Seamless MPLS with BGP labeled unicast (BGP-LU)
Seamless Multi-Protocol Label Switching (MPLS) is a network architecture that extends MPLS networks to integrate access and aggregation networks into a single MPLS domain, to solve the scaling problems in flat MPLS-based deployments. Seamless MPLS transport partitions the core, aggregation, and access networks into isolated IGP/LDP domains (alternatively, Seamless MPLS is also supported over SR-MPLS TE policy). Seamless MPLS does not define any new protocols or technologies and is based on existing and well-known ones. Seamless MPLS provides end-to-end service-independent transport, separating the service and transport plane. Therefore, it removes the need for service-specific configurations in network transport nodes. Service provisioning is restricted only at the points of the network where it is required.
When BGP is used to distribute a route, it can also distribute an MPLS label that is mapped to that route. The label mapping information is appended to the BGP update message that is used to distribute the route. This is described in RFC 3107, Carrying Label Information in BGP-4.
AN routers in a regional area learn the reachability of AN routers in other regional areas through BGP labeled routes redistributed by the local ABRs (RFC 3107).
The label stack contains three labels for packets sent in a VPN service between the access nodes:
-
The ANs push a service label to the packets sent in the VPN service. The service label remains unchanged end-to-end between ANs. The service label is popped by the remote AN and is the inner label of the label stack.
Note: Service configuration is not yet supported with BGP-LU in the current release. -
The BGP label is the middle label of the label stack and should be regarded as a transport label. The transport label stack is increased to two labels: BGP and LDP transport labels. The BGP label is pushed by the iLER AN and is swapped at the BGP next hop, which can be one of the two local ABRs. Both ABRs are configured with next-hop-self. The BGP label is also swapped by the remote ABR.
-
The iLER AN pushes an LDP transport label to the packets sent to the remote AN to reach the BGP next hop. At the local ABR, the LDP transport label is popped and a new LDP transport label is pushed to reach the BGP next hop (remote ABR). The LDP transport label is swapped in every label switching router (LSR) and popped by the ABR nearest to the remote AN. That ABR pops the LDP transport label, swaps the BGP label, and pushes an LDP transport label to reach the remote eLER AN.
Supported platforms
Seamless MPLS with BGP-LU is supported on the following platforms:
- 7250 IXR
- 7730 SXR
Seamless MPLS with BGP-LU configuration
The following diagram shows the example topology that is used in this chapter. In the regional areas and in the core area IS-IS L2 capability is used with LDP.
Alternatively, Seamless MPLS with BGP-LU can operate over SR-MPLS TE policy in all areas, or it can also operate over a mix of TE policy and LDP-enabled areas. For example, both regional areas can run LDP, while the core area runs TE policy. However, this example shows LDP configuration only.
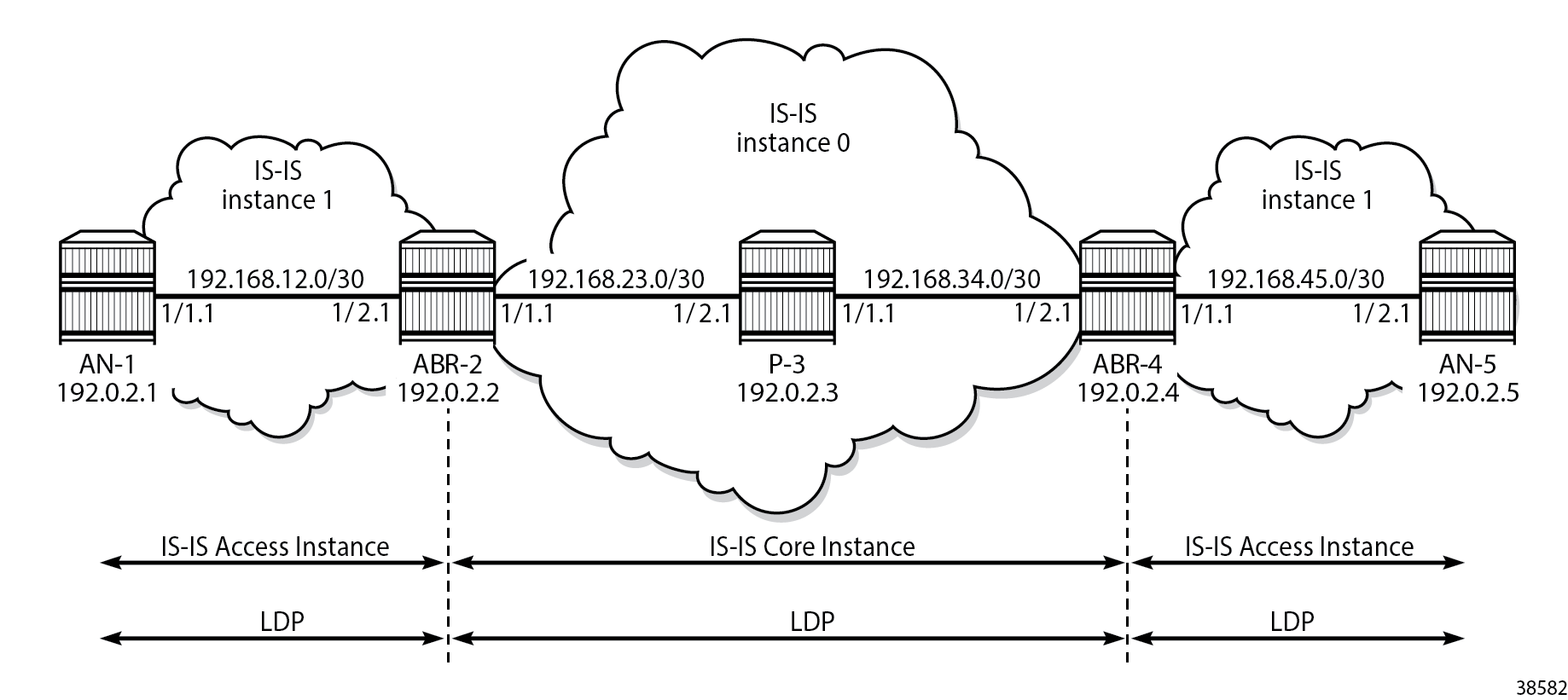
To configure Seamless MPLS, see the following sections:
- Initial configuration for Seamless MPLS
- BGP configuration for Seamless MPLS
- Configuring BGP on ANs toward ABRs
Initial configuration for Seamless MPLS
The following sections describe the initial configurations required on all nodes to enable Seamless MPLS.
Configuring interfaces
Configure the required routing interfaces and add them to the network-instance.
Configure interfaces (ABR-2)
The following example output shows the interface configuration on ABR-2.
# on ABR-2:
interface ethernet-1/2 {
description ABR2-AN1
admin-state enable
subinterface 1 {
admin-state enable
ipv4 {
admin-state enable
address 192.168.12.2/30 {
}
}
}
}
interface ethernet-1/1 {
description ABR2-P3
admin-state enable
subinterface 1 {
admin-state enable
ipv4 {
admin-state enable
address 192.168.23.1/30 {
}
}
}
}
interface system0 {
admin-state enable
subinterface 0 {
admin-state enable
ipv4 {
admin-state enable
address 192.0.2.2/32 {
}
}
}
}
Add interfaces to the network instance
# on ABR-2:
network-instance default {
interface ABR2-P3 {
interface-ref {
interface ethernet-1/1
subinterface 1
}
}
interface ABR2-AN1 {
interface-ref {
interface ethernet-1/2
subinterface 1
}
}
interface system0.0 {
}Configuring IS-IS
Configure IS-IS on each of the nodes.
The core area and regional areas run isolated IS-IS instances. ABRs run two IS-IS instances: instance 0 belongs to the core and instance 1 belongs to the access network.
Configure IS-IS on the core instance
On the core instance, all ABRs and Ps require level 2 (L2) capability, as shown in the following example.
# on ABR-2:
network-instance default {
protocols {
isis {
instance ISIS-0 {
admin-state enable
instance-id 0
level-capability L2
iid-tlv true
net [
49.0000.0000.0000.0002.00
]
ipv4-unicast {
admin-state enable
}
interface ethernet-1/1.1 {
circuit-type point-to-point
ipv4-unicast {
admin-state enable
}
level 2 {
}
}
interface system0.0 {
admin-state enable
passive true
ipv4-unicast {
admin-state enable
}
level 2 {
}
}
}
Configure IS-IS on the access instance
On the access instance, all ABRs and ANs also require L2 capability, as shown in the following example.
# on ABR-2:
network-instance default {
protocols {
isis {
instance ISIS-1 {
admin-state enable
instance-id 1
level-capability L2
iid-tlv true
net [
49.0001.0000.0000.0002.00
]
interface ethernet-1/2.1 {
circuit-type point-to-point
ipv4-unicast {
admin-state enable
}
level 2 {
}
}
interface system0.0 {
admin-state enable
passive true
ipv4-unicast {
admin-state enable
}
level 2 {
}
}
}
}
}
}
Configuring MPLS label blocks
Configure label blocks for LDP and for BGP-LU labels.
Configure label blocks for LDP and BGP-LU
--{ + candidate shared default }--[ ]--
# /info with-context system mpls label-ranges
system {
mpls {
label-ranges {
dynamic D1 {
start-label 200
end-label 299
}
dynamic bgp-lu-block {
start-label 12001
end-label 13000
}
}
}
}Configuring LDP
Enable Link LDP on all router interfaces on all nodes.
Configure Link LDP (ABR-2)
# on ABR-2:
network-instance default {
protocols {
ldp {
admin-state enable
dynamic-label-block D1
discovery {
interfaces {
interface ethernet-1/1.1 {
ipv4 {
admin-state enable
}
}
interface ethernet-1/2.1 {
ipv4 {
admin-state enable
}
}
}
}
}
}
}BGP configuration for Seamless MPLS
BGP is configured on all ABRs and all ANs. P-3 acts as a core Route Reflector (RR). To allow for separation of core/access IGP domains, the ABRs become RRs inline and implement next-hop-self on labeled IPv4 BGP prefixes. The following diagram shows the exchange of iBGP Labeled Unicast (LU) routes.
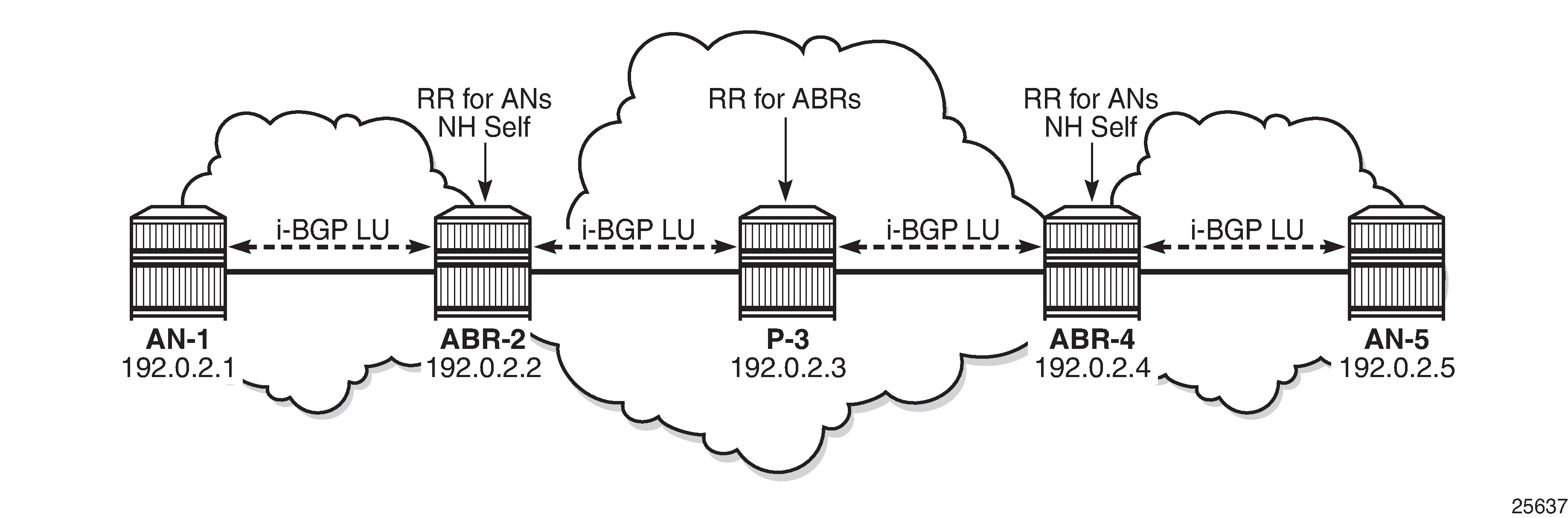
The following sections describe the BGP configurations required on all nodes to enable Seamless MPLS.
Configuring BGP on ABRs
Configure two BGP groups on the ABRs: one group toward the core RR and another group toward the AN. Enable advertise-inactive on the BGP group toward the core.
The /32 system IP addresses, learned in labeled BGP, are also learned in IS-IS. Because IS-IS has a lower preference compared to iBGP, the IS-IS routes are installed in the routing table. BGP default behavior only advertises those prefixes that were elected by RTM and used.
Configure BGP core on ABRs
# on ABR-2:
network-instance default
protocols {
bgp {
admin-state enable
autonomous-system 64496
router-id 192.0.2.2
best-path-selection {
advertise-inactive true
}
bgp-label {
labeled-unicast {
dynamic-label-block bgp-lu-block
}
}
afi-safi ipv4-labeled-unicast {
admin-state enable
ipv4-labeled-unicast {
next-hop-resolution {
ipv4-next-hops {
route-resolution {
ignore-default-routes true
}
tunnel-resolution {
allowed-tunnel-types [
ldp
]
}
}
}
}
}
group AN {
admin-state enable
peer-as 64496
}
group core {
admin-state enable
peer-as 64496
route-reflector {
cluster-id 10.2.2.2
client true
}
}
neighbor 192.0.2.1 {
description AN1
next-hop-self true
peer-group AN
}
neighbor 192.0.2.3 {
description coreRR_P3
next-hop-self true
peer-group core
}
}-
To enable ECMP, set afi-safi [ipv4-labeled-unicast | ipv6-labeled-unicast] multipath maximum-paths to a value greater than 1. The value of maximum-paths sets the maximum number of ECMP forwarding paths, including the best path, for a BGP prefix. The additional non-best-path labeled RIB-INs are added to the ECMP NHG.
-
Under tunnel-resolution allowed-tunnel-types, you can specify sr-isis to enable the use of SR-ISIS tunnels for next-hop resolution of BGP-LU traffic as an alternative to LDP, if SR-ISIS is configured in your domain.
Configuring BGP on the core RR
Configure BGP on the core RR
# on P-3:
network-instance default
protocols {
bgp {
admin-state enable
autonomous-system 64496
router-id 192.0.2.3
best-path-selection {
advertise-inactive true
}
bgp-label {
labeled-unicast {
dynamic-label-block bgp-lu-block
}
}
afi-safi ipv4-labeled-unicast {
admin-state enable
ipv4-labeled-unicast {
next-hop-resolution {
ipv4-next-hops {
tunnel-resolution {
allowed-tunnel-types [
ldp
]
}
}
}
}
}
group core {
admin-state enable
peer-as 64496
afi-safi ipv4-labeled-unicast {
admin-state enable
}
route-reflector {
cluster-id 10.3.3.3
}
}
neighbor 192.0.2.2 {
description ABR-2
peer-group core
route-reflector {
cluster-id 10.3.3.3
client true
}
}
neighbor 192.0.2.4 {
description ABR-4
peer-group core
route-reflector {
cluster-id 10.3.3.3
client true
}
}
}
Configuring BGP on ANs toward ABRs
Configure BGP on AN-1 toward ABR
Configuring afi-safi ipv4-labeled-unicast indicates that all advertised IPv4 prefixes are sent to the remote BGP peer as an RFC 3107 formatted label. The next-hop-self command only applies to labeled IPv4 prefixes.
# on AN-1:
network-instance default
protocols {
bgp {
admin-state enable
autonomous-system 64496
router-id 192.0.2.1
best-path-selection {
advertise-inactive true
}
bgp-label {
labeled-unicast {
dynamic-label-block bgp-lu-block
}
}
afi-safi ipv4-labeled-unicast {
admin-state enable
ipv4-labeled-unicast {
next-hop-resolution {
ipv4-next-hops {
route-resolution {
ignore-default-routes true
}
tunnel-resolution {
allowed-tunnel-types [
ldp
]
}
}
}
}
}
group ABRs {
admin-state enable
peer-as 64496
afi-safi ipv4-labeled-unicast {
admin-state enable
}
}
neighbor 192.0.2.2 {
description ABR2
peer-group ABRs
}
}
You can show the BGP sessions with the show network-instance default protocols bgp neighbor command.
Export policy configuration for Seamless MPLS
A policy is required on the ANs to advertise the system IP address in labeled BGP toward the ABRs. The same policy is required on the ABRs to advertise their system IP address in labeled BGP toward the core and the AN.
Configuring export policies on ANs and ABRs
Configure a policy on ANs and ABRs
# on AN-1 and ABR-2:
routing-policy {
prefix-set local-loopback {
prefix 192.0.2.1/32 mask-length-range exact {
}
}
policy export-system {
statement 10 {
match {
prefix-set local-loopback
protocol local
}
action {
policy-result accept
}
}
}
}Apply the policy on AN-1
- protocols bgp
- protocols bgp neighbor
- protocols bgp group
Or to apply the policy to BGP-LU only, use one of the following contexts:
- protocols bgp afi-safi ipv4-labeled-unicast
- protocols bgp neighbor afi-safi ipv4-labeled-unicast
- protocols bgp group afi-safi ipv4-labeled-unicast
In this example, the export policy is applied to BGP-LU in the group ABRs on AN-1, as follows:
# on AN-1:
network-instance default {
protocols {
bgp {
group ABRs {
afi-safi ipv4-labeled-unicast {
export-policy export-system
}
}
}
}
}
Apply the policy on ABR-2
The same export policy is applied in the group core on ABR-2, as follows:
# on ABR-2:
network-instance default {
protocols {
bgp {
group core {
afi-safi ipv4-labeled-unicast {
export-policy export-system
}
}
}
}
}
A similar export policy is required to export prefix 192.0.2.5 from AN-5 to ABR-4 and from ABR-4 to the RR in the core network, P-3.
Use the show network-instance default route-table command to display the route table. The prefix of the remote AN should be added to the routing table in AN-1.
BGP-LU selective install
In BGP-LU networks, the number of BGP-LU routes that are distributed in the control plane can exceed the capacity of the FIB and label forwarding information base (LFIB) of small access routers. One solution to this issue is to apply import policies on the access routers to limit the number of BGP-LU routes accepted in the RIB-IN, but this is labor-intensive and prone to errors. A better solution is to enable selective install of BGP-LU routes in the default network instance, which provides an alternate method of limiting the number of BGP-LU routes in the RIB-IN.
When selective install is configured, BGP-LU routes in the RIB-IN that are received from a BGP peer but not required by any eligible service are handled as follows:
-
No BGP-LU route is programmed as a next hop (primary next hop, ECMP next hop, or backup next hop) of any IP route or tunnel.
-
No BGP tunnel for the /32 IPv4 or /128 IPv6 prefix is added to the tunnel table.
BGP-LU selective install parameters
The BGP-LU selective install feature supports optional parameters (program-route and program-label-swap) that allow you to alter the default handling of BGP-LU selective install routes. These parameters enable the installation of ILM entries and FIB entries for the BGP-LU routes, even when those BGP-LU routes are not required by any service and therefore are not installed as tunnels. The parameters are defined as follows:
- program-label-swap — When set to true, the system programs a label swap entry even when the route is not installed as a tunnel.
- program-route — When set to true, the system programs an IP FIB entry even when the BGP-LU route is not installed as a tunnel. To set program-route to true, program-label-swap must also be set to true.
Configuring BGP-LU selective install
To enable BGP-LU selective install, use the network-instance protocols bgp bgp-label labeled-unicast selective-labeled-unicast-install command.
Configure BGP-LU selective install
The following example enables BGP-LU selective install. It also enables programming of label swap entries (program-label-swap true) and FIB entries (program-route true) for the BGP-LU routes, even when those BGP-LU routes are not installed as tunnels.
--{ candidate shared default }--[ ]--
# info with-context network-instance default protocols bgp bgp-label labeled-unicast selective-labeled-unicast-install
network-instance default {
protocols {
bgp {
bgp-label {
labeled-unicast {
selective-labeled-unicast-install {
program-label-swap true
program-route true
}
}
}
}
}
}Advertisement of BGP-LUv4 routes with IPv6 next hops
In networks where the routers are interconnected by IPv6-only links, SR Linux routers can advertise and receive BGP routes for IPv4 labeled-unicast destinations that are reachable through IPv6 next hops. Advertising and receiving IPv4 labeled-unicast routes with IPv6 next hops is useful in networks or regions with IPv6-only interfaces.
This feature requires the extended next hop encoding BGP capability which is described in RFC 5549, Advertising IPv4 Network Layer Reachability Information with an IPv6 Next Hop. BGP capabilities are advertised between peers.
By default, IPv4 labeled-unicast routes are advertised with IPv4 next hops. However, on IPv6-only TCP transport sessions, IPv4 labeled-unicast routes can be advertised with IPv6 next hops if the advertise-ipv6-next-hops command applies to the session.
To receive IPv4 labeled-unicast routes with IPv6 next-hop addresses, the receive-ipv6-next-hops command must be applied to the session. This advertises the RFC 5549 capability to the peer for the IPv4 labeled-unicast address family.
When the BGP session is established, the BGP peers advertise the capability to each other. The Extended Next Hop encoding capability is both a local and a remote capability, as in the following output examples between BGP peers 2001:db8::12:1 and 2001:db8::12:2:
# /show network-instance default protocols bgp neighbor 2001:db8::12:2 detail | grep Cap
Cap Sent: ROUTE_REFRESH EXT_NH_ENCODING 4-OCTET_ASN MP_BGP GRACEFUL_RESTART
Cap Recv: ROUTE_REFRESH EXT_NH_ENCODING 4-OCTET_ASN MP_BGP GRACEFUL_RESTART# /info with-context from state flat detail network-instance default protocols bgp neighbor 2001:db8::12:2 | grep EXT
/ network-instance default protocols bgp neighbor 2001:db8::12:2 advertised-capabilities [ ROUTE_REFRESH EXT_NH_ENCODING 4-OCTET_ASN MP_BGP GRACEFUL_RESTART ]
/ network-instance default protocols bgp neighbor 2001:db8::12:2 received-capabilities [ ROUTE_REFRESH EXT_NH_ENCODING 4-OCTET_ASN MP_BGP GRACEFUL_RESTART ]When next-hop-self applies to the BGP session and the neighbor address is IPv6, an IPv4 labeled-unicast route that is advertised or re-advertised uses the IPv6 local address used for peering as the next hop.
Enabling IPv6 next-hops on BGP-LUv4 routes
To advertise IPv4 labeled-unicast routes with IPv6 next-hops on IPv6-only TCP transport sessions, use the advertise-ipv6-next-hops command. To receive IPv4 labeled-unicast routes with IPv6 next-hop addresses, use the receive-ipv6-next-hops command. These commands can be applied to the ipv4-labeled-unicast family under the bgp, bgp group, or bgp neighbor contexts.
Enable IPv6 next-hops on BGP-LUv4 routes
--{ candidate shared default }--[ ]--
# info with-context network-instance default protocols bgp afi-safi ipv4-labeled-unicast
network-instance default {
protocols {
bgp {
afi-safi ipv4-labeled-unicast {
ipv4-labeled-unicast {
advertise-ipv6-next-hops true
receive-ipv6-next-hops true
}
}
}
}
}