-vrf network-instance type features a mac duplication mechanism that monitors MAC address moves across network-instance interfaces and across interfaces.
MAC selection
Each mac-vrf network-instance builds a bridge table to forward Layer 2 frames based on a MAC address lookup. The SR Linux selects the MAC addresses to be sent for installation to the line card (eXtensible Data Path (XDP)), based on the following priority:
Local application MACs
Local static MACs
EVPN static (MACs coming from a MAC/IP route with the static bit set)
Local duplicate MACs
Learned or EVPN-learned MACs
MAC duplication detection and actions
MAC duplication is the mechanism used by SR Linux for loop prevention. MAC duplication monitors MAC addresses that move between subinterfaces. It consists of detection, actions, and process restarts.
MAC duplication detection
Detection of duplicate MAC addresses is necessary when extending broadcast domains to multiple leaf nodes. SR Linux supports a MAC duplication mechanism that monitors MAC address moves across network-instance interfaces.
A MAC address is considered a duplicate when its number of detected moves is greater than a configured threshold within a configured time frame where the moves are observed. When exceeding the threshold, the system holds on to the prior local destination of the MAC and executes an action.
MAC duplication actions
The action taken when detecting one or more MAC addresses as duplicate on a subinterface can be configured for the mac-vrf network instance or for the subinterface. The following are the configurable actions:
oper-down
When one or more duplicate MAC addresses are detected on the subinterface, the subinterface is brought operationally down.
blackhole
On detection of a duplicate mac on the subinterface, the mac is blackholed.
stop-learning
On detection of a duplicate mac on the subinterface, the MAC address is no longer relearned on this or any subinterface. This is the default action for a mac-vrf network instance.
use-net-instance-action
(Only available for subinterfaces) Use the action specified for the mac-vrf network instance. This is the default action for a subinterface.
MAC duplication process restarts
When at least one duplicate MAC address is detected, the duplicate MAC addresses are visible in the state datastore and can be displayed with the info from state network-instance bridge-table mac-duplication duplicate-entries CLI command.
Configurable hold-down-time
The info from state network-instance bridge-table mac-duplication duplicate-entries command also displays the hold-down-time for each duplicate MAC address. When the hold-down-time expires for all of the duplicate MAC addresses for the subinterface, the oper-down or stop-learning action is cleared, and the subinterface is brought operationally up or starts learning again.
The hold-down-time is configurable from between 2 and 60 minutes. You can optionally specify indefinite for the hold-down-time, which prevents the oper-down or stop-learning action from being cleared after a duplicate MAC address is detected; in this case, you can manually clear the oper-down or stop-learning action by changing the mac-duplication configuration or using the tools network-instance bridge-table mac-duplication command.
Bridge table configuration
The bridge table, its MAC address limit, and maximum number of entries can be configured on a per mac-vrf or per-subinterface basis.
When the size of the bridge table exceeds its maximum number of entries, the MAC addresses are removed in reverse order of the priority listed in MAC selection.
You can also configure aging for dynamically learned MAC addresses and other parameters related to the bridge table.
Deleting entries from the bridge table
The SR Linux features commands to delete duplicate or learned MAC entries from the bridge table. For a mac-vrf or subinterface, you can delete all MAC entries, MAC entries with a blackhole destination, or a specific MAC entry.
Clear MAC entries with a blackhole destination
The following example clears MAC entries in the bridge table for a mac-vrf network instance that have a blackhole destination:
--{ candidate shared default }--[ ]--
# tools network-instance mac-vrf-1 bridge-table mac-duplication delete-macs-type blackhole-onlyClear a specified MAC entry
The following example deletes a specified learned MAC address from the bridge table for a mac-vrf network instance:
--{ candidate shared default }--[ ]--
# tools network-instance mac-vrf-1 bridge-table mac-learning learnt-entries mac 00:00:5e:00:53:01 delete-macClear duplicate MAC entries for a subinterface
The following example clears all duplicate MAC entries in the bridge table for a subinterface:
--{ candidate shared default }--[ ]--
# tools interface ethernet-1/1.1 bridge-table mac-duplication delete-all-macs
The mac-vrf network-instance type
The following example configures a mac-vrf network instance and settings for the bridge table. The bridge table is set to a maximum of 500 entries. Learned MAC addresses are aged out of the bridge table after 600 seconds.
MAC duplication detection is configured so that a MAC address is considered a duplicate when its number of detected moves across network instance interfaces is greater than three over a 5-minute interval. In this example, the MAC address is blackholed. After the hold-down-time of 3 minutes, the MAC address is flushed from the bridge table, and the monitoring process for the MAC address is restarted.
The example includes configuration for a static MAC address in the bridge table.
The mac-vrf network-instance type is associated with a bridged interface and an IRB interface.
--{ candidate shared default }--[ ]--
# info network-instance mac-vrf-1
network-instance mac-vrf-1 {
description "Sample mac-vrf network instance"
type mac-vrf
admin-state enable
interface ethernet-1/1.1 {
interface-ref {
interface ethernet-1/1
subinterface 1
}
}
interface irb1.1 {
interface-ref {
interface irb1
subinterface 1
}
}
bridge-table {
mac-limit {
maximum-entries 500
}
mac-learning {
admin-state enable
aging {
admin-state enable
age-time 600
}
}
mac-duplication {
admin-state enable
monitoring-window 5
num-moves 3
hold-down-time 3
action blackhole
static-mac {
address [mac1
}
}
}
}
Network-instance route leaking
SR Linux supports route leaking from one network-instance to another. An active/best IP route from an origin network-instance can be leaked into any number of destination network-instances.
The routes are leaked from an origin network-instance to destination network-instances based on import and export policies. The policies specify which routes are leaked from the origin network-instance to destination network-instances, as well as which routes can be accepted by a network-instance from other network instances. Import policy matching can be based on prefix, family, and protocol. The leaked routes are published with full forwarding information (next hop).
Network-instance route leaking is typically used to allow leafs attached to multiple tenants to share services (for example, DNS or NTP servers, common software repositories) and support leafs that provide hub functionality to spoke leafs. Network-instance route leaking shows an example configuration.
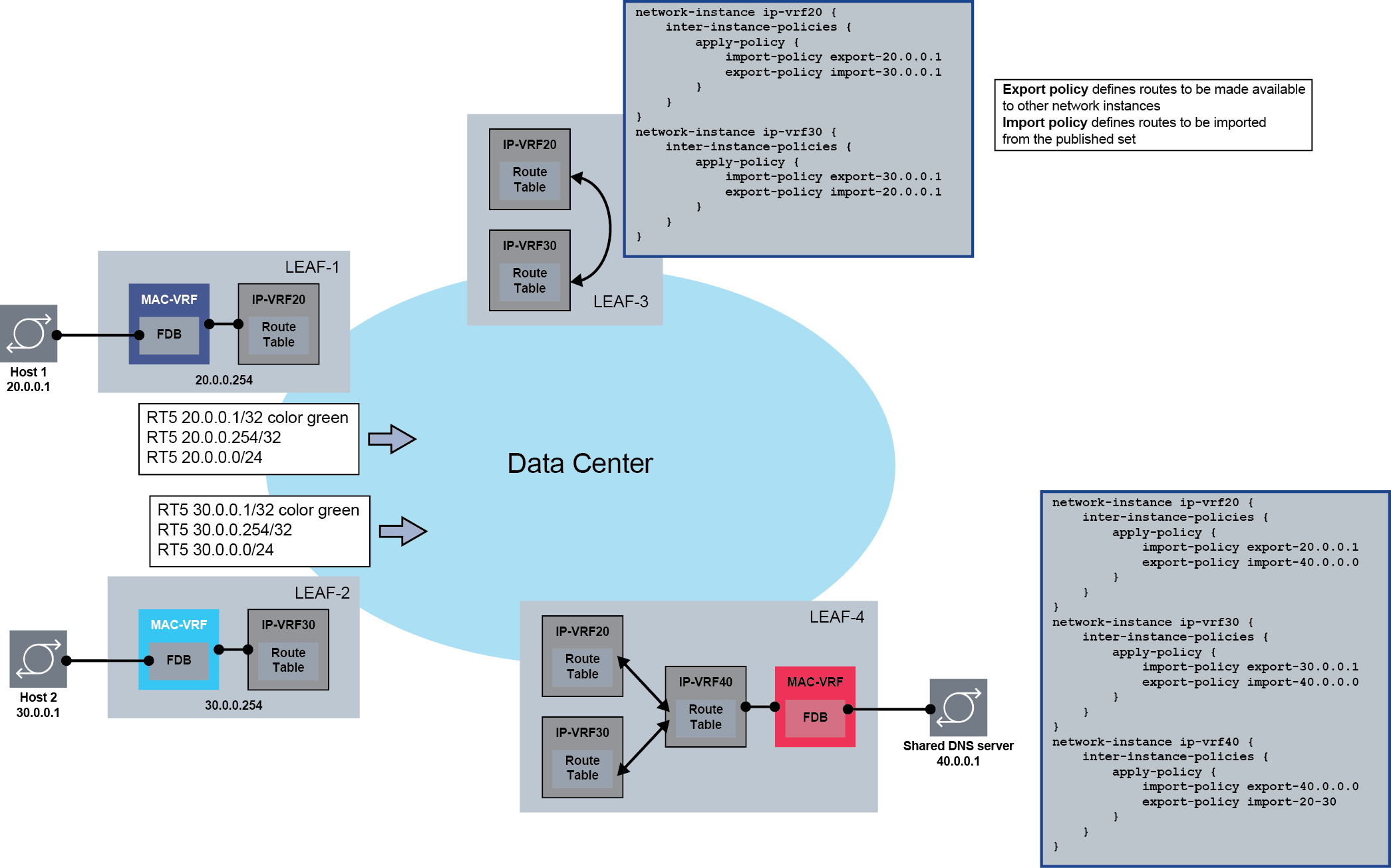
In this example, Leaf-4 has two customer IP-VRF network-instances: IP-VRF20 and IP-VRF30. Network-instance IP-VRF40 is used to connect the shared DNS server with IP address 40.0.0.1. An inter-instance export policy makes the shared DNS server leakable, and an inter-instance import policy imports 40.0.0.0 into IP-VRF20 and IP-VRF30. At this point, the prefix 40.0.0.0/24 can be advertised via EVPN and imported into Leaf-1 and Leaf-2, so that Host 1 and Host 2 have reachability to the DNS server. In the reverse direction, for traffic from the hosts to the DNS server, inter-instance import and export policies are configured so that the IP-VRF20 and IP-VRF30 prefixes are imported into IP-VRF40.
The hub-and-spoke functionality is shown on Leaf-3, where prefixes of IP-VRF20 and IP-VRF30 are leaked between each other, allowing connectivity between Host 1 and Host 2.
Configuration considerations for originating and terminating traffic
This feature does not prevent leaking of host routes. However, packets matching a local host route leaked from another network-instance are dropped by XDP CPM. For example, if a router is leaking a local loopback address from IP-VRF-A into IP-VRF-B, an ICMP request packet from IP-VRF-B with a destination of the loopback address in IP-VRF-A is discarded.
Packets matching a non-local host address belonging to a local subnet leaked from another network-instance are dropped. For example, if a router is leaking local subnet 10.10.10.0/24 on subinterface-1 from IP-VRF-A into IP-VRF-B and 10.10.10.10 is a server connected to subinterface-1 in IP-VRF-A, an ICMP request packet coming from IP-VRF-B with destination 10.10.10.10 is discarded. As a workaround, subinterface-1 can be configured with host-route populate dynamic datapath-programming true so that 10.10.10.10 creates and programs an ARP/ND host route in IP-VRF-A. If the ARP/ND host route is leaked into IP-VRF-B, traffic to 10.10.10.10 is forwarded from IP-VRF-B to IP-VRF-A.
Another workaround is to configure a static-route for 10.10.10.10 with next hop 10.10.10.10, and leak it into IP-VRF-B. Overall, any route that creates an entry in the host table for IP-VRF-B provides a way to forward packets to a local subnet.
XDP CPM uses (and does not ignore) leaked routes when forwarding originated control/management traffic. If a leaked route is the best route to the destination, then traffic egresses via a subinterface of the origin-network-instance.
On 7220 IXR-D1/D2/D3 and 7220 IXR-D4/D5 switches, VXLAN traffic received in a non-default VRF is not terminated, even if the destination IP address matches a leaked host route from the default network-instance.
If the next hop of any non-leaked route can only be resolved by a leaked route, the non-leaked route is considered unresolved. For example, if the BGP next hop of an EVPN-VXLAN route received by the default network-instance can only be resolved by a leaked route from another network-instance, the BGP route is considered unresolved. This process ensures VXLAN traffic is not originated from a non-default VRF.
In the current release, no leaked route is advertised in a routing protocol. The only exception to this rule is leaked local routes and their advertisement into BGP (ipv4/ipv6/evpn-ifl families).
Network-instance route leaking configuration example
Network-instance route leaking example shows a configuration for a hosting provider that uses route leaking on EVPN-VXLAN leaf switches.
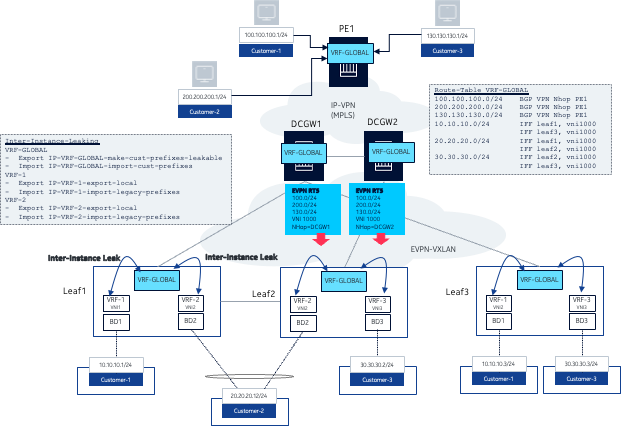
The data center network in this example uses SR Linux leaf switches and 7750 SR devices as data center (DC) gateways. Each customer is assigned an IP-VRF and a MAC-VRF on the leaf where their server is connected. For example, Customer-1 has a server connected to Leaf1 (10.10.10.1) and another server connected to Leaf3 (10.10.10.3). Both servers are attached to a bridged subinterface (no VLAN tagging) that is associated with MAC-VRF BD1. Regular EVPN-VXLAN connectivity happens for each customer with servers attached to multiple leaf switches.
Route leaking is necessary in this example because each customer also requires connectivity to some hosts that are connected to an IP-VPN network in the WAN, and this connectivity is not directly programmed in the IP-VRF of the customer.
The route-leaking example shown in Figure 2: Network-instance route leaking example shows the following:
-
Customer-1, Customer-2, and Customer-3 hosts and prefixes are learned on the IP-VRF VRF-GLOBAL on PE1.
-
PE1 advertises the three prefixes using IP-VPN control plane; DCGW1 and DCGW2 import those prefixes in VRF-GLOBAL as well.
-
In addition to supporting IP-VPN, the VPRN service on the 7750 DCGWs is configured with an EVPN-VXLAN instance that is used to advertise the customer legacy WAN prefixes to the leaf switches, and to import the customer prefixes of all customers attached to the leaf nodes.
-
A network-instance of type IP-VRF called VRF-GLOBAL is also configured on the three leaf switches.
host-route.populate[dynamic] and
host-route.populate[dynamic].datapath-programming true, so that
active hosts create ARP/ND host routes, and they are leaked into VRF-GLOBAL. The
commands create a host in the VRF-GLOBAL host table, and traffic can successfully be
forwarded to the ARP/ND learned hosts in VRF-1. PE1 configuration and route table
In the route leaking example shown in Figure 2: Network-instance route leaking example, PE1 is a 7750 SR WAN PE device attached to VRF-GLOBAL, where the three hosts are connected. The following example shows the configuration and route table for PE1.
// VRF-GLOBAL config on PE1
[ex:/configure service vprn "IP-VRF-GLOBAL"]
A:admin@pe1# info
admin-state enable
service-id 1000
customer "1"
bgp-ipvpn {
mpls {
admin-state enable
route-distinguisher "10.0.0.5:1000"
vrf-target {
community "target:64500:1000"
}
auto-bind-tunnel {
resolution any
}
}
}
interface "local-100" {
ipv4 {
admin-state enable
primary {
address 100.100.100.254
prefix-length 24
}
}
sap 1/1/c1/1:0.* {
}
}
interface "local-200" {
ipv4 {
admin-state enable
primary {
address 200.200.200.254
prefix-length 24
}
}
sap 1/1/c2/1:0.* {
}
}
interface "local-300" {
ipv4 {
admin-state enable
primary {
address 130.130.130.254
prefix-length 24
}
}
sap 1/1/c3/1:3.0 {
}
}
// The IP-VRF-GLOBAL route-table shows the routes 100.100.100.0/24 (customer-1), 200.200.200.0/24 (customer-2) and 130.130.130.0/24 (customer-3)
// PE1 also receives via IPVPN the corresponding prefixes from Leaf-1 so that each customer can have communication to/from the legacy hosts
[ex:/configure service vprn "IP-VRF-GLOBAL"]
A:admin@pe1# /show router "1000" route-table
===============================================================================
Route Table (Service: 1000)
===============================================================================
Dest Prefix[Flags] Type Proto Age Pref
Next Hop[Interface Name] Metric
-------------------------------------------------------------------------------
10.10.10.0/24 Remote BGP VPN 01h20m56s 170
10.0.0.4 (tunneled:SR-ISIS:524290) 10
20.20.20.0/24 Remote BGP VPN 01h18m59s 170
10.0.0.4 (tunneled:SR-ISIS:524290) 10
100.100.100.0/24 Local Local 07h55m03s 0
local-100 0
130.130.130.0/24 Local Local 07h55m03s 0
local-300 0
200.200.200.0/24 Local Local 07h55m03s 0
local-200 0
-------------------------------------------------------------------------------
No. of Routes: 5
Flags: n = Number of times nexthop is repeated
B = BGP backup route available
L = LFA nexthop available
S = Sticky ECMP requested
===============================================================================DCGW1 configuration and route table
DCGW1 is also attached to VRF-GLOBAL and provides a gateway between IP-VPN and EVPN-VXLAN. The following example shows the configuration and route table for DCGW1.
// VRF-GLOBAL config on DCGW1
[ex:/configure service vprn "IP-VRF-GLOBAL"]
A:admin@dcgw1# info
admin-state enable
service-id 1000
customer "1"
bgp-ipvpn {
mpls {
admin-state enable
route-distinguisher "10.0.0.4:1000"
vrf-target {
community "target:64500:1000"
}
auto-bind-tunnel {
resolution any
}
}
}
interface "sdb-1001" {
vpls "sdb-1001" {
evpn-tunnel {
ipv6-gateway-address mac
}
}
ipv6 {
}
}
// DCGW1 learns the legacy prefixes via IPVPN and the leaf prefixes from EVPN IFF (EVPN VXLAN)
A:admin@dcgw1# /show router "1000" route-table
===============================================================================
Route Table (Service: 1000)
===============================================================================
Dest Prefix[Flags] Type Proto Age Pref
Next Hop[Interface Name] Metric
-------------------------------------------------------------------------------
10.10.10.0/24 Remote EVPN-IFF 00h00m13s 169
sdb-1001 (ET-1a:8b:08:ff:00:00) 0
20.20.20.0/24 Remote EVPN-IFF 00h00m13s 169
sdb-1001 (ET-1a:8b:08:ff:00:00) 0
30.30.30.0/24 Remote EVPN-IFF 00h00m13s 169
sdb-1001 (ET-1a:b2:09:ff:00:00) 0
100.100.100.0/24 Remote BGP VPN 00h00m13s 170
10.0.0.5 (tunneled:SR-ISIS:524290) 10
130.130.130.0/24 Remote BGP VPN 00h00m13s 170
10.0.0.5 (tunneled:SR-ISIS:524290) 10
200.200.200.0/24 Remote BGP VPN 00h00m13s 170
10.0.0.5 (tunneled:SR-ISIS:524290) 10
-------------------------------------------------------------------------------
No. of Routes: 6
Flags: n = Number of times nexthop is repeated
B = BGP backup route available
L = LFA nexthop available
S = Sticky ECMP requested
===============================================================================Leaf1 customer VRF configuration
Leaf1 in the route leaking example shown in Figure 2: Network-instance route leaking example is an SR Linux device attached to customer IP-VRFs VRF-1 and VRF-2 and their corresponding MAC-VRFs. The following is a configuration on Leaf1 for the IP-VRFs and MAC-VRFs.
// Relevant config for VRF-1
--{ + candidate shared default }--[ network-instance * ]--
A:leaf1# info
network-instance BD1 {
type mac-vrf
interface ethernet-1/1.1 {
interface-ref {
interface ethernet-1/1
subinterface 1
}
}
interface irb0.1 {
interface-ref {
interface irb0
subinterface 1
}
}
vxlan-interface vxlan1.11 {
}
protocols {
bgp-evpn {
bgp-instance 1 {
admin-state enable
vxlan-interface vxlan1.11
evi 11
ecmp 8
routes {
bridge-table {
mac-ip {
advertise-arp-nd-only-with-mac-table-entry true
}
}
}
}
}
bgp-vpn {
bgp-instance 1 {
route-target {
export-rt target:100:11
import-rt target:100:11
}
}
}
}
}
network-instance IP-VRF-1 {
type ip-vrf
inter-instance-policies {
apply-policy {
import-policy IP-VRF-1-import-cust-1
export-policy IP-VRF-export-local
}
}
interface irb0.1 {
}
interface lo1.11 {
}
vxlan-interface vxlan1.1 {
}
protocols {
bgp-evpn {
bgp-instance 1 {
admin-state enable
vxlan-interface vxlan1.1
evi 1
ecmp 8
}
}
bgp-vpn {
bgp-instance 1 {
route-target {
export-rt target:100:1
import-rt target:100:1
}
}
}
}
}
// ARP/ND - host-route datapath-programming under subinterface
--{ + candidate shared default }--[ interface ethernet-1/3 subinterface 1 ]--
A:Dut-B# info
admin-state enable
ipv4 {
admin-state enable
address 2.3.0.1/30 {
}
arp {
host-route {
populate dynamic {
datapath-programming true
}
}
}
}
ipv6 {
admin-state enable
address 3ffe:2:3::1/124 {
}
neighbor-discovery {
host-route {
populate dynamic {
datapath-programming true
}
}
}
}
// Relevant config for VRF-2
--{ + candidate shared default }--[ network-instance * ]--
A:leaf1# info
network-instance BD2 {
type mac-vrf
interface irb0.2 {
}
interface lag1.1 {
}
vxlan-interface vxlan1.22 {
}
protocols {
bgp-evpn {
bgp-instance 1 {
admin-state enable
vxlan-interface vxlan1.22
evi 22
ecmp 8
routes {
bridge-table {
mac-ip {
advertise-arp-nd-only-with-mac-table-entry true
}
}
}
}
}
bgp-vpn {
bgp-instance 1 {
route-target {
export-rt target:100:22
import-rt target:100:22
}
}
}
}
}
network-instance IP-VRF-2 {
type ip-vrf
inter-instance-policies {
apply-policy {
import-policy IP-VRF-2-import-cust-2
export-policy IP-VRF-export-local
}
}
interface irb0.2 {
}
interface lo1.12 {
}
vxlan-interface vxlan1.2 {
}
protocols {
bgp-evpn {
bgp-instance 1 {
admin-state enable
vxlan-interface vxlan1.2
evi 2
ecmp 8
}
}
bgp-vpn {
bgp-instance 1 {
route-target {
export-rt target:100:2
import-rt target:100:2
}
}
}
}
}Leaf1 VRF-GLOBAL configuration
SR Linux Leaf1, as well as the other leaf switches, must be configured with VRF-GLOBAL so that the legacy prefixes for all customers are imported. The following is a configuration for VRF-GLOBAL on Leaf1.
--{ + candidate shared default }--[ network-instance IP-VRF-GLOBAL ]--
A:leaf1# info
type ip-vrf
admin-state enable
inter-instance-policies {
apply-policy {
import-policy IP-VRF-GLOBAL-import-cust-prefixes
export-policy IP-VRF-GLOBAL-make-cust-prefixes-leakable
}
}
vxlan-interface vxlan1.1000 {
}
protocols {
bgp-evpn {
bgp-instance 1 {
admin-state enable
vxlan-interface vxlan1.1000
evi 1000
ecmp 8
}
}
bgp-vpn {
bgp-instance 1 {
route-target {
export-rt target:100:1000
import-rt target:100:1000
}
}
}
}Leaf1 routing policy configuration
In the route leaking example shown in Figure 2: Network-instance route leaking example, route leaking policies are required to guarantee communication between servers in the DC and hosts in the legacy IP-VPN network.
VRF-GLOBAL requires the following inter-instance policies:
export policy IP-VRF-GLOBAL-make-cust-prefixes-leakableThis policy makes the legacy prefixes 100.100.100.0/24, 200.200.200.0/24 and 130.130.130.0/24 in the VRF-GLOBAL route-table leakable. The policy matches on and accepts protocol bgp-evpn and prefix-set routes and rejects everything else to ensure no other routes are made available for leaking. Leaked routes are ignored by the policy.
import policy IP-VRF-GLOBAL-import-cust-prefixesThis policy imports all prefixes that are made leakable into the VRF-GLOBAL route-table.
VRF-1 requires the following inter-instance policies:
export policy IP-VRF-export-localThis policy matches on protocol local and protocol arp-nd so that the local/arp-nd routes of VRF-1 are made available for leaking.
import policy IP-VRF-1-import-cust-1This policy matches on prefix-set customer-1 (which comprises all prefixes in 100.100.100.0/24) to accept only the routes of customer-1 and reject the rest.
The policies for VRF-2 are similar to those for VRF-1, only replacing the
prefix-set with prefix-set customer-2, which
covers all prefixes in 200.200.200.0/24.
The following are the policies configured on SR Linux Leaf1. Similar policies are configured on the other leaf devices.
--{ + candidate shared default }--[ routing-policy ]--
A:leaf1# info
// prefix sets defined:
prefix-set cust-1 {
prefix 100.100.0.0/16 mask-length-range 16..24 {
}
}
prefix-set cust-2 {
prefix 200.200.0.0/16 mask-length-range 16..24 {
}
}
prefix-set cust-3 {
prefix 130.130.0.0/16 mask-length-range 16..24 {
}
}
community-set target:100:1000 {
member [
target:100:1000
]
}
policy IP-VRF-1-import-cust-1 { // leaks into IP-VRF-1 only the prefix-set of customer 1
default-action {
policy-result reject
}
statement 1 {
match {
prefix-set cust-1
}
action {
policy-result accept
}
}
}
policy IP-VRF-2-import-cust-2 { // leaks into IP-VRF-2 only the prefix-set of customer 1
default-action {
policy-result reject
}
statement 1 {
match {
prefix-set cust-2
}
action {
policy-result accept
}
}
}
policy IP-VRF-GLOBAL-import-cust-prefixes { // leaks into IP-VRF-GLOBAL all the prefixes made leakable
default-action {
policy-result accept
}
}
policy IP-VRF-GLOBAL-make-cust-prefixes-leakable {
default-action {
policy-result reject
}
statement 10 {
match {
protocol bgp-evpn
}
action {
policy-result accept
}
}
}
policy IP-VRF-export-local { // applied to IP-VRF-1 and IP-VRF-2, makes leakable the routes that are either local or arp-nd
default-action {
policy-result reject
}
statement 10 {
match {
protocol local
}
action {
policy-result accept
}
}
statement 20 {
match {
protocol arp-nd
}
action {
policy-result accept
}
}
}
policy import-local-cust { // applied as import on the IP-VRF-GLOBAL, imports only the legacy prefixes of the local customers
default-action {
policy-result reject
}
statement 10 {
match {
prefix-set cust-1
bgp {
community-set target:100:1000
}
}
action {
policy-result accept
}
}
statement 20 {
match {
prefix-set cust-2
bgp {
community-set target:100:1000
}
}
action {
policy-result accept
}
}
}Leaf1 IP-VRF route-tables
Based on the preceding policies, the route tables in Leaf1 shows the leaked routes as follows:
-{ + candidate shared default }--[ ]--
A:leaf1# show network-instance IP-VRF-* route-table
------------------------------------------------------------------------------------------------------
IPv4 unicast route table of network instance IP-VRF-1
------------------------------------------------------------------------------------------------------
+------------------+---+---------+-------------+-------+------+----+----------------------+----------+
| Prefix | ID| Route | Route | Active|Metric|Pref| Next-hop | Next-hop |
| | | Type | Owner | | | | (Type) |Interface |
+==================+===+=========+=============+=======+======+====+======================+==========+
| 10.10.10.0/ | 0 | bgp-evpn| bgp_evpn_mgr| False | 0 | 170| 10.0.0.3/32 | |
| | | | | | | | (indirect/vxlan) | |
| 10.10.10.0/24 | 4 | local | net_inst_mgr| True | 0 | 0 | 10.10.10.254 (direct)| irb0.1 |
| 10.10.10.1/32 | 4 | arp-nd | arp_nd_mgr | True | 0 | 1 | 10.10.10.1 (direct) | irb0.1 |
| 10.10.10.254/32 | 4 | host | net_inst_mgr| True | 0 | 0 | None (extract) | None |
| 10.10.10.255/32 | 4 | host | net_inst_mgr| True | 0 | 0 | None (broadcast) | |
| 11.11.11.11/32 | 7 | host | net_inst_mgr| True | 0 | 0 | None (extract) | None |
| 31.31.31.31/32 | 0 | bgp-evpn| bgp_evpn_mgr| True | 0 | 170| 10.0.0.3/32 | |
| | | | | | | | (indirect/vxlan) | |
| 100.100.100.0/24 | 0 | bgp-evpn| bgp_evpn_mgr| True | 0 | 170| | |
+------------------+---+---------+-------------+-------+------+----+----------------------+----------+
------------------------------------------------------------------------------------------------------
IPv4 routes total
IPv4 prefixes with active routes : 7
IPv4 prefixes with active ECMP routes: 0
------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------
IPv4 unicast route table of network instance IP-VRF-2
------------------------------------------------------------------------------------------------------
+------------------+---+---------+-------------+-------+------+----+----------------------+----------+
| Prefix | ID| Route | Route | Active|Metric|Pref| Next-hop | Next-hop |
| | | Type | Owner | | | | (Type) |Interface |
+==================+===+=========+=============+=======+======+====+======================+==========+
| 12.12.12.12/32 | 8 | host | net_inst_mgr| True | 0 | 0 | None (extract) | None |
| 20.20.20.0/24 | 0 | bgp-evpn| bgp_evpn_mgr| False | 0 | 170| 10.0.0.2/32 | |
| | | | | | | | (indirect/vxlan) | |
| 20.20.20.0/24 | 5 | local | net_inst_mgr| True | 0 | 0 | 20.20.20.254 (direct)| irb0.2 |
| 20.20.20.12/32 | 0 | bgp-evpn| bgp_evpn_mgr| True | 0 | 170| 10.0.0.2/32 | |
| | | | | | | | (indirect/vxlan) | |
| 20.20.20.254/32 | 5 | host | net_inst_mgr| | 0 | 0 | None (extract) | None |
| 20.20.20.255/32 | 5 | host | net_inst_mgr| True | 0 | 0 | None (broadcast) | |
| 22.22.22.22/32 | 0 | bgp-evpn| bgp_evpn_mgr| True | 0 | 170| 10.0.0.2/32 | |
| | | | | | | | (indirect/vxlan) | |
| 200.200.200.0/24 | 0 | bgp-evpn| bgp_evpn_mgr| True | 0 | 170| | |
+------------------+---+---------+-------------+-------+------+----+----------------------+----------+
-----------------------------------------------------------------------------------------------------
IPv4 routes total : 8
IPv4 prefixes with active routes : 7
IPv4 prefixes with active ECMP routes: 0
------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------
IPv4 unicast route table of network instan
--------------------------------------------------------------------------------------------------
+------------------+---+---------+-------------+-------+------+----+------------------+----------+
| Prefix | ID| Route | Route | Active|Metric|Pref| Next-hop | Next-hop |
| | | Type | Owner | | | | (Type) |Interface |
+==================+===+=========+=============+=======+======+====+==================+==========+
| 10.10.10.0/24 | 4 | local | net_inst_mgr| True | 0 | 0 | | |
| 10.10.10.1/32 | 4 | arp-nd | arp_nd_mgr | True | 0 | 1 | | |
| 20.20.20.0/24 | 5 | local | net_inst_mgr| True | 0 | 0 | | |
| 100.100.100.0/24 | 0 | bgp-evpn| bgp_evpn_mgr| True | 0 | 170| 10.0.0.4/32 | |
| | | | | | | | (indirect/vxlan) | |
| 200.200.200.0/24 | 0 | bgp-evpn| bgp_evpn_mgr| True | 0 | 170| 10.0.0.4/32 | |
| | | | | | | | (indirect/vxlan) | |
+------------------+---+---------+-------------+-------+------+----+------------------+----------+
-------------------------------------------------------------------------------------------------
IPv4 routes total : 5
IPv4 prefixes with active routes : 5
IPv4 prefixes with active ECMP routes: 0
-------------------------------------------------------------------------------------------------
--{ + candidate shared default }--[ ]--Leaf1 route-tables state
The info from state information shows the origin of the leaked
routes:
-{ + candidate shared default }--[ network-instance IP-VRF-* ]--
A:leaf1# info from state route-table
network-instance IP-VRF-1 {
route-table {
ipv4-unicast {
route 10.10.10.0/24 id 0 route-type bgp-evpn route-owner bgp_evpn_mgr origin-network-instance IP-VRF-1 {
leakable false
metric 0
preference 170
active false
last-app-update 2023-01-26T14:59:31.386Z
next-hop-group 538392877111
next-hop-group-network-instance IP-VRF-1
resilient-hash false
fib-programming {
suppressed false
last-successful-operation-type modify
last-successful-operation-timestamp 2023-01-26T14:59:31.387Z
pending-operation-type none
last-failed-operation-type none
}
}
<snip>
route 100.100.100.0/24 id 0 route-type bgp-evpn route-owner bgp_evpn_mgr origin-network-instance IP-VRF-GLOBAL {
leakable true
metric 0
preference 170
active true
last-app-update 2023-01-26T14:59:31.386Z
next-hop-group 538392877123
next-hop-group-network-instance IP-VRF-GLOBAL
resilient-hash false
target-network-instances [
IP-VRF-1
]
fib-programming {
suppressed false
last-successful-operation-type modify
last-successful-operation-timestamp 2023-01-26T14:59:31.397Z
pending-operation-type none
last-failed-operation-type none
}
}
statistics {
active-routes 7
active-routes-with-ecmp 0
resilient-hash-routes 0
fib-failed-routes 0
total-routes 8
}
route-summary {
route-type arp-nd {
active-routes 1
}
route-type bgp-evpn {
active-routes 3
}
route-type host {
active-routes 3
}
route-type local {
active-routes 1
}
}
}
ipv6-unicast {
}
next-hop-group 538392877076 {
backup-next-hop-group 0
fib-programming {
last-successful-operation-type add
last-successful-operation-timestamp 2023-01-26T14:59:31.393Z
pending-operation-type none
last-failed-operation-type none
}
next-hop 0 {
next-hop 538392877074
resolved not-applicable
}
}
next-hop-group 538392877085 {
backup-next-hop-group 0
fib-programming {
last-successful-operation-type add
last-successful-operation-timestamp 2023-01-26T14:59:31.393Z
pending-operation-type none
last-failed-operation-type none
}
next-hop 0 {
next-hop 538392877081
resolved not-applicable
}
}
next-hop-group 538392877086 {
backup-next-hop-group 0
fib-programming {
last-successful-operation-type add
last-successful-operation-timestamp 2023-01-26T14:59:31.393Z
pending-operation-type none
last-failed-operation-type none
}
next-hop 0 {
next-hop 538392877082
resolved not-applicable
}
}
next-hop-group 538392877087 {
backup-next-hop-group 0
fib-programming {
last-successful-operation-type add
last-successful-operation-timestamp 2023-01-26T14:59:31.393Z
pending-operation-type none
last-failed-operation-type none
}
next-hop 0 {
next-hop 3
resolved not-applicable
}
}
next-hop-group 538392877111 {
backup-next-hop-group 0
fib-programming {
last-successful-operation-type add
last-successful-operation-timestamp 2023-01-26T14:59:31.393Z
pending-operation-type none
last-failed-operation-type none
}
next-hop 0 {
next-hop 538392877104
resolved true
}
}
next-hop-group 538392877120 {
backup-next-hop-group 0
fib-programming {
last-successful-operation-type add
last-successful-operation-timestamp 2023-01-26T14:59:31.393Z
pending-operation-type none
last-failed-operation-type none
}
next-hop 0 {
next-hop 538392877111
resolved not-applicable
}
}
next-hop 3 {
type broadcast
}
next-hop 538392877074 {
type extract
}
next-hop 538392877081 {
type direct
ip-address 10.10.10.254
subinterface irb0.1
}
next-hop 538392877082 {
type extract
}
next-hop 538392877104 {
type indirect
ip-address 10.0.0.3
resolving-tunnel {
ip-prefix 10.0.0.3/32
tunnel-type vxlan
tunnel-owner vxlan_mgr
}
vxlan {
vni 1
source-mac 1A:8B:08:FF:00:00
destination-mac 1A:4D:0A:FF:00:00
}
}
next-hop 538392877111 {
type direct
ip-address 10.10.10.1
subinterface irb0.1
}
}
}
network-instance IP-VRF-2 {
route-table {
ipv4-unicast {
route 12.12.12.12/32 id 8 route-type host route-owner net_inst_mgr origin-network-instance IP-VRF-2 {
leakable false
metric 0
preference 0
active true
last-app-update 2023-01-26T14:59:31.384Z
next-hop-group 538392877077
next-hop-group-network-instance IP-VRF-2
resilient-hash false
fib-programming {
suppressed false
last-successful-operation-type modify
last-successful-operation-timestamp 2023-01-26T14:59:31.387Z
pending-operation-type none
last-failed-operation-type none
}
}
<snip>
route 200.200.200.0/24 id 0 route-type bgp-evpn route-owner bgp_evpn_mgr origin-network-instance IP-VRF-GLOBAL {
leakable false
metric 0
preference 170
active true
last-app-update 2023-01-26T14:59:31.386Z
next-hop-group 538392877123
next-hop-group-network-instance IP-VRF-GLOBAL
resilient-hash false
fib-programming {
suppressed false
last-successful-operation-type modify
last-successful-operation-timestamp 2023-01-26T14:59:31.387Z
pending-operation-type none
last-failed-operation-type none
}
}
statistics {
active-routes 7
active-routes-with-ecmp 0
resilient-hash-routes 0
fib-failed-routes 0
total-routes 8
}
route-summary {
route-type bgp-evpn {
active-routes 4
}
route-type host {
active-routes 3
}
route-type local {
active-routes 1
}
}
}
ipv6-unicast {
}
next-hop-group 538392877077 {
backup-next-hop-group 0
fib-programming {
last-successful-operation-type add
last-successful-operation-timestamp 2023-01-26T14:59:31.393Z
pending-operation-type none
last-failed-operation-type none
}
next-hop 0 {
next-hop 538392877075
resolved not-applicable
}
}
next-hop-group 538392877082 {
backup-next-hop-group 0
fib-programming {
last-successful-operation-type add
last-successful-operation-timestamp 2023-01-26T14:59:31.393Z
pending-operation-type none
last-failed-operation-type none
}
next-hop 0 {
next-hop 538392877079
resolved not-applicable
}
}
next-hop-group 538392877083 {
backup-next-hop-group 0
fib-programming {
last-successful-operation-type add
last-successful-operation-timestamp 2023-01-26T14:59:31.393Z
pending-operation-type none
last-failed-operation-type none
}
next-hop 0 {
next-hop 538392877080
resolved not-applicable
}
}
next-hop-group 538392877084 {
backup-next-hop-group 0
fib-programming {
last-successful-operation-type add
last-successful-operation-timestamp 2023-01-26T14:59:31.393Z
pending-operation-type none
last-failed-operation-type none
}
next-hop 0 {
next-hop 3
resolved not-applicable
}
}
next-hop-group 538392877105 {
backup-next-hop-group 0
fib-programming {
last-successful-operation-type add
last-successful-operation-timestamp 2023-01-26T14:59:31.393Z
pending-operation-type none
last-failed-operation-type none
}
next-hop 0 {
next-hop 538392877098
resolved true
}
}
next-hop 3 {
type broadcast
}
next-hop 538392877075 {
type extract
}
next-hop 538392877079 {
type direct
ip-address 20.20.20.254
subinterface irb0.2
}
next-hop 538392877080 {
type extract
}
next-hop 538392877098 {
type indirect
ip-address 10.0.0.2
resolving-tunnel {
ip-prefix 10.0.0.2/32
tunnel-type vxlan
tunnel-owner vxlan_mgr
}
vxlan {
vni 2
source-mac 1A:8B:08:FF:00:00
destination-mac 1A:B2:09:FF:00:00
}
}
}
}
network-instance IP-VRF-GLOBAL {
route-table {
ipv4-unicast {
route 10.10.10.0/24 id 4 route-type local route-owner net_inst_mgr origin-network-instance IP-VRF-1 {
leakable false
metric 0
preference 0
active true
last-app-update 2023-01-26T14:59:31.384Z
next-hop-group 538392877085
next-hop-group-network-instance IP-VRF-1
resilient-hash false
fib-programming {
suppressed false
last-successful-operation-type modify
last-successful-operation-timestamp 2023-01-26T14:59:31.387Z
pending-operation-type none
last-failed-operation-type none
}
}
route 10.10.10.1/32 id 4 route-type arp-nd route-owner arp_nd_mgr origin-network-instance IP-VRF-1 {
leakable false
metric 0
preference 1
active true
last-app-update 2023-01-26T14:59:31.385Z
next-hop-group 538392877120
next-hop-group-network-instance IP-VRF-1
resilient-hash false
fib-programming {
suppressed false
last-successful-operation-type modify
last-successful-operation-timestamp 2023-01-26T14:59:31.387Z
pending-operation-type none
last-failed-operation-type none
}
}
route 20.20.20.0/24 id 5 route-type local route-owner net_inst_mgr origin-network-instance IP-VRF-2 {
leakable false
metric 0
preference 0
active true
last-app-update 2023-01-26T14:59:31.384Z
next-hop-group 538392877082
next-hop-group-network-instance IP-VRF-2
resilient-hash false
fib-programming {
suppressed false
last-successful-operation-type modify
last-successful-operation-timestamp 2023-01-26T14:59:31.387Z
pending-operation-type none
last-failed-operation-type none
}
}
route 100.100.100.0/24 id 0 route-type bgp-evpn route-owner bgp_evpn_mgr origin-network-instance IP-VRF-GLOBAL {
leakable true
metric 0
preference 170
active true
last-app-update 2023-01-26T14:59:31.386Z
next-hop-group 538392877123
next-hop-group-network-instance IP-VRF-GLOBAL
resilient-hash false
fib-programming {
suppressed false
last-successful-operation-type modify
last-successful-operation-timestamp 2023-01-26T14:59:31.387Z
pending-operation-type none
last-failed-operation-type none
}
}
route 200.200.200.0/24 id 0 route-type bgp-evpn route-owner bgp_evpn_mgr origin-network-instance IP-VRF-GLOBAL {
leakable true
metric 0
preference 170
active true
last-app-update 2023-01-26T14:59:31.386Z
next-hop-group 538392877123
next-hop-group-network-instance IP-VRF-GLOBAL
resilient-hash false
fib-programming {
suppressed false
last-successful-operation-type modify
last-successful-operation-timestamp 2023-01-26T14:59:31.387Z
pending-operation-type none
last-failed-operation-type none
}
}
statistics {
active-routes 5
active-routes-with-ecmp 0
resilient-hash-routes 0
fib-failed-routes 0
total-routes 5
}
route-summary {
route-type arp-nd {
active-routes 1
}
route-type bgp-evpn {
active-routes 2
}
route-type local {
active-routes 2
}
}
}
ipv6-unicast {
}
next-hop-group 538392877123 {
backup-next-hop-group 0
fib-programming {
last-successful-operation-type add
last-successful-operation-timestamp 2023-01-26T14:59:31.393Z
pending-operation-type none
last-failed-operation-type none
}
next-hop 0 {
next-hop 538392877114
resolved true
}
}
next-hop 538392877114 {
type indirect
ip-address 10.0.0.4
resolving-tunnel {
ip-prefix 10.0.0.4/32
tunnel-type vxlan
tunnel-owner vxlan_mgr
}
vxlan {
vni 1000
source-mac 1A:8B:08:FF:00:00
destination-mac 00:00:DC:00:00:01
}
}
}
}Configuring interface references
An interface reference is a user-defined name for a configured interface and subinterface within a network-instance. You can refer to the interface by the defined name within the context of the network instance.
The following example configures interface ethernet-1/10, subinterface 1 on the SR Linux device. In network instance black, an interface named red is created. Interface red is defined as interface ethernet-1/10, subinterface 1.
--{ + candidate shared default }--[ ]--
# info interface
interface ethernet-1/10 {
subinterface 1 {
}
}
--{ + candidate shared default }--[ ]--
# info network-instance black
network-instance black {
interface red {
interface-ref {
interface ethernet-1/10
subinterface 1
}
}
}
In the context of network instance black, you can use the name red to refer to interface ethernet-1/10, subinterface 1. For example:
--{ + running }--[ network-instance black ]--
# show interfaces red
===========================================================================
Net instance : black
Interface : ethernet-1/10.1 (red)
Type : routed
Oper state : down
Oper down reason: subif-down
Ip mtu : 1500
===========================================================================