Resources
In EDA, a resource is a unit of automation and can represent virtually anything:
- an interface on a network device
- a complete fabric configuration
- a network service like a VPN or a VRF
- and even non-network related resources like a user account, a DNS record, or a firewall rule.
As a Kubernetes citizen, EDA represents its resources using Custom Resources (CRs) of Kubernetes that can be created using multiple methods including the Kubernetes (K8s) API, the EDA API, or through a User Interface (UI). By using CRs, EDA also implements the Kubernetes Resource Model, or KRM.
The KRM defines how Kubernetes resources are described, created, updated, and monitored.
Kubernetes resources consist of a combination of fields that describe their state and
behavior within the cluster, most importantly the spec,
status, and metadata fields.
In Kubernetes, a resource is any object the Kubernetes API can create and manage. These
resources represent various entities, such as Pods,
Services, Deployments,
ConfigMapsand so on., which are essential for orchestrating
containerized applications.
Every resource in Kubernetes is defined using a standard structure that includes
metadata, a spec, and a status.
Where:
metadataprovides unique identifiers and metadata for resources.specprovides the specification for the resource - its configuration.statusprovides an interface for the controller/resource to publish relevant information back to the user/operator.
Derived resources
As part of the execution of a transaction, EDA applications sometimes generate a set of resources. These resources are not "owned" by the user or operator; instead, they owned by the application that generated them. To ensure the ongoing operation of the owning application, such resources can only be changed by that same application.
In EDA such a resource is known as a derived resource; it is a resource whose entire content is derived from some other resource.
The EDA GUI prevents you from modifying or deleting derived resources. To indicate that a resource is derived and cannot be modified or deleted, derived resources are presented as read-only, and the usual modification actions are restricted; for example, EDA does not allow you to use a Delete action to delete a derived resource. Unavailable actions are grayed out in action lists.
In data grids, rows displaying derived resources are shaded to indicate that those resources cannot be modified or deleted.
Labels
EDA uses labels to organize and describe resources. Labels are among the metadata common to all resources in EDA. In the EDA GUI, labels can be viewed and entered in the Metadata panel for a resource.
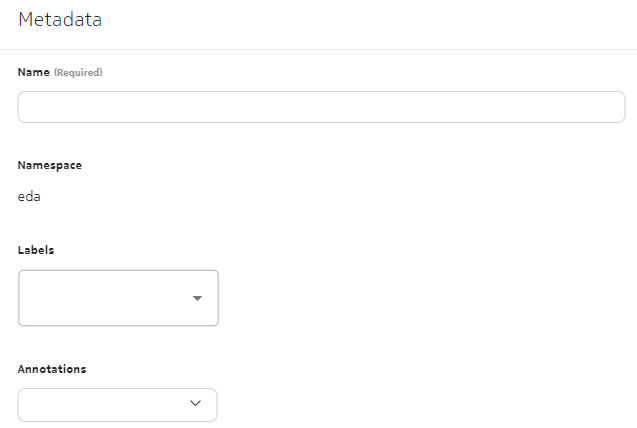
Labels are not mere descriptions of objects; they are also used throughout EDA as the basis for selecting objects. You can apply the same label to a set of objects and then manipulate them as a group based on that shared label. This makes it easier for system administrators and operators to manage large-scale clusters.
A label consists of two pieces of information: a key, and a value. Labels are limited to key-value pairs of small size and are designed for simple, static values. For example:
- app=frontend
- version=v1.0
- environment=prod
The key can include up to 253 characters if using the DNS subdomain format
(<domain>/<key>=<value>), and the value can include up to
63 characters.
Labels are particularly useful for selecting objects; for example, you can use a label to indicate which pods a service should treat as traffic destinations. The following illustration shows a segment of a fabric configuration in which participating leaf nodes are selected among those that possess the label "role" and its value is "leaf". Additional labels can be selected to narrow down the set of qualifying nodes.
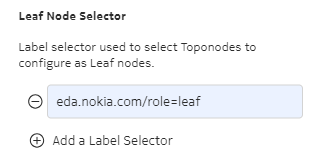
Users and application writers can:
- apply labels arbitrarily to resources
- select resources within their application based on these labels
Label changes are considered normal changes for the purposes of transactions. A label change can trigger execution of scripts, and if executions are successful their changes are persisted to git.
Labels are a flexible way to decouple the interactions between resources, but they do have some limitations. In particular, the value of a label is limited to 63 characters, and Kubernetes resource names are limited to 253 characters. This means that labels cannot reliably encode a resource name, for example.
metav1.LabelSelector Go struct in
order to select labels of a certain resource type. This LabelSelector
is not supported in EDA. Instead, EDA uses one or more string expressions to select.
An expression can contain one or more selectors, separated by ,.
Selectors are AND'd together, similar to Kubernetes' LabelSelector.
A selector supports various operators, including but not limited to
=, !=, in,
notin.
Some examples:
app=catmeans a resource is only returned if it has a label present namedapp, with a value ofcat.app in (cat)is another way of writing the above, meaning a resource is only returned if it has a label namedappwith a value ofcat.appreturns a resource if it has a label present with the nameapp, with any value (including an empty value).!appreturns a resource if it does not have a label present with the nameapp, with or without a value.app in (cat, dog)returns a resource if it has a label present with the nameapp, with a value ofcatORdog.app in (cat, dog),env in (prod, demo)returns a resource if it has both a label namedappwith valuescatORdog, AND a label namedenvwith valuesprodORdemo.app notin (elephant, rhino)returns a resource if it does NOT contain a label namedappwith a value of eitherelephantORrhino.app=cat,env=prodreturns a resource if it has a label namedappwith the valuecat, AND a label namedenvwith valueprod.
Selecting or creating a label
In the EDA GUI, where a Label field is present, you can enter a label by clicking in the Label field. This displays a list of available labels to choose from:
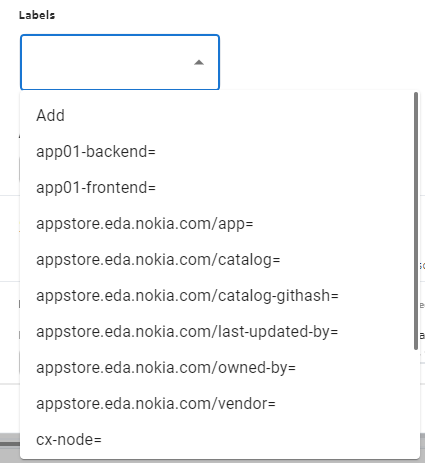
To use an existing label, select it in the list. To narrow the list of displayed labels, type the first few letters of a label you are looking for; the list filters to show only the labels that match the text provided.
To create a new label, click Add to open the label creation window:
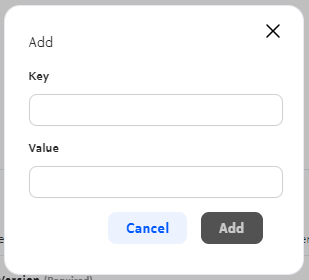
Enter a Key and a Value, then click Add.
Annotations
EDA uses annotations to organize and describe resources. Annotations are among the metadata common to all resources in EDA. In the EDA GUI, annotations can be viewed and entered in the Metadata panel for a resource.
Annotations are similar to labels, but are used for different purposes.
Like a label, an annotation consists of a key and a value. However, annotations values are not subject to the same length restrictions as labels. Annotations can store lengthy information that resembles the information contained in labels, but frequently overruns labels length restrictions.
Like labels, annotations are metadata about an object. But unlike labels, annotations do not influence the system’s behavior. Annotations are not used for selection or querying. They are not indexed and do not affect any selection logic. Annotations are more informational; and although they are not used by EDA's resource selection systems, they can still be useful to external systems, people, or automation tools.
Annotations are typically used to store arbitrary, unstructured data like configuration details, URLs, object tracking information, or any other information that does not need to be part of Kubernetes’ logic. They are useful for attaching large or complex data that doesn’t need to be indexed, like CI/CD metadata, deployment signatures, or documentation links.
- ConfigEngine uses the annotations property to tag resources for which
transactions have failed.
The system-generated annotation text indicates that the resource is part of a failed transaction, and the Kubernetes-visible version of the resource may not be aligned with the running/actual version.
- The system uses the annotations property to store resource names
This is primarily used with derived resources, where it is useful to be able to see the hierarchy of resources - for example a
VirtualNetworkgenerating aBridgeDomain.
- kubectl.kubernetes.io/last-applied-configuration="JSON"
- author=team-name
- description="Stores the last applied configuration of a resource for use by kubectl apply"
Annotation changes are considered normal changes for the purposes of transactions. They trigger execution of scripts, and if executions are successful their changes are persisted to git. However there are a small number of exceptions. EDA does not trigger, monitor, or persist any annotations with the following keys:
core.eda.nokia.com/failed-transactioncore.eda.nokia.com/running-versionkubectl.kubernetes.io/last-applied-configuration
Selecting or creating an annotation
In the EDA GUI, where an Annotation field is present, you can enter an annotation by clicking in the Annotation field. This displays a list of available annotations to choose from:
To use an existing annotation, select it in the list. To narrow the list of displayed annotations, type the first few letters of a label you are looking for; the list filters to show only the annotations that match the text provided.
To create a new annotation, click Create a Key Value pair chip... to open the annotation creation window:
Enter a Key and a Value, then click Add.