Alarms
Alarms in EDA can arise from a variety of sources, including the EDA system itself and
the wide array of supported apps. For any alarm, the source/affected object is
identified as part of the alarm in the group and kind
fields.
Alarm are also associated with a namespace; this could be the base EDA namespace, or some other namespace. Users can only see and interact with alarms in namespaces for which they have access permissions.
Some alarms can be generated by intent-based apps within EDA. EDA treats such alarms as having been cleared if the app stops reporting that alarm.
Alarms associated with apps are described in documentation for individual apps.
Alarms on standby clusters
Standby cluster alarms can be important in understanding the state of redundancy in an EDA cluster. It is therefore useful to be able to see alarms generated on a standby cluster member even when working with the active member.
EDA supports this using the `cluster_member` field, which is set to the name of the cluster member that raised the alarm. This allows an operator to view alarms for all clusters, but still distinguish alarms for the active cluster from those for a standby cluster. For alarms that are not cluster-specific, this field remains unset.
Alarms in the EDA GUI
An alarm summary is displayed on the EDA home page. Beyond that summary, alarms are primarily displayed, and interacted with, on the Alarms page. There you can do the following for individual alarms, or as a bulk operation to a number of concurrently selected alarms:
- Suppress an alarm: this sets the suppressed flag for the current instance of the alarm. By default, suppressed alarms are not displayed in the EDA GUI.
- Delete an alarm: this removes all history of the alarm. Deletion is only allowed for cleared alarms. The option is disabled for active alarms.
- Acknowledge an alarm: this sets the Acknowledged flag for the current instance of the alarm.
The Alarms page
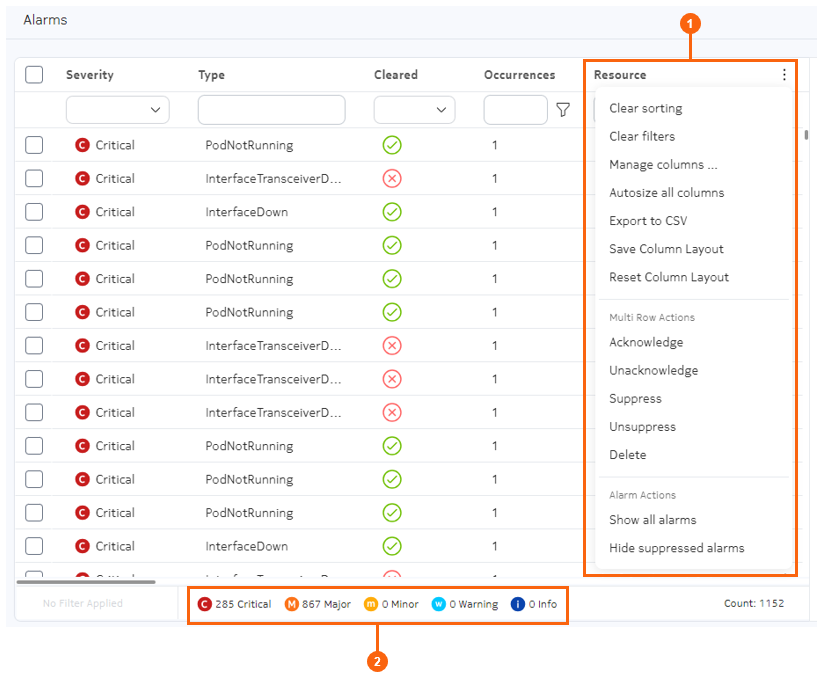
| # | Name | Function |
|---|---|---|
| 1 | Alarms menu | The Alarms menu includes:
|
| 2 | Alarm count | Displays the number of current alarms of various severities. |
Columns
The list of alarms displays the following columns by default.
| Column | Description |
|---|---|
| Severity | The importance of the alarm, as defined by the alarm itself.
Supported severities are:
|
| Type | The alarm type, as defined by the alarm itself. For example, InterfaceDown. |
| Cleared | Whether the alarm has been cleared by an operator. Possible
values are:
|
| Occurrences | The number of occurrences for the alarm. |
| Resource | Indicates the name of the resource that this alarm is present
on.
|
| Kind | Indicates the kind of resource the alarm is present on.
|
| Group | Indicates the group of the resource the alarm is present on.
|
| Last Changed | Indicates the time the alarm last changed state. The timestamp is updated any time an alarm changes state between cleared and not cleared. |
Sample core alarms
| Property | Description |
|---|---|
| Name | RepositoryReachabilityDown-<cluster>-<server-name>-<repo-type>-<source> |
| Severity | Critical |
| Description | Connectivity between <source-kind> "<source>" and the "<repo-type>" repository at "<server-uri/remote-path>" is down. This alarm is raised after three failures to connect to a repository, where each attempt is made at a 15s interval. After three failures the alarm is generated (so after 45s), and is cleared on a connection attempt succeeding. |
| Probable cause | Connectivity issues, Kubernetes CNI misconfiguration, or credential/TLS misconfiguration/expiration. |
| Remedial action | Restore connectivity between the corresponding <source-kind> and apps repository/git server. Ensure credentials and proxy configuration is correct, and any offered certificates are trusted. |
|
|
| Property | Description |
|---|---|
| Name | ServiceReachabilityDown-<cluster>-<service>-<source> |
| Severity | Critical |
| Description | Connectivity between <source-kind> "<source>" and the <kind> on "<service>" is down. |
| Probable cause | Connectivity issues between worker nodes in the Kubernetes cluster, Kubernetes CNI misconfiguration, pod failure, or TLS misconfiguration/expiration. |
| Remedial action | Restore connectivity between the corresponding source and destination. Ensure credentials and proxy configuration is correct (typically using no proxy for inter-cluster HTTPS), and certificate validity. |
|
|
| Property | Description |
|---|---|
| Name | PodNotRunning-<cluster>-<pod> |
| Severity | Critical |
| Description | Pod "<pod>" is not in the "Running" state. Any functionality provided by this pod is not available. This alarm can be raised transiently at system startup. |
| Probable cause | Kubernetes controller or registry reachability issues, worker node failure, initial instantiation. |
| Remedial action | Validate reachability to the registry used to pull the image for the specified pod, ensure no worker node, storage, or networking issues exist that would cause the Kubernetes controller to mark the pod in any state other than "Running". |
|
|
| Property | Description |
|---|---|
| Name | DeploymentDegraded-<cluster>-<deployment> |
| Severity | Critical |
| Description | Deployment "<deployment>" has at least one replica not in the "Running" state. Depending on the application this may result in loss of functionality or loss of service capacity. This alarm can be raised transiently at system startup. |
| Probable cause | Kubernetes infrastructure issues, worker node failure, initial instantiation. |
| Remedial action | Validate reachability to the registry used to pull images for any failed pods in the Deployment, ensure no worker node, storage, or networking issues exist that would cause the Kubernetes controller to mark pods in any state other than "Running". |
|
|
| Property | Description |
|---|---|
| Name | DeploymentDown-<cluster>-<deployment> |
| Severity | Critical |
| Description | Deployment "<deployment>" is down, with no pods in the "Running" state. Any functionality provided by the Deployment is not available. This alarm can be raised transiently at system startup. |
| Probable cause | Kubernetes infrastructure issues, worker node failure, initial instantiation. |
| Remedial action | Validate reachability to the registry used to pull images for failed pods in the Deployment, ensure no worker node, storage, or networking issues exist that would cause the Kubernetes controller to mark pods in any state other than "Running". |
|
|
| Property | Description |
|---|---|
| Name | PPDown-<cluster>-<npp> |
| Severity | Critical |
| Description | Connectivity between ConfigEngine "<config-engine>" and the NPP "<npp>" is down. This results in no new transactions succeeding to targets served by this NPP (unless operating in null mode), and no telemetry updates being received. Effectively targets served by this NPP are offline. Look for a corresponding PodNotRunning alarm. |
| Probable cause | Connectivity issues between worker nodes in the Kubernetes cluster, Kubernetes CNI misconfiguration, pod failure, or TLS misconfiguration/expiration. |
| Remedial action | Restore connectivity between the corresponding ConfigEngine and the destination NPP. Ensure credentials and proxy configuration is correct (typically using no proxy for inter-cluster HTTPS), and certificate validity. |
|
|
| Property | Description |
|---|---|
| Name | PoolThresholdExceeded-<pool-type>-<pool-name>-<pool-instance> |
| Severity | Varies; see definitions |
| Description | The "<pool-instance>" instance of the <pool-type> "<pool-name>" has crossed the <severity> threshold of <threshold>. |
| Probable cause | Pool utilization. |
| Remedial action | Expand the pool via growing a segment, or add additional segments. Additionally you may move pool consumers to a different pool. |
|
|
| Property | Description |
|---|---|
| Name | StateEngineReachabilityDown-<state-engine>-<state-controller> |
| Severity | Critical |
| Description | Connectivity between State Controller "<state-controller>" and the State Engine "<state-engine>" is down. This results in no new state application instances being deployed to the corresponding State Engine, and the rebalancing of already-pinned instances to other State Engines. This connectivity is also used to distribute the map of shards to State Engine, meaning the corresponding State Engine will not receive shard updates (assuming it is still running). |
| Probable cause | Connectivity issues between worker nodes in the Kubernetes cluster, Kubernetes CNI misconfiguration, pod failure, or TLS misconfiguration/expiration. |
| Remedial action | Restore connectivity between the corresponding State Controller and the destination State Engine. Ensure credentials and proxy configuration is correct (typically using no proxy for inter-cluster HTTPS), and certificate validity. |
|
|
Viewing alarms
The page in the EDA UI in which to view and interact with alarms is located at .
- is sorted first by "Severity", and then by the "last changed" timestamp in descending order (most recent change first)
- hides any suppressed alarms
- Use standard EDA table controls to manage the alarms list. XREF
-
To include suppressed alarms (which are hidden by default), do the
following:
- Click the More icon at the upper right of the Alarms page.
- Select Show All Alarms from the displayed list.
-
To exclude suppressed alarms from the list, do the following:
- Click the More icon at the upper right of the Alarms page.
- Select Hide suppressed alarms from the displayed list.
Acknowledging an alarm
- Find the alarm in the list using the sorting and filtering controls.
- At the right side of the row, click the Table row actions button.
- Select Acknowledge from the list.
- Click Confirm to complete the acknowledgement.
Acknowledge multiple alarms
- Use the sorting and filtering controls to display the necessary set of alarms in the list.
-
Select all of the alarms you want to acknowledge by checking the box at the
left edge of the list. Click the check box again to unselect any alarm.
Note: To select all alarms in the list, check the check box in the title row. Click the check box again to unselect all alarms in the list.Note: The number of alarms you have selected, as well as the total number of alarms, is indicated at the lower right of the Alarms page.
- At the upper right of the Alarms page, click the Table settings & actions button.
- Select Acknowledge from the list.
- Click Confirm to complete the acknowledgement for all alarms.
Deleting a single alarm
- Find the alarm in the list using the sorting and filtering controls.
- At the right side of the row, click the Table row actions button.
-
Select Delete from the list.
Note: The Delete option is not displayed for an alarm that has not been cleared.
- Click Confirm to complete the acknowledgement.
Deleting multiple alarms
- Use the sorting and filtering controls to display the necessary set of alarms in the list.
-
Select all of the alarms you want to delete by checking the box at the left
edge of the list. Click the check box again to unselect any alarm.
Note: To select all alarms in the list, check the check box in the title row. Click the check box again to unselect all alarms in the list.Note: The number of alarms you have selected, as well as the total number of alarms, is indicated at the lower right of the Alarms page.
- At the upper right of the Alarms page, click the Table settings & actions button.
- Select Delete from the list.
-
Click Confirm to complete the acknowledgement for all
alarms.
Note: If some of the alarms you selected were not eligible for deletion, only those that were eligible are deleted by this operation. Ineligible alarms are not deleted. No error message displays in this case.
Suppress a single alarm
- Find the alarm in the list using the sorting and filtering controls.
- At the right side of the row, click the Table row actions button.
- Select Suppress from the list.
-
Click Confirm to complete the acknowledgement.
Note: By default, suppressed alarms are not displayed in the alarms list. Unless you have selected to show all alarms, suppressing an alarm causes it to vanish from the alarms list.
Suppressing multiple alarms
- Use the sorting and filtering controls to display the necessary set of alarms in the list.
-
Select all of the alarms you want to delete by checking the box at the left
edge of the list. Click the check box again to unselect any alarm.
Note: To select all alarms in the list, check the check box in the title row. Click the check box again to unselect all alarms in the list.Note: The number of alarms you have selected, as well as the total number of alarms, is indicated at the lower right of the Alarms page.
- At the upper right of the Alarms page, click the Table settings & actions button.
- Select Suppress from the list.
-
Click Confirm to complete the acknowledgement for all
alarms.
Note: By default, suppressed alarms are not displayed in the alarms list. Unless you have selected to show all alarms, suppressing alarms causes them to vanish from the alarms list.
Viewing alarm history
- Find the alarm in the list using the sorting and filtering controls.
- At the right side of the row, click the Table row actions button.
-
Select History from the list.
EDA opens the Alarm History window, which shows all events pertaining to the selected alarm including the following details:
- Cleared (yes/no)
- Last change date/time
- Probable cause
- Remedial action