BGP for underlay routing
A routing protocol is needed to dynamically discover the shortest loop-free path through the underlay of a DC fabric to reach every destination IP subnet. The Border Gateway Protocol (BGP) is one of the leading technologies for this purpose as a result of its simplicity, scalability, and ease of multi-vendor interoperability.
BGP also provides policy mechanisms to perform hop-by-hop traffic engineering, leveraging functionality originally designed for this same purpose in the public Internet.
BGP underlay routing example
The following figure shows a 3-stage Clos fabric design using only BGP for underlay routing.
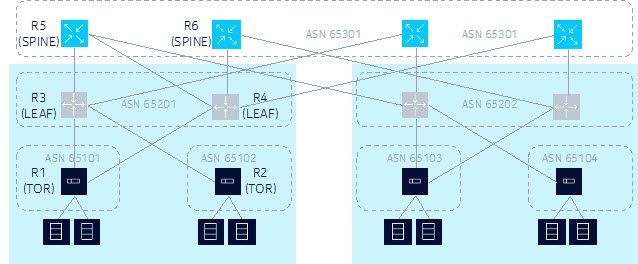
This design example shows the following:
Each Top-of-Rack (TOR) switch is a BGP router assigned with its own unique Autonomous System Number (ASN).
Each TOR switch is dual-homed to the two leaf switches in its same POD or container and adding more leaf switches later can achieve scale capacity.
Each TOR forms one single-hop External Border Gateway Protocol (EBGP) session to each of its upstream leaf switches. From a TOR perspective, these sessions are single-hop because each leaf switch is a BGP neighbor in the same IP subnet as its interface address toward the leaf switch.
Each leaf switch is a BGP router. All of the leaf switches in one POD or container belong to the same ASN, but this ASN is unique in the data center.
Each leaf switch has two uplinks into the spine layer. More uplinks could be added later to achieve scale capacity. Each leaf switch forms one single-hop EBGP session with each of its upstream spine switches.
Each spine switch is a BGP router. All of the spine switches in one data center belong to the same ASN but this ASN is unique in the network.
Advantages of BGP for underlay routing
Using BGP as shown in BGP underlay routing example has the following advantages:
Standard operation of the BGP best-path selection algorithm chooses the route to each destination with the AS_PATH length. This equates to the lowest hop count when each device prepends one ASN to the AS_PATH.
Standard operation of the BGP multipath algorithm sprays traffic across all paths with the same shortest AS_PATH length.
When a link goes down in the topology, the BGP session is taken down immediately if fast-failover is enabled. This may cause a new BGP best path to be advertised by the routers at each end of the failed session. Other routers may also advertise their own new best paths, but typically the failure does not propagate beyond routers that do not change their best path.
Traffic can be rerouted around any node in the topology by having it prepend extra AS numbers to the AS_PATH.
The best path or set of multipaths available to reach a destination TOR are visible in any device by looking at the AS_PATH attribute. This can be helpful with troubleshooting.
BGP configuration for underlay routing
The following examples define how to bring up a static, preconfigured EBGP session between Router 3 and Router 5 (as shown in BGP underlay routing example). Use the following two examples to define the minimum configuration required for each router:
Example: Configure Router 3 for static EBGP session
Use the following example to configure Router 3 for the static EBGP session.
-
In candidate mode, create a network-instance that owns the IP subinterface
toward Router 5.
--{ candidate shared default}--[ network-instance default ]-- # info detail type default admin-state enable ip-load-balancing { } interface ethernet-1/1.0 { } protocols { }Ensure the following:
- The network-instance is operationally enabled.
- The subinterface is operationally enabled.
- The subinterface has at least one IPv4 or IPv6 address assigned.
-
Add the BGP protocol to the network-instance.
By default, it is administratively enabled when the configuration is committed.
--{ candidate shared default}--[ network-instance default ]-- # protocols bgp -
Assign a global ASN to the BGP instance.
This is the ASN reported to peers when this network-instance opens a BGP session toward another router (unless it is overridden by a local-as configuration).Router 3 has a global ASN of 65201.
--{ candidate shared default}--[ network-instance default protocols bgp ]-- # autonomous-system 65201 -
Assign a router-ID to the BGP instance.
This is the BGP identifier reported to peers when this network-instance opens a BGP session toward another router. This overrides the router-id configuration at the network-instance level.Router 3 has a router-id of 192.0.3.1.
--{ candidate shared default}--[ network-instance default protocols bgp ]-- # router-id 192.0.3.1 -
Enable all address families that should be enabled globally as a default for
all peers of the BGP instance.
When you later configure individual neighbors or groups, you can override the enabled families at those levels.
--{ candidate shared default}--[ network-instance default protocols bgp ]-- # afi-safi ipv4-unicast admin-state enable --{ candidate shared default}--[ network-instance default protocols bgp ]-- # afi-safi ipv6-unicast admin-state enable -
Create a peer group to contain the neighbor session with Router 5.
A peer-group should include sessions that have a similar or almost identical configuration.In this example, the peer group is named "spine" because it is used to contain all spine layer peers. New groups are administratively enabled by default.
--{ candidate shared default}--[ network-instance default protocols bgp ]-- # group spine -
All of the configuration that is common to all peers in the group must be
configured at the group level.
In this example, this includes:
- peer-as (of the spine peers)
- export-policy
The export policy (named ‟pass-all” in the example) in the configuration output below was previously created in this work flow (if it does not exist, the commit fails). The export policy is required to advertise any routes to R5. This is because R5 is an EBGP peer, and by default, no routes are advertised to EBGP peers without an export policy. Note: this can be controlled by a setting in the network-instance protocols ‟bgp ebgp-default-policy” container.The "pass-all" export policy matches and accepts all BGP routes, while rejecting all non-BGP routes.--{ candidate shared default}--[ network- instance default protocols bgp group spine ] -- # info peer-as 65301 export-policy pass-all --{ candidate shared }--[ ] # info from running routing-policy routing-policy { policy pass-all { default-action { reject { } } statement 10 { match { protocol bgp } action { accept } } } } -
Configure the BGP session with router R5.
In this example, router R5 is reachable to R3 through the ethernet-1/1.0 subinterface. On this subnet, router R5 has the global-unicast IPv6 address 2001:db8::c11.In this minimal configuration example, the only required configuration for the neighbor is its association with the group "spine" that was previously created. New neighbors are administratively enabled by default.
--{ candidate shared default}--[ network-instance default protocols bgp ]-- # neighbor 2001:db8::c11 peer-group spine -
Review all changes and, if everything appears correct, commit the
changes:
# commit stay
Example: Configure Router 5 for static EBGP session
Use the following example to configure Router 5 for the static EBGP session.
-
In candidate mode, create a network-instance that owns the IP subinterface
toward Router 3. Ensure that:
- The network-instance is operationally enabled.
- The subinterface is operationally enabled.
- The subinterface has at least one IPv4 or IPv6 address assigned.
--{ candidate shared default}--[ network-instance default ]-- # info detail type default admin-state enable ip-forwarding { receive-ipv4-check true receive-ipv6-check true } ip-load-balancing { } interface ethernet-3/1.1 { } protocols { } mtu { path-mtu-discovery true } -
Add the BGP protocol to the network-instance. By default, it is
administratively enabled when the configuration is committed.
--{ candidate shared default}--[ network-instance default ]-- # protocols bgp -
Assign a global autonomous system number to the BGP instance.
Router 5 has a global autonomous system number of 65301.
--{ candidate shared default}--[ network-instance default protocols bgp ]-- # autonomous-system 65301 -
Assign a router-ID to the BGP instance.
This is the BGP identifier reported to peers when this network-instance opens a BGP session toward another router. This overrides the router-ID configuration at the network-instance level.Router 5 has a router-ID of 192.0.5.1.
--{ candidate shared default}--[ network-instance default protocols bgp ]-- # router-id 192.0.5.1 -
Enable all address families that should be enabled globally as a default for
all peers of the BGP instance.
When you later configure individual neighbors or groups, you can override the enabled families at those levels.
--{ candidate shared default}--[ network-instance default protocols bgp ]-- # afi-safi ipv4-unicast admin-state enable --{ candidate shared default}--[ network-instance default protocols bgp ]-- # afi-safi ipv6-unicast admin-state enable -
Create a peer-group to contain the neighbor session with Router 3. A peer-group
should include sessions that have a similar or almost identical configuration.
In this example, the peer-group is named "leaf-pod1" because it is used to contain all leaf peers in POD1. New groups are administratively enabled by default.
--{ candidate shared default}--[ network-instance default protocols bgp ]-- # group leaf-pod1 -
All of the configuration that is common to all peers in the group must be
configured at the group level.
In this example, this includes:
- peer-as (of the leaf peers in POD1)
- export-policy
The export policy (named ‟pass-all” in the example) is shown in the following running configuration output, and is required to advertise any routes to R3. This is because R3 is an EBGP peer and, by default, no routes are advertised to EBGP peers without an export policy.Note: This can be controlled by a setting in the network-instance protocols ‟bgp ebgp-default-policy” container.The "pass-all" export policy is a simple policy that matches all BGP routes and accepts them, while rejecting all non-BGP routes.--{ candidate Shared default}--[ network-instance default protocols bgp group leaf- pod1 ]-- # info peer-as 65201 export-policy pass-all --{ candidate }--[ network-instance default protocols bgp group leaf-pod1 ]-- # exit all --{ candidate shared default}--[ ] # info from running routing-policy routing-policy { policy pass-all { default-action { reject { } } statement 10 { match { protocol bgp } action { accept } } -
Configure the BGP session with router R3.
In this example, router R3 is reachable to R5 through the ethernet-3/1.1 subinterface. On this subnet, router R5 has the global-unicast IPv6 address 2001:db8::c12.In this minimal configuration example, the only required configuration for the neighbor is its association with the group ‟leaf-pod1” that was previously created. New neighbors are administratively enabled by default.
--{ candidate shared default}--[ network-instance default protocols bgp ]-- # neighbor 2001:db8::c12 peer-group leaf-pod1 - Review all changes and if everything looks correct, commit the changes.
-
From Router 3, verify that the session is up (State is established) using the
show neighbor command under the network-instance
protocols BGP hierarchy.
--{running}--{ network-instance default protocols bgp }-- srlinux# show neighbor ------------------------------------------------------------------------------------------------ BGP neighbor summary for network-instance "default" Flags: S static, D dynamic, L discovered by LLDP, B BFD enabled, - disabled, * slow ------------------------------------------------------------------------------------------------ +----------+---------------+-------+-------+-------+-------------+----------+--------------+---------+ | Net-Inst | Peer | Group | Flags | Peer- | State | Uptime | AFI/SAFI | RX/ | | | | | | AS | | | | Active | | | | | | | | | | /TX | +==========+===============+=======+=======+=======+=============+==========+==============+=========+ | default | 2001:db8::cli | spine | S | 65301 | established | 0d:0h: | ipv4-unicast | [4/3/1] | | | | | | | | 34min 7s | ipv6-unicast | [1/1/1] | +----------+---------------+-------+-------+-------+-------------+----------+--------------+---------+ ------------------------------------------------------------------------------------------------ Summary: 1 configured neighbors, 1 configured sessions are established, 0 disabled peers None dynamic sessions are established
Advanced configuration: BGP timers
When two BGP routers form a session, they each propose a value for the session hold-time in their OPEN messages. The lowest of the two proposed values becomes the operational hold-time for the lifetime of the session. If the operational hold-time is greater than zero, both routers are agreeing to send keepalive messages to each other. This ensures that any loss of connectivity between them can be detected.
Each router restarts its hold-timer every time it receives a message from the other peer. If the operational hold-timer reaches zero without receiving any keepalive or related message from the peer, the session is torn down (returned to the Idle state). Each router sends a keepalive message to its peer no more than one message every keepalive interval. The default value for the keepalive interval is one third of the operational hold-time, but it possible to configure a different interval.
In a data center environment, an EBGP session failure is usually caused by an interface going down. Interface events are propagated to BGP if fast-failover is enabled. The hold-timer expiry is not the usual mechanism for detecting connectivity problems. However, there may be some circumstances where some adjustment of the hold-time and the keepalive interval can be used.
Modifying timer-related defaults
Advanced configuration: BGP convergence optimization
By default, the SR Linux BGP process (running the BGP control plane) does not advertise a route for an IPv4 or IPv6 prefix until it has positive confirmation from the FIB manager process that the route is in the FIB of all installed line cards. This ensures that the router does not attract traffic destined for an IP prefix until all line cards have the ability to forward the traffic.
The BGP process does not delay route withdrawals until it knows that all line cards have removed the FIB state as this is not needed.
Configuring wait-for-fib-install
Nokia recommends that the wait-for-fib-install functionality remain enabled on routers that are in the datapath (that is, routers that set BGP next-hop-self). However, this does cause the rate of RIB-OUT route advertisements to slow to the rate of FIB programming. If the objective of a BGP performance test is to reach the highest possible route advertisement rate, set the wait-for-fib-install configuration leaf to false. For example:
Set wait-for-fib-install leaf to false
--{ candidate shared default}--[network-instance default protocols bgp route-
advertisement]--
# wait-for-fib-install false
Convergence process optimization after restarts
The BGP protocol and its state machine must attempt to reconverge whenever the following occurs:
the router starts up
the BGP manager (control plane) application restarts
all peers of a network-instance are hard-reset by a tools reset-peer command
When any of these conditions are met, the router resynchronizes its BGP RIB with the BGP RIB of other routers in the network. When resynchronization completes, BGP has "converged". During convergence, the following occurs to the restarting router:
It must reestablish its sessions with configured (and discovered) BGP neighbors.
It must relearn all BGP routes advertised by its direct BGP neighbors (their best paths, plus potentially some additional paths).
It must advertise to its direct neighbors, its own locally originated BGP routes plus the received routes that it considers its own set of best paths.
The default behavior of SR Linux BGP is to execute all of the preceding steps in parallel. As soon as the first BGP session has reestablished, the restarting router begins to advertise its own best paths to that BGP neighbor (even though it is still in the early stages of rebuilding its RIB-IN database).
As more sessions come up and more routes are learned, it is likely that routes previously considered best are no longer best, leading to multiple route advertisements for the same prefix with each incrementally better than the previous one. The best route is not determined until the last advertisement. The intermediate route advertisements can substantially increase the processing workload on the restarting router as well as its BGP neighbors. This can lengthen the overall convergence time and cause short term inefficiencies in traffic forwarding.
Configuring min-wait-to-advertise to delay BGP route advertisement
Instead of reconverging as previously described, SR Linux BGP can also be configured to delay the advertisement of BGP routes in a particular address family until convergence has occurred for that address family or until a configured time limit has expired. This behavior is activated by configuring a non-zero value for the min-wait-to-advertise configuration leaf. For example:
Set min-wait-to-advertise
--{ candidate shared default}--[ network-
instance default protocols bgp convergence ]--
# min-wait-to-advertise 600
Configuring max-wait-to-advertise
The max-wait-to-advertise leaf value for the IPv4-unicast and IPv6-unicast address families can be configured, or you can accept their default values (3x the min-wait-to-advertise value). If configuring a max-wait-to-advertise leaf with a non-default value, the value must be greater than the configured min-wait-to-advertise timer. In the following example, the max-wait-to-advertise timer is set to 900 seconds for IPv4-unicast and set to 800 seconds for IPv6-unicast.
Set max-wait-to-advertise
--{ candidate shared default}--[ network-instance default protocols bgp ]--
# afi-safi ipv4-unicast ipv4-unicast convergence max-wait-to-advertise max-wait-to-advertise 900
# afi-safi ipv6-unicast ipv6-unicast convergence max-wait-to-advertise 800
BGP min-/max-wait-to-advertise timers behavior
The min-wait-to-advertise timer begins after one of the following triggers occurs and the first BGP session becomes established.
-
BGP instance admin state set to enable or disable
-
Running tools clear network-instance protocols bgp reset-peer
-
BGP application restart
-
Node reboot
When the first session that supports the exchange of IPv4-unicast routes is established, the max-wait-to-advertise timer of the IPv4 address family starts. Likewise, when the first session that supports the exchange of IPv6-unicast routes is established, the max-wait-to-advertise timer of the IPv6 address family starts.
While the min-wait-to-advertise timer is running, BGP sessions come up, and routes are learned and sorted according to preference by the BGP decision process. However, no routes are advertised to any of the peers.
When the min-wait-to-advertise expires, BGP makes a list of IPv4 and IPv6 peers (that is, peers that support the exchange of IPv4-unicast routes and IPv6-unicast routes). It expects to receive the IPv4-unicast End of RIB (EOR) marker from each neighbor in the list of IPv4 peers, and it expects to receive the IPv6-unicast EOR from each neighbor in the list of IPv6 peers.
When BGP in the restarting router receives the last expected IPv4-unicast EOR, it declares that address family as converged and starts to advertise its best IPv4-unicast routes. Likewise, when BGP receives the last expected IPv6-unicast EOR, it declares that address family as converged and starts to advertise its best IPv6-unicast routes.
If the max-wait-to-advertise timer expires before the last expected EOR, is received for an address family, the convergence state for the address family moves to ‟timeout” and a RIB-OUT advertisement is triggered. This occurs even though convergence is not complete. The max-wait-to-advertise timers are fail-safe. They handle the scenario when one or more peers come up within the min-wait-to-advertise window, but their EORs are not sent.
Displaying convergence snapshot
In the example that follows, the BGP convergence process is triggered by a hard reset of all peers of the BGP instance:
Trigger BGP convergence using reset-peer
--{ * candidate shared default}--[ ]--
dut1# tools network-instance default protocols bgp reset-peer
/network-instance[name=default]/protocols/bgp:
Successfully executed the tools clear command.
--{ candidate shared }--[ ]--
If the show network-instance protocols bgp summary command is issued a few minutes after the session restarts, a snapshot of the convergence process can be viewed. For example, in the following output example, ten IPv4-unicast sessions are established when the min-wait-to-advertise timer expires and IPv4-unicast convergence takes 517 seconds.
Display convergence snapshot
dut1# show network-instance default protocols bgp summary
-----------------------------------------------------------------------------
BGP is enabled and up in network-instance "default"
Global AS number : 65201
BGP identifier : 192.0.3.1
-----------------------------------------------------------------------------
Total paths : 27
Received routes : 200000
Received and active routes: 200000
Total UP peers : 20
Configured peers : 20, 0 are disabled
Dynamic peers : None
-----------------------------------------------------------------------------
Default preferences
BGP Local Preference attribute: 100
EBGP route-table preference : 170
IBGP route-table preference : 170
-----------------------------------------------------------------------------
Wait for FIB install to advertise: True
Send rapid withdrawals : False
-----------------------------------------------------------------------------
Ipv4-unicast AFI/SAFI
Received routes : 100000
Received and active routes : 100000
Max number of multipaths : 8, 1
Multipath can transit multi AS: True
-----------------------------------------------------------------------------
Min adv delay after restart(slow peer thresh): 600s
Currently established sessions : 10
Sessions established at slow peer thresh : 10
First session establishment after restart : 5s
Last session established after restart : 252s
-----------------------------------------------------------------------------
Max advertisement delay after first peer UP: 900s
Max adv delay exceeded after last restart : None
Current convergence state : converged
Converged peers : 10
Convergence time after last restart : 517s
-----------------------------------------------------------------------------
Ipv6-unicast AFI/SAFI
Received routes : 100000
Received and active routes : 100000
Max number of multipaths : 1,1
Multipath can transit multi AS: True
-----------------------------------------------------------------------------
Min adv delay after restart(slow peer thresh): 600s
Currently established sessions : 10
Sessions established at slow peer thresh : 10
First session establishment after restart : 8s
Last session established after restart : 312s
-----------------------------------------------------------------------------
Max advertisement delay after first peer UP: 800s
Max adv delay exceeded after last restart : None
Current convergence state : converged
Converged peers : 10
Convergence time after last restart : 705s
-----------------------------------------------------------------------------
--{ candidate shared }--[ ]--
Advanced configuration: IPv4 route advertisement with IPv6 next-hops
Some data centers are migrating away from an IPv4/IPv6 dual-stack infrastructure and moving toward an IPv6-only infrastructure. In an IPv6-only design, each interface in the fabric (such as the leaf-spine, leaf-TOR) is assigned one or more IPv6 addresses, but no IPv4 addresses.
To route and forward IPv4 packets over an IPv6-only fabric, the leaf and spine switches must support the following:
The ability to advertise a BGP route for IPv4 Network Level Reachability Information (NLRI) with an IPv6 BGP next-hop address.
The ability to receive a BGP route for IPv4 NLRI with an IPv6 BGP next-hop address.
The ability to accept IPv4 packets on an IPv6-only interface.
Advertising a BGP route for IPv4 NLRI with an IPv6 BGP next-hop address
To enable this functionality, use the advertise-ipv6-next-hops command, which is available on a per-session basis. The following is a sample configuration:
Advertise BGP route for IPv4 NLRI with IPv6 BGP next-hop
--{ candidate shared default}--[ network-instance default protocols bgp ]--
# afi-safi ipv4-unicast ipv4-unicast advertise-ipv6-next-hops true
Receiving a BGP route for IPv4 NLRI with an IPv6 BGP next-hop address
On the SR Linux, the ability to receive a BGP route for IPv4 NLRI with an IPv6 BGP next-hop address is not enabled by default. To enable this functionality, use the receive-ipv6-next-hops command, which is available on a per-session basis.
This command allows SR Linux to advertise the extended-next-hop-encoding BGP capability, defined in RFC 5549, to the peers included in the scope of the command. This BGP capability encodes NLRI AFI 1, NLRI SAFI 1, and next-hop AFI 2. It informs peers that they can advertise MP-BGP encoded IPv4 routes with IPv6 next-hops. When the routes are received, the router then attempts to resolve them using IPv6 routes.
If the router receives an IPv4 route with an IPv6 next-hop that is resolved by a static or direct IPv6 route (and an IPv6 neighbor entry for the next-hop host address), the IPv4 route is programmed in the FIB so that matching IPv4 packets are sent without additional encapsulation. Packets are sent through the indicated interface with a MAC destination address provided by the IPv6 neighbor entry.
The following is a configuration example:
Receive BGP route for IPv4 NLRI with IPv6 BGP next-hop
--{ candidate shared }--[ network-instance default protocols bgp ]--
# afi-safi ipv4-unicast ipv4-unicast receive-ipv6-next-hops true
Accepting IPv4 packets on an IPv6-only interface
The datapath of the SR Linux checks for and discards all IPv4 packets that are received on an IPv6-only subinterface (that is, a subinterface with no configured IPv4 addresses). This is done for security reasons. However, if the router has advertised IPv4 routes with IPv6 next-hops to a peer, the check should be disabled on all subinterfaces that could be used by the peer when it installs the IPv4 route.
To disable this check on all subinterfaces bound to a specific network-instance, set the ipv4-receive-check leaf to false.
The following is a configuration example:
Accept IPv4 packets on an IPv6-only interface
--{ candidate shared default}--[ network-instance default ]--
# ip-forwarding receive-ipv4-check false