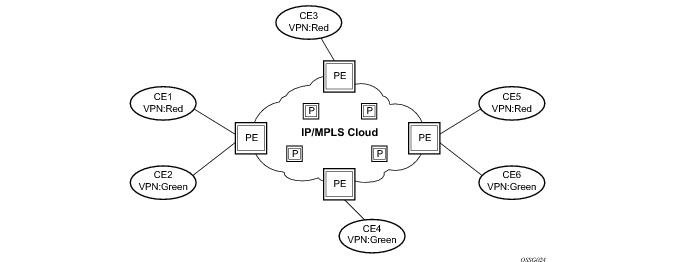
RFC 2547b is an extension to the original RFC 2547, BGP/MPLS VPNs, which details a method of distributing routing information using BGP and MPLS forwarding data to provide a Layer 3 Virtual Private Network (VPN) service to end customers.
BGP is used with BGP extensions mentioned in Routing Prerequisites to distribute VPRN routing information across the service provider’s network.
The route distinguisher (RD) is an 8-byte value consisting of two major fields, the Type field and
Value field. The
Type field determines how the
Value field should be interpreted. The 7750 SR OS implementation supports the three (3)
Type values as defined in the standard.
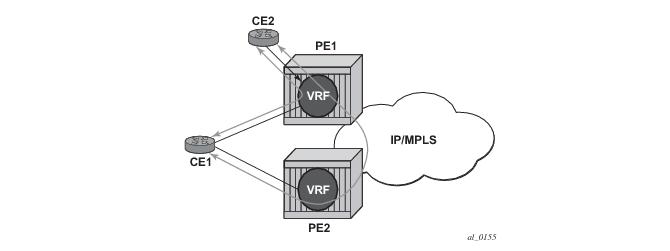
Figure 91 displays a basic topology that could use eiBGP load balancing. In this topology CE1 is dual homed and thus reachable by two separate PE routers. CE 2 (a site in the same VPRN) is also attached to PE1. With eiBGP load balancing, PE1 will utilize its own local IPv4 nexthop as well as the route advertised by MP-BGP, by PE2.
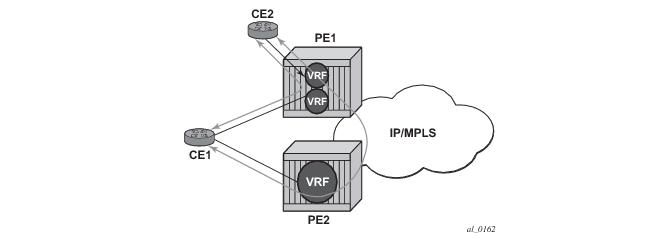
Another example displayed in Figure 92 shows an extra net VPRN (VRF). The traffic ingressing the PE that should be load balanced is part of a second VPRN and the route over which the load balancing is to occur is part of a separate VPRN instance and are leaked into the second VPRN by route policies.
VPN-IP routes imported into a VPRN, have the protocol type bgp-vpn to denote that it is an VPRN route. This can be used within the route policy match criteria.
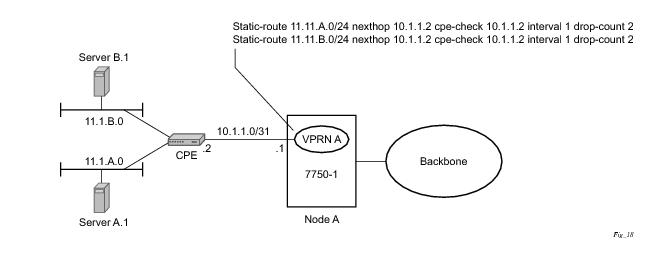
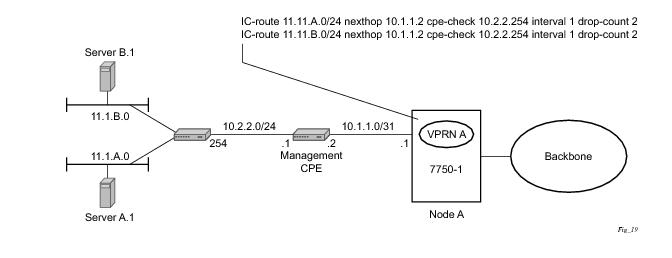
Static routes are used within many IES and VPRN services. Unlike dynamic routing protocols, there is no way to change the state of routes based on availability information for the associated CPE. CPE connectivity check adds flexibility so that unavailable destinations will be removed from the VPRN routing tables dynamically and minimize wasted bandwidth.
RT Constraint is supported only by the base router BGP instance. When the family command at the BGP router group or neighbor CLI context includes the
route-target keyword, the RT Constraint capability is negotiated with the associated set of EBGP and IBGP peers.
A 7750 SR may be configured to send the default RTC route to any RTC peer. This is done using the new
default-route-target group/neighbor CLI command. The default RTC route is a special type of RTC route that has zero prefix length. Sending the default RTC route to a peer conveys a request to receive all VPN routes (regardless of route target extended community) from that peer. The default RTC route is typically advertised by a route reflector to its clients. The advertisement of the default RTC route to a peer does not suppress other more specific RTC routes from being sent to that peer.
Note: These advertisement rules do not handle hierarchical RR topologies properly. This is a limitation of the current RT constraint standard.
Configuring the backup-path command under
config>service>vprn>bgp causes only routes learned from CE BGP peers to be considered when selecting the primary and backup paths. Configuring the
enable-bgp-vpn-backup command under
config>service>vprn causes imported BGP-VPN routes to be compared to CE BGP routes when selecting the primary and backup paths. This command is required to support fast failover of ingress traffic from one remote PE to another remote PE and to support fast failover of egress traffic from a locally connected CE to a remote PE.
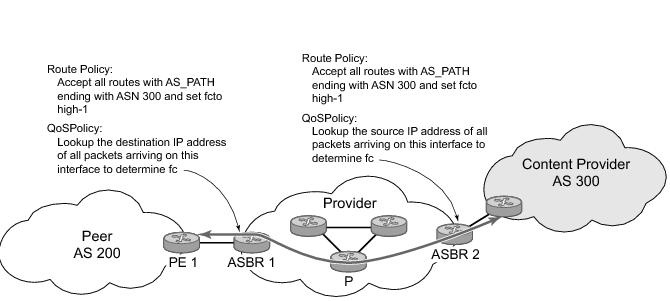
Figure 95 shows an example of an ISP that has an agreement with the content provider managing AS300 to provide traffic sourced and terminating within AS300 with differentiated service appropriate to the content being transported. In this example we presume that ASBR1 and ASBR2 mark the DSCP of packets terminating and sourced, respectively, in AS300 so that other nodes within the ISP’s network do not need to rely on QPPB to determine the correct forwarding-class to use for the traffic. Note however, that the DSCP or other COS markings could be left unchanged in the ISP’s network and QPPB used on every node.
The fc command is supported with all existing from and to match conditions in a route policy entry and with any action other than reject, it is supported with next-entry, next-policy and accept actions. If a next-entry or next-policy action results in multiple matching entries then the last entry with a QPPB action determines the forwarding class and priority.
A route policy that includes the fc command in one or more entries can be used in any import or export policy but the
fc command has no effect except in the following types of policies:
This feature uses a qos keyword to the
show>router>route-table command. When this option is specified the output includes an additional line per route entry that displays the forwarding class and priority of the route. If a route has no fc and priority information then the third line is blank. The following CLI shows an example:
To enable QoS classification of ingress IP packets on an interface based on the QoS information associated with the routes that best match the packets the qos-route-lookup command is necessary in the configuration of the IP interface. The
qos-route-lookup command has parameters to indicate whether the QoS result is based on lookup of the source or destination IP address in every packet. There are separate qos-route-lookup commands for the IPv4 and IPv6 packets on an interface, which allows QPPB to enabled for IPv4 only, IPv6 only, or both IPv4 and IPv6. Note however, current QPPB based on a source IP address is not supported for IPv6 packets nor is it supported for ingress subscriber management traffic on a group interface.
When QPPB is enabled on a SAP IP interface the forwarding class of a packet may change from fc1, the original
fc determined by the SAP ingress QoS policy to fc2, the new fc determined by QPPB. In the ingress datapath SAP ingress QoS policies are applied in the first P chip and route lookup/QPPB occurs in the second P chip. This has the implications listed below:
Table 24 summarizes these interactions.
The 7750 SR VPRN supports the following PE to CE routing protocols:
The 7750 SR supports multiple mechanisms to provide transport tunnels for the forwarding of traffic between PE routers within the 2547bis network.
The 7750 SR VPRN implementation supports the use of:
The 7750 SR allows setting the maximum number of routes that can be accepted in the VRF for a VPRN service. There are options to specify a percentage threshold at which to generate an event that the VRF table is near full and an option to disable additional route learning when full or only generate an event.
Figure 96 depicts traffic terminating on a specific IES or VPRN service that is identified by the
sdp-id and VC label present in the service packet.
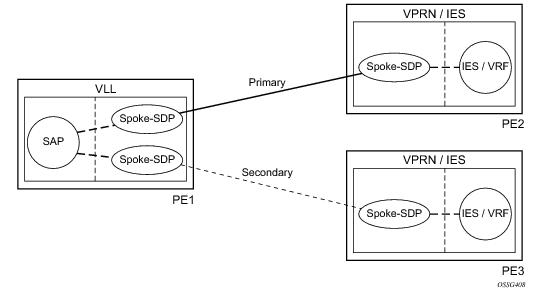
In Figure 97, PE1 terminates two spoke-SDPs that are bound to one SAP connected to CE1. PE1 chooses to forward traffic on one of the spoke SDPs (the active spoke-SDP), while blocking traffic on the other spoke-SDP (the standby spoke-SDP) in the transmit direction. PE2 and PE3 take any spoke-SDPs for which PW forwarding standby has been signaled by PE1 to an operationally down state.
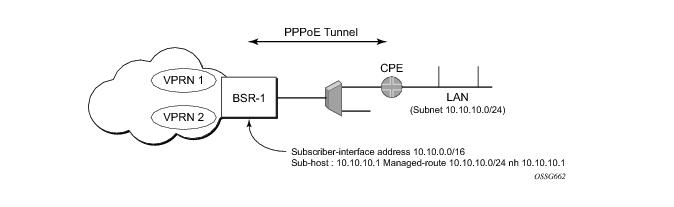
From a BNG perspective, the given PPPoE host is allocated a subnet (instead of /32) by RADIUS, external dhcp-server, or local-user-db. And locally, the host is associated with managed-route. This managed-route will be subset of the subscriber-interface subnet, and also, subscriber-host ip-address will be from managed-route range. The negotiation between BNG and CPE allows CPE to be allocated both ip-address and associated subnet.
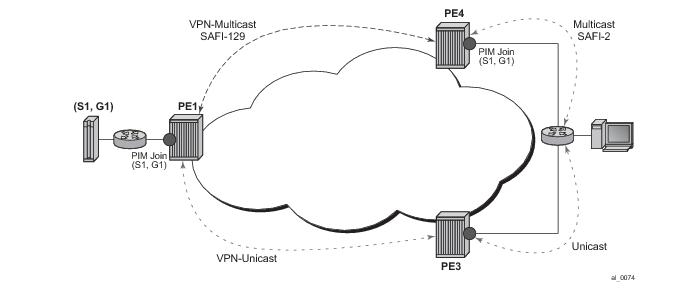
Implementation of the draft-rosen-vpn-mcast, Multicast in MPLS/BGP IP VPNs, entails the support and separation of the providers core multicast domain from the various customer multicast domains and the various customer multicast domains from each other.
Figure 100 depicts an example of multicast in an IP-VPN application. The provider’s domain encompasses the core routers (1 through 4) and the edge routers (5 through 10). The various IP-VPN customers each have their own multicast domain, VPN-1 (CE routers 12, 13 and 16) and VPN-2 (CE Routers 11, 14, 15, 17 and 18). Multicast in this VPRN example, the VPN-1 data generated by the customer behind router 16 will be multicast only by PE 9 to PE routers 6 and 7 for delivery to CE routers 12 and 13 respectively. Data generated for VPN-2 generated by the customer behind router 15 will be forwarded by PE 8 to PE routers 5, 7 and 10 for delivery to CE routers 18, 11, 14 and 17 respectively.
Table 26 and
Table 27 describe the supported configuration combinations. If the CLI combination is not allowed, the system returns an error message. If the CLI command is marked as “ignored” in the table, the configuration is not blocked, but its value is ignored by the software.
For example, if auto-discovery is disabled, the c-mcast-signaling bgp command will fail with an error message stating:
If c-mcast-signaling is set to
bgp then
no auto-discovery will fail with an error message stating
When c-mcast-signaling is set to
bgp, S-PMSI A-D is always enabled (its configuration is ignored);
When auto-discovery is disabled, S-PMSI A-D is always disabled (its configuration is ignored).
When auto-discovery is enabled and c-multicast-signaling is set to
pim, S-PMSI A-D configuration value is used.
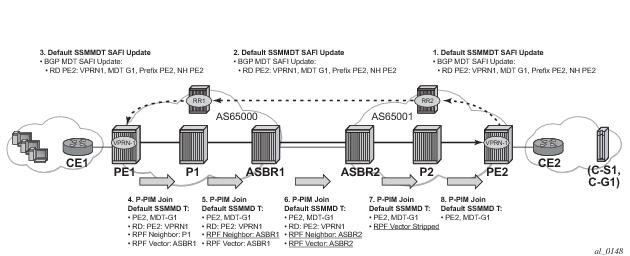
MVPN implementation based on the draft -Rosen can support membership auto discovery using BGP MDT-SAFI. A CLI option is provided per MVPN instance to enable auto discovery either using BGP MDT-SAFI or NG-MVPN. Only PIM-MDT is supported with BGP MDT-SAFI method.
UMH tunnel-status selection option must be enabled on the receiver PE for upstream fast failover. Primary and standby upstream PE pairs must be configured on the receiver PE to allow receiving active redundant multicast flow from the standby upstream PE.
Only one unique multicast flow is supported over each P2MP RSVP-TE or P2MP LDP LSP S-PMSI. Number of S-PMSI that can be initiated per MVPN instance is restricted by CLI command maximum-p2mp-spmsi. P2MP LSP S-PMSI cannot be used for more than one (S,G) stream (that is, multiple multicast flow) as number of S-PMSI per MVPN limit is reached. Multicast flows that cannot switch to S-PMSI remain on I-PMSI.
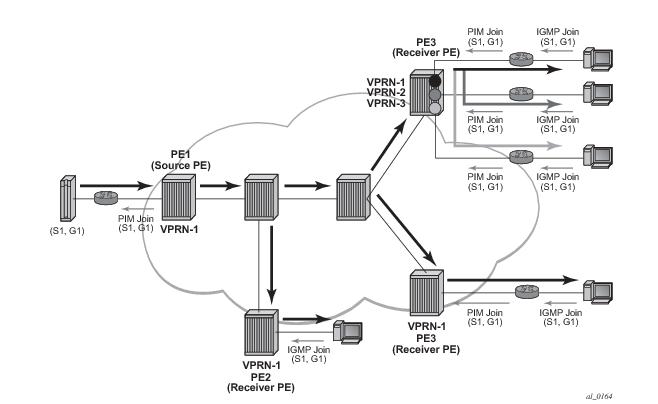
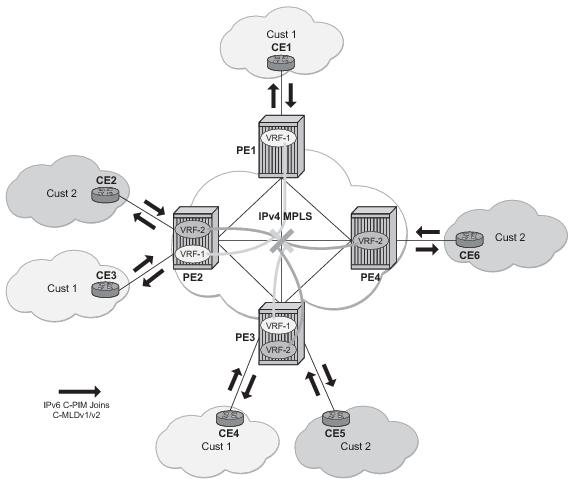
In Figure 102, VPRN-1 is source VPRN instance. VPRN-2 and VPRN-3 are receiver VPRN instances. PIM/IGMP JOIN received on VPRN-2 or VPRN-3 is for (S1,G1) multicast flow. Source S1 belongs to VPRN-1. Due to route export policy in VPRN-1 and import policy in VPRN-2 and VPRN-3, receiver host in VPRN-2 or VPRN-3 can subscribe to stream (S1,G1).
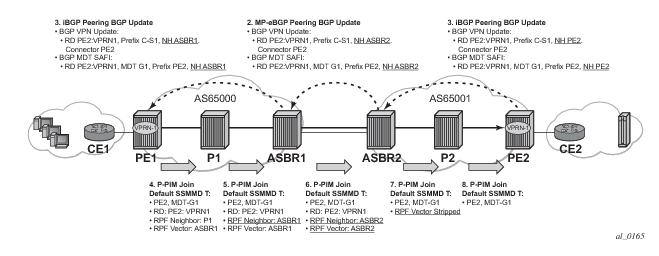
The RPF vector is added to a PIM join at a PE router when configure router pim rpfv option is enabled. P routers and ASBR routers must also have the option enabled to allow RPF Vector processing. If the option is not enabled, the RPF Vector is dropped and the PIM JOIN is processed as if the PIM Vector were not present.
The first option, referred to as Option-A (Figure 107), is considered inherent in any implementation. This method uses a back-to-back connection between separate VPRN instances in each AS. As a result, each VPRN instance views the inter-AS connection as an external interface to a remote VPRN customer site. The back-to-back VRF connections between the ASBR nodes require individual sub-interfaces, one per VRF.
The second option, referred to as Option-B (Figure 108), relies heavily on the AS Boundary Routers (ASBRs) as the interface between the autonomous systems. This approach enhances the scalability of the eBGP VRF-to-VRF solution by eliminating the need for per-VPRN configuration on the ASBR(s). However it requires that the ASBR(s) provide a control plan and forwarding plane connection between the autonomous systems. The ASBR(s) are connected to the PE nodes in its local autonomous system using iBGP either directly or through route reflectors. This means the ASBR(s) receive all the VPRN information and will forward these VPRN updates, VPN-IPV4, to all its EBGP peers, ASBR(s), using itself as the next-hop. It also changes the label associated with the route. This means the ASBR(s) must maintain an associate mapping of labels received and labels issued for those routes. The peer ASBR(s) will in turn forward those updates to all local IBGP peers.
This form of inter-AS VPRNs does not require instances of the VPRN to be created on the ASBR, as in option-A, as a result there is less management overhead. This is also the most common form of Inter-AS VPRNs used between different service providers as all routes advertised between autonomous systems can be controlled by route policies on the ASBRs by the
config>router>bgp>transport-tunnel CLI command.
The third option, referred to as Option-C (Figure 109), allows for a higher scale of VPRNs across AS boundaries but also expands the trust model between ASNs. As a result this model is typically used within a single company that may have multiple ASNs for various reasons.
config>service>vprn>network-interface>port port-id
config>service>vprn>network-interface>lag
lag-id
config>service>vprn>network-interface>port port-id:qtag1
config>service>vprn>network-interface>lag
port-id:qtag1
config>service>vprn>network-interface>port port-id:qtag1.qtag2
config>service>vprn>network-interface>port
port-id:qtag1.*
config>service>vprn>network-interface>lag
port-id:qtag1.qtag2
config>service>vprn>network-interface>lag
port-id:qtag1.*
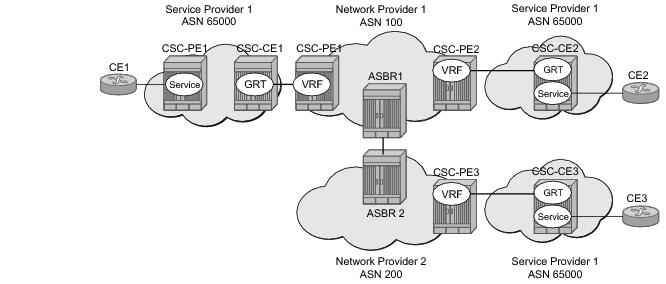
To use BGP-3107 as the label distribution protocol on the CSC interface, add the advertise-label ipv4 command to the BGP neighbor configuration. This command causes the capability to send and receive labeled-IPv4 routes {AFI=1, SAFI=4} to be negotiated with the CSC-CE peers.
To configure a VPRN to support CSC service, the carrier-carrier-vpn command must be enabled in its configuration. The command will fail if the VPRN has any existing SAP or spoke-SDP interfaces. A CSC interface can be added to a VPRN (using the
network-interface command) only if the
carrier-carrier-vpn command is present.
A VPRN service with the carrier-carrier-vpn command may be provisioned to use auto-bind, configured spoke SDPs or some combination. All SDP types are supported except for:
This feature is enabled within the VPRN service context under config>service>vprn>grt-lookup. This is an administrative context and provides the container under which all specific commands can be entered, except for policy definition. Policy definitions remain unchanged but are referenced from this context.
The enable-grt command establishes the basic functionality. When it is configured, any lookup miss in the VRF table will be resolved in the GRT, if available. By itself, this only provides part of the solution. Packet forwarding within GRT must understand how to route packets back to the proper node and to the specific VPRN from which the destination exists. Destination prefixes must be leaked from the VPRN to the GRT through the use of policy. Policies are created under the
config>router>policy-options hierarchy. By default, the number of prefixes leaked from the VPRN to the GRT is limited to five. The
export-limit command under the
grt-lookup hierarchy allows the service provider to override the default, or remove the limit.
The mode used for allocating service labels to VPN routes is now configurable per VPRN service. When the label mode is configured in the default per-VRF mode, the 7750-SR allocates one unique (platform-wide) service label per VRF. All VPN-IP routes exported by the PE from a particular VPRN service with that configuration have the same service label. When the PE receives a terminating MPLS packet, the service label value determines the VRF to which the packet belongs. A lookup of the IP packet DA in the forwarding table of the selected VRF determines the next-hop interface.